
前不久Intel NEX事业部的活动上,有几个现场demo让我们印象挺深刻的:主要是CV(计算机视觉)类行业应用(部分是基于AI),靠CPU单打独斗(或搭配核显)就行,不需要外部加速器。
比如说海康机器人视觉方案VC3000X用于PL光伏检测,最新一代方案用了12代酷睿CPU,替换掉了上一代方案选配的酷睿i7-9700 + RTX 3060的方案。据说不仅功耗和成本都更低,而且性能还更好了。是不是还挺反直觉的?
还有Intel自己展示了一台OCES架构服务器,作为边缘服务器,用于智慧社区——比如说小区里有孩子走丢了,给这套系统输入孩子的照片,它就能从监控数据库里,通过特征比对和搜索的优化算法,来给出孩子最后出现的时间、地点。这个方案是在至强CPU上完成的,完全没有借助独立GPU或者别的加速器。


此类展示还不少,感觉还是挺突破我们对于这种规模的CV或者AI应用,需要加速器参与的认知的。前不久Intel在大湾区科技创新中心,给我们现场展示了用轻薄本来推理LLM大语言模型和Stable Diffusion文生图与图生图,速度也还挺快——CPU或者核显,在这其中就是算力担当。当然,和大功率独显或加速器相比,模型肯定不是一个量级,但起码让我们见识了,并不是所有边缘的AI、CV都得用GPU和AI芯片。
“很多客户用CPU的时间很多,他们也可能需要运行AI工作负载。”宋继强(英特尔研究院副总裁、英特尔中国研究院院长)在前不久的Intel中国学术峰会上接受采访时说,“有些并不需要单独购置加速器,不管是AI加速器还是GPU,直接就在CPU上去做。这对他们而言,不仅节省了部署成本,也减少了传输、存储等成本。”
我们从今年这场学术峰会上,听到最多的恐怕就是AI和生成式AI了——毕竟这是现在的大热门。可能大部分读者听到生成式AI就会立刻想到英伟达。而同样提供算力的Intel似乎在这股洪流下,就显得没那么耀眼。但从这场学术峰会几名大佬的演讲,我们还是能够从中窥见Intel在这个时代下的AI哲学。
借此,我们来谈谈Intel的AI布局。其实AI并非本场学术大会的唯一主题,比如宋继强还给出了Intel在半导体制造、封装,乃至新计算范式方面的前沿技术介绍,我们也听到了一些新料:比如不同NA的EUV设备对晶体管scaling down的具体影响,以及Loihi神经拟态计算的潜在价值、量子计算的阶段成果等等——不过这些,我们放到后续单独的文章里再谈。本文就谈谈Intel和AI,即便基于本场活动的探讨,大概只能算是管中窥豹。
AI时代,CPU扮演这样的角色
大部分关注Intel处理器的同学应该知道,Intel在Sunny Cove/Cypress Cove(10代酷睿,2代至强)这代CPU核心上新增AVX-512支持,同时实现针对AI/ML加速的Deep Learning Boost,支持VNNI指令(Vector Neural Network Instructions,专用于INT8量化)。换句话说,就是CPU某个模块的AI加速——这已经是几年前了。
当时我们认为,加速计算发展大背景下,这类工作显然最终都会落到GPU或者专用AI加速处理器上,CPU做出这番支持价值真的会有多大吗?而且早在2020年前后,就已经有数据统计机构在唱衰CPU未来的市场价值会被加速器压缩了。
后续统称作“Intel AMX(Advanced Matrix Extensions)”的这一思路仍然得到了延续,包括现在的4代至强(Sapphire Rapids),AMX的INT8量化又再度大幅提升了模型性能。戴金权(英特尔院士、大数据技术全球CTO)在主题演讲中说Sapphire Rapids“提供了更大的2D寄存器支持,通过最新的矩阵计算指令,大大提升了BF16和INT8方面的AI能力。”表明Intel还是很坚持他们对于CPU的这一决策的。
这应该是今年Intel最早在Computex上就演示轻薄本具备生成式AI推理能力的实现基础之一。而且就NEX业务在边缘端部署的那些案例来看,对于很多具体的应用而言,CPU可能真的是最优选。我们在2023英特尔网络与边缘产业高层论坛上,和做零售AI解决方案的一家企业负责人聊了聊,他就强调说零售客户对成本很敏感,所以他们的AI Box里面就只配了酷睿i5处理器,再无其他加速器——况且效果也很不错。
“虽然我没有具体的数字,但我可以说在推理方面,Intel CPU是市场占有率第一。”戴金权所说的“占有率第一”应该是指在所有处理器类型里的第一。他在这次的Intel中国学术峰会上展示了好几个用轻薄本做生成式AI模型推理的例子,“这些应用在客户端设备上有更广泛的应用场景。”
技术分享会上,Intel给我们现场展示了用一台采用酷睿i7-13700H处理器的轻薄本来推理ChatGLM-6b、Llama 2-13b,AI回应的token生成速度是显著快于人的阅读速度的。据说ChatGLM-6b入门级规模的模型,只需要4个Golden Cove核(12代酷睿的P-core),就能快速跑起来;“13b规模翻一倍,现在我们也能做到很好的体验”。
戴金权另外在主题演讲里给出了跑StarCoder-15.5b模型的展示,同样是轻薄本。Intel宣传中是说,16GB RAM的酷睿处理器轻薄本跑160亿参数级别的模型本地推理都是没问题的。
“Intel的一个愿景是AI everywhere。其实Intel今天的硬件,某种意义上已经是无处不在的了。大家都需要用笔记本或者边缘端的一些设备。”戴金权谈到,“要做到AI无处不在,那就必须做到生成式AI得在这些客户端上跑起来——这些客户端可能只有很轻量的CPU,但却要求做到对生成式AI的高效支撑。”

也不光是酷睿CPU,田新民(英特尔院士、首席编译器性能架构师)提到借着至强CPU(Sapphire Rapids)自身对AI推理的“平衡”设计,在诸如蛋白质折叠预测、变异检测这类小型AI模型上,靠CPU一己之力就实现相比CPU+GPU更强的性能和效率。“这也说明了第四代至强对小规模科学研究就能起到很好的支撑作用。”这就是至强CPU应用AI的典型案例了吧。
XPU加持下的AI之路
如果你对酷睿处理器真的了解就会发现,现在的酷睿CPU并不单纯是“CPU”——它是一颗包含了CPU、核显、VPU等关键组成部分的SoC芯片。其实在今年Computex上,Intel首次展示用Meteor Lake(下一代酷睿处理器)在推理Diffusion模型,就同时用到了CPU、核显和VPU资源。
当时Intel对外展示的是输入提示语“月亮上,宇航员骑着一只马”,20秒出图。Intel解释说这个演示“是将不同层放在不同的IP上,比如VPU承载VNET模块的运行,GPU承载encoder模块的运行”,“整体是将整个模型分散到不同的IP上。”另外最终还有个将出图执行AI超分的流程,是完全基于VPU加速。值得一提的是,这个调度过程由OpenVINO完成。
“现在笔记本里面的Intel芯片就是很强大的XPU了。”戴金权谈到,另一方面当然也可以用性能更强大的Arc GPU,也就是Intel面向PC设备的独立显卡。他在学术峰会上展示基于Arc GPU来跑ChatGLM2-6b:“当然这样就能支撑更多更大的模型。这方面的工作,我们现在还在开展中——前两周我们刚刚把这两个模型带到Arc独立显卡上。”
技术分享会上,Intel也展示了Arc GPU加速的能力。而关键信息是,Intel告诉我们这次用Arc GPU跑Stable Diffusion相比2个月之前有了非常明确的进步;甚至说如今的Arc A770在生成式AI推理能力上,完全能够达到隔壁RTX 4080的水平。这些其实都是软件团队努力的结果。有关软件的部分,后文也会谈到。
由此,我们可以扩展开去,看到就AI支持——包括生成式AI的支持,Intel的底层硬件实则涵盖了前文谈到的酷睿、至强CPU,Arc GPU,以及面向数据中心的Flex GPU,还有下文会谈到的Max(Ponte Vecchio);和峰会上被多次提及的AI芯片Habana Gaudi2——特别面向中国市场的,以及在Intel XPU策略版图中的FPGA等芯片类型。
这些芯片构成了Intel整个AI王国的算力底座。据说目前主流的LLM都已经能够跑在Intel的GPU上了,“下一步我们要聚焦到性能的提高上。”田新民说。李映(英特尔公司副总裁、英特尔中国软件生态事业部总经理)还明确提到不同处理器面向不同应用,比如说“Arc可能更多集中在汽车、客户端上,数据中心我们有Max系列,还有前一段时间刚刚发布的AI加速器Gaudi2”,“根据模型本身的特点,以及部署环境,找到最适合的选择”。
那么Intel作为一家传统意义上的芯片企业,用于AI的芯片产品线布局就已经相对完备了。而且要说算力水平,Intel对于Gaudi2的宣传(与Ampere架构GPU的对比,如上图)是前些日子还挺热门的新闻,不需要我们多做赘述。但实际上,基于我们对英伟达AI基础设施的了解,硬件基础设施层面光有芯片、板卡也还是不行的。尤其当AI算力需要做规模化扩展,或者说要上升到大语言模型training时,封装、互联、networking之类的问题都需要去解决。
“在Gaudi2之前,已经有了Gaudi1。目前Gaudi1已经应用到了AWS上。这块的工作Intel一直在进行中,包括和我们的很多合作伙伴,像浪潮、华勤等。生态这块我们始终是很有信心的。”戴金权说。不知道是英伟达太过擅长做包括互联、networking在内基础设施技术的营销,还是Intel在这方面太低调或成效不显——也可能和Intel在HPC AI生态上,现阶段选择了更开放的标准和技术有关,所以我们就不大能听得到这方面更具体的商业宣传概念。
从包含系统、互联的大规模集群层面要看Intel的实力,不有个现成的Aurora超算吗?今年ISC上,Intel更新了Aurora的更多信息——这是个ExaFLOPS算力级别的超算系统。
当真正上升到HPC AI
既然是AI everywhere,那也不能光是端侧和边缘侧的everywhere——核心部分真正的HPC AI,或者起码也是SuperPOD互联、跨节点的大规模集群,才是Intel这种在高性能计算市场摸爬滚打多年应该展示的水平。
Aurora是Intel和HPE Cray设计,为美国阿贡国家实验室准备的。既然是国家实验室,应用无外乎数据分析、AI、模拟仿真之类——戴金权在主题演讲中提到针对不同科学领域,跑在Aurora系统上的,“我们构建达到万亿级别数量级参数规模的大模型,构建面向科学领域的生成式AI大模型”。
“万亿”级别参数是个什么概念呢?现在很火的GPT-4也在这个参数量级水平上。所以Aurora应该是这个时代下,Intel亲自捉刀最具代表性的HPC系统了。这里特别谈到Aurora,也是因为田新民在学术峰会上花了较多篇幅去谈Aurora——虽然其实主要是软件,包括编程模型等。这应该表明Aurora是Intel当前产业应用的HPC前沿代表了。
目前我们所知有关Aurora系统的相关数据包括,总重量600吨,使用光缆总长度300英里,占地面积10000平方英尺,230PB DAOS存储,以及ExaFLOPS级别算力。感觉这些数字对一般人还是挺抽象的。从系统构成来看,Aurora总共10624个节点,每个节点2颗CPU——即总共21248颗CPU;而GPU Max配了63744张,也就是每个节点6张显卡。有兴趣的同学可以将其与英伟达前不久刚刚发布的GH200完整系统做个对比。

其他参数看上面这张图,包括存储容量、互联带宽等。因为时间关系,目前我们还无法完全理清这套系统所用的互联技术、存储技术,及可能存在的系统瓶颈;或者说当它和竞品的超算系统比较,尤其是如果考虑生成式AI这种对存储与带宽有极高需求,甚至要求networking交换系统都做重新设计的应用场景下,Aurora的系统构建方式有没有特别的创新。
无论如何,Aurora的存在,及Intel官方给出的应用示例(包括"clean fusion", "catalysts research", 神经科学研究之类的)都表明Intel在这种能给普通人秀肌肉的HPC场景也并未懈怠。
这里我们比较关心的,戴金权所说达到万亿量级参数的生成式AI模型叫genAI——也是Intel在ISC23上提到的。Aurora genAI模型基础是Megatron和DeepSpeed。genAI模型会基于通用文本、科学文本、科学数据和相关领域的代码做训练,所以就是个纯粹科学向的生成式AI,潜在应用领域涵盖了癌症研究、气候科学、宇宙学、系统生物学、聚合物化学与材料等。

Aurora当然并非Intel于HPC、AI领域的唯一产品或方案,这部分主要给了解HPC、超算系统的读者提供个参考和索引。
其实由这个系统展开去,田新民谈到了挺多Intel在AI上的研究和努力的。比如说GPU Max的memory hierarchy为什么做这样的设计,诸如L2 cache为什么设定在最大408MB...
“这些平衡性设计对我们来说没有理论依据,完全是基于大量application,通过很多模拟实验来决定memory hierarchy的设计,包括register file、L1 cache、L2 cache,什么样的ratio满足应用、系统需求,以及做各方面的平衡——die size、放多少晶体管进去,可靠性、功耗等。”
AI软件生态进度是这样...
现在去看每年英伟达GTC开发者大会,都会发现英伟达很早就开始说自己“不是一家芯片公司”这句话有多么正确;其实图形加速卡这种硬件的发展历史,由早年群雄割据进入到双寡头时代,最重要的一个原因就是GPU的逐步标准化和走向通用化,致使后来的GPU企业有了传说中“1硬件工程师 :10个软件工程师”的配比。
在企业规模日益扩大,而市场又容纳不下那么大的体量时,必然有一众参与者要退出,并最终走向市场的寡头化。这里面软件的地位一点都不比芯片和硬件低,或者在某些时候软件甚至更重要。
李映提到现如今Intel的转变,其中最大的就是“软件优先”的转变。这其实不光是因为Intel现如今的CEO、CTO都有软件背景,还在于Intel的XPU策略,面临的竞争对手是异常彪悍,而且在软件生态方面的建设完善度令人咋舌的存在。
软件部分我们不打算花太多笔墨去谈,这是现阶段Intel在芯片产品布局完备后,最需要努力的部分。这次Intel中国学术峰会,有两个关键点,还是令我们印象很深刻。
其一是BigDL-LLM,这是前文提及在轻薄本上跑生成式AI的关键要素——这个点虽然很具体,但应该能看到Intel发展AI的思路。BigDL-LLM是个开源的LLM推理库,面向LLM其一大职能就是简化在端侧PC上的LLM推理工作,“通过BigDL-LLM库,我们可以对跑在本地的各种LLM做优化和支持。”对主流的transformers模型做量化,降低本地硬件资源需求。“利用低精度比如INT4, INT3等进行高效的大规模推理”。

所以前文谈用酷睿CPU跑各种LLM,其实是BigDL-LLM的demo,真正展示的是Intel在软件方面的工作进度;包括用Arc GPU来跑ChatGLM2-6b——即便戴金权说这个demo目前所处的阶段还比较早期。“我们还有很大的进步空间,但现在的确是能够把Intel客户端XPU的能力都运用起来了。”加上社区标准API兼容,包括LangChain这种将多个模型工作流串起来的API支持,也都是为了简化开发、快速扩展生态。
据说Intel此前去上海交大做了个针对BigDL-LLM不到半天的培训,就有几名学生几天内依托租到的4核服务器instance,把基于ChatGLM的service搭起来了。“把AI大模型搬到轻薄本上,或者其他客户端、设备端的场景,我们还能做些什么?我觉得这是非常重要、可以探索的方向。”
换一个视角,除了开源和开放这条常规思路,Intel显然是期望依托自家CPU的广泛用户基础,来拓展自己的AI生态,而且听起来是十分有效的。接下来应该就是田新民所说的,要逐渐从支持大模型,转变为聚焦在性能提升上。所以才有了前后2个月的时间,Stable Diffusion在Intel轻薄本上推理性能的显著提升这回事——想必Intel的AI相关软件团队的加班,一点也不必图形卡驱动团队的加班少,更新都是如此紧凑密集...
其二是“开放战略”——这一点可能未必只是AI软件,甚至在涉及芯片、系统层面的标准,以及各类应用的工具、框架、库上都采用开放的思路。对外宣传自然是说技术创新和服务社区——包括几个月前成立的中国开源技术委员会,但其实就现阶段的Intel而言,这也是在我们看来要壮大生态的必行之策。Intel现在不大可能像英伟达那样打造一堆自有技术,构成完整、自洽、排他又环环相扣的生态。
比如说在AI应用开发不同阶段(如下图),Intel所布局的技术是尝试融入到各种开源框架里的。这对Intel现阶段的发展至关重要。

甚至原本仅针对自家不同XPU设备统一编程的oneAPI,现在倡导为用户在不同硬件环境、不同厂商架构中,在同一编程模型上,提供支持。田新民说在oneAPI最初设计理念的基础上,“要让oneAPI有很强的可扩展性,不只是针对Intel的硬件架构,也包括非Intel的硬件架构”:Intel新收购的Codeplay不就有oneAPI for CUDA这种让开发者能用oneAPI面向Intel和英伟达处理器,使用统一的工具链来开发么...
从面向媒体的沟通来看,Intel现在也开始主动去谈软件了,这其实是个非常积极的转变——因为现在Intel最缺的大概就是这一部分,至少在AI领域相比英伟达是这样。不过我们觉得,谈得还是不够——要知道英伟达针对不同软件工具、库的宣传和市场概念之丰富,绝对会让人感觉什么Ampere, Hopper都不过是配角。
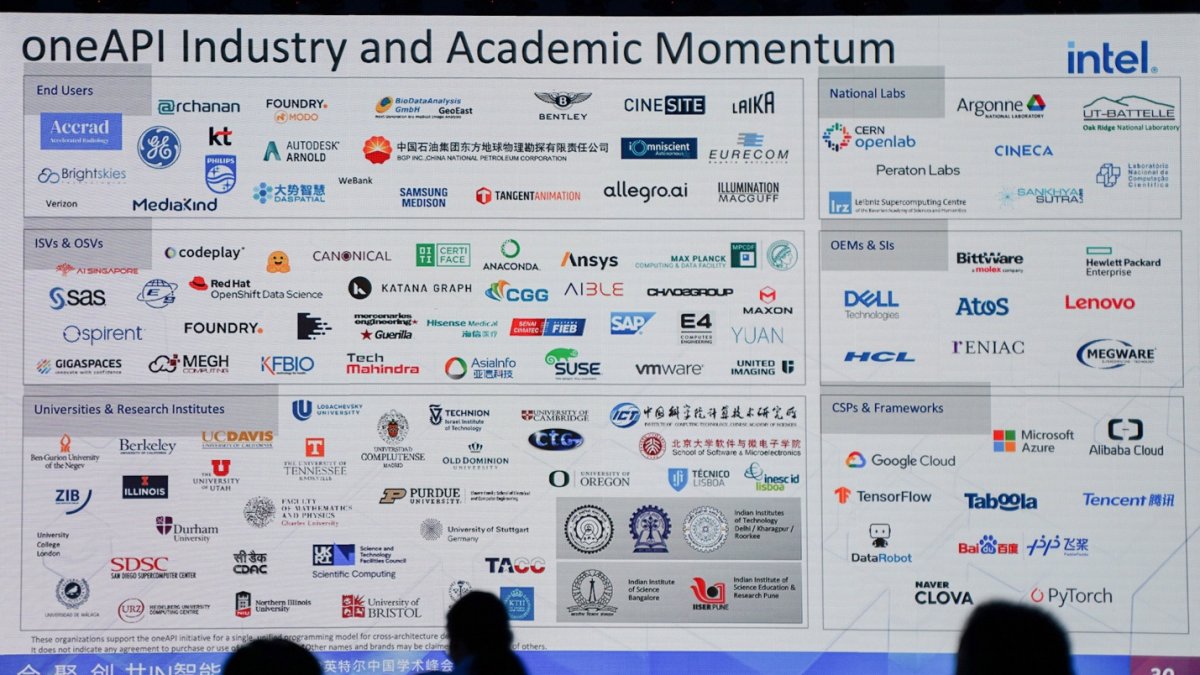
还是很高兴听到,田新民在谈oneAPI时最后一张PPT展示了oneAPI的现状(下图),“通过几年的努力,包括我们和工业界、学术界、国家实验室、服务供应商、云服务提供商、终端用户等等角色的合作,现在已经初具规模了”。“初具规模”这个评价在我们看来真的是相当贴切,内里饱含的既有成果的来之不易,也有对未来生态发展潜力的期待。

最后给一张Intel的端到端AI pipeline,一方面助于理清Intel不同产品所处的位置,包括前文提到的BigDL、OpenVINO、oneAPI,以及各类芯片产品。虽说就一期学术峰会,我们还是很难把这家公司的AI布局全貌给搞清楚,但显然Intel的这张蓝图正变得越来越清晰,AI各方面的工作开展也在有序进行。
