
电子工程专辑讯 此前小米公布2023Q1财报时,卢伟冰曾指出,小米不会像OpenAI公司那样去做通用大模型,会跟公司的业务相结合,通过技术转化为业务成果。小米对AI大模型的态度也是持开放状态,有可能引进第三方来帮助发展。
近日,小米来自大模型评测平台的C-Eval、CMMLU的数据评分被曝光,引发谈论。AI概念这段时间的“风声”很大,小米偷偷发力AI大模型的进展到什么程度了?
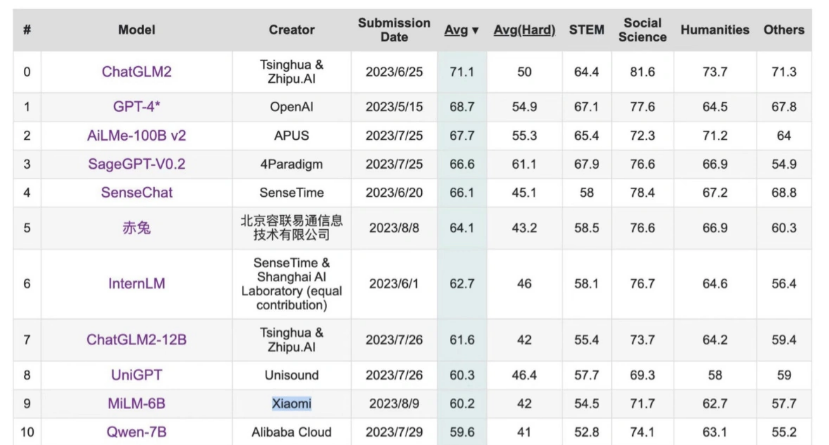
小米在Github是这样介绍MiLM-6B:MiLM-6B是由小米开发的一个大规模预训练语言模型,参数规模为64亿。在 C-Eval 和 CMMLU 上均取得同尺寸最好的效果。
在得分方面,在C-Eval评估中,MiLM-6B 的平均分为60.2,总榜单排名第10、同参数量级排名第 1。在CMMLU评估中,MiLM-6B在Five-shot和Zero-shot 测试中的平均分分别为57.17和60.37。
根据 C-Eval 给出的信息,MiLM-6B 模型在具体各科目成绩上,在 STEM(科学、技术、工程和数学教育)全部 20 个科目中,计量师、物理、化学、生物等多个项目获得了较高的准确率。不过在“法学、数学、编程、概率论、离散数学”等涉及“抽象思维”的科目中,还有一定进步空间。在人文科学的 11 个科目中,MiLM-6B 则在“历史与法律”基础上有着不错的准确率表现。
“CMMLU”是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。CMMLU涵盖了从基础学科到高级专业水平的67个主题。它包括:需要计算和推理的自然科学,需要知识的人文科学和社会科学,以及需要生活常识的中国驾驶规则等。此外,CMMLU中的许多任务具有中国特定的答案,可能在其他地区或语言中并不普遍适用。因此是一个完全中国化的中文测试基准。
“C-Eval”是由上海交通大学、清华大学、爱丁堡大学共同构建的一个针对基础模型的综合中文评估套件。它由 13948 道多项选择题组成,涵盖 52 个不同学科和四个难度级别,覆盖人文、社科、理工,及其他专业四个大方向,用以帮助中文社区研发大模型。
据悉,目前小米在大模型团队方面的主力团队有30多人,按照人才、数据、模型、算力、评测、产品这几个方面进行筹备,不会扩张的太快。小米把“AI实验室”比喻成集团层面AI技术的“试验田”和“弹药库”,如果AI发展迅速,AI实验室会研发一些中长期的前沿技术,围绕小米业务做储备,在集团需要的时候输出“弹药”。
AI的发展速度究竟会有多快或者多慢,其实很难评判。就比如OpenAI推出的ChatGPT,一夜之间就让沉淀的AI技术发生井喷式发展,但现在AI技术还在找一个能真正落地的应用场景。小米的大模型也将在未来丰富其业务发展,比如小米的小爱同学、手机操作系统MIUI、汽车的座舱、IoT、机器人,都是应用大模型的典型场景。
而且小米现在研发的AI大模型也是有侧重点的,更多侧重在语言大模型上,去丰富提升小爱同学的理解能力、智能家居指令的识别能力等。至于通过大模型来实现智能家居的自动组网、个性化的家居体验,至少小米AI实验室没有在做。
