
在日前召开的第五届智源大会AI系统分论坛上,上海天数智芯半导体有限公司正式宣布其天垓100加速卡的算力集群,基于北京智源人工智能研究院70亿参数的Aquila语言基础模型,使用代码数据进行继续训练,稳定运行19天,模型收敛效果符合预期,证明天数智芯有支持百亿级参数大模型训练的能力。
全功能GPU成AI大模型应用关键
天数智芯产品线总裁邹翾认为,目前来看,尽管国内企业与美国顶级厂商的产品性能之间仍存在不小的差距,尤其是在旗舰级产品性能方面,加之品牌知名度也不够,还需要逐渐培养下游企业对于本土GPU企业的认知。但好在国内产品是可用的,实现了国产通用GPU产品从0到1的突破。
据介绍,在北京市海淀区的大力支持下,智源研究院、天数智芯与爱特云翔共同合作,联手开展基于自主通用GPU的大模型CodeGen(高效编码)项目,通过中文描述来生成可用的C、Java、Python代码以实现高效编码。智源研究院负责算法设计、训练框架开发、大模型的训练与调优,天数智芯负责提供天垓100加速卡、构建算力集群及全程技术支持,爱特云翔负责提供算存网基础硬件及智能化运维服务。
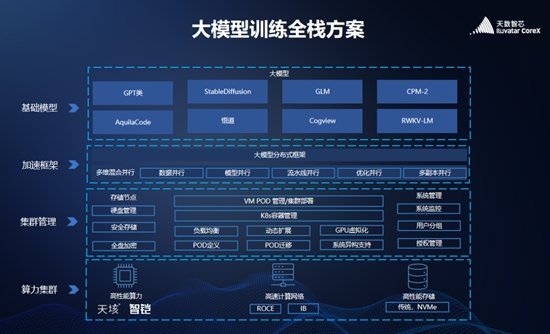
天数智芯大模型训练全栈方案
在三方的共同努力下,在基于天垓100加速卡的算力集群上,100B Tokens编程语料、70亿参数量的AquilaCode大模型参数优化工作结果显示,1个Epoch后loss下降到0.8,训练速度达到87K Tokens/s,线性加速比高达95%以上。与国际主流的A100加速卡集群相比,天垓100加速卡集群的收敛效果、训练速度、线性加速比相当,稳定性更优。在HumanEval基准数据集上,以Pass@1作为评估指标,自主算力集群训练出来的模型测试结果达到相近参数级别大模型的SOAT水平,在AI编程能力与国际主流GPU产品训练结果相近。
基于天垓100算力集群的AquilaCode大模型训练性能采样
“天垓100率先完成百亿级参数大模型训练,迈出了自主通用GPU大模型应用的重要的一步。”邹翾表示,这一成果充分证明了天垓产品可以支持大模型训练,打通了国内大模型创新发展的关键“堵点”,对于我国大模型自主生态建设、产业链安全保障具有十分重大的意义。
他希望国产通用GPU接下来“能用5-10年左右的时间追赶上国际同类主流产品的性能”,并且在人工智能、元宇宙、科学计算、天气预报、分子动力学、股票量化交易、投资等多个赛道取得成绩。
算力缺口巨大
ChatGPT等AI产品的火爆,不仅带来了短期的巨大算力缺口,也将持续带来并行化的通用计算需求。邹翾表示,当前,企业开发大模型的竞争焦点在于挖掘大模型的更多能力,实现这一目标需要算力的堆积,以提升大模型的参数值。此外,随着科学计算、AI建模的不断发展,市场对算力的需求也将显著扩大。
相关资料显示,对头部企业来说,早期的GPT3大模型大概需要1万张英伟达GPU,但GPT4达到了100万亿的参数规模,可能就需要3-5万张最先进的GPU才能完成。对于这一领域出现的众多跟随者来说,势必要在算力上不能输于头部企业,甚至还要进行更多的算力基础设施投资才能实现追赶。
因此,本土GPU企业要抓住AI大模型兴起的产业机遇,需要从底层定位大模型的算力需求。邹翾表示,从模型、计算框架层和算子加速等维度出发,通用GPU的优势在于“通用”—可支持模型的快速变形、快速支持新算子、快速支持新通信;“易用”—可利用现有算法模块,对新的重组架构进行调优;“好用”—可重构并行计算、访存全交换、计算全互联等。
同时,面对未来大规模的计算工作量需要通过组合多个GPU来完成任务的趋势,邹翾认为“相比提升单张GPU卡的性能,如何提高效率和管理能力,减少成本的同时实现节能减排”,更为关键,毕竟这其中要涉及散热/功耗管理、多通信模式支持、算法调优等多个要素。他强调称,“真正的平衡实际上是基于具体应用和对应的架构设计,并非性能参数越高越好。”
在谈及关于“大模型参数规模不断上调”话题时,邹翾说他个人还有点不一样的看法:一是现在业界还没有把大模型的性能潜力全部挖掘出来,现在的大模型只是一个起点,头部企业希望能够率先抓住那些没有被发现的能力制高点,于是不断调高通用大模型的参数以开发新功能;二是随着大模型的不断迭代,最终不可能有那么多的算力投资都真正产生效益,他个人判断未来1-2年内,当前许多重复性的投资会看到一个收敛稳定的阈值。
中外用户的需求差异
邹翾讨论了中国客户和海外客户在需求和使用习惯上的差异,认为中国市场上大多数客户仍然以“快”为主,“拿来主义”之风比较盛行,在软件和应用模式方面缺乏独立创新。“对于硬件企业来说,一个难点在于如果用户不愿意自己尝试做一些原生性的创新,那我们就很难在体系支撑角度去提供创新,因为我企业的需求首先是要看客户需要什么。”
但中国在应用场景上有着自己独特的优势,很多国内头部企业也正在思考如何让大模型更好的使用起来,创造出类似“新四大发明”的独特应用,实现原生技术的通用性。因此,底层技术与市场差异化的融合将成为关键,需要更多工程师、更多的创新、甚至是国家的机制引领,来共同推动全国产化进程。
他同时也对“大公司不愿意采用国产GPU”这样的说法做出了回应,认为公众“对这句话解读是存在一定偏差的”。一方面,大公司没有说一定不会使用,只是现在国内的大多数算力平台并不符合大模型的要求;另一方面,商业化算力芯片产品在使用过程中,性价比也确实要能实际达到英伟达的水平才行。只有这样,头部的大公司才能获得真正的商业价值,毕竟他们面临着算力、安全、联合调优等多维度的挑战。
“对于天数智芯而言,我们并不追求在每个赛道上都和国际顶尖产品拥有同样的水平。可以考虑先从某一方面入手,通过产品性能和服务水平,吸引更多本土客户与我们合作。然后再‘由点及面’,最终目标在于如何服务好本土客户。“邹翾说,在服务本土客户方面可以主要从两方面入手,一是为头部大模型企业做算力补充;二是微调,即在模型训练好后再根据领域数据做一次微调优化,以实现算力的推理功能。为此,算法研究和模型结构、工程化实践落地与应用创新,将成为天数智芯接下来最为关注的三大领域。

