
人工智能和机器学习(AI/ML)提供了无与伦比的识别复杂模式和快速做出决策的能力。因此,许多公司正在迅速将AI/ML推理功能添加到各种产品中。
所提供的AI/ML功能,可以将其集成到系统级芯片(SoC)中,也可以作为独立的硬件AI/ML加速器。这些芯片市场越来越拥挤,尤其是嵌入式产品。
在选择AI/ML实现技术时,工程师会面临看上去可能令人应接不暇的一系列广泛选择。其中,可以在未增强的微处理器或微控制器上运行AI/ML模型。采用这种方案时,性能较差,且效率也比较低,不过,大多数处理器供应商都支持在其处理器上利用软件库来运行AI/ML模型的方法,而这些软件库都接受一些标准AI/ML开发工具中自带的模型。
另外,工程师还可以获得专门为非增强处理器ISAs开发的AI/ML工具。例如,为微控制器开发的Tensorflow Lite,是专门为集成Arm Cortex-M处理器内核的微控制器和SoC开发的。该工具用C++编写,已经成功移植到了其他处理器架构中。
然而,如果处理器没有专门用于AI/ML任务的硬件,其速度会很慢,且效率也比较低,因为运行AI/ML模型需要大量的乘法和加法运算。因此,通常应该使用向量或张量硬件来获得良好的性能。包括意法半导体、瑞萨、恩智浦和XMOS在内的许多微控制器中,都添加了支持AI/ML模型执行的硬件,以提高处理器的AI/ML性能。
另一种可利用的方法是在处理器SoC中添加一个DSP,用作AI/ML协处理器。这类解决方案方案的确可以提高AI/ML性能,不过,由于乘法器/累加器(MAC)的数量有限,性能的提高仍然会受到限制。
如果增强型处理器仍然不足以达到所需性能和功率要求,那么还有其他选择。GPU和FPGA也已用于AI/ML任务,不过由于其功耗相对较高,通常这些方案只适用于数据中心的训练和推理,而不适合边缘推理。
还可以利用专用神经处理器(NPU)和NPU IP。这类处理器利用MAC阵列和微调网络在MAC之间传递数据,如今已有30多家公司能够提供。这些器件提供不同级别的性能和功率效率,比带有AI/ML指令的微处理器和微控制器更好。然而,采用NPU这类的新架构,需要学习曲线。
MemryX解决方案
MemryX作为一个新的市场参与者,利用一种不同的AI/ML加速器来解决噪声问题。该公司的MX3 Edge AI Accelerator芯片,可以执行AI/ML模型,并且由于采用的是“at-memory”架构,从而无需访问外部DRAM。MemryX的设计方法,特别适合需要通过训练好的AI/ML模型来传递实时数据的嵌入式边缘设备。
MemryX认为,MX3的数据流架构最适合于对连续流数据进行AI/ML推理,这类连续流数据是由视频、安全摄像头和其他类型的传感器生成的连续数据。由于MX3的片上存储器存储了AI/ML模型所需的所有权重,并且不与主处理器共享运算,因此只有数据需要流入MemryX芯片,而输出的只有结果。故对于各种需要传递实时数据通过已训练的AI/ML模型的嵌入式边缘设备来说,这是最合适的正确工作模型。
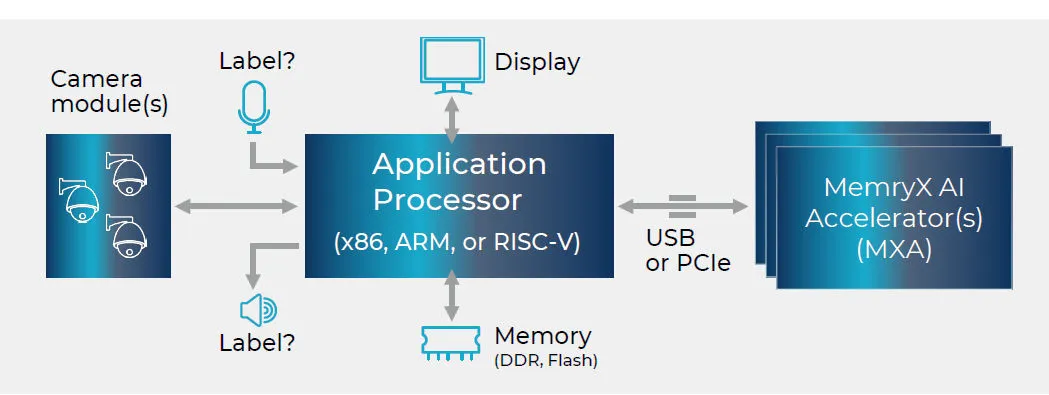
图1:MemoryX MX3应用程序示意图。(来源:MemoryX)
AI/ML芯片制造商喜欢讨论的事情之一是他们的model zoo。一个典型的zoo是许多已经适用于支持供应商独特的人工智能架构的AI/ML模型的集合。芯片供应商的model zoo规模,通常可根据公司的软件资源规模进行扩展,每个模型都必须进行修改和再训练。
MemryX有一个非典型的AI Model Zoo,经过一键编译后,MX3就可以执行经过训练的AI模型。由于已经验证了数百个直接从互联网上各种存储库中提取的经过训练的AI/ML模型,以及数百个直接来自客户和合作伙伴的私有模型,从而可以断言,该一键编译能自动生成50~80%的利用率。
MemryX MX3并不是一款独立的AI/ML器件。它旨在用作主CPU的配套芯片,通过PCIe或USB接口连接。这种方案相对容易,可方便地将该器件集成到新的或已有的硬件设计中。
如今,通常都会在某个地方留有备用端口。由于MX3加速器是独立的,不需要外部存储器,因此在设备的硬件设计中添加AI/ML模型处理能力,并不比在现有CPU和MX3加速器之间提供端口连接更复杂。
每颗MemryX MX3加速器芯片增加了大约5 TFLOPS(每秒万亿次浮点运算)的AI/ML处理性能。该器件内部使用bfloat16格式数据进行激活,并逐层选择4位、8位或16位整数作为权重。MX3器件设计为菊花链状,并且采用的是“at memory”以及数据流架构,故其处理能力可随着添加的芯片数量而线性扩展。
因此,2器件阵列的MX3加速器可提供10 TFLOPS,4器件阵列则可提供20 TFLOPS。通常每颗MX3器件的功耗约为1瓦,如果配上MX3的片上权重存储器,则可以同时实现多个AI/ML模型。此外,在进出MX3加速器时,可以实现模型交换,这一过程所需的时间还不到10毫秒。
MX3开发流程使用一键编译方案,接受来自所有流行的AI/ML开发框架的训练模型,包括PyTorch、ONNX、Tensorflow、Tensorflow Lite和Keras等。当然,像MX3这样具有数据流定向功能的加速器,可以与基于任何架构(Arm、x86、RISC-V等)的任何微处理器或微控制器兼容,并且也独立于操作系统,故处理器也很方便地为MX3提供配置文件和数据。上述所有这些特性,使MX3加速器非常适合那些希望在设计中添加AI/ML、而又不至于引起太大麻烦的设计团队。
(参考原文:Adding Low-Power AI/ML Inference to Edge Devices)
本文为《电子工程专辑》2023年7月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订阅
