
由瑞士苏黎世联邦理工学院(ETH Zurich)和博洛尼亚大学的工程师团队联合开发的 Occamy 处理器已接近完成。这颗芯片在2021年4月20日开始研发,2022年7月基于GlobalFoundries 12nm FinFET技术流片成功,同年10月采用GlobalFoundries 65nm Hedwig无源硅中介层进行流片。这两次流片都得到了Fraunhofer IIS的Europractice-IC团队支持。
据悉, Occamy 团队成员只有不到25人,其中大部分是博士生。
目前已知的一些芯片特性
据悉该芯片属于并行超低功耗 (PULP) 平台项目,包含两个计算单元(CPU),每个采用了 216 个 32 位 RISC-V 内核的 Chiplet设计、未知数量的 64 位浮点单元 (FPU),以及两颗来自美光的 16GB HBM2E 内存。这颗处理器的内核通过中介层实现互连,双块 CPU 估计峰值性能为: FP64 时达到 0.768 TFLOp/s,在 FP32 时达到 1.536 TFLOp/s,在 FP16 时达到 3.072 TFLOp/s,在 FP8 精度时达到 6.144 TFLOp/s。

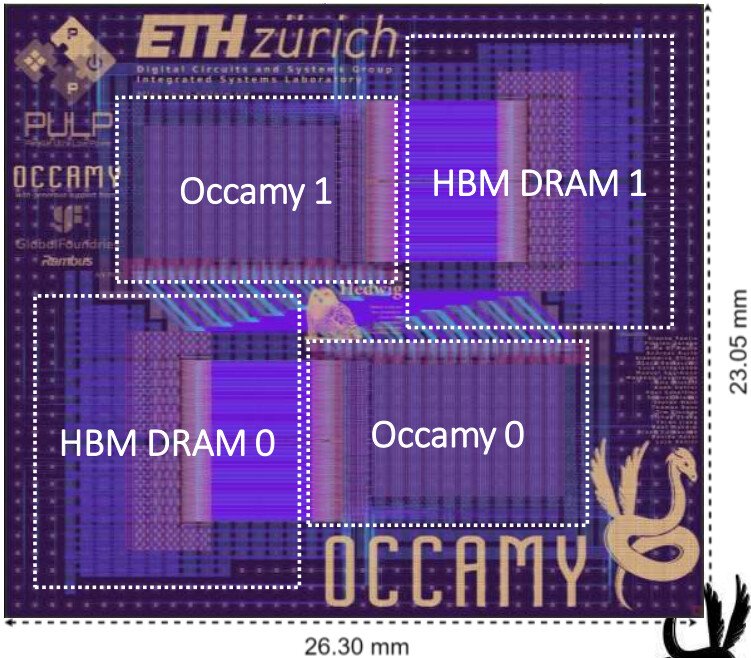
65纳米无源硅中阶层Hedwig配备两个Occamy计算Chiplet,每个芯片都有来自美光的专用16GB HBM2e DRAM和用于芯片间通信的die-to-die接口
在该芯片中,研发人员将名为 Snitch 的小型超高效有序 32 位 RISC-V 整数内核,与通过单指令多数据 (SIMD) 增强的大型多精度 FPU相结合,实现以下 FP 格式的功能:FP64 (11,52)、FP32 (8,23)、FP16 (5,10)、FP16alt (8,7)、FP8 (5,2)、FP8alt (4,3)。 除了标准的 RISC-V 融合乘法累加 (FMA) 指令外,两种 8 位和两种 16 位 FP 格式还具有新的扩展和点积和三加数求和(exsdotp、exvsum 和 vsum ) 指令。
为了在数据并行 FP 工作负载上实现超高效计算,研发人员利用了两个自定义架构扩展:数据可预取寄存器文件条目和重复缓冲区。 相应的 RISC-V ISA 扩展流语义寄存器 (SSR) 和 FP 重复指令 (FREP) 使 Snitch 内核能够为计算绑定内核实现高于 90% 的 FPU 利用率。
据悉该团队还设计了新的扩展,用于提高稀疏数据结构和模版的效率,这些扩展将在不久的将来提供。

每个 Occamy 每颗Chiplet包含超过 216 个 Snitch 内核,这些内核以四个计算集群为一组进行组织。 每个集群在八个计算内核和一个高带宽(512 位)DMA 增强内核之间共享一个紧密耦合的内存,用于编排数据流。 基于 AXI 的宽多级互连和专用 DMA 引擎有助于管理巨大的片上带宽。 支持 CVA6 Linux 的 RISC-V 核心管理所有计算集群和系统外围设备。 每个Chiplet都有一个专用的 16GB 高带宽内存 (HBM2e),并且可以通过 19.5 GB/s 宽、源同步技术独立的die-to-die DDR 链路与相邻的Chiplet进行通信。

Occamy包括6组4个计算集群,host CVA6,来自Rambus的HBM2e控制器IP,以及一个源同步串行DDR die-to-die链接
Occamy 是一款用于 AI 和高性能计算工作负载的低功耗芯片,其轻量级的 32 位 CPU 核心更像是一个控制芯片,负责将任务重新路由到 AI 核心。今天的 AI 工作负载在很大程度上依赖于 GPU 和 AI 核心等加速器来进行训练和推理,研究人员希望开源芯片也可以用于太空中的 AI 工作负载。
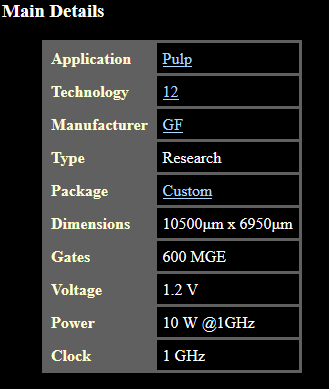
单个 Occamy 芯片以 1GHz 的频滤运行时功耗是 10 瓦,因此两个芯片加上 HBM 内存会使最终芯片的功耗增加一倍以上。Occamy 的具体功耗没有被透露,据悉团队正在等待合作伙伴Fraunhofer IZM将芯片组装进系统,预计很快就可以收集(和公布)测量到的相关数据。
无心插柳的Chiplet设计
这款 432 核芯片是新旧技术的有趣结合,当下热门的Chiplet设计优点之一是允许在芯片封装内混合和匹配新旧技术,例如模拟或数字处理器,后续还可以在封装中添加其他功能模块,以便在需要时加速某些工作负载。每颗 Occamy 芯片中都有 216 个 RISC-V 内核和用于矩阵计算的 FPU,这颗尺寸72mm2 的小小芯片上总计大约分布了 10 亿晶体管,与英特尔 2011 年制造的四核 Sandy Bridge 芯片大致相同(大三倍)。
苏黎世联邦理工学院Occamy 团队表示,该项目最初是其在 2020 年 Hot Chips 会议上提出的 Manticore 高性能架构概念的偶然成果。在会议之后,GlobalFoundries找到了PULP平台团队,提出了将概念架构转化为真正的硅设计的令人兴奋的建议。
目前的研究原型,用于展示和探索基于 RISC-V 的架构在 2.5D 集成Chiplet系统中的可扩展性、性能和效率。该项目由GlobalFoundries提供技术支持、专家建议、生态系统赋能和流片预算, Rambus提供HBM2e 控制器 IP 和集成支持, Micron提供HBM2e DRAM 供应和集成支持,新思科技(Synopsys)在EDA工具许可以及 Avery在HBM2e DRAM 验证模型上的支持使该项目成为可能。此外合作伙伴们也对该项目给予了资金上的支持。

作为对比,英特尔 Alder Lake 裸片尺寸为 163 mm2。就性能而言,英伟达 A30 GPU 具有 24GB HBM2 显存,可提供 5.2 FP64/10.3 FP64 的 Tensor TFLOPS 以及 330/660 (稀疏性) INT8 TOPS。
欧洲航天局看好的芯片
据公开资料显示,Occamy是 欧洲航天局(ESA) 正在考虑用于航天计算的众多芯片之一。他们制定了一个EuPilot 计划(European PILOT Project),旨在通过创建一套在欧洲设计、实施、制造和部署的自主加速器,交付第一个基于全欧洲开源和开放标准的软件和硬件集成 HPC 系统。 加速器将采用新的欧洲 Global Foundries 先进工艺技术制造,以展示欧洲技术的独立性。
EuPilot计划正在开发本土处理器以减少对专有 x86 和 Arm架构芯片的依赖,也在为超级计算机、人工智能、物联网和自动驾驶汽车开发自主可控芯片。
虽然此前很多报道称Occamy项目是针对太空项目开发的,但根据《电子工程专辑》从苏黎世联邦理工学院Occamy项目团队独家获悉,该团队并未为针对对太空探索等方案来设计这个项目,所以它不是作为EUPilot计划的一部分设计的。

不过ESA 对这些芯片很感兴趣,因为它将允许太空中的设备执行片上数据分析。虽然不能保证 ESA 会让该芯片投入太空运行,但它是正在探索用于航天计算的众多处理器之一。美国这边,NASA 也采用了 Microchip 和 SiFive 的 RISC-V 芯片来升级其航天计算机。
据介绍,Occamy 可以在 FPGA 上进行仿真运算,该实现已在两个 AMD Xilinx Virtex UltraScale+ HBM FPGA 和 Virtex UltraScale+ VCU1525 FPGA 上进行了测试。设计 Occamy 芯片的研究人员希望芯片设计能够被采用并被低成本地复用,衍生产品可能会在汽车、航空电子设备和太空中找到合适的应用场景。这些领域需要高性能和极高的能源效率,而RISC-V在这些领域中正迅速获得青睐。据悉该团队也在积极寻找在未来项目中与ESA 合作的方案。
