
AI技术越来越成熟,应用越来越广泛。但是训练AI模型需要大量的算力,这对芯片提出了不少的挑战,而在芯片内部,不仅仅存在着性能提升的瓶颈,同时还存在内存访问的大瓶颈,这方面,国际国内各大公司在多年的技术研发过程中不断的进行着探索与研发。发现3D Stacked DRAM存算芯片或许是目前最高效的技术。
在2023中国IC领袖峰会上,视海芯图创始人许达文博士以“DRAM存算芯片,引领AI大模型算力革命”介绍了存算芯片的技术演变和产品研发等情况。

许达文博士,毕业于中国科学院计算技术研究所,期间赴加州大学圣芭芭拉分校(UCSB)博士联合培养。归国之后,分别在AMD中国研究院工作和高校任教,曾主持和负责国家自然科学基金项目,在Transaction on Computers, TCAD, TVLSI、ICCD、ICCAD等顶级期刊和会议发表多篇论文,具备多次AI流片经验与创业经验,曾从事指纹芯片工作,次年销售额即达到两千万元,获昆山市创业领军人才,19年退出后指纹芯片公司,之后创办视海芯图。
许达文博士分三个部分介绍了存算芯片方面的市场和技术:大模型对现有芯片的挑战、DRAM PIM和PNM历史以及GPT芯片设计和应用。
大模型对现有芯片的挑战
从AI发展与受限制的硬件趋势看到,AI模型每2-3年规模增长1个数量级以上,芯片峰值算力平均每两年提升3倍,落后于AI模型的发展,然而,内存性能方面落后更多,平均每两年内存容量增长80%,在带宽方面提升40%,在延迟方面几乎不变。
从另一个角度看,单位算力所匹配的内存容量以及带宽和延迟是什么样的情况呢?
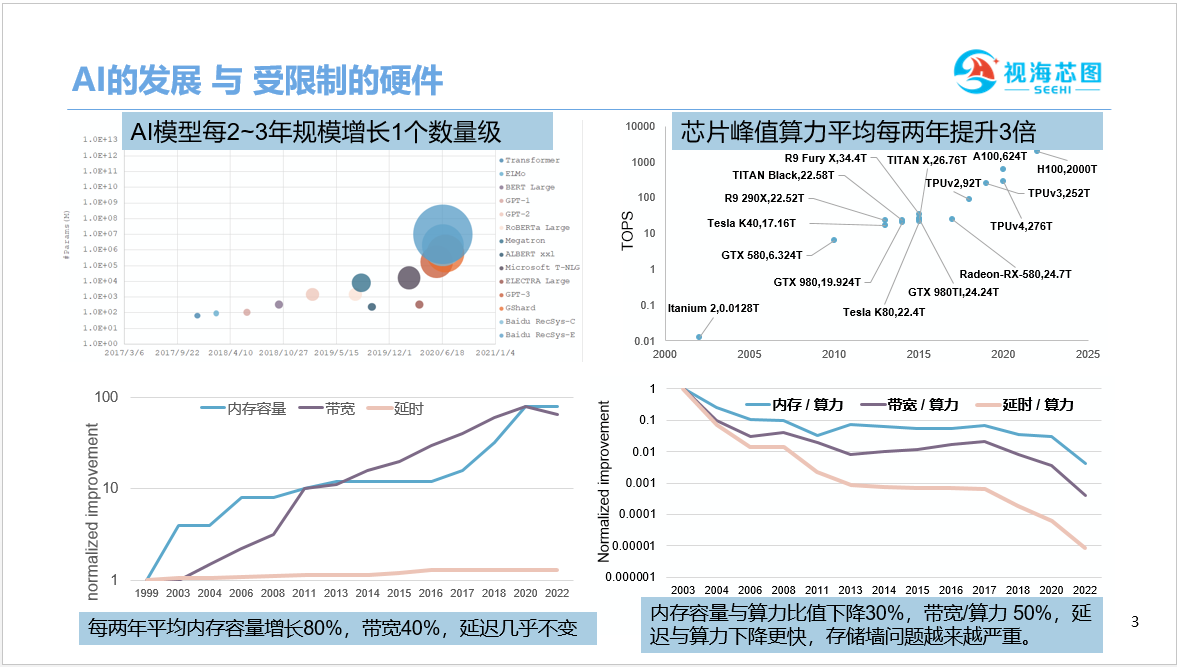
我们可以看到下降越来越严重,换句话说,存储管墙的问题也越来越严重。
目前火爆的GPT4的模型,(OPENAI)号称,其能力在很多方面已经超过90%人类,而且还在不断迭代增强,它也是目前最受欢迎的AI程序,用户数量飞速增长。同样值得注意的是,GPT计算需要消耗的资源非常庞大。
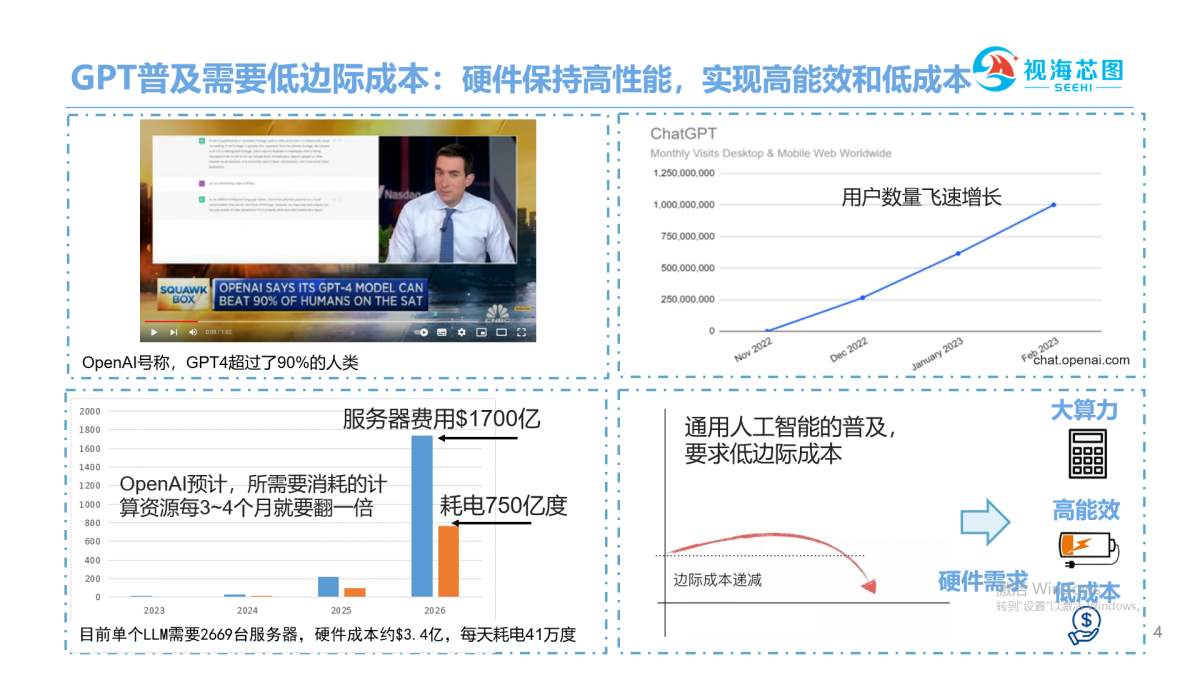
单个模型需要2600多个服务器,换算成经费大概是3.4亿美金,耗电量是每天大概41万度,OpenAI预计随着模型迭代,计算资源每三四个月要翻倍,也就是到2026年服务器费用每年需要1700亿美金,耗电量需要750亿度,这个消耗量是巨大的,特别是随着通用AI的普及,我们需要特别低的边际成本,越是基础模型,越是得有接近于0的边际成本,这样才能保证通用AI的大规模应用,这就要求硬件在保持高算力的同时,还要实现高能效和低成本。
当前,芯片进入后摩尔时代,在水平方向上的集成密度发展已经放缓了,3D集成提升垂直方向上集成密度,目前AMD、GraphCore发展起来。
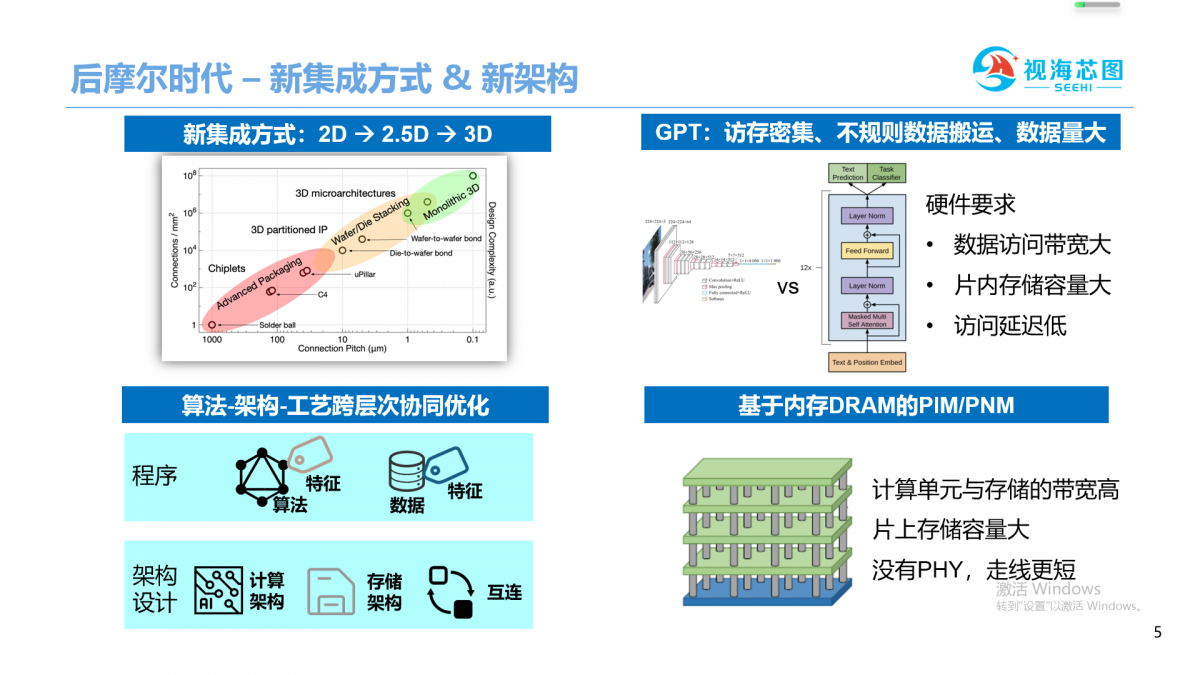
进入后摩尔时代,芯片水平方向晶体管scaling放缓,不过,3D集成工艺可以在垂直维度提升芯片密度,被AMD、GraphCore等纷纷采用。架构方面,分析算法和数据的特点,结合工艺,来设计芯片的计算、存储和互联,从算法、工艺和架构上进行跨层次协同优化,也成为了提升性能和能效比的重要方式。
与以CNN为主框架的模型不同,GPT的特点是:访存密集和数据搬运不规则的,数据复用不足,因此,GPT对硬件的内存带宽、片内存储容量,低延迟和运算并行性都有很高要求,DRAM存算的技术把DRAM与逻辑进行3D集成,可以为计算单元与存储提供超大带宽和大容量,还可以降低数据搬运,降低功耗,是加速GPT的不错选择。
DRAM PIM和PNM历史
接下来我们介绍一下DRAM 存算(存内计算和近存计算)的过往,相关技术包括几种,Processing-In-Memory存内计算,智能DIMM,HMC、HBM、3D-Stacked DRAM与逻辑。

Processing-In-Memory存内计算有两种方式,一种是存储颗粒里面,采用DRAM器件在存储阵列旁边构建一个逻辑电路,早在1992年多伦多大学就提出了Computational RAM,加速了卷积和Data Mining等程序,后来一个典型工作DIVA,它更进一步,把PIM芯片串联在一起并行工作。另一种同样是在DRAM颗粒内部,但是它是修改存储阵列Ambit & Compute DRAM是这方面工作代表,他们让每个bit存储单元具备存储和计算的功能,提高了硬件并行性,减低了数据搬运。但是,这两种方式都会存在一个问题,采用DRAM来构建逻辑运算,成本比较高,商业化目前来说不太成功。

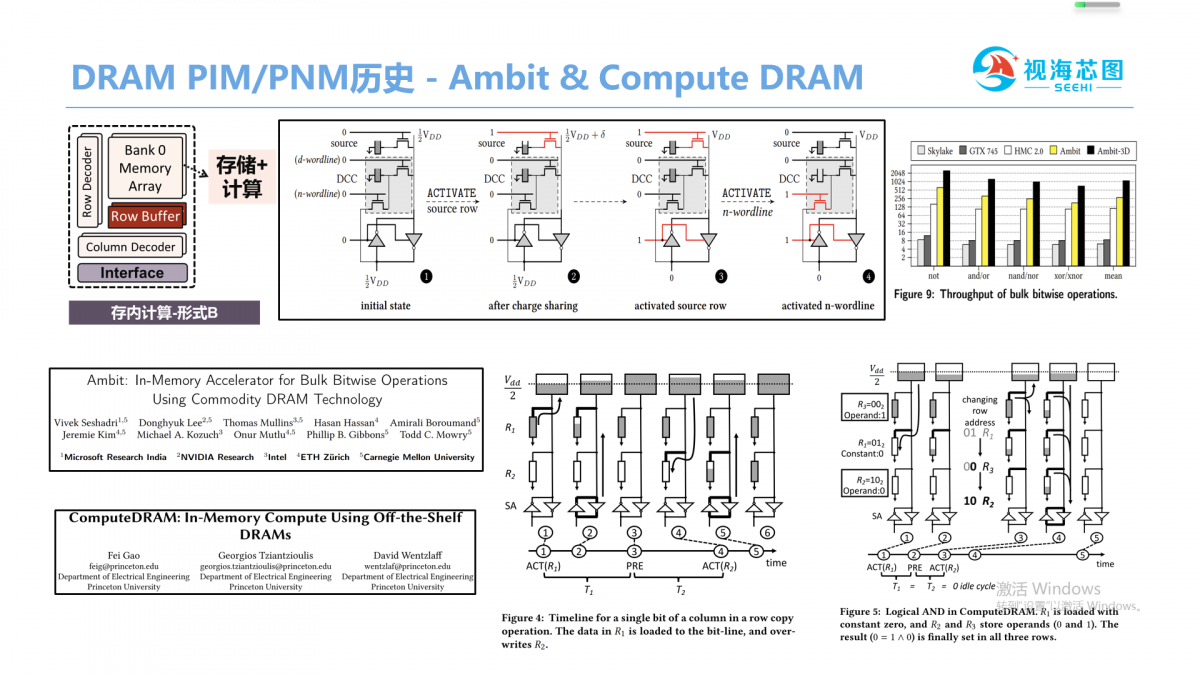
第二种是智能DIMM,在内存条上面放置一个运算电路,三星提出了AxDIMM,采用fpga来加速推荐系统的应用,facebook也有类似的工作RecNMP加速图神经网络。
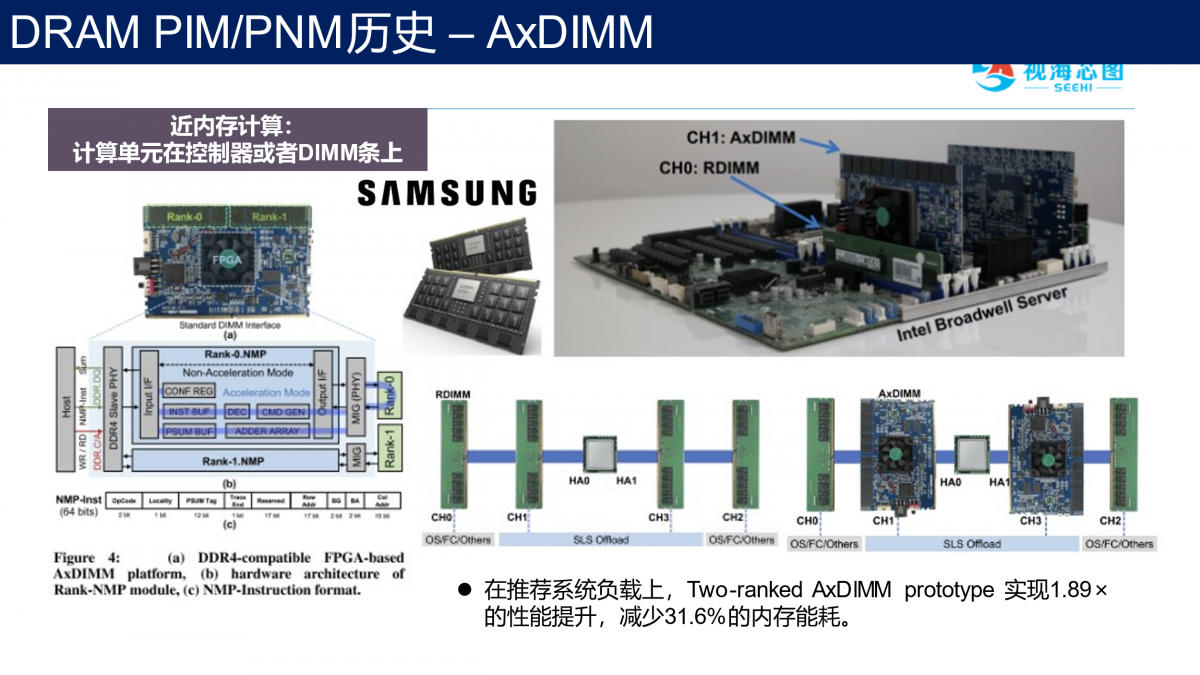
但是,这种方式存储的颗粒以及计算芯片是两个不同的芯片,他们被集成在一块PCB板上,通信之间的带宽还不够大,而且成本多增加了一个计算芯片,目前来说这也不是特别广泛。
2011年镁光提出了HMC技术。
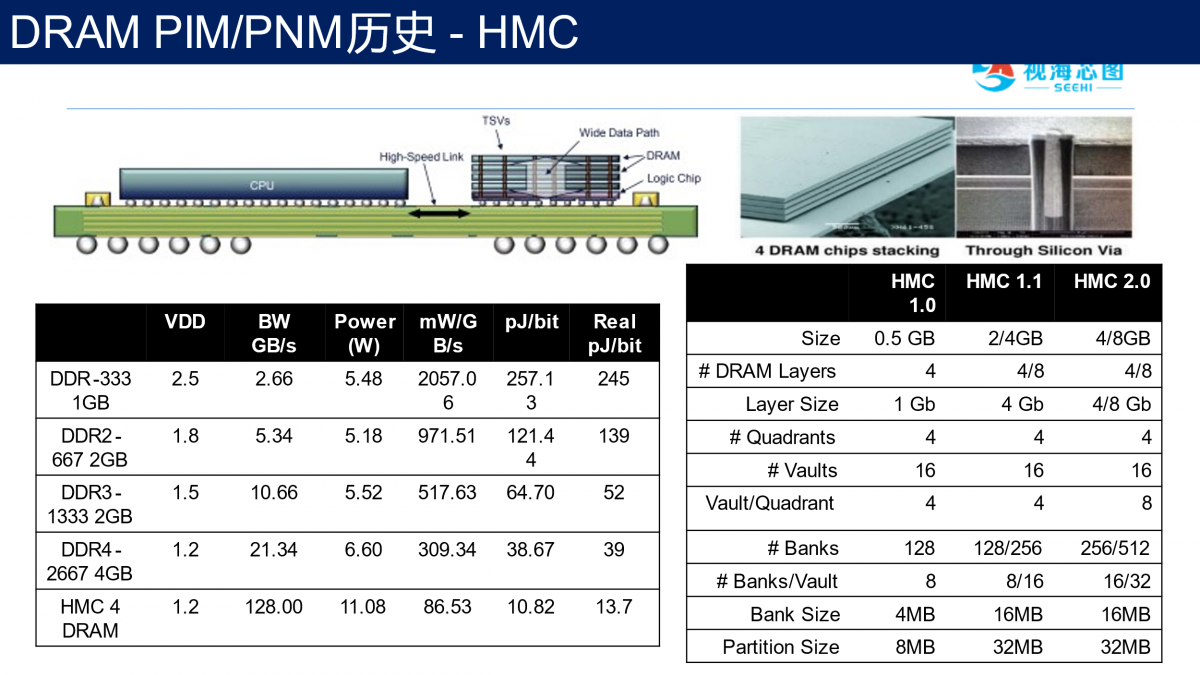
它把多个DRAM堆叠在一个逻辑芯片上面,构建HMC芯片,HMC芯片与处理器以serdes互连,HMC可以把内存容量和带宽做的比较大。HMC中逻辑芯片也可以完成一定的运算,曾有人用它完成了数据库的应用。问题是HMC颗粒与处理器是通过PCB板做互连,其实延迟还是比较高的,HMC能完成逻辑功能比较简单,不能很强大,还是会增加一些成本,最后镁光放弃了HMC技术。
HMC之后,三星推出HBM。

类似于HMC,HBM也把DRAM堆叠在逻辑芯片上面,不过,HBM存储颗粒与处理器更进一步做成2.5D集成,这种方式极大的缩短了存储颗粒与处理器之间的距离。它的好处是容量比较大,带宽也会比较高,功耗比HMC好很多,缺点是成本比较高,互连有一些限制,通常来说,一个处理器只能连4个HBM颗粒。
2022年,达摩院与紫光把25纳米DRAM堆叠在55纳米逻辑芯片上,构建了神经网络计算以及推荐系统里的匹配加速等。系统带宽达到1.38TBps,性能上,相比CPU版本,速度提升9倍,能效比超300倍。
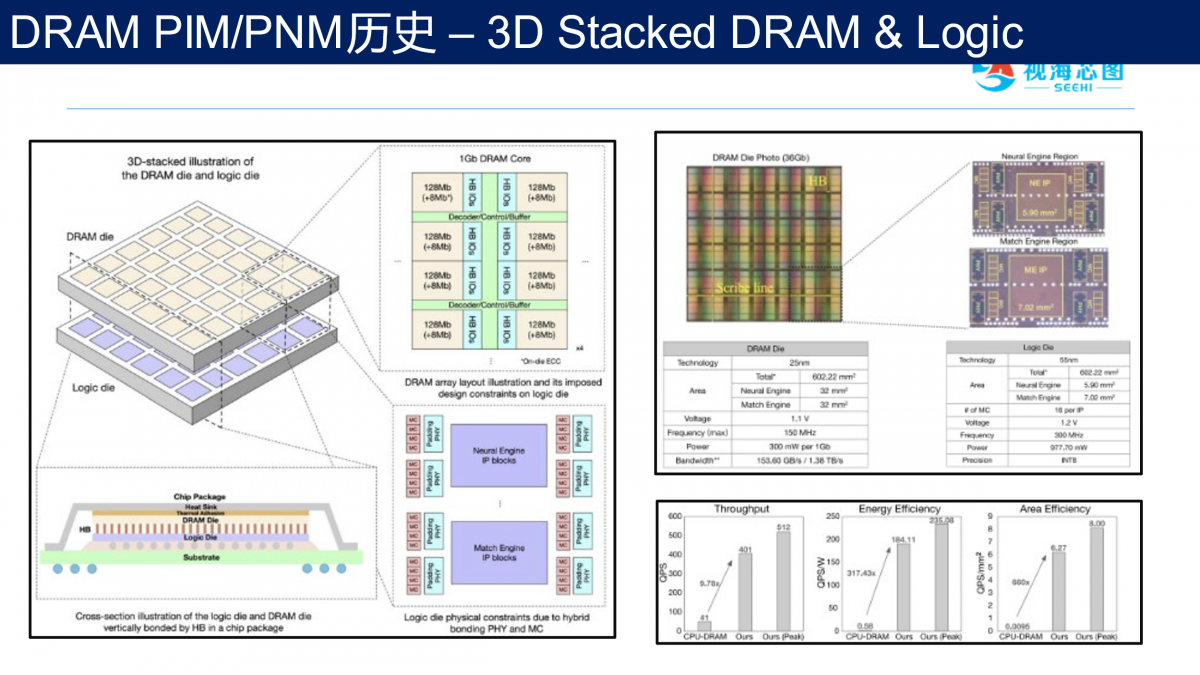
对比美中方式的特色和优缺点,可以认为3D堆叠技术已经成熟,国内企业已经具备成熟的实现方案。最近的杀手级应用,譬如Transformer,图计算,图数据库兴起对带宽延迟的刚性需求在兴起,或许预示着3D Stacked DRAM与逻辑的商业化时机已经到来。
GPT芯片设计和应用
由于3D DRAM延迟和带宽逼近于末级缓存,我们的策略是移除面积占比较大的末级缓存,让3D Stacked DRAM保证高带宽和低延迟,芯片会有更多晶体管来构建更多算力。
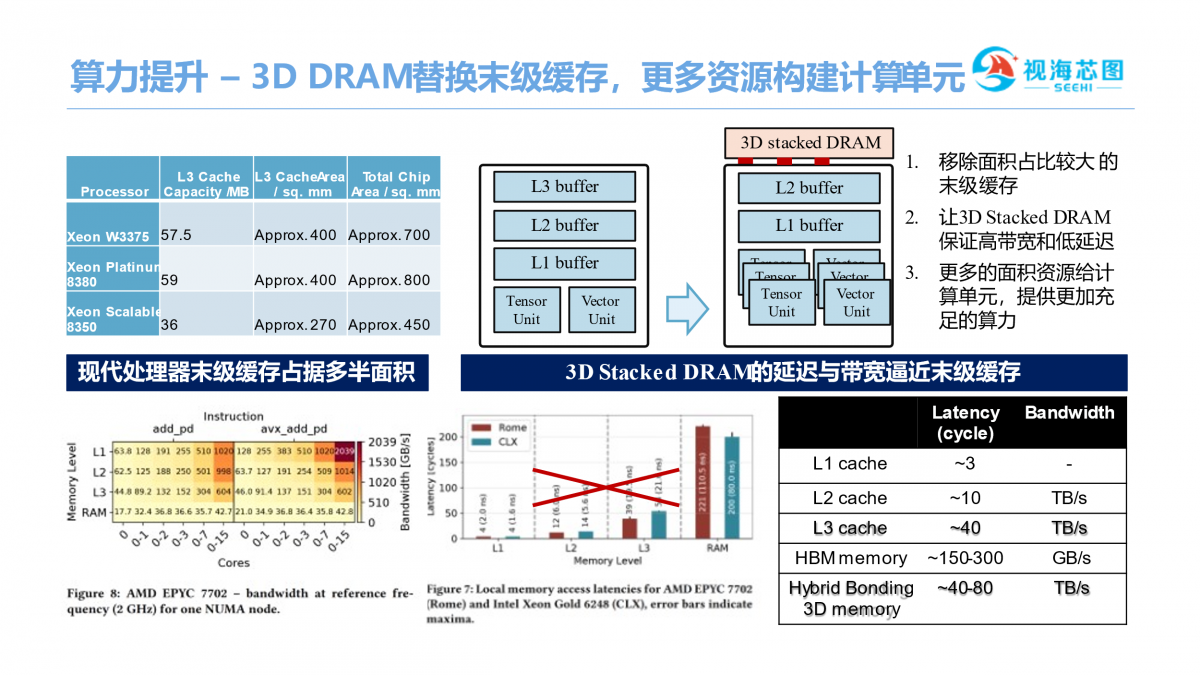
我们通过3D堆叠技术可以把处理器与DRAM之间的距离做到微米级甚至亚微米级,这种情况下的走线非常短,延迟比较小。通过这种技术,单位平方毫米可以完成数千甚至几十万的互联联线,实现的带宽更高。省去PHY,更短的走线,将带来更低的功耗,更好的性价比。整个芯片是由多个Tile构成的,每个Tile由DRAM和逻辑堆叠而成.DRAM部分主要是提供高存储容量高传输带宽,逻辑部分主要是做高算力和高效互联。Tile之间由NoC来通信,这个NoC是一个in/through NoC的设计,同一平面上与邻近Tile互联,垂直方向与内存通信,内存带宽和容量的可扩展性也可以得到很好的保证。
在去除末级缓存之后,如何保证性能不受影响?
首先在算法上面做模型量化,模型剪枝,模型压缩,同时硬件上会有在线剪枝电路、混合精度的设计,再配上压缩感知DMA,在数据流方面有数据并行,Tensor并行等等。
压缩词元的注意力机制对模型进行压缩,高效地去除了词元序列中的语义特征重复,可以显著地减小模型的计算量。
数据布局方面,DRAM有特别的读写机制,按照数据计算方式,设计数据布局,来尽量避免row conflict之类的问题。结合算法特性,采用数据并行,模型并行以及流水并行,减少核间的数据交互。
容错策略方面,因为是多颗晶圆堆叠,3颗堆叠在一起芯片良率就变成0.9×0.9×0.9,降低到70%左右,这样将很难实现大规模应用。
这时,需要在芯片上和DRAM上堆叠冗余的逻辑,保证错误逻辑之后还可以通过容错手段让芯片正常工作。
视海芯图芯片和应用案例
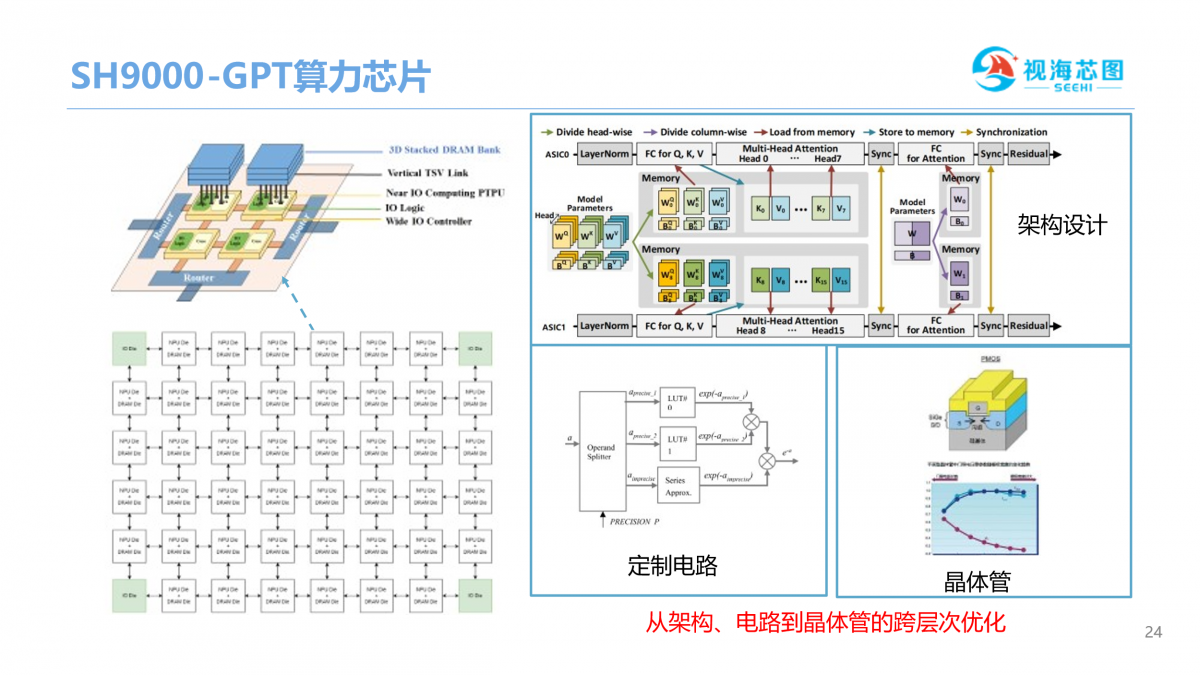
上图是视海芯图研发的SH9000 GPT算力芯片,是根据客户算法,围绕架构层,电路层,晶体管层,跨层次融合,这套技术在矿机上成功的做到了优秀的成本和能效比。
SH9000芯片设计理论峰值功耗可能略低于A100,实际RTOPS预计达到对手的2倍,这样可以达到更好的能效比。是针对算法优化,所以在跑GPT模型的时候,可以达到更好的性能。实际展现出的性能,在功耗方面可以减少一半。

在游戏领域,GPT算力可以很好的帮助游戏里面的用户生成千人千面NPC的角色,包括刀具等等。同时,根据用户行为随机生成场景的调整,为用户做成开放世界。此外,可以根据提供的场景自动生成图片,节约游戏开发成本。

在智慧教育方面的应用,GPT同样可以带来巨大的帮助,包括人性化助教。系统可以根据小朋友实际情况来做业务解答,也可以实时生成训练题。此外,在作文辅导和编程辅助方面也可以实现比较好的实时性交互。
在虚拟人、主播,GPT算力也可以发挥很好的作用。通过硬件加速的支持,可以让虚拟人的主播可更加人性化,,增强用户的参与感和互动体验,模拟真实情景。
在老年人服务机器人方面,GPT也能发挥很大的作用。GPT一方面作为知识学习系统,帮助老年人存储日常接触当中的记忆片断,还可以给老年人做情感分析,自动与老年人做交流,提升老年人生活品质。
