
Intel面向PC的独立显卡发布也有一段时间了,Arc两个定位的3、7系列都已经有产品上市。Intel这次推独显的决心还是相当大的,对于Arc显卡各方面的宣传都显得不遗余力,从技术到市场。
不过桌面显卡市场发展了这么多年,双寡头局面形成已经有些年份——就桌面端的主流图形应用来看,这个市场已经高度成熟。后来者要想在这样的市场上分一杯羹,通常需要付出相当于现有市场参与者数倍的努力,才可能真正有所斩获。


而且这种努力绝不仅是市场宣传上的成倍投入,因为GPU这种形态的处理器发展到现在,生态建设和软件相关的工作早就是重中之重。这就涉及到技术与生态积累的考验,也进一步加大了步入这个赛道并混出一片天的难度。
目前已有的Arc A380、A770/A750相关评测内容也已经不少,Arc GPU的先期口碑并不能说有多好。前不久在13代酷睿处理器的体验文章中,我也顺带谈到了入门级Arc A380显卡。其实际表现算是符合我们对于新入市者的初代产品预期的:存在问题,但未来可期。
高层级的体验内容看多了,或许我们应该关注一下Intel Arc显卡微观层面的细节表现。上个月,Chips and Cheese对Arc A770做了个microbenchmarking,我们援引其中的部分数据,来更具体地看看Intel的Arc初代独显,究竟做得怎么样。
前期好像在走性价比路线
虽说按照Arc 3、5、7数字划分低中高端,理论上A750/A770应该算作高端定位。不过市场似乎将Intel Arc A770定位在英伟达GeForce RTX 3060相似的水平上。这两款显卡目前的市场零售价也差不多,后者比前者稍高一些。
而GeForce RTX 3060其实只是英伟达PC游戏显卡家族中的“甜品卡”;则至少就Intel对于Arc GPU的现有布局来看,PC市场上,Intel还没有真正的游戏旗舰GPU。
但值得一提的是,Arc A770/A750显卡之上的那颗ACM-G10 die,尺寸达到了406mm²,基于台积电N6工艺,晶体管数量217亿个。单就晶体管堆料参数来看,它相比于英伟达GA104,无论工艺先进程度、晶体管密度还是die size,都要更甚。而GA104这片die的完全体其实是GeForce RTX 3070/3070 Ti在用的。
用着高于3070的料,却卖着比3060还便宜的价格,Intel对此应该也是比较无奈的,毕竟其性能表现好像没有达到堆了217亿晶体管所应当达到的水平。
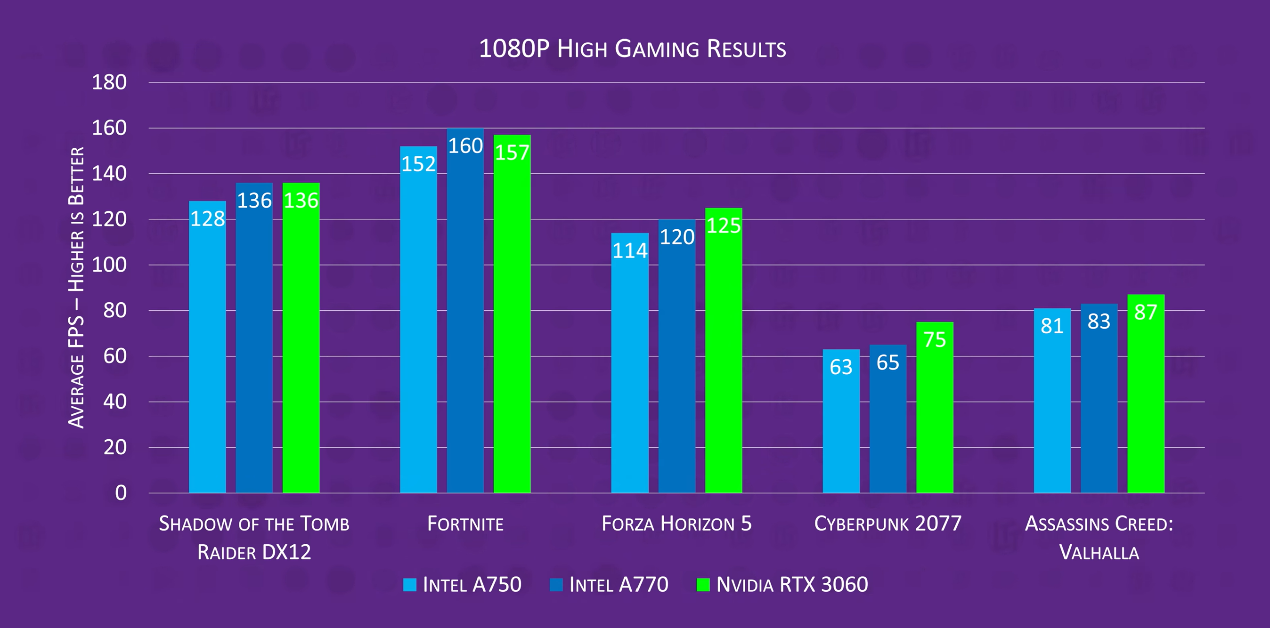
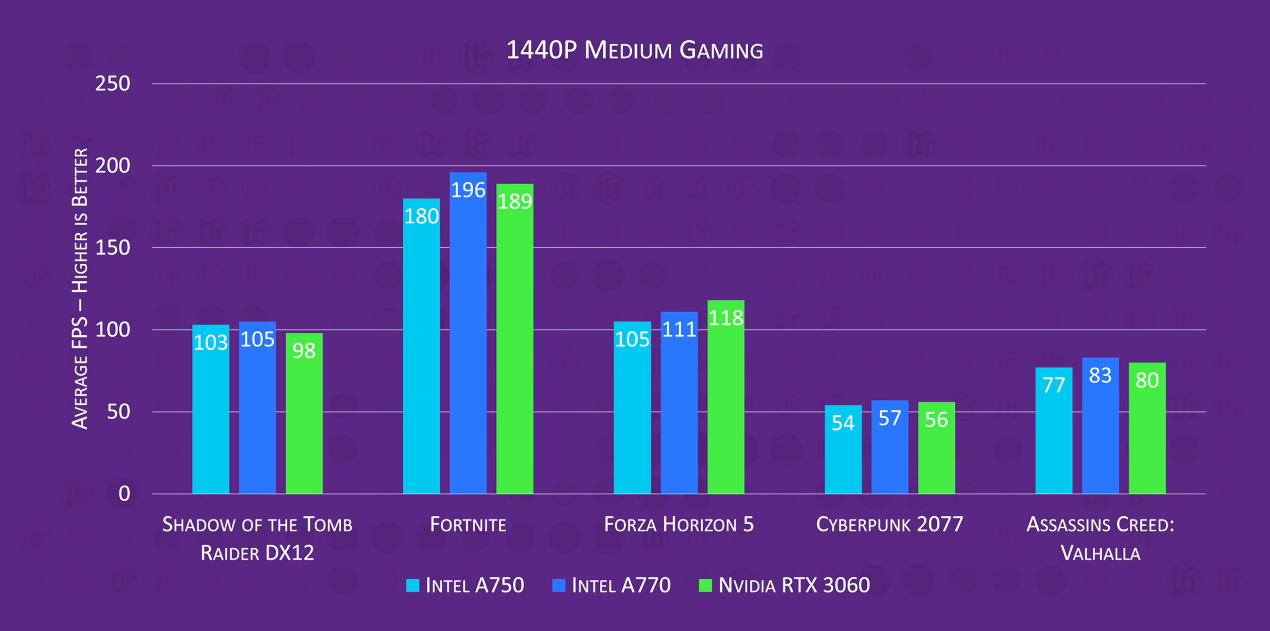
其实作为一张DirectX 12/Vulkan显卡,Arc A770对于最新的DirectX 12游戏支持情况还不错,在1080p分辨率、高画质下的游戏性能与GeForce RTX 3060差不多;2k分辨率下还能做到反超。当然,即便是这样,基于Arc A770的硬件堆料,猜想其图形渲染性能也并未达到Intel的预期。
而更悲剧的是,Arc对老游戏(或更早DirectX版本游戏)的支持一言难尽。在《古墓丽影:暗影》的DirectX 11模式下,画面帧率立刻腰斩。像《CS:GO》这种更老DX版本的游戏,Arc A770连RTX 3050都打不过...原因在于Arc跑DirectX 9游戏,是用DirectX 12→DirectX 9的中间转义层来实现兼容的。加上没有专门优化,以及CPU需要额外开销做转义工作,老游戏的效率是可想而知的。
但如果说性价比,其实Arc A750/A770这种卡又不大可能把价格降到太低的程度,毕竟die size和晶体管数量就是实打实的成本。而且这些die size不光是用在了传统的图形计算单元上,Arc A770还在AI单元、解码器、图形光线追踪方面堆了不少料,这就令其在某些方面显得很偏科;其光追、AI超分和视频编解码性能都还是挺不错的。
为什么更高分辨率下,性能会更好?
高层级、应用层面的体验内容,网上已经有不少分享了,上面这个段落也算做个总结。有关初代Arc显卡Xe-HPG的架构,此前我们也详细撰文谈过,这里也不多费笔墨。
Arc A770的纸面数字配置主要包括有32个Xe核心,8个render slices,32个RTU(光追单元),512个XMX引擎(AI加速单元),512个矢量引擎,PCIe 4.0 x16连接,256bit 16GB GDDR6显存,TBP 225W。我们主要来看看Chips and Cheese做的相关存储与计算方面的一些“microbenchmarking”核心数据。
首先是存储,在GPU核心上Intel也采用了两个层级的cache存储方案,英伟达也是如此。Intel在架构策略上,选择了比竞品更大容量的cache(Chips and Cheese测试结果是每个Xe核心192KB)。更大的cache也会带来更高的延迟,不过在GPU高利用率的情况下,小幅延迟增加是可以被隐藏的;而且更高的L1命中率本身也能够一定程度提高平均访问延迟。
Arc A770的L2 cache也比较大,达到了16MB,至少比英伟达Ampere和AMD RDNA 2大。从测试结果来看,Arc A770的L2 cache虽然容量更大,但延迟表现很不错,比RTX 3060 Ti还略快,介于AMD RDNA 2的L2 cache和Infinity Cache之间(如下图)。对比中英伟达和AMD显卡的L2 cache容量要小得多。
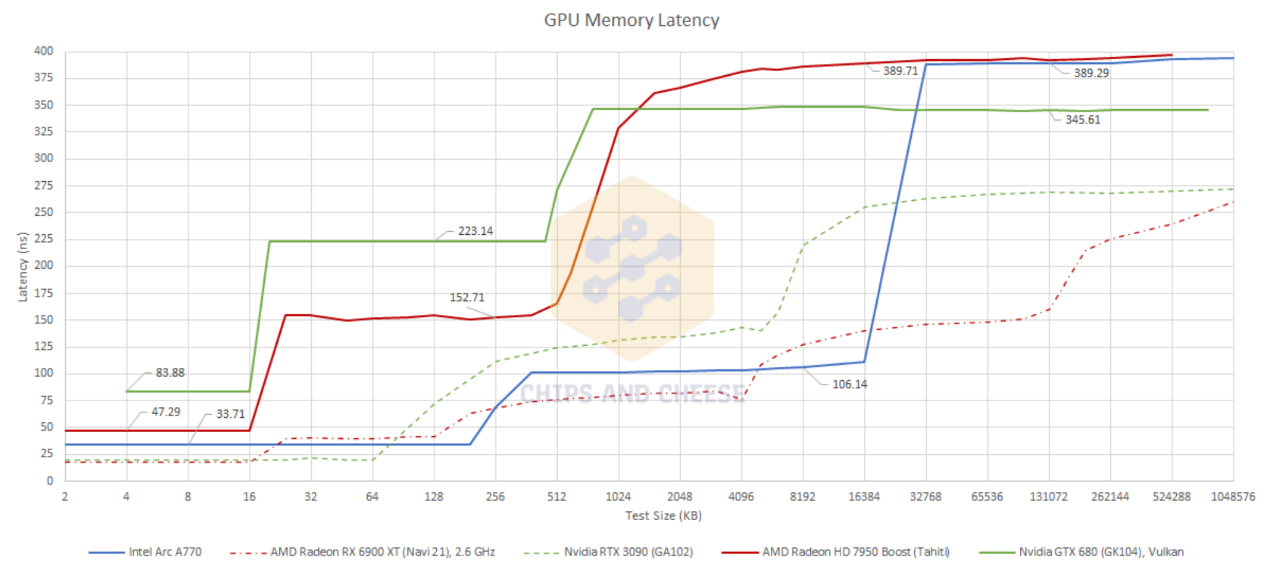
显存访问延迟方面,Intel会比AMD和英伟达高不少:而且用Chips and Cheese的话来说,这个延迟数字达到了10年前显卡的水平。不过在GPU高占用率(线程数尽可能填满)的情况下,显存延迟的影响并不会太大。
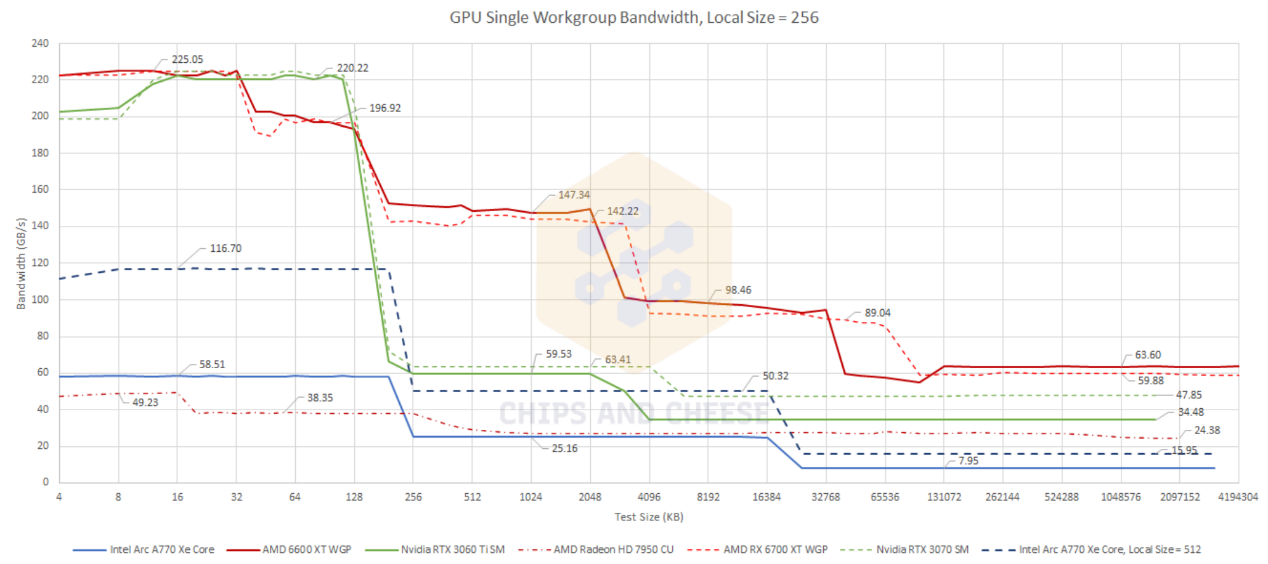
存储带宽测试,首先是dispatch一个workgroup,则GPU的一个模块或者说一个核心就会开始工作——所谓的GPU基础模块构成,对于Intel而言是Xe核心,对英伟达而言是SM、对AMD而言是WGP(RDNA)/CU(GCN)。
从测试结果来看,一个Xe核心在不同存储层级——包括cache和显存上都无法获得很高的带宽。尤其当数据深入到显存部分的时候,情况相当不乐观:AMD一个WGP从显存拿到的带宽就能有63GB/s,而英伟达一个SM则有34.4GB/s,Intel的一个Xe核心只有8GB/s的带宽。片内cache的情况也没好到哪里去,就这个结果来看,Intel的Xe核心的存储级并行能力(MLP)不大行。
一般GPU能够执行的workgroup size是256线程,而Arc支持的workgroup size最多有512线程,这对于隐藏延迟是有帮助的。所以基于这个size做测试,测试结果会有显著提升(蓝色虚线,Local Size = 512):L2 cache带宽将近能够达到英伟达Ampere的水平,但显存带宽仍然比较悲惨。
Chips and Cheese评价说,Arc A770单个workgroup执行的存储带宽表现和古老的AMD Radeon HD 5850差不多....
不过一般GPU跑真实负载的时候,不会只用上GPU的一个核心。上面这样的测试也就作为某种参考。随测试增加workgroup或者说并行度,存储带宽利用会增加 - 当然更低并行度下达成越高的带宽一般也更理想。
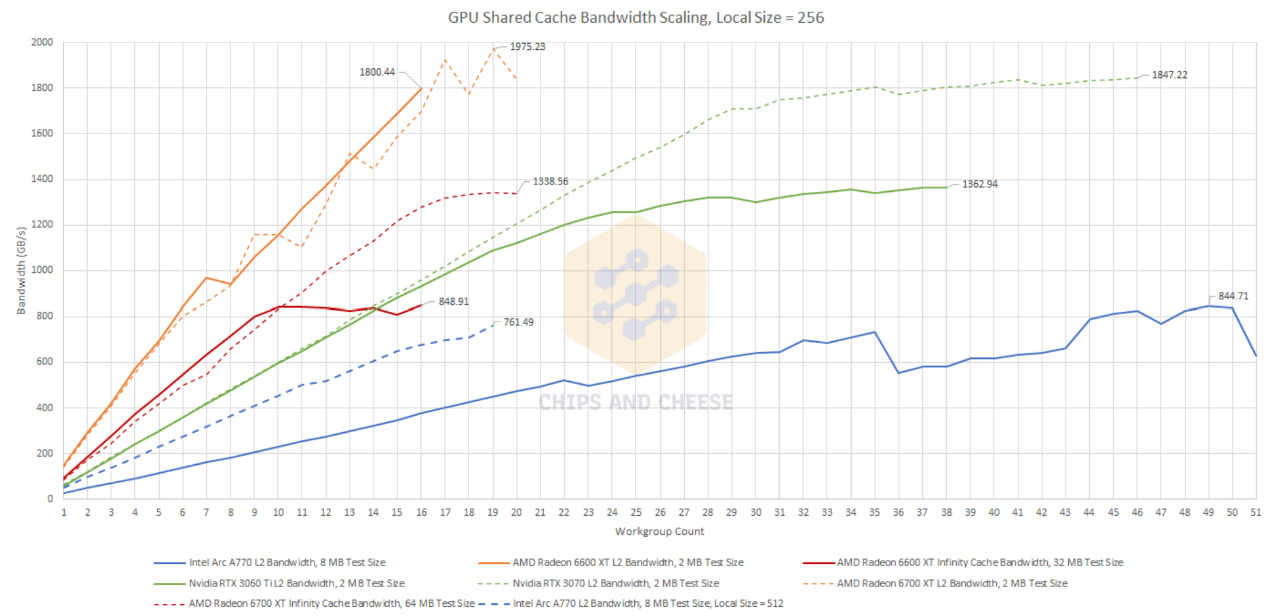
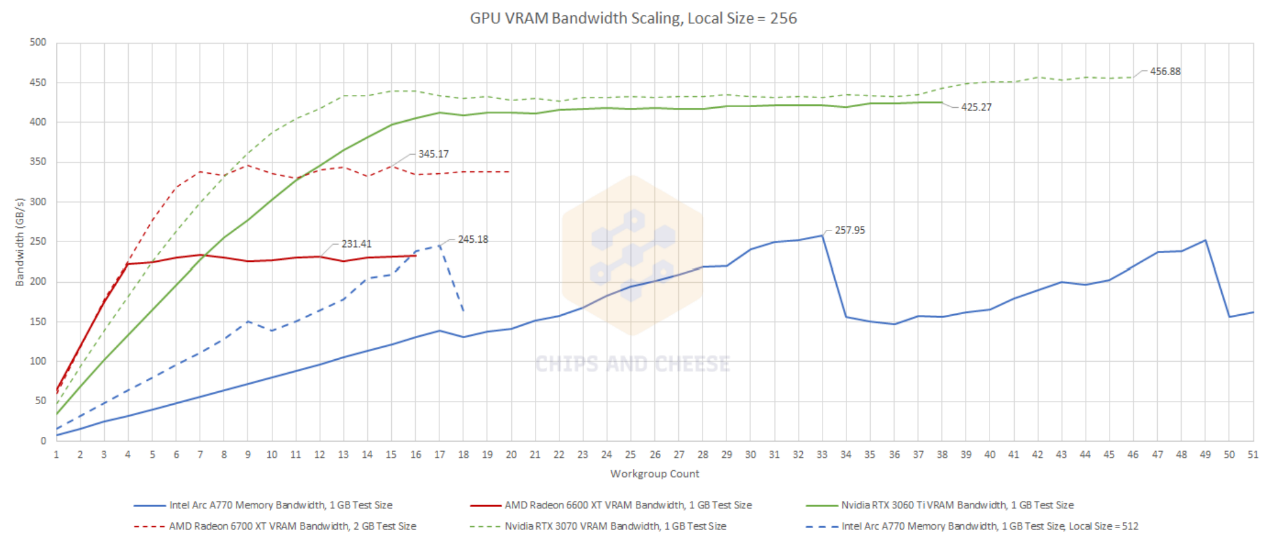
即便增加workgroup,无论是共享cache(包括L2 cache),还是显存,Arc A770的情况看来和其他竞品都完全不在一个水平线上。AMD和英伟达这边都能快速达成带宽利用增长或满载。
就共享cache来看,AMD这边的Infinity Cache容量还更大,情况都比Arc A770的L2 cache好。而在显存方面,即便Arc A770的所有32个Xe核心都处在工作状态,显存带宽似乎都没有填满。看起来Intel在Arc显卡存储系统的带宽利用率方面还有很多工作要做。
值得一提的是,Chips and Cheese的测试流程也可能存在问题,抑或测试用的这一版Intel驱动存在问题,尤其在测试反复分配、释放存储资源的过程里,Chips and Cheese提到OpenCL runtime还会报错。
这几个月Intel应当有在频繁做驱动的bug修正工作,这也是新入市者前期会遭遇的问题——我在A380的体验中也提到过,即现在的每次驱动更新都能发现不少问题被解决。
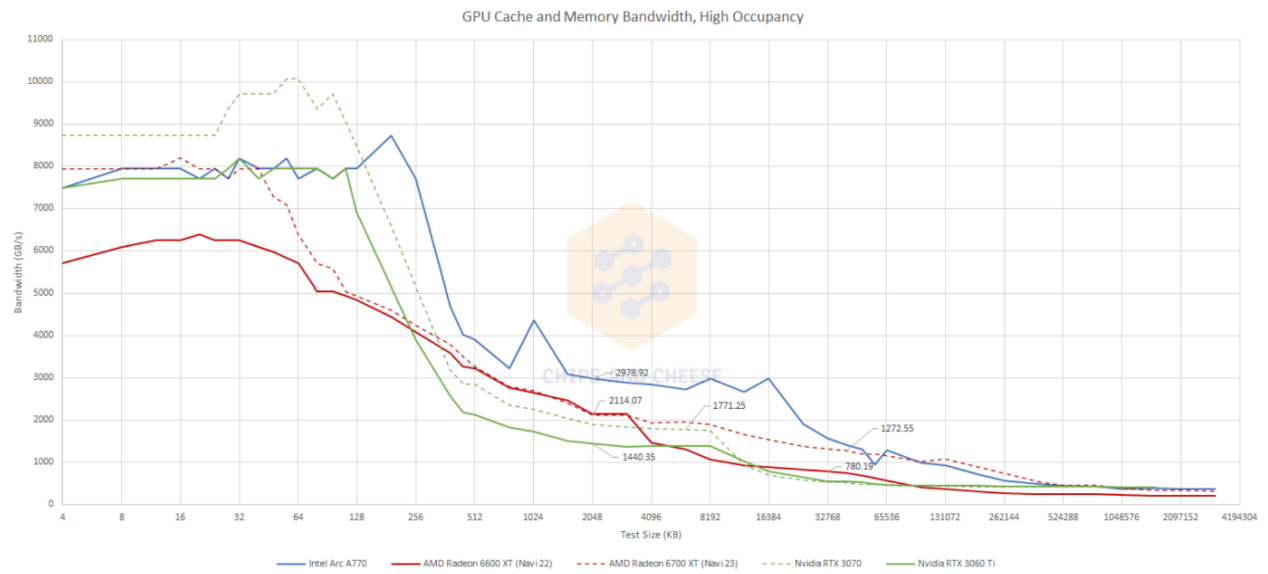
上面这个测试是跑512个workgroup,以期达成全部GPU单元模块的满载。在GPU资源高占用的情况下,Arc A770的存储性能表现就会比较理想,在不同存储层级全周期内,都能表现出很不错的带宽吞吐,包括cache和显存。
不过配合真实测试来看,Arc A770真的需要高占用、高并行度才能表现出比较理想的存储性能——某些游戏由于各种原因无法做到GPU的高利用率,不管是游戏类型需要、CPU瓶颈还是软件优化,则实际表现可能会比竞争对手的GPU显著更差。Arc因此有更大概率在游戏的高分辨率设定下,有不错的帧率表现。
这可能就解释了,为什么在实际游戏测试的2k分辨率下,Arc A770相比竞品的优势会更大,或者差距会更小。
另外有关local memory延迟的情况,也就是一个workgroup内的所有线程共享的存储部分,Chips and Cheese也做了测试。Intel Arc A770(27.57ns)在这方面稍落后于英伟达Ampere(16.71ns)和AMD RDNA 2(19ns左右),和Maxwell(26.33ns)差不多——不能说出色,但也不算差。
计算吞吐与延迟
存储系统测试之外,另外比较重要的当然就是连接和计算了。Chips and Cheese倒是有做PCIe带宽测试,以及计算相关的测试。不过连接测试内容,因为设定的关系,个人认为可能并不具有太高的参考价值——大抵上基于测试PCIe 3.0和Resizable BAR设定,Arc A770的数据复制带宽水平都不理想,至少和目前在售的AMD和英伟达当代架构竞品比是如此。
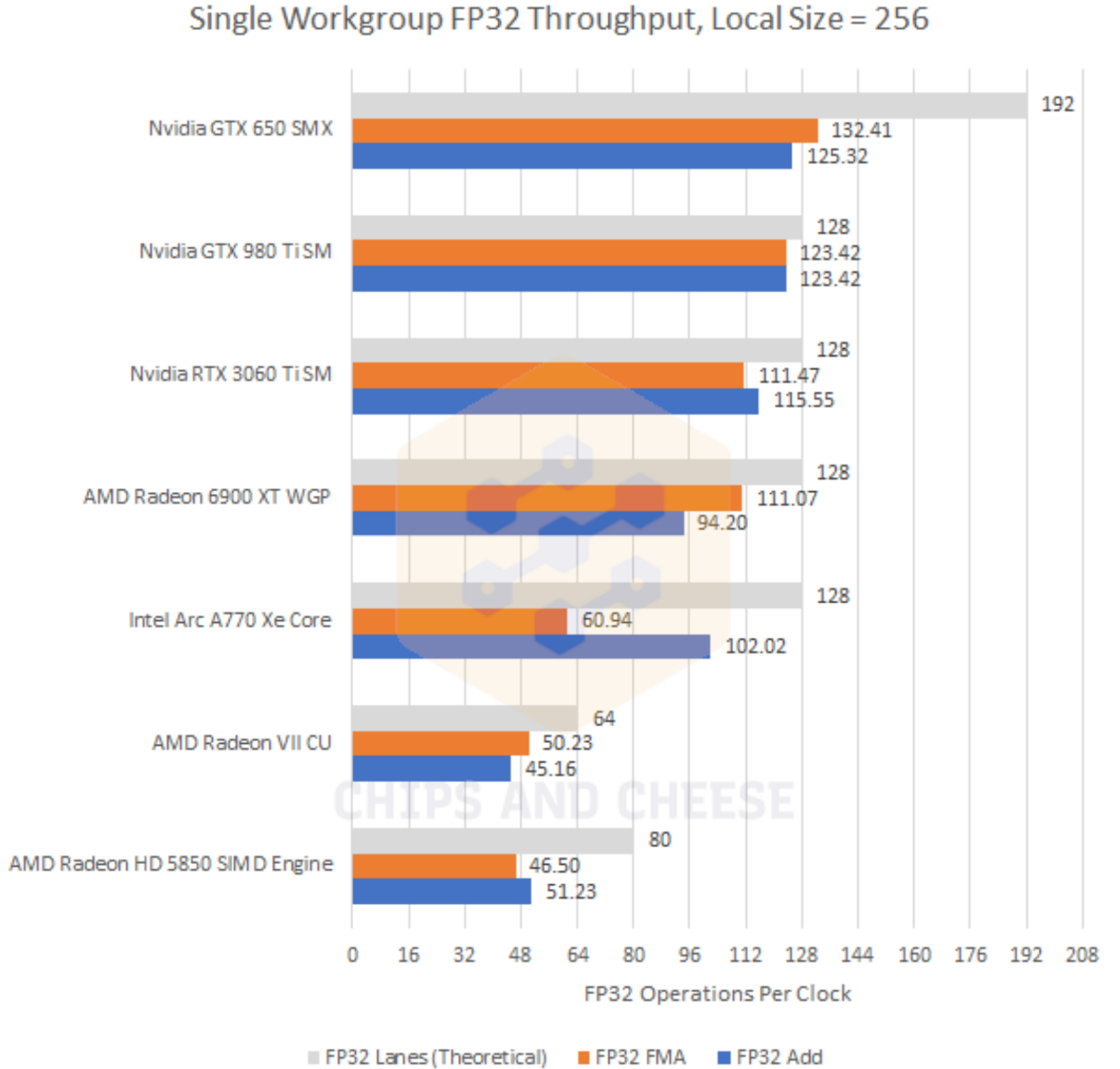
要说GPU计算性能,FP32吞吐应该是一个重要指标,因为图形渲染包含了大量的FP32操作。从测试结果来看,Arc A770的Xe核心在FP32加法操作上表现不错,但FP32 FMA(融合乘加运算)不理想,原因不明。
整数(INT32)操作吞吐部分,Arc A770的表现不差,但似乎和当代竞品相比有一定差距。不过这部分测试结果也仅供参考,Chips and Cheese的测试工具还在做完善。之所以只给了单个GPU核心跑测试的结果,也在于如果看整个GPU的吞吐数据,A770的情况更为异常。这部分后续仍有商榷的余地。
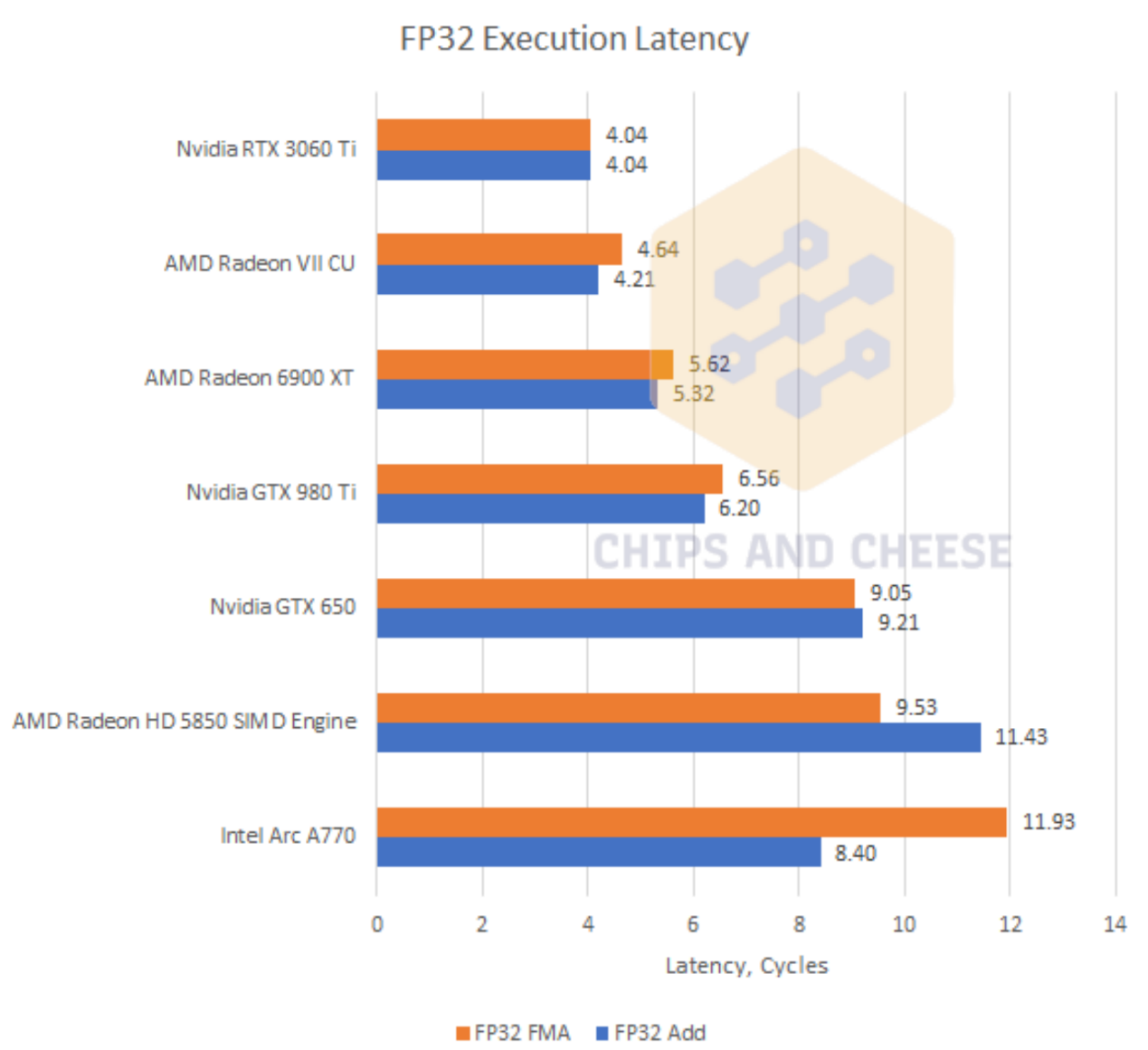
在FP32执行延迟(单位:周期)方面,近代英伟达和AMD的GPU表现都相当不错,就周期数来看和CPU差不多——当然CPU的频率还是显著高于GPU的。Arc A770在运算单元的执行延迟会明显更高,尤其是FP32 FMA操作。
INT32整数执行延迟情况也类似,但比旧架构的显卡会稍好,包括比Kepler和Maxwell都好些,但显著弱于Ampere和RDNA 2。整数执行延迟数据对比图就不放了。
Chips and Cheese认为,像FP32执行延迟达到11-12个周期,在最终更系统层面并不会表现出多大的差异——这些延迟完全可能被其他因素隐藏。而且像AMD Terascale 2架构的FP32延迟也很高,但并不妨碍其计算性能的发挥。不过如果要在最终应用里有效隐藏较高的执行延迟,则同样需要较高的GPU资源占用度才行,这可能也是Arc A770在高分辨率图形渲染时,表现会更好的原因之一。

比较有趣的是,因为现在时常在Intel活动上出现的执行副总裁Raja Koduri此前来自AMD图形业务,所以Intel这次在推Arc显卡时,就有很多网友开玩笑说Intel的Arc,本质上就是AMD的Vega。当然其实从内部架构来看就知道,这纯粹是个玩笑。
不过Chips and Cheese还真的特别对比了Intel Arc A770和AMD Radeon VII(GCN),感觉对Intel足以产生一万点暴击...主要测试的还是cache和显存的带宽和延迟,有兴趣的同学可以去看看:上述弱项中,在低资源占用的情况下(较少workgroup数),Arc 770的存储性能表现仍然不乐观(Radeon VII在显存方面还很豪气地用了HBM2)。
Radeon VII其实也算是在应用资源高占用时,才能发挥实力的典型代表,但似乎仍然没有Arc A770那么依赖高占用。不过达到GPU高占用时,Arc A770作为今年发布的显卡,综合存储性能表现还是能够把Radeon VII甩在身后的。
这一代Arc显卡架构这种资源高占用、才可发挥出实力的特性,可能与Xe-HPG架构构成有很大关系,尤其是每个Xe核心L1 cache需要在8个Send端口(一个Xe核心包含8对EU/矢量引擎)之间做仲裁,每个端口还需要在2个矢量引擎间做决策。而且load/store系统以轮询的方式来服务EU/矢量引擎,这可能能够解释GPU低资源占用、低并行度时存在的带宽问题。
最后值得一提的是,最近Intel为Arc A770/A750发布了新版驱动,据说在游戏中达成了8%的性能提升——其实从驱动更新角度,8%也不是什么大数字,尤其在Intel目前驱动程序可能仍然效率不高的大前提下。不过这也表明,驱动更新仍有持续优化Arc显卡性能的余地。
而且我们都始终觉得,Intel这类参赛选手对于GPU市场的介入是个好事,尤其初代独显产品能有这样的表现,虽然仍然存在诸多不成熟,但已经是个非常出色的开端。难怪Linus Tech Tips要呼吁大家都去买Arc显卡,英伟达和AMD也是积累了十几、几十年才有了现在这番作为的:而Intel显卡的成熟也会持续盘活GPU市场,带动技术发展。
