
在半导体行业发展的这几十年,“摩尔定律”估计是被提及次数最多的一个词,没有之一了——无论是产品发布,还是行业峰会、技术研讨会之类。将于11月10日在深圳大中华交易广场举办的IIC深圳(2022国际集成电路展览会暨研讨会)也不例外,IIC展会将设置IC设计专区、分销与供应链专区、综合展区等,集合了国际国内最顶尖的电子科技产业领袖。
同期还将举办全球CEO峰会、全球分销与供应链领袖峰会、国际工业4.0技术与应用论坛及第24届高效电源管理及功率器件论坛。尤其是全球CEO峰会,虽然离现在还有大概一个月的时间,不过我们猜一定会有CxO级别的人物在我们的会上提到“摩尔定律”这个几个字。所以千万不要错过本届盛会,点击这里报名参会。
好了,广告做完了,我们来细品“摩尔定律”这几个字。虽然我们整天把“摩尔定律”挂在嘴上,但你真的知道什么是摩尔定律吗?摩尔定律真的是说每18个月,单位面积内的晶体管数量就翻番吗?比较有趣的是,上个月英伟达GTC开发者大会上,黄仁勋在答记者问上两次提到摩尔定律已经结束了;而几天后的Intel Innovation大会上,Pat Gelsinger又说摩尔定律肯定还没死。
这到底“死”没“死”的,就看谁说了。本文我们就以EE历史课的方式来追溯一下“摩尔定律”究竟死没死,以及其实质是什么。不要忘了参与我们即将于11月份举办的全球CEO峰会,来听听各家电子科技领袖CEO们对于摩尔定律的看法。
摩尔定律的一个实例
前一阵Semiwiki有作者撰文举了个挺有趣的例子,我们也搬来用一用。这篇文章的作者Paul McWilliams说他入行是在1976年,当时DRAM领域比较热门的产品是容量16Kb的Mostek MK4116。16Kb大小的这么个DRAM存储器件,功耗(active state)大约是0.432W;受制于当时的工艺水平,每平方英寸PCB只能塞进1.5个器件;这颗MK4116当时的售价是10美元。
如果说摩尔定律不存在,想象一下现在我们PC里面常见的16GB内存大概是怎样的规模。即便不算通胀,那么以1975年的成本等比放大,则16GB的内存应该需要8000万美元,而且占板面积大概是3.7万平方英尺,耗电是3500000W。如果按照每千瓦时的电费是0.1美元计,则每个月在这块内存的用电花费就有25万美元。
看样子如果没有摩尔定律,那就只有亿万富翁才买得起16GB内存了——实际上现在在京东买根16GB DDR4内存条只要三四百块钱人民币。而且请注意这个算法只是等比扩大了存储单元,没有算其他的各种主动、被动器件。不知道1975年的人有没有想过,到2022年,16GB DRAM是多么唾手可得。

如果加上通胀的考量,计入摩尔定律,则仅针对这一例来看DRAM成本下降了99.9999995%,功耗下降了99.9999993%;每bit成本下降的数量级实际有1000万倍——如果是看数字处理器类型的芯片,则经济效益自Intel 4004(1971年)到今天提升了超过10亿倍。这个例子听起来还是相当震撼的吧,再一想今天很多企业在说未来1000倍性能提升,好像根本也不算什么。
不过大概大家更在意的是近些年摩尔定律是否已经“死”了,而不是从1975年算起。前一阵我们参加英伟达GTC,英伟达给出2018年Turing架构最高端的显卡芯片用上了186亿晶体管,die size是754mm²;而2020年Ampere架构芯片用上283亿晶体管,die size为628.4mm²;今年刚刚发布的Ada Lovelace架构芯片晶体管数量是763亿,die size是608.5mm²。这够近代了吧?
这3代芯片应用的工艺分别是台积电12nm、三星8nm、台积电4nm,看起来好像摩尔定律依旧活得还不错——即便用晶体管数量÷面积,得到的数字也还算是可观的。那么摩尔定律没死吗?
摩尔定律的出处和实质
首先我们得肯定,摩尔定律对于电子科技产业整体的贡献和意义,要不然就只有亿万富翁才买得起16GB内存,而且顺丰小哥还搬不动那么大的东西。不过要回答摩尔定律死没死的问题,除了在Aspencore的全球CEO峰会你有一定概率找到答案,我们首先还是要搞清楚究竟什么是摩尔定律。
1965年,还是仙童半导体研发总监的Gordon Moore——也就是后来Intel的创始人之一,受邀《Electronics》杂志写了篇比较短的paper,主要内容是就未来10+年的半导体产业趋势预测的。这篇文章在Intel官网现在也仍然能看得到,题为Cramming more components onto integrated circuits(把更多器件塞进集成电路)。

1968年的Gordon Moore(左)与Robert Noyce,来源:Intel
有关“摩尔定律”的全貌,都可以从这篇原始文章里得到解答。当时Gordon Moore在文章中预测,按照这个论断,则到1975年(也就是1965年的未来10年)单个1/4英寸半导体产品上将有可能足够容纳6.5万器件(components)——注意是器件,器件包括有晶体管、电阻器、二极管、电容器。Moore还说,以最小成本能够达到的复杂度,每年都会有大约2个数量级的增长。也就是说,时间和复杂度是对数线性(log-linear)关系。
实际在1975年的IEEE国际电子器件大会上,Moore对这一预测做了重新修正,他预测大约到1980年半导体复杂度每年还会持续以两倍速度提升,而在此之后会渐渐缩减到每两年两倍速的程度。其实在此之前“摩尔定律”这个词都还没有真正流行。很快,加州理工学院教授Carver Mead对“摩尔定律(Moore's law)”这个词做了推广,然后摩尔定律就在半导体行业开始全面风靡——Intel的竞争对手为了宣传自家产品在性能上的提升也开始频繁引用“摩尔定律”一词。
Gordon Moore本人后续在很多场合接受过不少媒体采访,都被问到了“摩尔定律”。有一回他本人玩笑说:“摩尔定律其实是违反了墨菲定律的。”毕竟墨菲定律是说事情总会往更糟的方向发展。我们现在当然知道,摩尔定律被推而广之地作为IC芯片之上晶体管数量增长速度的一个现象表达,属于某种趋势的观察和推论,而不是什么自然界的物理法则。
早在2005年4月,Gordon Moore就在某次采访中回复说这个“定律”无法无限持续。当时他也提到了晶体管最终会在原子级别达到某种最小化的限制:“从(晶体管)尺寸来看,你会发现我们已经接近原子级别的尺寸,这会成为根本性障碍。不过在遇到障碍之前,至少还会要2、3代,但是我们能够看得到的未来。在遭遇这一根本性限制之前,我们还有10-20年。”
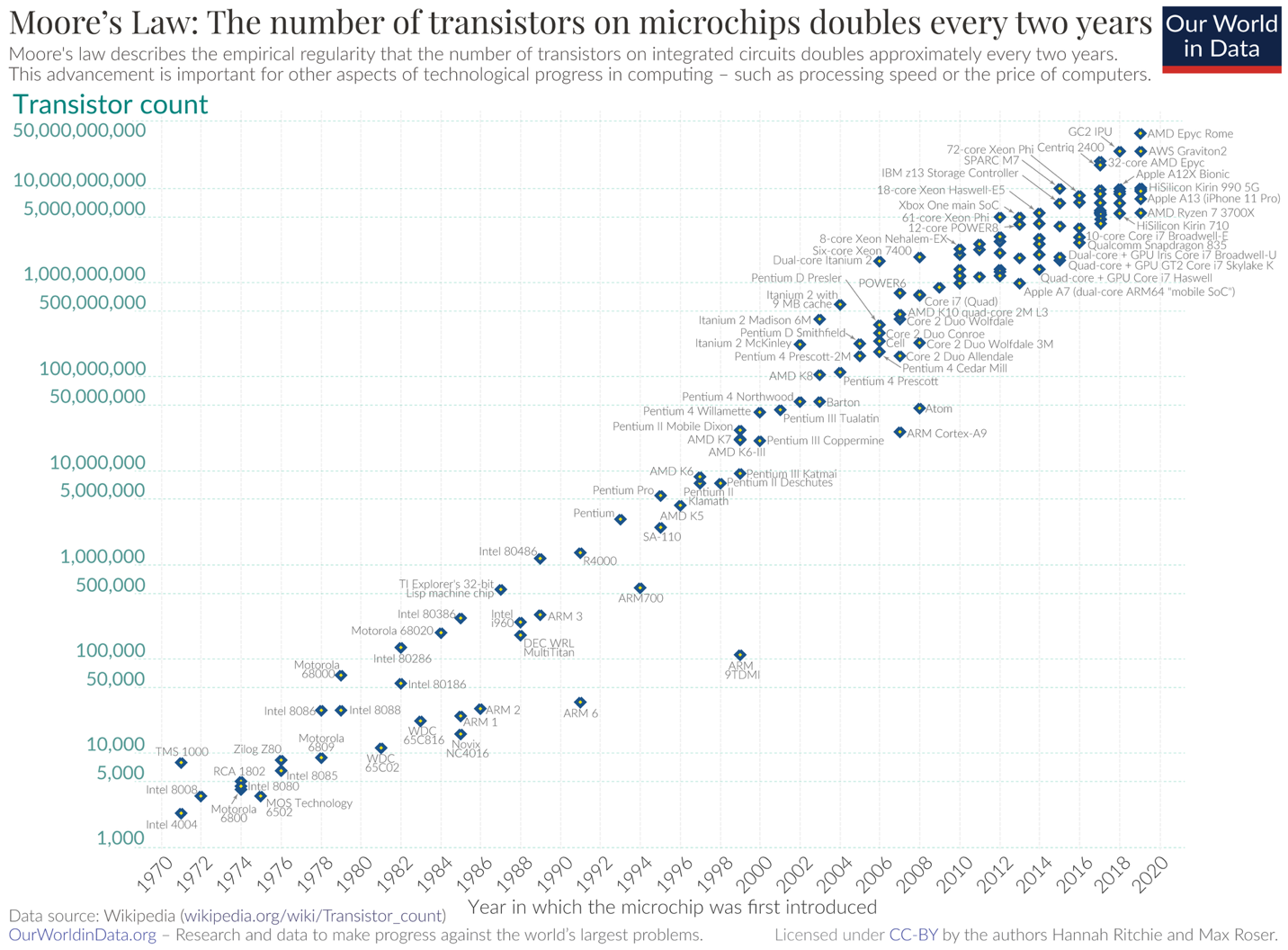
大部分行业预测专家,包括Gordon Moore本人,都预计摩尔定律将于2025年前后终结——维基百科有这方面的资料做参考,可做扩展阅读,都是比较严谨的研究paper。不过如果以Intel的PC处理器为参考,则起码在14nm之前,摩尔定律都是基本成立的,具体的数据可以去看Paul McWilliams的总结,1971年Intel 4004的晶体管密度是187.5个晶体管每平方毫米;2015年的酷睿i7处理器大约是1428.57万晶体管/平方毫米:这44年间,晶体管密度涨了76190倍。
其实到台积电N5工艺应用于苹果M1 Max,达成的晶体管密度约1.319亿晶体管/平方毫米都仍然在循着摩尔定律的轨迹。(注:这里计算晶体管密度的方法仅是整个芯片的晶体管数量÷die size,这种计算方法无法用于表达某一代工艺节点的器件密度)
其他延伸定律
基于对原文本的研究,我们大概可以说当代的“摩尔定律”,属于对原表达的演绎——不过其实也八九不离十。值得一提的是,行业对于摩尔定律常有个错误的援引,就是将Gordon Moore此前所说的时间改写成“18个月”,就是每18个月单位面积的晶体管(或器件)数量翻番。
有关“18个月”的误传,同样是有出处可循的。1975年Intel的David House说摩尔定律修正为每18个月晶体管数量翻番,同时功耗不会增加。不管是几个月吧,摩尔定律的意义已经不止于一个现象的解读,还在很长一段时间内都成为整个半导体行业的长期规划指导原则。
不过作为行业指导原则的结束是在2000年之际,登纳德缩放定律(Dennard scaling)的终结。登纳德缩放定律的名气虽然没有摩尔定律那么大,但也算是同期大量“定律”的重要一员了。这一定律表达的是随着MOS管变小,功率密度保持不变;换句话说芯片单位面积内的功耗恒定。也就是说,随摩尔定律达成的芯片性能增长,在相同面积内不会带来功耗的增长。
但公认的,在2000年以后登纳德缩放定律就结束了——其中一部分原因应该是随着器件尺寸缩小后漏电流的增加。即便摩尔定律在此之后仍在持续,但诸多市场从业者从此之后从以摩尔定律为指导,转向了以应用为导向。在原本描述CPU性能提升的“摩尔定律”的指导下,CPU性能的提升幅度也并不与晶体管数量增长呈线性关系;在登纳德缩放定律结束后,可达成的实际性能提升幅度就更是如此了。
1995年Moore还发过一篇paper,已经不仅把“定律”或“推论”局限在晶体管数量的增长问题上了。在此之后似乎所有相关与半导体行业,存在一定对数或接近关系的现象都和摩尔定律挂上钩了。期间从网络、通信、IT,甚至到生物制药领域都衍生出了各种各样的“定律”,包括什么Eroom's law——Moore反过来写,还有Edholm's law说通信网络带宽每18个月翻番等等。
摩尔第二定律,与摩尔定律的经济基础
作为一个现象——和对现象的表达,而非规律,这种现象能持续这么多年必然是有背后的推动力的。摩尔定律本身暗含了一个前提或前置条件,就是半导体制造成本的不断下降。比如以单个晶体管造价为依据,若随技术进步,这个价格必须呈一定的下降趋势,才有推动企业不断采用新技术的动力——因为成本下降了,意味着能赚到更多的钱。
就好像本文第一部分提到的例子,如果摩尔定律的持续只是带来16GB DRAM的体积大幅缩小,但成本还是8000万美元,那就是不可持续,对企业而言没有驱动力的。
一般我们讨论成本,可以把成本切分为固定成本(CapEx)和可变成本(Marginal)。固定成本可以理解为一些生产资料、基础设施的一次性投入,比如说芯片制造所需的设备、厂房建设之类的投入;当然如果囊括范围更大,则芯片设计也作为固定成本算在其中。这种成本在先期会非常巨大,但一旦投入完成,则会随着生产规模的扩大逐渐回本。而可变成本则是指在每次生产时都需要投入的新成本。
通常我们会说半导体制造行业的大头在固定成本上,随着产量起来,获利将会越来越高。而且半导体行业还有个比较厉害的特性,即基本的制造原材料——硅供应几乎是无限的,则产量理论上要多少就能有多少。
当然我们知道随技术难度增大,这方面的特性也会有一些变化。一方面是对于尖端制造工艺而言,固定成本每年的增幅是相当骇人的。2017年美国半导体行业协会的预估是7nm/10nm工艺节点建厂,配套制造设备需要70亿美元投入。在过去25年里,新节点成本每年推升13%。
但我们认为,这个数据这两年还可以再进一步改写。因为台积电今年的CapEx成本投入就预计有440亿美元(虽然并不都是尖端制造工艺投入),则可见工艺迭代有多费钱。Intel过去这么10+年的固定成本与可变成本之比,已经变得非常惊人。
在我们探讨的“摩尔定律”话题下,成本的快速提升带来两个问题。其一是因为成本攀升速度都比市场增长率还快,大量市场参与者就不得不退出这一市场;其二,作为推进摩尔定律的驱动力,如果某种单位的造价不能按照一定的比例下降,那么摩尔定律本身必然就不可持续,因为其存在基础都没有了。
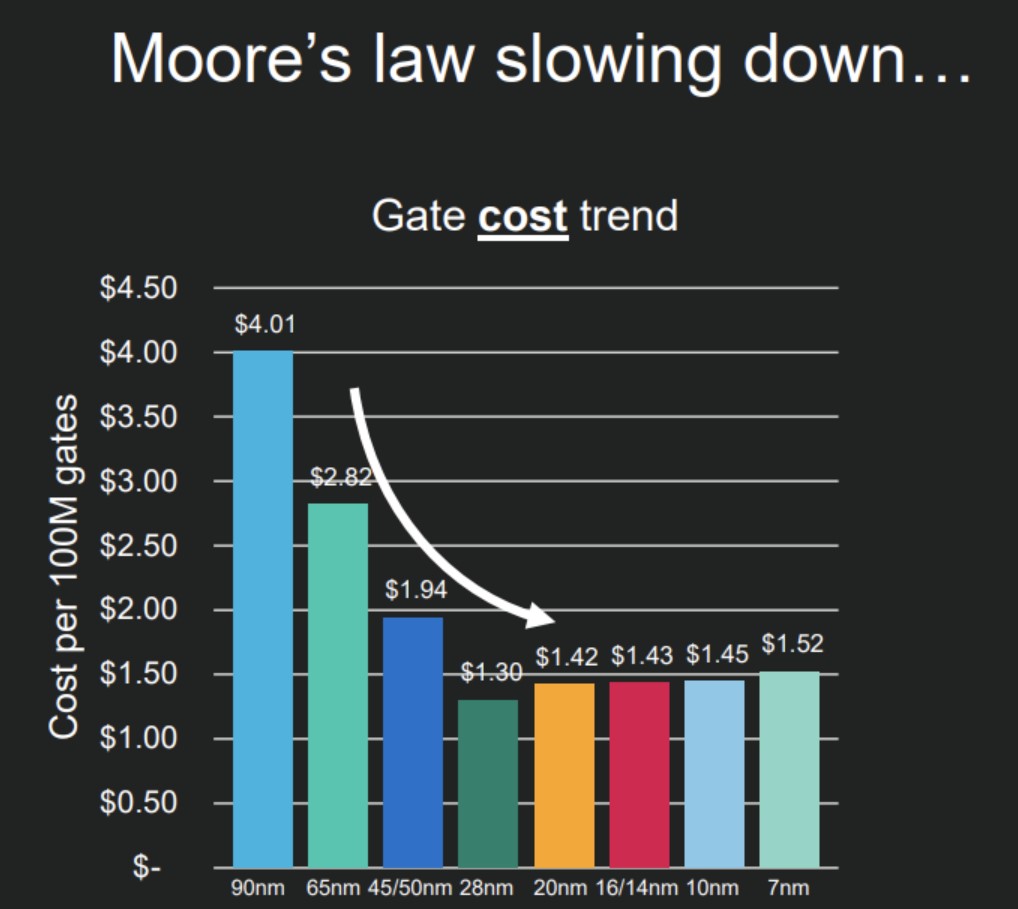
维基百科有个“摩尔第二定律(Moore's second law)”,或者叫Rock's law。这个“定律”的出处不大可考。不过按照维基百科的说法,摩尔定律表达的是半导体芯片fab厂的成本每4年翻番。这是个反摩尔定律,或者至少在经济驱动力上与摩尔定律部分相违背的“定律”。
不管这个定律是不是真的吧,驱动摩尔定律超过50年的经济底座接近丧失都是事实。前两年有不少研究都在探讨从单个晶体管造价的角度来看成本问题。有的说法是10nm以后,单个晶体管成本就已经不再下降;上面这张图是Marvell在前两年的Investor Day上给出的,每亿门成本的变化趋势,是在20nm之后就趋于平稳,甚至有小幅蹿升了。
当然单晶体管造价这个维度可能仍然无法佐证摩尔定律经济驱动力的消失。但只要摩尔第二定律成立,则总有一天会达成驱动力的不再。且成本的增加并不单纯体现在单晶体管或固定数量逻辑门的造价上,还在大die加上良率后的成本上...这些更细枝末节的问题就不谈了。看起来2025年摩尔定律的终结,算是个比较靠谱的预测。
摩尔定律将结束的征兆
有关摩尔定律终结的“预测”好像是年年都有的,最早是1985年Intel 80386问世的时候,华尔街日报的文章就说摩尔定律要死了。
现在我们又提摩尔定律终结,是不是既没新意,又有点狼来了的感觉。这里我们列几条摩尔定律趋于终结的征兆。其实前面谈摩尔定律驱动力的不再,就已经是强有力佐证了。不过其他征兆还包括:
第一,从190nm以后,晶体管器件的实际三围尺寸或者间距,就和这个nm数没有关系了。比如我们现在说的5nm,就只是一个称谓。对晶体管而言,并不存在哪个部位真的是5nm。而类似10nm、7nm、5nm这些数字步进,单纯只是在技术迭代时,将数字乘以0.7——因为对于一个正方形而言,边长变成0.7倍,就意味着面积刚好差不多缩减1倍——也就符合摩尔定律了。或者说我们现在听到的这些工艺数字,只是foundry厂为了让你以为工艺还在跟随摩尔定律,而硬是乘以0.7得到,但实际不存在任何意义的数字。
第二,近两年我们相对详细地剖析过7nm、5nm、4nm工艺技术。近代尖端制造工艺,实现晶体管密度的提升,有大量技术手段不再是器件层面的pitch scaling,而是单元(cell)层面的scaling booster或DTCO。其实单元层面的调优,你可以理解为优化晶体管的摆放方式。这类方案带来的晶体管密度提升的确还不错,但它从侧面印证了尖端制造工艺,要在器件层面做pitch scaling已经难上加难。
相似的,技术层面可反推的是,当代先进封装技术成为一个新的技术重心,就不难发现制造工艺进步带来的收益正在减少。
第三,加速计算和专用处理器/单元用得越来越多。比如苹果芯片在疯狂堆砌媒体引擎专用单元;Intel的酷睿/至强处理器这两年正在往里加各种专用单元,包括强化AI计算的CPU后端,还有整颗SoC上出现AI专用单元、图像处理器单元。
这一点表现最夸张的,应该是英伟达GPU。数据中心GPU都在走DSA之路(如专门的FP8 Transformer引擎);而图形GPU,不光有专门用作光追计算的RT core、用于AI计算的Tensor core——现在RT core里面还在堆更专用的硬件单元。今年更新的Ada Lovelace,又在RT core里至少加了两个新单元用于加速光追。
更有趣的是,英伟达认为单纯的图形渲染速度太慢,还靠AI单元来生成更多的像素和帧——这都已经脱离图形范畴,而借助于计算机视觉技术加速了。要知道GPU本来就已经是图形计算加速器了,现在这个加速器还在依赖更多的二级甚至三级加速器来加速计算:算力不足以支撑的部分,不惜让AI技术来脑补。
在芯片设计层面增加越来越多的专用硬件,无非就是因为摩尔定律越来越疲软。
难以维系行业发展的摩尔定律
不过这也引出了另一个议题,就是当代人类社会的算力需求已经远超摩尔定律能够提供的水平了。换句话说就算摩尔定律还能延续,现在的算力需求也远超单位面积晶体管数量翻番可达成的效果。
比如仰赖晶体管密度提升,2018-2022年英伟达GPU也不过实现了同系列芯片的晶体管用量增长4倍。但具体到光线追踪这一个应用上,英伟达或者说市场期望达成的就是16倍甚至更高的性能提升。这额外的倍数靠摩尔定律搞不定。更不用说AI训练应用算力需求每3.5个月就翻番。
所以我们看到,电子工程和计算机科学正在变着花儿地做架构调整,今天软件的某个中间件优化一下提升1倍性能,明天硬件内部要做调度优化或增加专用单元,再提升1倍性能。现在受惠于尖端制造工艺的那些芯片设计公司,即便每年宣称性能提升x倍,这其中的90%可能都需要依赖开发者改代码才能达成。自下而上的架构优化,全栈的各种调整会成为将来电子科技发展的主旋律。

不过摩尔定律终结也并不需要太过悲观。电子科技从沙子到最上层的软件应用,中间有那么多的环节都有优化的余地,依然能够在未来很长时间里带来性能和能效上千倍的提升——这一点过去1-2年里,各层级市场参与者似乎都提出过这样的论断。
我们现在已知持续提升性能和能效,让电子器件成本下降的技术至少包括了:DSA——也就是专用架构或专用计算,这个分支下最为全面开花的技术大概就是AI了;各层级的架构优化——比如制造层面的晶体管结构优化GAAFET/CFET、单元层面的nMOS/pMOS结构3D化,封装层面的结构chiplet化和3D化,当然还有更底层材料层面的优化;甚至包括计算范式的彻底颠覆,比如将原本的存储器用作计算单元,以打破存储墙限制。
从更系统的层面来考虑优化方案,或者以上层应用为驱动来定制系统结构,其中也包括更上层软件的各种优化——从全栈和更系统的角度来解决问题,也是诸多电子产业市场参与者的共识,部分EDA厂商就已经在这么倡导了。
在具体实践上,真正的市场参与者自然比我们更有发言权。以上我们提到的这些方案,在今年的IIC深圳和全球CEO峰会上,你大概都有机会听到。他们作为真正的电子科技产业推动力量,会给出更具实际意义的技术和方案。所以不要错过将于11月10日在深圳大中华交易广场举办的IIC深圳(2022国际集成电路展览会暨研讨会)。同期举办的全球CEO峰会、全球分销与供应链领袖峰会、国际工业4.0技术与应用论坛及第24届高效电源管理及功率器件论坛异彩纷呈,点击 这里 或扫码 报名参会。


