
这两个月,Intel在显卡产品上的更新动作愈加频繁。比如8月初Intel在SIGGRAPH图形大会上首次展示了Arc Pro显卡——面向专业图形市场;上周则正式推出了数据中心GPU Flex系列——不过这个系列是基于Xe-HPG架构,和Ponte Vecchio那样更纯粹的加速卡(Xe-HPC架构)还是有区别,面向的应用类型包括游戏、视频媒体、VDI(virtual desktop infrastructure)、AI等。
前不久的Hot Chips 34之上,Intel更详细地介绍了Ponte Vecchio,并宣称Ponte Vecchio相较英伟达A100有2.5倍的性能优势。似乎无论是PC游戏、专业视觉、数据中心图形计算,还是数据中心AI与HPC加速,Intel都有大举攻城的意思。而且产品上和英伟达、AMD高度重合;即便Intel在这一领域还是个十足的新手。


很少有入市新手以这么快的速度全面覆盖GPU应用的各方各面,毕竟无论在哪个市场上,英伟达都占据着绝对的强势地位。尤其像PC游戏、专业图形加速这些应用领域,实则都已经发展到了相对成熟的阶段,早就过了百花齐放的市场争霸期。新选手要在其中分一杯羹已经有十二分难度。
只不过数据中心市场的确还有巨大发展空间,要不然近些年也不会涌现出这么多面向数据中心的AI training芯片,以及完全不做图形计算的GPU产品。在这一市场上,由于异构计算趋势的到来,GPU的地位空前显赫,CPU的市场地位已经大不如前。这应该也是Intel当前花大代价做GPU(和更多DSA芯片)的关键。
有关Intel面向数据中心的GPU,我们以后再谈。从既有PC市场的少量Arc GPU铺货情况来看,在面向PC的游戏GPU产品上,Intel现下最欠缺的还是软件和生态:包括驱动程序的效率、游戏的支持度,以及部分新特性的亟待问世。但这也的确不是一蹴而就的,英伟达和AMD都耕耘几十年了。
这跟摩尔定律有点关系
面向游戏和图形计算的新特性里,有一项是当前的大热门,即基于AI的超分(Super Resolution)技术:用通俗的话来说,也就是把低分辨率的画面upscale为高分辨率。这么做的好处在于,GPU渲染低分辨率的画面,超分过后,也能获得不错的画质和观感;更重要的是,因为只渲染低分辨率内容,所以游戏帧率还能显著提升。
以前我们说,游戏画面的清晰度(分辨率)和流畅度(帧率)是一对矛盾体,GPU渲染更高的分辨率必然意味着要牺牲帧率,反之亦然。超分技术似乎就是为了解决这个问题而生的。超分技术本身一点也不新鲜,实施方案和算法各异。
现在会被广泛提起,一方面是因为摩尔定律放缓,GPU堆料、图形算力提升不像以前那么容易了,急需技术来解决清晰度和流畅度的矛盾。另一方面则在于AI技术崛起,为超分提出了新的思路——而AI技术的崛起,和摩尔定律的放缓实则也有关系。前不久我们撰文详谈过英伟达DLSS和联发科Game AI-SR技术。这两者都是基于深度学习AI技术来做超分。

Intel版本的AI超分技术名为XeSS(Xe Super Sampling),关注GPU技术的同学对此应该也不会陌生。XeSS本身就是Intel在大力宣传的GPU技术点。毕竟谁不希望花更少的钱,获得更高的游戏帧率呢?我们在前不久的Dell灵越14 Plus笔记本体验文章里就提到过,超分技术对于入门级GPU的意义非常大:原本很多入门GPU无法畅玩的游戏,在有了超分技术加成之后,也能在不怎么影响画质的情况下畅玩了。
上周Intel专门发布了一个大约40分钟的视频,用于解析XeSS技术——而且是让Intel Fellow Tom Peterson去讲的,可见对于XeSS技术的重视。不过我们感觉,这则视频的内容基本还是在做科普,而且是大方向AI超分技术的科普。所以我们认为,它对于理解广泛意义上的AI超分技术都算有帮助;在讲解上比此前英伟达公布的资料更详实。
那么这篇文章即可作为AI超分技术的科普内容,来大致谈谈AI是怎么做超分的。起码在大方向上,它与英伟达DLSS也十分相似。
游戏中,插入超分流程
GPU工作有个渲染流水线,先干什么、再干什么,最后成为屏幕上显示的画面——也就是一帧一帧的影像。每个帧都需要这样工作,帧连在一起就构成了连续的画面。下面这张图展示了对于一个传统的4K分辨率帧而言,3部分工作的占比情况。其中渲染(render)占了绝大部分时间。
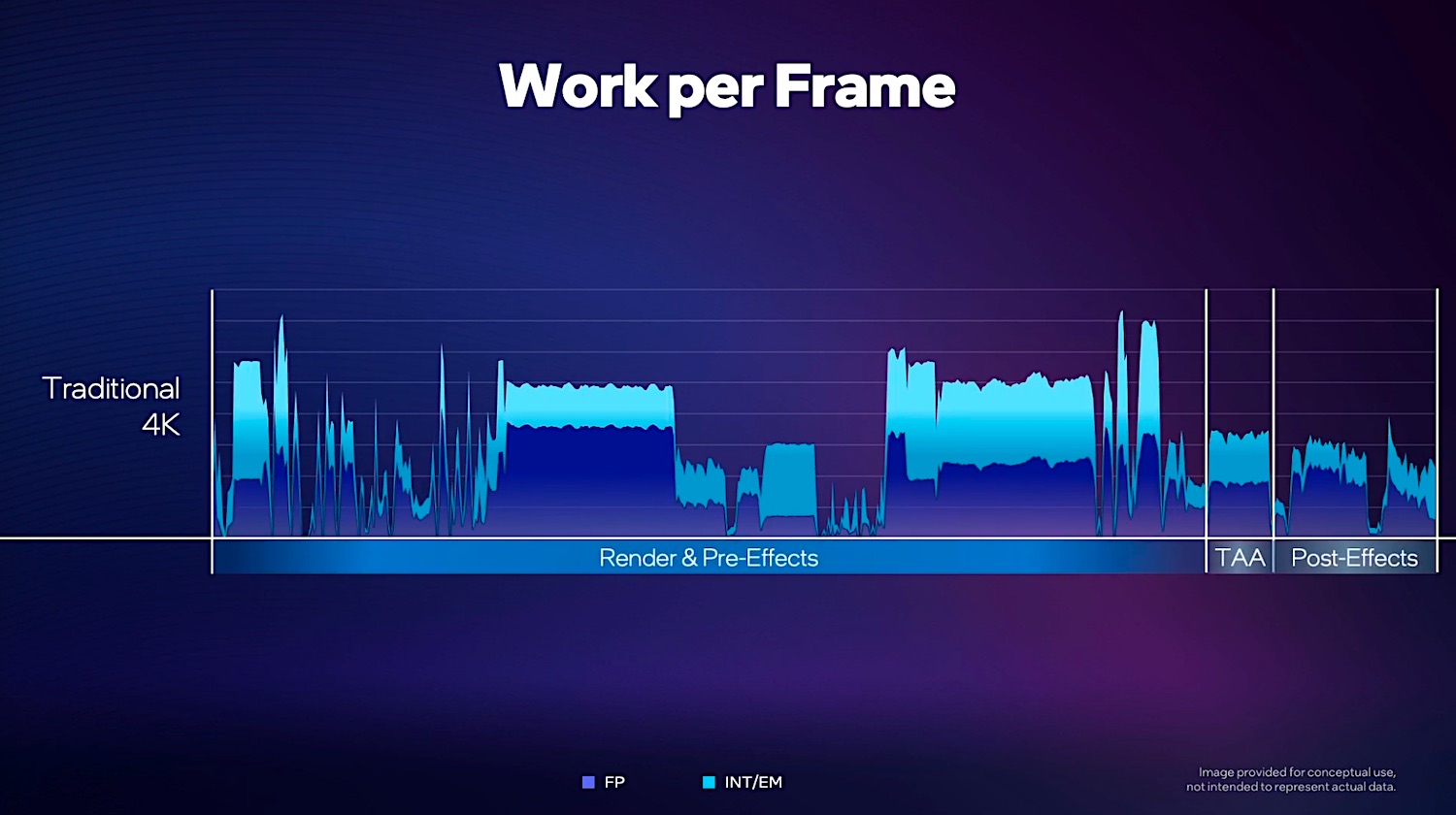
TAA(时域抗锯齿)和后处理(Post-Effects)只占了一小部分。如果我们要让每一帧处理的时间足够少,那么减少前面的Render&Pre-Effects的时间显然是最符合直觉的。减少这部分工作时间的方法,自然是渲染更少像素(更低分辨率)的画面——比如把4K分辨率降低到1080p,或者把1080p分辨率降低至480p。
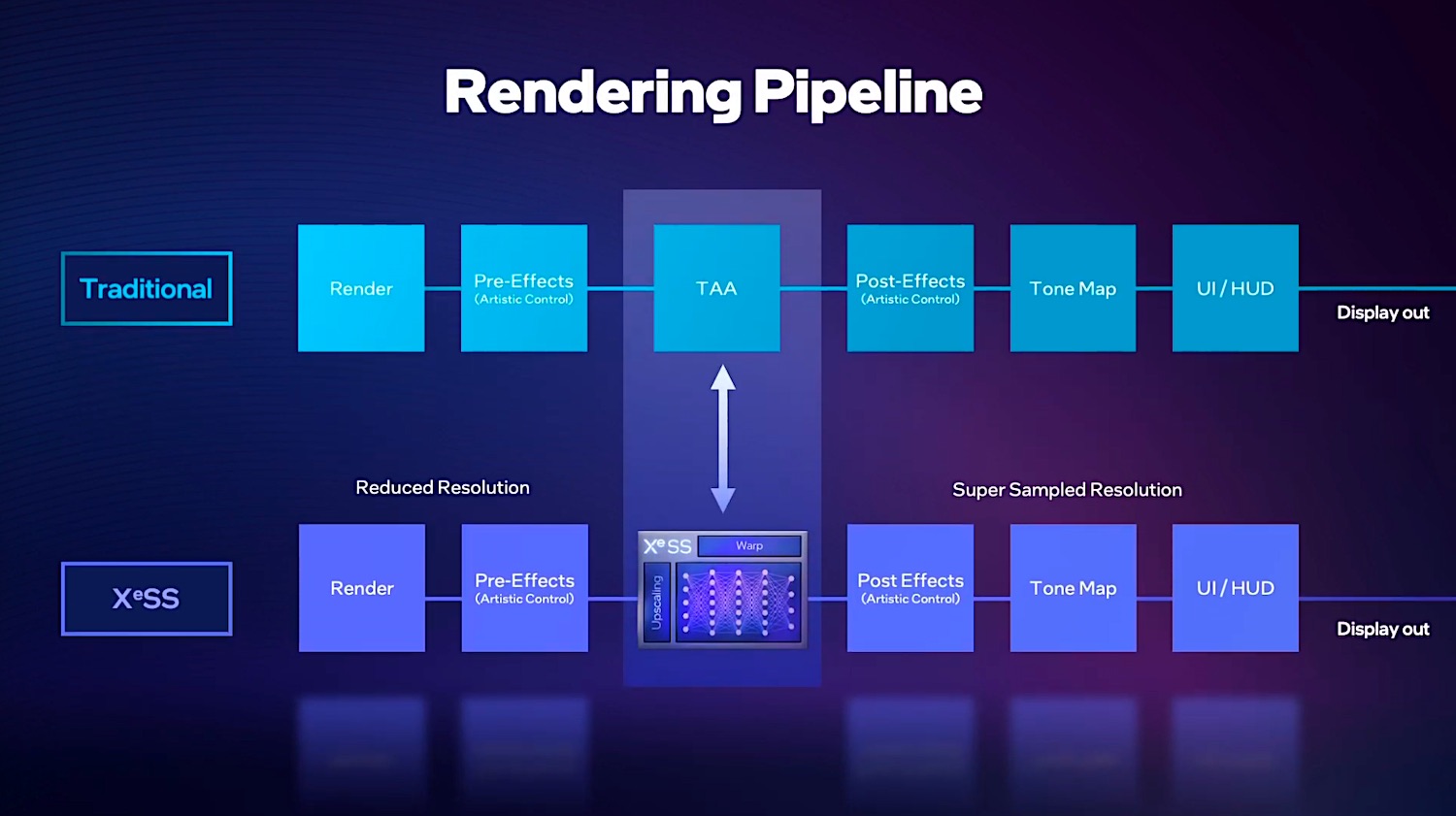
而另一方面,将TAA抗锯齿这个步骤换成超分(如XeSS),前后工作内容不变。那么每一帧所需的时间就能缩短到如下图所示的程度——因为Render渲染阶段就不需要做4K分辨率的活儿了,所以处理时间显著变短;XeSS相较传统的TAA所需的时间当然会更久一些——如前文所述,XeSS就是把1080p分辨率的画面再upscale为4K分辨率:
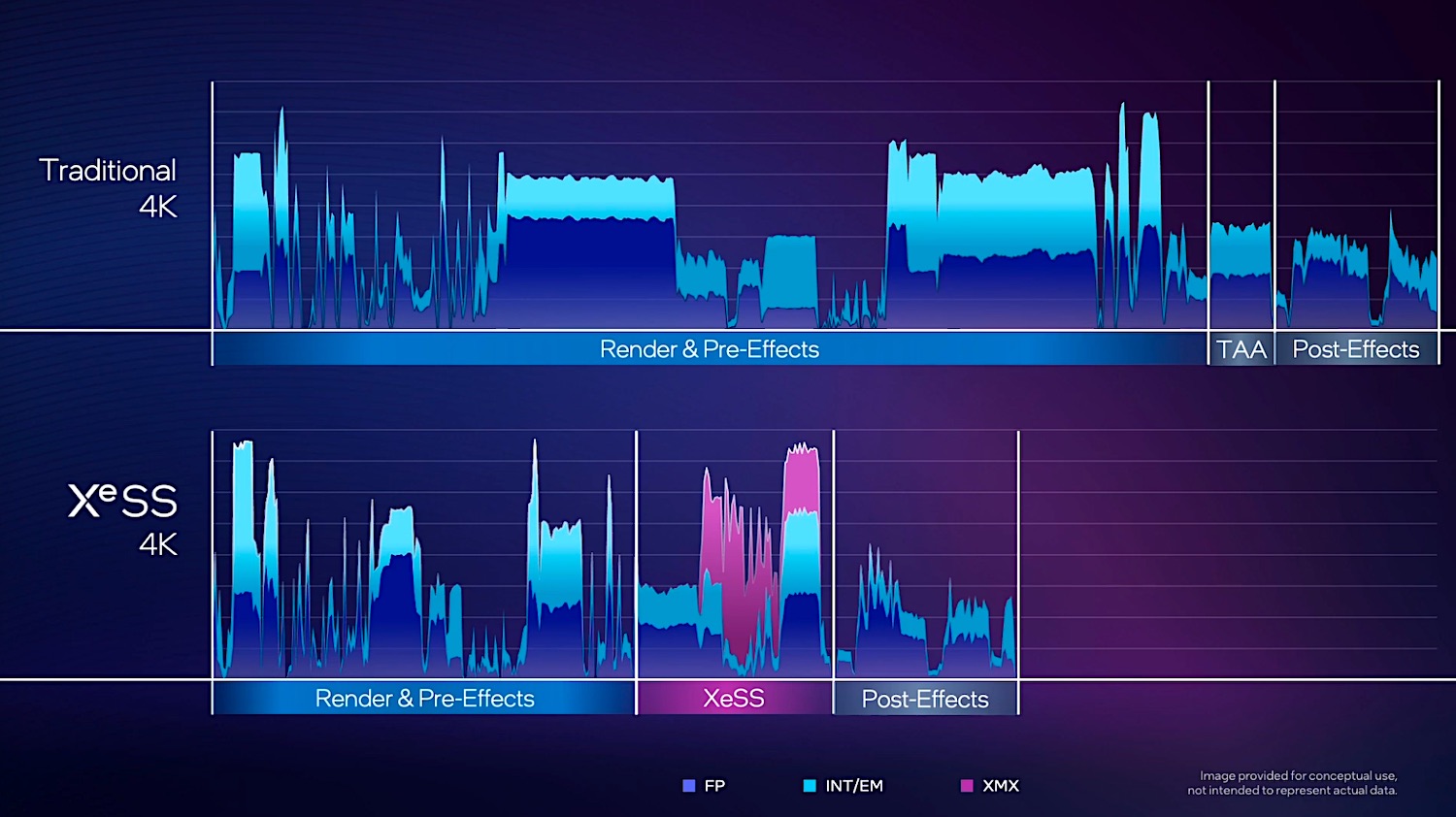
值得一提的是,XeSS阶段的工作项目中多出了紫色的部分。这部分就可简单看作是AI单元或对应指令的工作过程,所以这是个基于AI的超分技术。
对于英伟达GPU而言,这部分工作交由Tensor core完成,联发科则部分交给APU,Intel将自家GPU内部的AI单元称作XMX(Xe Matrix eXtensions)。此前我们在解析Intel GPU架构的文章里提到过,对于Intel这一代用作图形计算的GPU而言,每个Xe核心都会配16个XMX矩阵引擎,结构上也就是脉动阵列(systolic array),用于AI工作的加速。
Tom Peterson特别谈到,这里的紫色部分虽然看起来不多,但实际上因为XMX指令在矩阵引擎中达成了16倍的性能提升,所以如果要是按照比例画这部分工作,那么已经超出这张图的天际了。类似tensor core和XMX引擎的存在,本质上都是当代处理器朝着DSA方向迈进的佐证。
用AI来搞超分
以上是从渲染管线和阶段的角度谈XeSS所处的位置。接下来就涉及到XeSS究竟怎么工作的问题了。本质上将低分辨率的画面升格为高分辨率的算法,都是做一系列算术题。只不过不同技术所做的算术题不一样,效果和复杂度也存在差异:不管是如何更好地抗锯齿,还是把一个像素神奇地切成几个。
而AI的本质是通过训练,搞出一个适用性很高的模型或网络。这个神经网络会从外界获取数据,然后生成输出。对于AI超分而言,从外界输入的就是低分辨率的帧,经过网络以后,生成高分辨率的帧——这个输出的高分辨率帧起初应该是很不理想的。所以还要将其与原先就准备好的、用做参考的超采样、高分辨率图像做对比。

通过这种循环往复的对比和训练,就能不断修正输出的帧、修正权重参数,令网络模型达到理想的效果。这个过程一般会在云端进行,因为需要大量算力。最终得到满意的模型,这个网络就可以拿来用了——也就是在游戏过程中,将低分辨率的帧输入给该网络,就能获得相对准确的高分辨率帧,几近达到原生高分辨率渲染的效果。使用该网络的过程就叫AI推理(inference)。
我们日常所说狭义的AI大致上也就是这么回事。从更靠下的层面来说,这类繁重的计算任务通常意味着海量的乘加运算,下面这张图是在进行AI推理操作时,一般MAC乘法累加运算的过程,先对两个寄存器中的Int8数据进行乘法运算,然后将结果与其他寄存器中的结果进行累加。大量此类运算在此过程中进行。
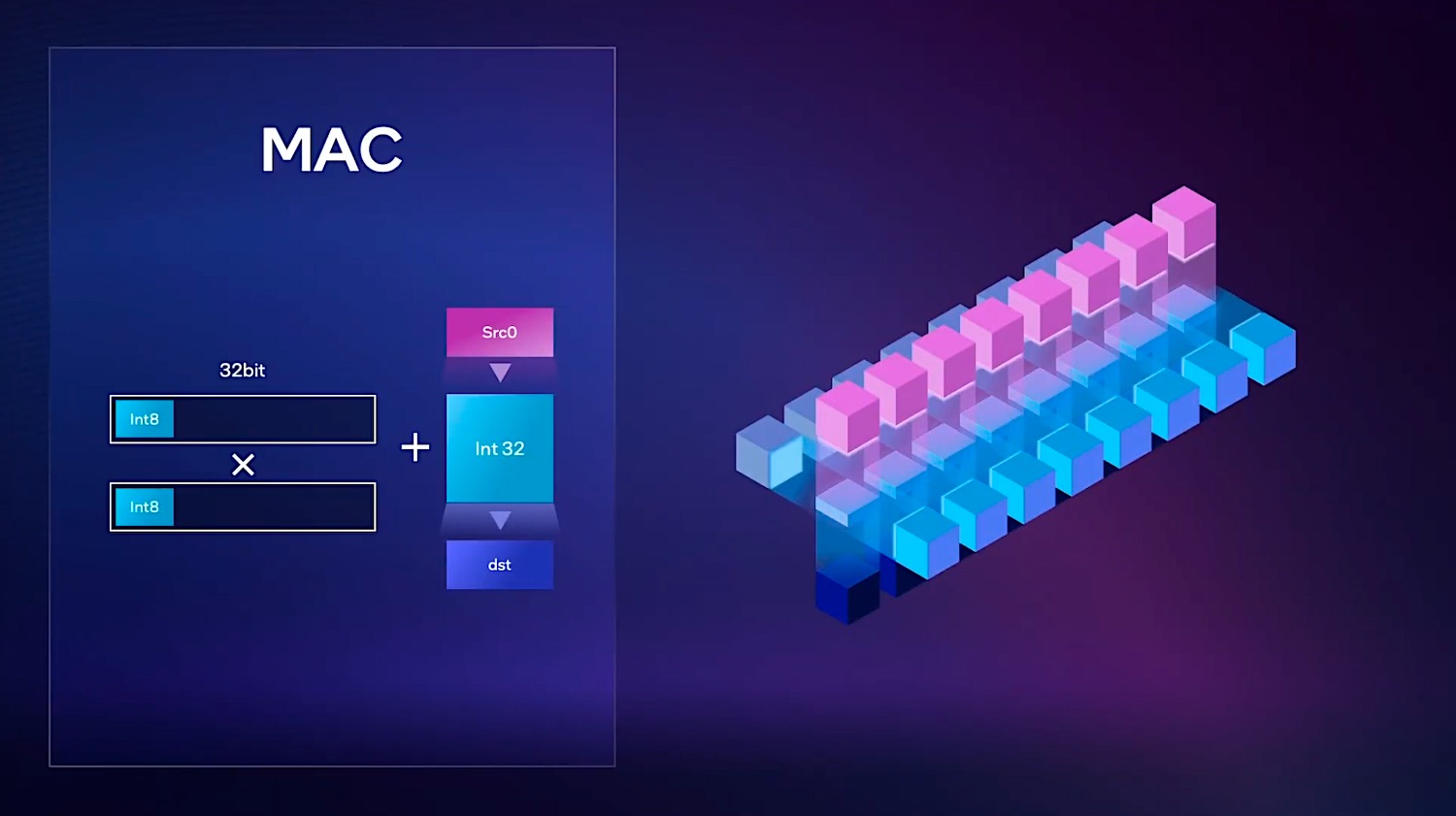
对于这类计算来说,专用的AI单元显然有着高得多的效率。比如对于XMX矩阵引擎而言,就能大规模地并行做此类乘加运算,相比进行一次次乘加、写出结果,速度也就快得多了。所以Intel说XMX对此达成的吞吐提升最高有16倍。

在游戏中真正实施这套方案的流程实际上还会更复杂一些——而且未来可能还有进一步进化的余地。英伟达DLSS发布至今已经更新了很多版本。在英伟达DLSS 1.0刚发布之际,游戏玩家的反馈并不好。在游戏过程中,因为DLSS的接入,不少动态画面会出现伪像。
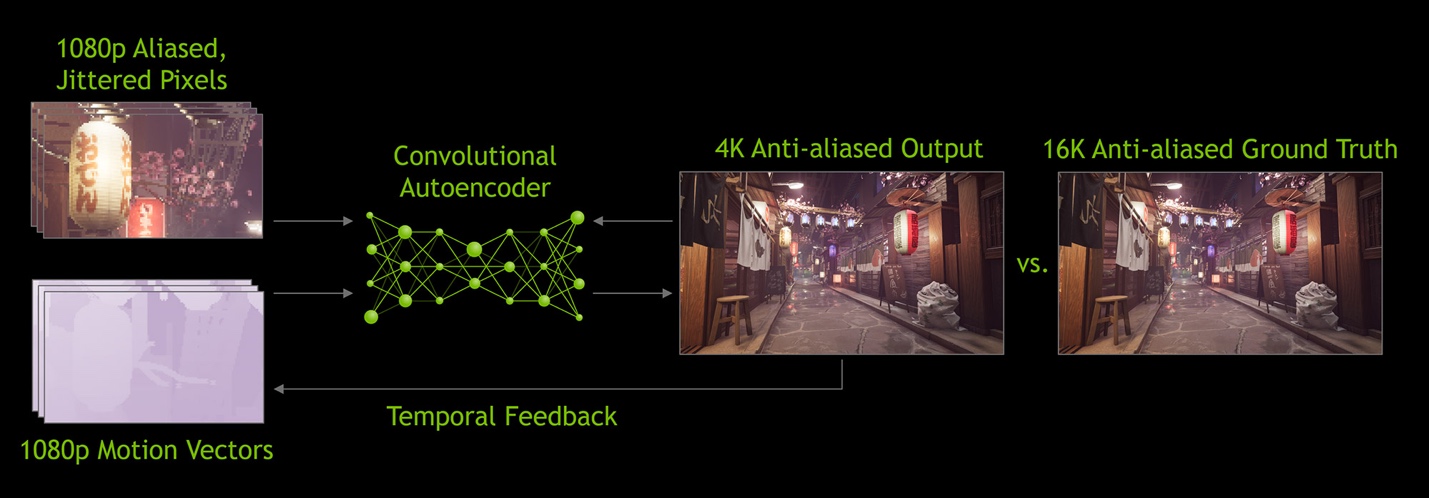
Nvidia DLSS 2.0
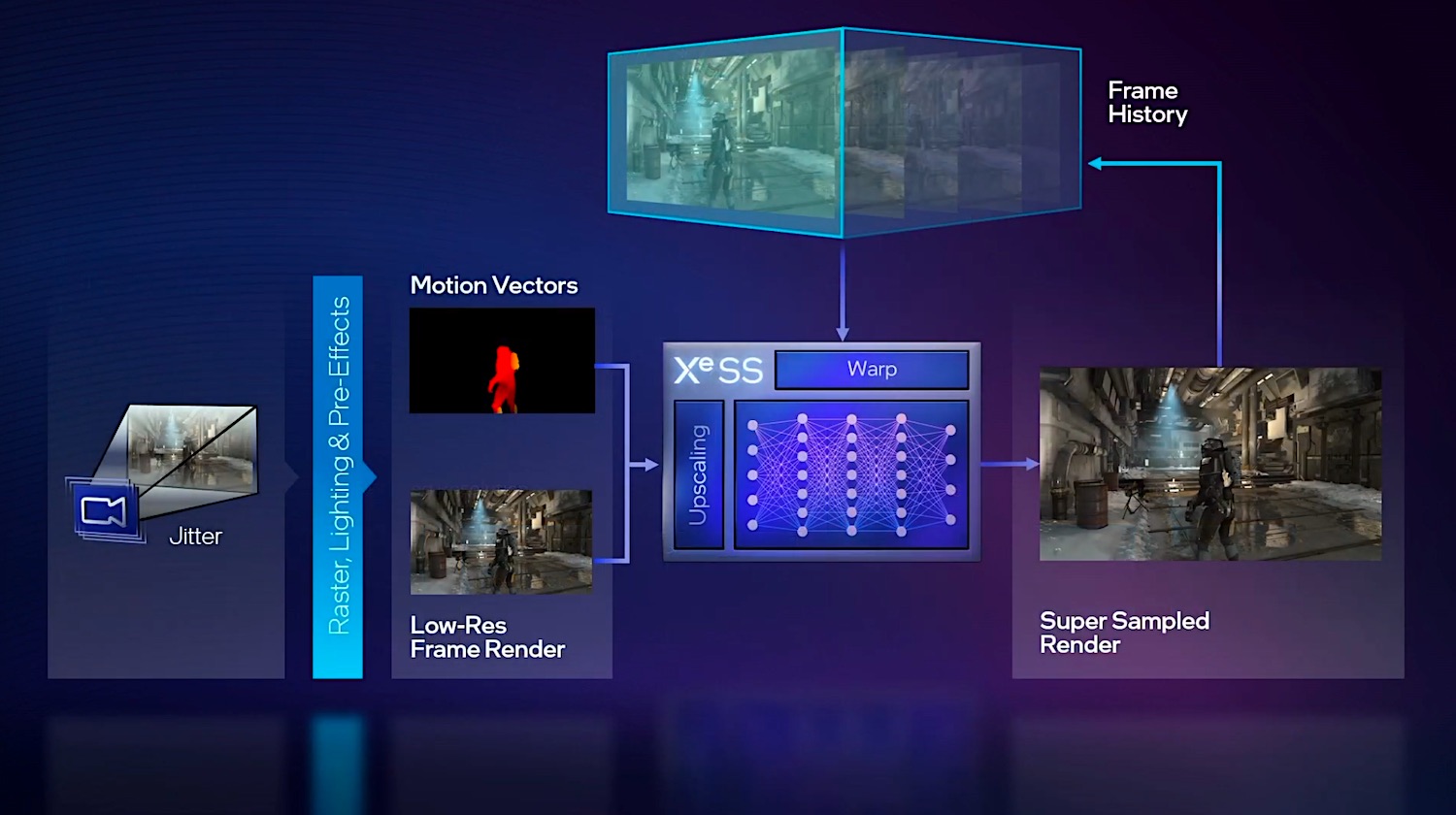
Intel XeSS
于是DLSS 2.0对实施方案做了优化。此前的文章里解读过DLSS 2.0的工作流程。而XeSS实则与此还颇为相似。对于XeSS这道工序而言,首先输入的是低分辨率帧,以及动作矢量(motion vectors)——对比一下DLSS 2.0会发现,英伟达也是这么干的。motion vector也是相当重要的。与此同时再加入已经生成的历史帧信息。
Tom Peterson在解释中还特别谈到了,会对camera进行抖动(camera可以理解为观察游戏画面的视角),以生成更多样本、更多数据。然后将这些连续帧再喂给XeSS,最终生成超分以后的高分辨率画面。下面的这个gif动态图,相对抽象地解释了这一过程。

中间的就是神经网络:从左边输入低分辨率帧、运动向量,生成超分以后的高分辨率图像——并且将该帧也将作为历史帧,成为后续帧的素材,并且“我们还会在前面抖动camera”——Tom Peterson说。
软件和生态问题
从前文提到XeSS所处流程,就不难发现,这东西是需要游戏开发者特别接入对应API的。一旦涉及到开发,就和生态问题有关了。对于任何专用方向的应用而言,生态都是逃避不了的话题。图形计算如此,AI更是如此。就像英伟达总是说自己可不只是一家芯片公司那样,软件和生态是其现如今制霸GPU市场的根本。芯片做的再好,却没有高效的软件搭配,或者没有开发者去应用,则芯片本身就没有价值。
即便DLSS 1.0正式发布至今也有3年多了,英伟达也仍旧在不遗余力地宣传和扩张DLSS生态。不同GPU厂商之间的超分技术是各有不同的,开发者接入不同的超分技术自然涉及不同的开发更动。
Tom在谈到XeSS SDK的时候说,其接入接口与TAA类似:“如果某个游戏用上了TAA,则接入XeSS也不难。”

比较值得一提的是,“我们也做了单独的模型来支持DP4a”。对于DP4a指令的支持,应该主要是让XeSS可以用到Arc之外的GPU上,其中也包括Intel现如今的核显(Xe-LP)。像核显这种图形计算资源紧张的GPU,接入超分技术的价值本身也是相当大的。
那么不出意外的,XeSS也对其他厂商的GPU提供支持,主要自然就是AMD和英伟达了。当然支持情况还是要看游戏开发者支持度。这本身也是一种拓展生态的方法。

Tom在技术讲解中也特别提到了DP4a指令的工作方式,其工作效率会比一般MAC指令执行要高,但也会显著低于专用AI单元。DP4a能做到4倍于MAC的并行度,具体如上图所示——可与前文提及的MAC和XMX做比较。

这次视频讲解中,Intel展示了20款游戏对于XeSS的支持。其中已经有部分游戏发售,未来应该会加上XeSS的支持补丁。与此同时Intel也特别提到了两款新游戏,一则将在今秋发布的游戏《使命与召唤:现代战争2(Call of Duty: Modern Warfare II)》.
还有一款是预计于2025年发布的《Instinction》。去年我们就看到过有关这款游戏的预告,其亮点之一是会采用虚幻引擎5(UE5),包括对其中Lumen照明和Nanite虚拟几何体特性的采用;另外当然就是会加入Intel XeSS支持。Intel特别提到这款游戏,似乎是为了表明自家对XeSS技术长期做支持的决心。
此前Arc显卡发布之初,网上对XeSS特性的上市时间和初期游戏数量实则是多有诟病的。我们倒是认为先期游戏支持数量还不错,只不过还要看XeSS达成的画质水平如何,毕竟DLSS也不是发布头一天就广受好评的。
今年3月,Arc 3发布之际,Tom在接受采访时,我们就问过XeSS与DLSS相较,画质水平和帧率提升效果如何。Tom回答说“很难去直接比较我们的AI网络和别家的同类技术”,“这对对比、评估、基准测试来说,其实都是个全新的领域”。实则在综合画质水平和帧率提升幅度因素之后,这样的对比的确很难进行。

不过同样作为生态的一部分,Intel似乎和UL Benchmarks也展开了合作,开发者版本的3DMark已经加入了针对XeSS的测试项目。只不过比的也就是开启和关闭XeSS的两种场景下,游戏帧率变化情况;另外也支持设定渲染固定帧数,并放大对比原生渲染+TAA和XeSS之间的画质水平如何——不过这个对比大概是指如1080p渲染+TAA,和1080p渲染并XeSS超分至4K后,两者的静态画面比较。
基于画质+帧率,应该也能做指标量化,来衡量不同的超分技术可达成的体验加成效果;感觉3DMark未来也可以推这样的Benchmark。这对推动AI超分技术的持续进化大概也会有帮助吧。
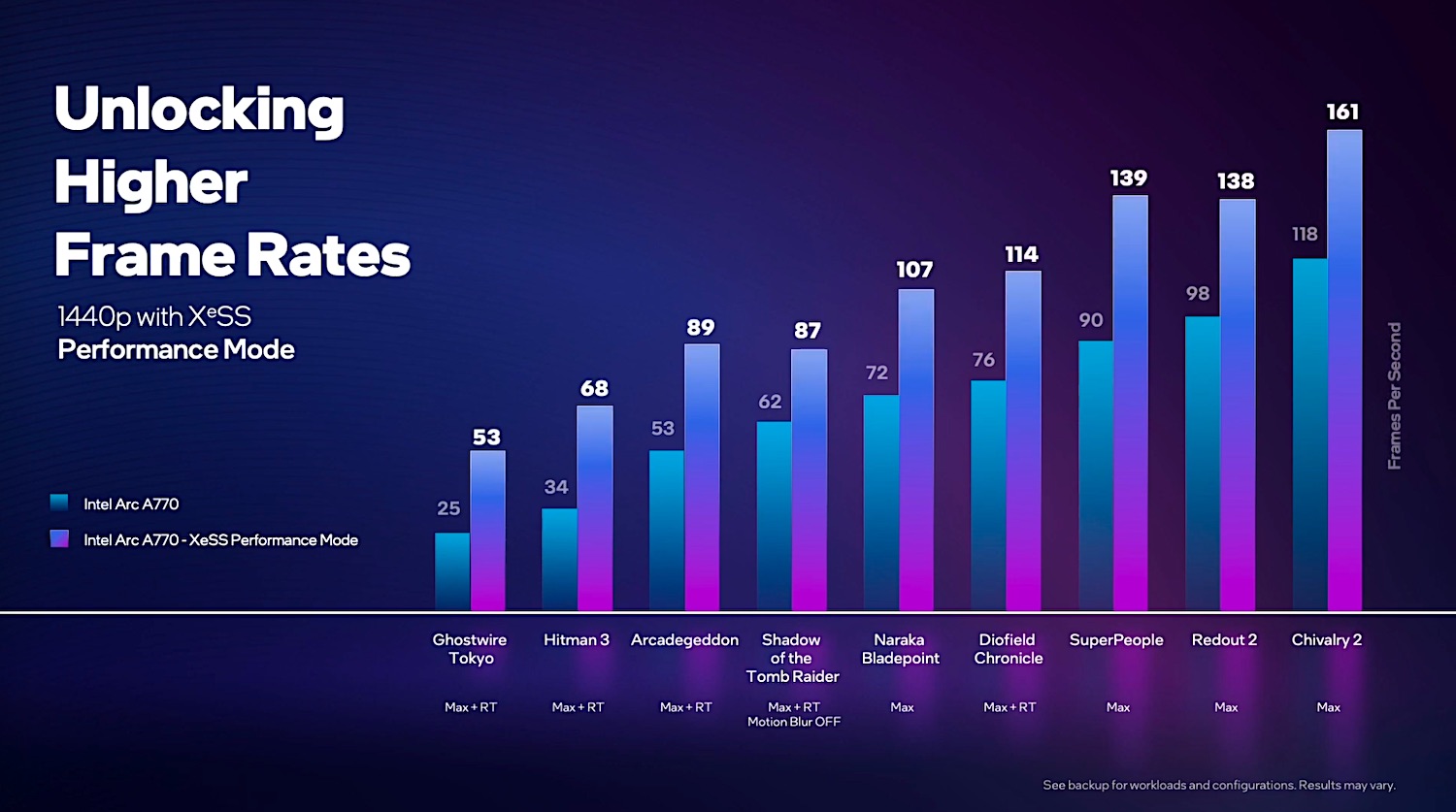
最后展示一下Intel给出的第一方帧率提升数据吧,这是基于Arc A770的测试结果,设定为XeSS性能模式,升格至1440p分辨率(看起来XeSS有Performance, Balanced, Quality, Ultra Quality多档可选——这个对应的主要就是从哪种分辨率upscale为目标分辨率,更低的分辨率达成更高的帧率,但画质会更差)。
Tom特别提到,像《杀手3》《幽灵线:东京》这种游戏的帧率提升是最显著的,有超过2倍的性能提升。“越是存在性能挑战的、跑在较低帧率的游戏,越能从XeSS技术上获利。回看前面的表就会发现,最长的渲染时间经过XeSS就能获得最大的收益。”所以我们始终觉得,全系不同定位的独立GPU普及XMX单元,还是有很大价值的。至于XeSS的具体表现如何,还是交给未来的市场表现来说话吧。
