
今年WAIC可谓是国产AI技术相关企业的主场,尤其是AI芯片和GPU厂商。至少有两家AI芯片企业在WAIC上更新了自家的系统级解决方案——而且从这些企业的产品更新也能够体会到,国产AI芯片企业越来越脚踏实地了。比如燧原科技在今年的WAIC上发布了“云燧智算机”(CloudBlazer POD)——从这种POD类设备的发布,能够看到国产AI芯片企业正逐步走向成熟。
从前些年开始,AI模型参数规模就以每3个月提高一倍的速度在发展,燧原科技创始人兼COO张亚林在WAIC “AI领Show”的主题演讲中说:“模型参数已经到了千亿,甚至往万亿级规模。”这是大规模算力方面的需求;加上训练并行的变迁,大规模集群是AI计算的必需品。

“算力底座不仅是芯片,还有板卡、软件。更重要的是什么?系统一体化。这块除了美国友商之外,中国国内还非常罕见。”张亚林说,“如何真正通过集群和系统的方式,使能AI大模型、达成更高的生产力已经成为一个关键的问题。”“中国计算中心落地过程,不仅对能效、算力密度有要求,还在部署、运维、集成等各方面都提出了非常高的交钥匙一体化的需求。”这是云燧智算机和集群诞生的背景。
云燧智算机及集群方案的诞生,也让燧原完成了芯片、板卡、服务器、集群算力中心解决方案的覆盖。
云燧智算机和集群
张亚林提到,目前国内数据中心的业务痛点,首先是集群落地的标准规范弱:“这么大的一个集群,其装配、集成、部署、运维,模组化标准化非常难。能否做到了开箱即用?”其次则在于专业性强,“集群在部署过程中,是否能够真正做到随时随地的监控、很快推动算力利用率、推动绿色集约化;这些问题并没有被很好地解决。”另外交付周期很长,“大量组件的搬运、组装、集成、部署、运维、上线等等,要等上半年、大半年甚至一年时间。”
这是本次燧原发布新品的基础。实际上,像英伟达、Graphcore这类企业早就有了POD, SuperPOD形态设备。燧原则藉由云燧智算机(CloudBlazer POD)的发布补全了这一形态,令其成为更大规模计算集群的基本组件。配合软件,一体化方案是燧原看来解决以上痛点的基础。

云燧智算机
除了邃思芯片作为核心之外,云燧智算机“是个一体化平台,软硬件、整个系统全部集成在里面。模块是标准的,液冷服务器所有器件标准化,非常利于即插即用和部署。”张亚林说,“除了硬件之外,还有强大的软件和平台、各种开箱即用的工具链。”“这样的云燧智算机整体能够达到开箱即用、上电即用的效果。”
燧原在官方介绍中提到云燧智算机采用一体化设计,“是转为人工智能场景下计算、存储、网络、软硬协同设计的标准化产品,提供高可用的整体安全设计,确保集群架构扩展性能符合预期,提供包括采购、安装、运维一体的交钥匙方案。”

云燧智算机整体设计
云燧智算机的内部构成如上图,整体由8个液冷单元组成——这是燧原与浪潮合作打造的。值得一提的是其中的液冷散热——似乎液冷已经是现在数据中心很流行的一个解决方案了,今年Computex上英伟达也发布了液冷PCIe板卡。张亚林在演讲中说,国家期望推动数据中心做到绿色集约、低碳高效,“液冷是绿色集约的关键,传统风冷越来越不能满足低碳、高能效需求。液冷是大势所趋。”
对企业来说,液冷本身是有助于降低散热、能耗和运维成本的;而且液冷本身也有利于相同空间下的性能释放,有助于达成更高的PUE(Power Usage Effectiveness,能源效率)。
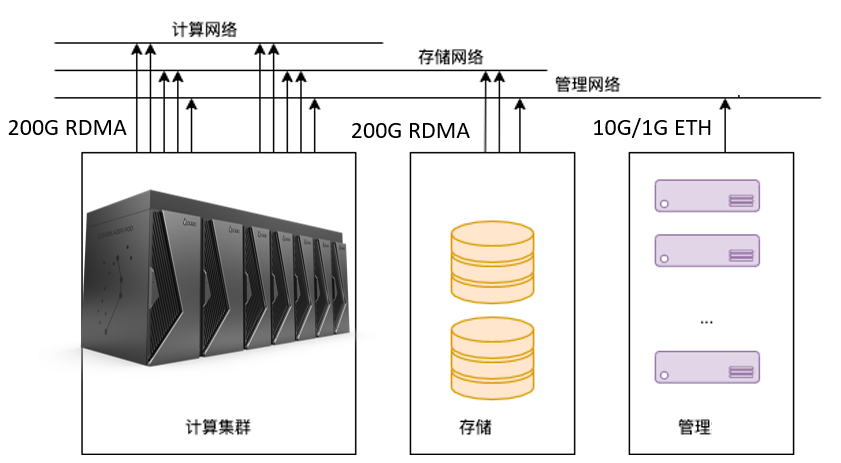
从算力参数来看,云燧智算机内的每个单元TF32算力为8PetaFLOPS。则在横向扩展以后,藉由“超千卡规模集群”能够“突破E级算力”。
通信带宽方面,节点内部为1TB/s聚合通信带宽,在节点横向扩展时节点间提供3个200Gb/s RDMA传输。另外张亚林也强调了存算网络分离,“可以独立地增加算力,或者独立地增加存储”。
在管理运维方面,其中内置了故障监测和智能诊断系统,用于监测存储、算力、能效等的运行情况;并能够在发现故障后立即报警。其中“集成高效的智能调度系统,并能做到秒级热迁移”——智能调度体现在监控算力利用率、发现算力瓶颈和功耗水平,达成智能化的算力利用;而“秒级热迁移”主要藉由组件化特性,实现即插即用。

横向扩展后的云燧智算集群CloudBlazer Matrix,即是通过横向扩展达成E级算力。燧原形容其方案是“预优化的”,设备是“预集成的”,系统是“预调优的”。
“我们可以根据终端客户、合作伙伴的需求,进行专门的半定制化。整个集群的算力、存储、模块、软件等都是可配置的。”张亚林总结智算集群的三大特点涵盖了绿色集约、自主创新、安全可靠。
绿色集约主要表现的是算力效率,以及数据中心PUE之类的指标。液冷方案也是其中的重要一环。而“自主创新”,则包含其中的软硬件和系统,和“整个液冷机柜都由燧原科技自主完成设计”;
“安全可靠”则体现在藉由算力调度和监控平台可发现问题,而且“整个液冷集群已经在客户那里稳定上线运行了两个月,没有出现任何问题”,“上线之前我们也和互联网头部客户一起,用美国友商测试最极端的方法精准打磨,经过了6个月的测试”,确保稳定和可靠。

此外张亚林也预告了燧原的POD产品路线,在突破E级算力之后,未来会以更大规模组合的方式,达成10倍以上的算力提升。“从目前的AI领域到泛AI,或者某些HPC的能力。”
软件和系统的价值很重要
软件和生态部分自然是燧池软件平台CloudBlazer Station。这个平台上有4个组件是赋能上层诸多应用的关键。分别是TopsMine智能算法管理平台、TopsDL训推一体化平台、TopsStack异构算力调度平台、TopsDiscover智能运维平台。

其中算法服务层的TopsMine是个算法仓,内置了不少算法;而TopsDL用以实现训推一体化,即令集群既能做训练,又能做推理。算法服务层的这两个平台,“把整个顶层的场景和算法,以及训推一体化,自动地结合起来。”
底层的基础设施部分,TopsStack异构算力调度平台,是将硬件的算力调用起来,“下发的大量任务通过这个平台能够形成最智能的分发和使用”;而TopsDiscover智能运维平台用于监控存储、算力等的使用率、能效情况,以及故障监测——也支持远程服务访问,实现远程监控集群的运行情况。

对燧原这类AI芯片企业而言,系统和软件的确是“算力服务应用的关键”。现在的AI芯片面对多样化的场景、巨量化的模型,要求规模化的算力;对开发生态而言,易用性、迁移性、“泛化性”、编程性都格外重要。这些实际上是一家已经把AI芯片做出来,且趋于成熟、要正式起量的企业更愿意去谈的部分,是发展中真正的难点;也是英伟达这种竞争对手把握的能力。
从底层硬件 - 芯片到板卡,再到服务器与集群;到中间层的燧池软件平台;以及上层的应用,包括各种网络模型,如视觉模型、语音模型、推荐模型、多模态大模型等。似乎今年不少国产AI芯片企业都开始强调自家的“一体化方案”,而着墨于系统和软件平台,体现的实则也是芯片的真正落地。
这套方案各组成部分的不断完善,也是燧原这样的企业需要花大量精力不断推进和迭代的。软件方面和更上层,“我们会专注于和所有的客户一起打磨整个业务系统,提高我们的AI生产力”。系统方面,“我们会持续优化它的整体价值——也就是TCO(总拥有成本)。通过芯片、板卡、系统集群成本,以及软件的大量迭代,保证更低的TCO”,“不仅仅是整个集群的建设成本,还有部署运维成本,包括电力开销成本。”
体现走向应用场景、落地的一句话是张亚林所说的:“我们现在提出软件和系统的价值。最近工信部也一直在强调,真正的AI要从终端去看,从用户去看,从场景去看,从系统角度去看,而不是简单去谈未来和愿景。”今年WAIC在AI技术上的主体氛围即是如此,也让我们看到了以燧原为代表的AI芯片企业近两年真正的发展。
落地和应用
张亚林在列举当前燧原已经应用的场景中,除了“头部互联网公司”“大型股份制商业银行”“国家高新技术开发区”以及“国际奢侈品电商平台”之外,相对给我们留下深刻印象的是某“国家著名实验室”。所谓的“千卡业务集群”就是在这个实验室里应用的,被燧原称作“国内首个落地千卡规模液冷集群的AI算力企业”。

张亚林介绍说这个集群已经落地运行了两个月的时间,“这是一个集成的、高度稳定的、安全可靠的、真正大规模的复杂系统工程。千卡业务本身就有巨大的复杂度。”它特别谈到,“我们1280张卡已经做到了0.9的线性度,未来我们还会继续优化。这样的线性度本身就代表了多卡通信的优化和算力的高可用。”“据我所知,目前1280液冷卡集群,0.9的线性度在国内是绝无仅有的。”
燧原列举的数据中提到,该实验室数据中心因此达成的PUE≤1.15,电力消耗降低了30%。
除此之外,其它的集群典型应用还包括“西南核心省会城市‘1+5+N’新型算力中心”,上层应用主要是城市安全、智慧交通、智慧教育、智慧社区、智慧工地等;从介绍来看,主要是藉由计算机视觉来打造智慧城市,比如说用电调度、社区管理、疫情推演等等。
以燧原为代表的国产AI芯片厂商,如今更愿意去谈系统、软件、应用,以及与合作伙伴间的合作——换句话说是让芯片落到实处。从产品形态的补全,到更加着眼于落地,这样的成长是显而易见的。
发布POD、集群,强调系统和软件生态的重要性,并将其落地转化为生产力,无一不体现着现在的国产AI芯片企业已经脱离了过去讲故事、卖情怀、谈愿景的初期阶段,朝着更具切实意义的方向迈进。或许对于整个行业而言,这些都是AI芯片从大量步入成熟的开端。


邃思2.5 AI推理芯片

邃思2.0 AI训练芯片

云燧T21 AI训练OAM模组

