
封装(packaging)是半导体制造流程往后的一道工序:把一片硅造出来,用某种方法将其连接到板子上。以前封装企业不像一般前道制造企业那么受重视,封装供应链常被称归于“后道”工序。
但前道生产制造工艺的技术行进步伐放缓,行业的注意力开始往封装转移。尤其是先进封装工艺,已经成为承托未来半导体技术发展的重要依据。研究机构Yole的数据显示,2021年先进封装市场规模已经达到了约350亿美元;并且到2025年这一数字将上升至420亿美元。
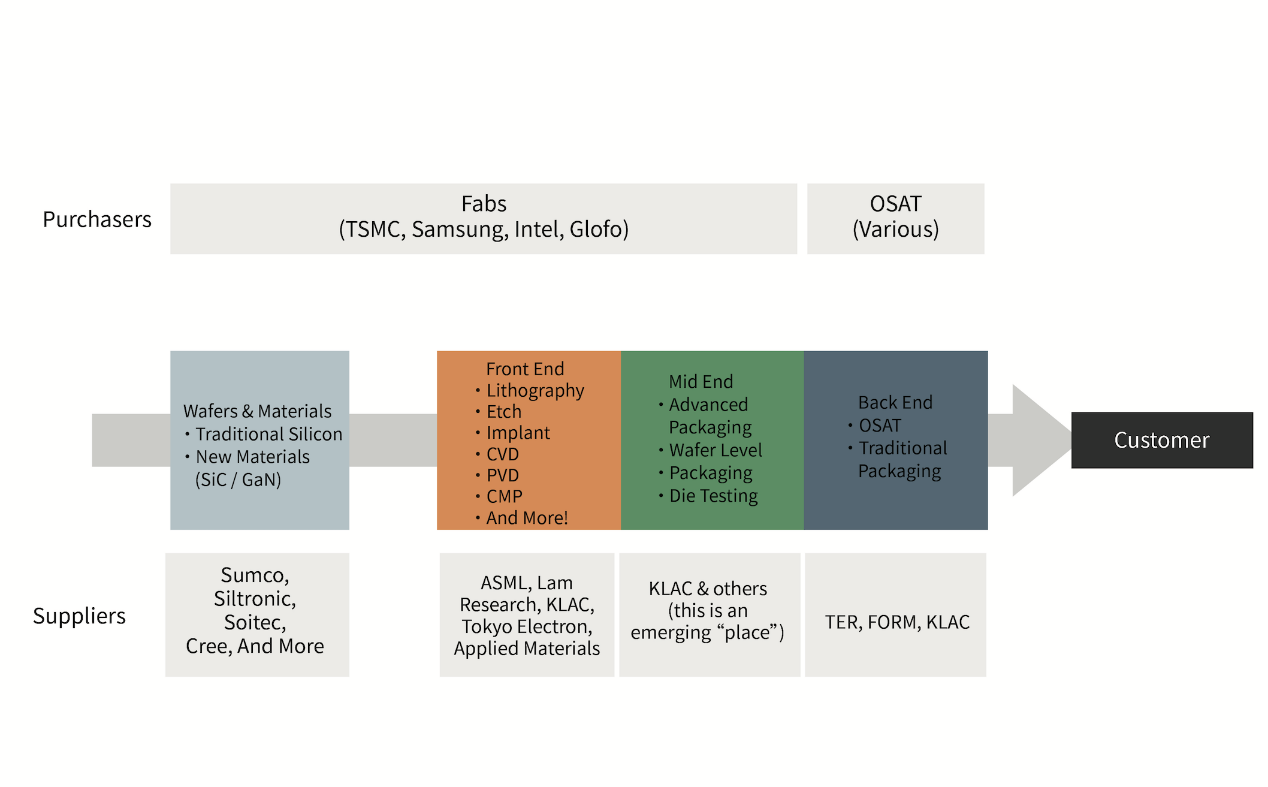

图1,先进封装所处环节
市场营收数据在我们看来还不是最紧要的——抛开技术革新不谈,市场层面“先进封装”颇有重新定义封测产业链价值,或转移价值重心的意思。如图1所示,先进封装在流程中处在“中道(mid-end)”的位置。以前封装预算是被排除在WFE(Wafer Fab Equipment)预算之外的;但从2020年开始,晶圆级封装也包含在内了。这是值得深思的。
长电科技去年提出从“封测”到“芯片成品制造”的概念升级,长电CEO郑力提到:“‘封测’这个词已经不能很好地表达‘先进封装’的含义,以及高密度封装的技术需求和技术实际状态。所以以‘成品制造’去描述更为贴切,可以反映当下的集成电路最后一道制造流程中的技术含量和技术内涵。”这应该是对先进封装技术对产业链影响的最佳写照。
本文尝试从大方向谈谈先进封装工艺发展现状及前景。

先进封装技术的诞生基础
“先进封装”是相较于“传统封装”而言的,去年我们有机会了解凌波微步半导体科技的球焊机——这就是传统封装技术所用的设备之一,应用于引线键合——就是用金属线将芯片焊盘和基板引脚进行焊合,实现芯片与基板、芯片与芯片之间的电气与信号互联。传统封装工艺在半导体生产制造行业的应用仍然非常广泛。
不过从我们能查到的资料来看,“先进封装”的确切定义存在差别。比如部分资料将先进封装窄化为2.5D/3D封装;某些专家则认为芯片级封装(chip scale packaging)和晶圆级封装(wafer level packaging)就可以算作先进封装。
但不同的“先进封装”定义有共性,即封装尺寸显著缩减、不同信号连接点间距变得很小。比如说高精度的芯片倒装(flip chip),从bump pitch(凸点间距)的角度来说,当该值小到某个程度(<100μm)可被冠以“先进”之名。其实单是芯片倒装,在实施方面都有不少差异可谈,比如Intel较多投入的TCB(Thermocompression bonding,热压接合)——这项技术对于Intel的3D封装方案也显得尤为重要。
体现间距微缩先进性的,如苹果芯片较早采用更高密度的封装技术,芯片die封装以90-60μm的间距量级放在载体晶圆/平台之上,相比传统的芯片倒装,密度高出大约8倍。载体晶圆/平台再进一步扩散出I/O(比如面向PCB板扩散出去),这是现在我们常说的“fanout”扇出型封装一词的来源(比如长电科技去年推出的XDFOITM全系列极高密度扇出型封装解决方案)。服务器、汽车等HPC平台的CPU、GPU等芯片当大规模应用这样的技术。
在说先进封装技术路线之前,有必要解决一个基本问题,那就是为什么需要先进封装技术?
摩尔定律描述的是一定周期(12-18个月)内晶体管密度提升1倍。而当代尖端制造工艺实现的大致上是每3年晶体管密度提升1倍。之所以实际发展步调更慢,除了制造工艺推进更有难度之外,另两个重要原因是SRAM缩放停滞,以及数据I/O发展速度很慢。尤其是后者,数据I/O传输每4年才提速1倍。所以晶体管密度推进,和I/O数据传输速率变化是不对等的。
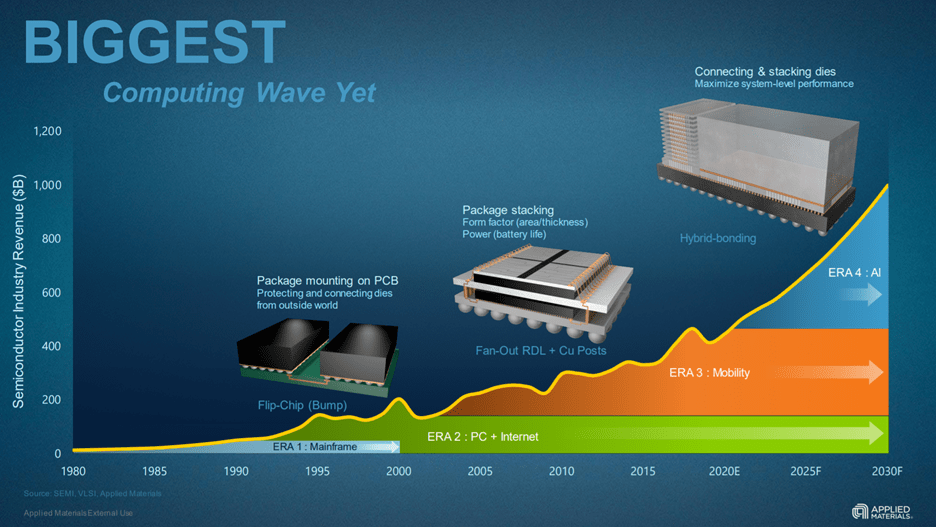
图2,封装技术发展方向,来源:美国应用材料
对于数据I/O来说,芯片本身需要容纳更多的数据通讯“点”才能实现越高的传输速率,才能与外界更高效地沟通。
90年代就问世的芯片倒装法,算是这个问题的一大推进之道。芯片倒装是相对于引线键合而言的。简而言之,die是翻转过来的,金属互联层面向下方,而晶体管倒反而在上面(图2)。芯片倒装也是后续更多先进封装技术的基础。
不过芯片倒装以往的发展也相当缓慢。传统倒装芯片封装,实现的这些数据通讯接触“点”之间的间距,或者说bump pitch在150μm-200μm之间。相对先进一些的,台积电N7工艺把bump pitch降到了130μm,而Intel 10nm工艺则令此值下探到了100μm。
这么多年来芯片倒装达成的bump pitch间距变化都是不大的。bump pitch所定义的I/O这20年来,只有2.35倍-4倍的提升。和芯片之上晶体管密度这些年来的变化相比实在是“不思进取”。
I/O密度或者I/O触点数难以提升也带来一个比较大的问题:更早的设计如果要用新的制造工艺,则设计本身对应缩小;但I/O会对此造成障碍,因为I/O还是需要很大的空间来摆放,整个die的尺寸难以对等的方式缩小;这被称为pad limit。
缓解I/O限制带来的性能效率降低有一些解决方案,比如说在die内增加更大容量的cache——也就是近存计算,借用这类方案的芯片现在也不少,典型的比如苹果。另一个重要解决方案是增加专用计算单元或电路,或者叫异构计算。比如现在大型SoC上都有专门的AI计算单元,专用于影像处理的ISP;数据中心的芯片上还有专门用来跑hypervisor、管理堆栈、相关于networking的部分(DPU)。
这些方案的本质都是通过增大die size,或“烧钱”的方式来提升芯片效率,缓解I/O数据传输的存储墙问题。不过增大die size也会遇到一个更现实的问题,就是die大到一定程度会超过了制造设备可处理的极限尺寸——这个限制叫做reticle limit。现在的高端GPU单die尺寸已经十分接近reticle limit。所以芯片并不能无节制地做大。
在器件微缩速度变慢、pad limit和reticle limit之外,还有一个比较大的问题,就是尖端工艺成本的显著攀升。这一点算是老生常谈。摩尔定律说随着晶体管尺寸变小,芯片制造理应带来成本效益。
但近两代尖端工艺的发展,让我们看到晶体管变小以后,单个晶体管的成本是在急剧增加的;芯片单位面积的造价也在急剧增长。这一点好像比较反常识,却是确确实实存在的。这就加剧了芯片做大以后造成的良率下降和成本的显著提升。
基于时代对算力需求的提升,I/O发展速度的局限性,近存计算/异构集成的发展趋势,芯片尺寸做大的限制,以及尖端工艺制造成本的急剧提升,先进封装工艺就成为时代发展的必然。Chiplet成为芯片设计与制造主流的必要性。通俗地说,chiplet就是把一片原本的大芯片切分成多个小片的chiplet,藉由先进封装技术将其“组合”到一起,工作起来就和一片大芯片一样。
当然chiplet也需要配合前文提到的bump pitch更为密集的先进封装方式。比如扇出型封装——更少受制于pad limit,不仅密度更高,而且封装的芯片间互联I/O数也不少;而chiplet这种小die形态,本身也搞定了reticle limit限制。
为了了解市场对于先进封装技术的态度,我们这次特别采访了Achronix公司。这是美国一家提供高性能FPGA解决方案的fabless公司——不仅包括高性能、高密度单独的FPGA芯片,也包括嵌入式eFPGA IP和PCIe加速卡。这类企业对先进封装的态度,应当是时下最有说服力的。
这家公司的eFPGA IP在异构计算上就有颇为广泛的应用。在是否采用先进封装工艺的问题上,Achronix公司产品营销总监Bob Siller表示:“我们目前的产品使用有机基板封装技术。面向未来,Achronix正在评估在我们的下一代产品中使用先进的2.5D封装技术,这将为异构集成提供更多的选择。”
其驱动力在于“先进的封装可以支持Achronix基于chiplet技术构建模块化产品。通过利用先进的封装,Achronix可以更快地进行创新以满足多个市场的需求,而不必为每一代新产品重新设计整个单片FPGA器件。”
Achronix本身也是ODSA(开放专用域架构)和UCIe产业联盟成员。UCIe(Universal Chiplet Interconnect Express)是推动chiplet互联统一的标准——从主要半导体企业对UCIe的支持都能看出异构集成、chiplet技术以及先进封装工艺未来的发展潜力。
Bob提到标准机构在开发下一代D2D物理层接口和控制器,借此Achronix客户能够用其eFPGA IP来构建定制的FPGA chiplet。“这些chiplet可以集成在一个有机基板或更先进的封装上,例如中介层(interposer)或扇出RDL类型的封装。”
异构集成成本分析
既然先进封装和异构集成技术这么好,技术采用为何还需要评估呢?前期的技术复杂性和成本投入应当是企业需要考虑的。Bob也在采访中谈到基于chiplet的解决方案更复杂:“挑战不仅在于这样组装成的系统的设计和验证,还在于已知为良好的chiplet在采购和制造过程中的组装测试。如果chiplet及各部分来自不同的制造商,那么D2D接口的互操作性和合规性测试也会很复杂。”
这是从更高层面去谈先进封装实践的复杂性了。实际上chiplet并不算新鲜。除了数据中心、汽车等HPC平台逐渐普及;消费产品之上,也已经能够见到基于chiplet高级封装的处理器芯片——这两年Intel的酷睿处理器会将这种技术在PC平台普及;苹果M1 Ultra则已经基于2.5D封装做到了大规模普及。
不过这是基于走量摊薄成本的例子。从chiplet实施更具体的层面来看,芯片采用chiplet方案的确也带来了更多的工程问题和更高的复杂度。
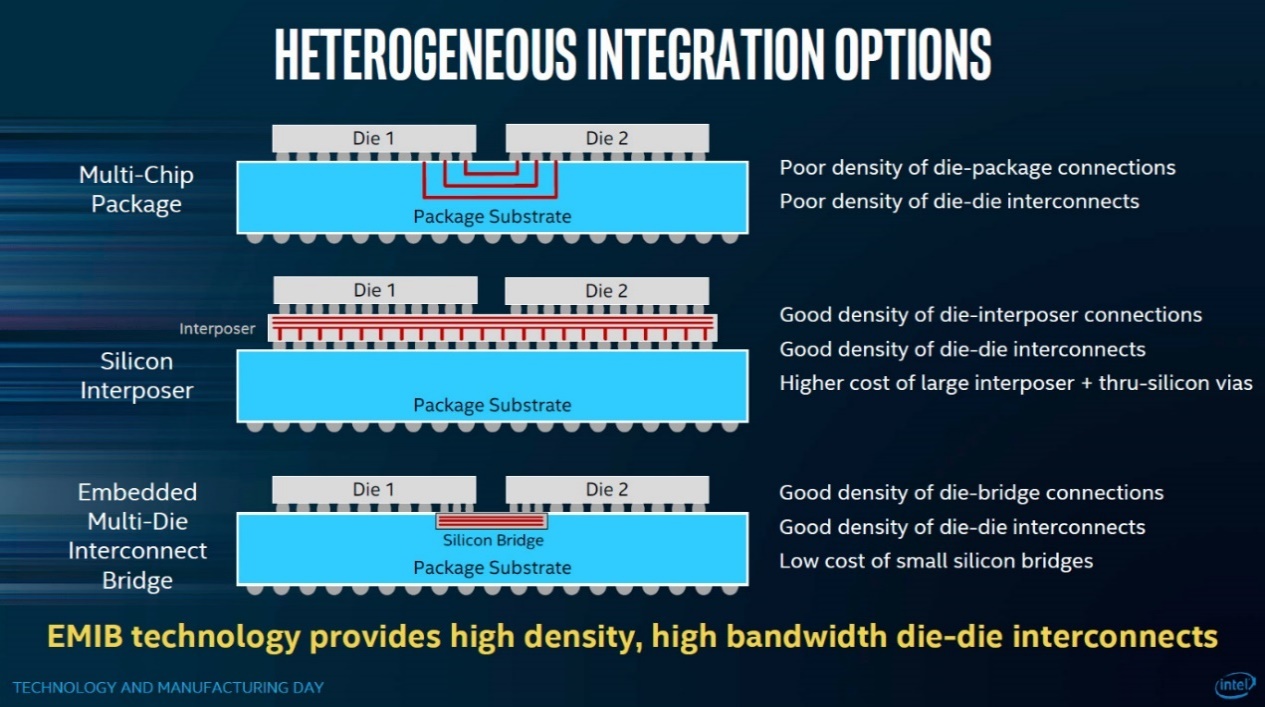
图3,常见2.5D封装方案,来源:Intel
照例简单解释一下什么是2.5D封装和3D堆叠。比较常见的2.5D封装,会把一片大die切成一个个小die(chiplet),然后把这些小die都放到一个硅中介层(silicon interposer)上,这个硅中介内部可实现die之间的互联(RDL,redistribution layers)。
不过在不同方案下,die之间的互联方案可能是多样的。比如Intel EMIB就没有采用硅中介,而是直接在封装基板上“挖”出硅桥(silicon bridge),实现die之间的互联,如图3所示。
而3D堆叠顾名思义,就是不同的die可以叠起来,形成三维立体结构。Die与die之间通过microbump或者hybrid bonding键合方案实现互联。
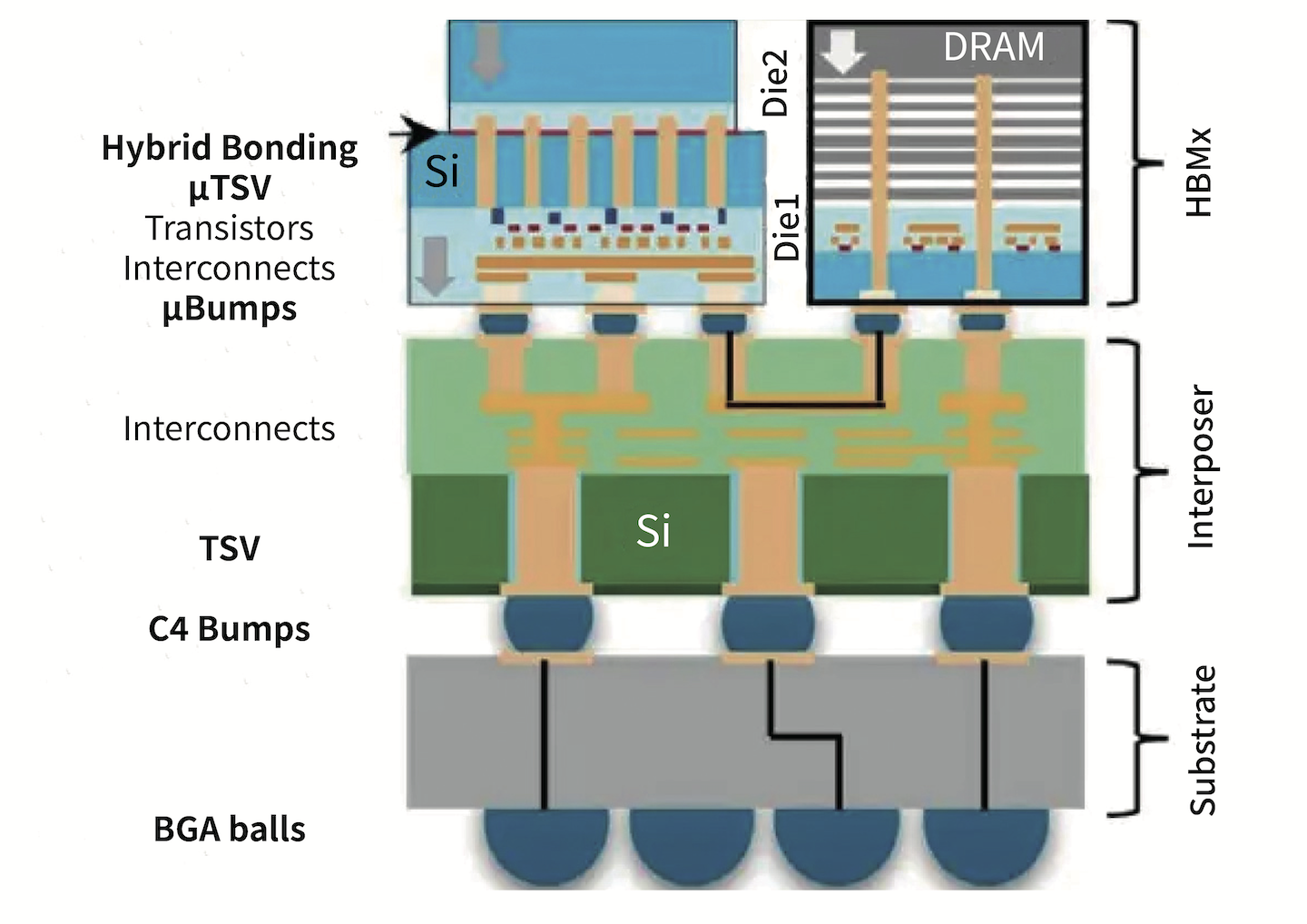
图4,先进封装示例图
图4能够比较到位地反映进行先进封装时,不同层级之间的关系。示例中的这颗芯片用上了3D堆叠的DRAM(右上角),叠了2层die的chiplet(左上角)。这两部分通过中间层的interposer进行互联(2.5D封装)——其中RDL层用于信号互联,包括触达封装基板的部分。
这张图中出现了不同大小和间距的bump与键合方式,包括C4 Bump(间距在110-150μm之间)、μBump(40-55μm间距),以及左上两个die进行3D堆叠的hybrid bonding混合键合。硅中介部分,在bump和RDL层之间还需要TSV(硅通孔);而die的3D堆叠贯穿也用到了μTSV。
Synopsys在今年的IEDM之上,将这种chiplet式的异构集成实施方案与monolithic(一整片die)在成本方面做了对比。Synopsys与IC Knowledge合作做了预测模型,基于2nm工艺做成本上的估算。对比中的这颗SoC芯片包括采用GAA晶体管,17层金属层,600mm x2 die size——其中65%逻辑电路,20% L3 SRAM,外加10%的I/O电路。
在异构集成的实现上,L3 SRAM叠在核心die上面,采用上述hybrid bonding方案(AMD现在已经开始采用这样的方案);I/O die单独出来——这片die采用90nm工艺制造;然后用2.5D封装的方案,把它们封装到一起。
最终IC Knowledge和Synopsys得到的结果是,相比于monolithic传统方案,这种3D堆叠+2.5D封装方案能够实现48%的成本节约。成本节约主要来自于更高的良率(因为die切分得更小了),且非逻辑电路功能部分不需要用17层金属层(L3 SRAM为4层,I/O为7层);另外I/O die只需要用90nm工艺制造即可。
相对来说增加成本的部分主要包括die的协同,硅中介需要成本(而且当前的一个技术挑战也在于interposer如何做得更大,甚至突破reticle limit限制),以及异构集成的封装测试成本等。两相抵消就能得到48%这个数字。可见在某些场景下,复杂度的增加是值得的。
Synopsys在IEDM之上的呈现内容除了成本剖析之外,还谈到了异构集成方案实施过程中的PDN(供电网络),以及互联电气分析和对串行、并行总线互联实施方案的选择问题等。
很显然这样的方案对于解决本文第一部分提到的技术挑战是有相当价值的,也是现在半导体制造必行的技术路线。
具代表性的一些封装技术
长电科技在先进封装方面有诸多可谈的技术类型,不仅是前文提到的XDFOITM技术。从长电提供的资料看来,先进封装已经成为其主要收入来源,主要可分为系统级封装、倒装与晶圆级封装等类型。不过长电当前公开有关其封装技术的技术细节并不多。将来若有机会,我们可做更深入的采访。
更为我们所知、以及公开了较多技术细节的先进封装与2.5D/3D封装方案来自Intel、台积电、三星、日月光、索尼等。因为篇幅关系,本文仅对目前比较热门的一些技术做大致浏览。而且此前《电子工程专辑》网站也以较大篇幅介绍过Intel和台积电的先进封装技术。
台积电有一种芯片倒装封装方案比较具有代表性,主要是substrate基板部分没有采用ABF(Ajinomoto build-up films)常见流程,而更偏向于半导体制造方式。其RDL层相比大部分OSAT封测代工厂的方案都更小、更密,故而可实现更复杂的互联。技术归属于其InFO(Integrated Fan Out)封装方案;InFO还有下属不同的技术分支。

图5,台积电3DFabric封装技术,来源:台积电
这类FOWLP(Fan Out Wafer Level Packaging,扇出晶圆级封装),日月光也有一种FoCoS(Fan out Chip on Substrate)技术相对类似。我们猜测长电的XDFOI(X-Dimensional Fan-out Integration)可能亦为其中代表。三星的同类技术方案叫做FOSiP(Fan Out System in Package)。
值得一提的是,在台积电InFO封装技术中,有一种InFO-LSI(Local Silicon Interconnect)——这种技术归属于InFO-R,如图5所示。多个die下方有个“本地硅互联”层。台积电在今年4月份的International Symposium on 3D IC and Heterogeneous Integration会议上提到,苹果M1 Ultra组合两颗M1 Max的方法就是InFO-LSI,而不是很多人猜测的CoWoS-S。

图6,InFO-LSI封装技术图示,来源:台积电
从示意图(图6)来看,InFO-LSI的硅桥很像Intel EMIB(Embedded Multi-die Interconnect Bridge)。但实际上EMIB的成本还是更低:这种方案是把连接多个die的互联硅桥(silicon bridge)放进基板腔里面。EMIB方案从2018年就开始部分量产了,目前已经要进入大规模应用阶段。这一代EMIB的连接间距为55μm,预计第二代、第三代的值会降到45μm和40μm。台积电InFO-LSI的bump pitch间距会更小(25μm)。
InFO-LSI和EMIB于基板材料和制造工艺都是不同的。日月光可做类比的技术是FOEB,但FOEB和在基板上“挖”个槽的方法又不大一样;而且RDL层是玻璃基板材料。日月光在宣传中会将FOEB与EMIB作比较,其优势似乎在于布线密度,但成本会略高些。
台积电更为人所知的2.5D封装技术是CoWoS。其中CoWoS-R和CoWoS-L可与InFO-R和InFO-L对应。从工艺流程来看,其不同之处在于,InFO为“Chip First”工艺,也就是先放芯片,然后再构建RDL层;CoWoS则先搭RDL,然后再放芯片。

图7,英伟达A100 GPU,来源:英伟达
CoWoS-S的知名度可能是这其中最高的,这里S就是指Silicon Interposer(硅中介)。通常die以倒装的方式封装在一片无源晶圆(硅中介)之上,硅中介里面会有各种线路连接。我们介绍2.5D封装时,通常都以这样的硅中介为模板——包括本文上半部分的分析。而且CoWoS-S也的确广泛存在于现有的HPC芯片产品中,比如英伟达的数据中心GPU(图7)。大部分用HBM内存的芯片通常都考虑用CoWoS封装方案。
值得一提的是,CoWoS-S所用的硅中介技术还在进化,主要体现在其可承载的chiplet总面积变得越来越大。此前我们撰文提到过,最新一代CoWoS-S5的硅中介尺寸达到了2500mm²,三倍于reticle limit面积,如此可容纳更多的chiplet于同一个封装内。
三星有一种叫做I-Cube的技术比较类似于CoWoS-S,百度AI芯片似乎就应用了I-Cube。
说完靠后端的2.5D封装,最后聊聊更受人瞩目的前端3D堆叠技术。其实die的3D堆叠也不算新鲜,毕竟存储器领域,3D堆叠已经是很常见的技术了。比如长江存储的Xtacking技术,叠了128层TLC和QLC。
DRAM实际上也在应用先进3D封装:三星、SK海力士和美光针对HBM内存就应用先进封装多年了。SK海力士的HBM3会有12层DRAM die垂直堆叠。三星针对DDR5、LPDDR5X也已经开始叠层。
将来逻辑芯片更广泛应用的3D堆叠技术,比较受人瞩目的是Intel Foveros和台积电SoIC(System on Integrated Chips,分成CoW与WoW两种)。
Die的3D堆叠一般是指两片有源die,以垂直的方式叠在一起。Intel最早的3D堆叠处理器见于2020年的Lakefield CPU,初代Foveros的bump pitch为55μm。最新一代Foveros技术则将应用于面向数据中心的Ponte Vecchio——这是一颗非常复杂的数据中心GPU,其上应用了die堆叠的Foveros封装的bump pitch已经减到了36μm。
预计从明年的14代酷睿CPU开始,民用市场会普及Foveros技术。且14代酷睿具体会应用Foveros Omni(双向互联,Omni-Directional Interconnect;第三代Foveros)——这种技术除了bump pitch更小(25μm),通过铜柱可以直接为上层die提供电力和信号;这种方案也允许下层die的尺寸比上层die更小,而且上下层die可有多个,提升灵活性。从实现来看,Foveros Omni对于其TCB(热压接合)技术也会有更大的依赖性。
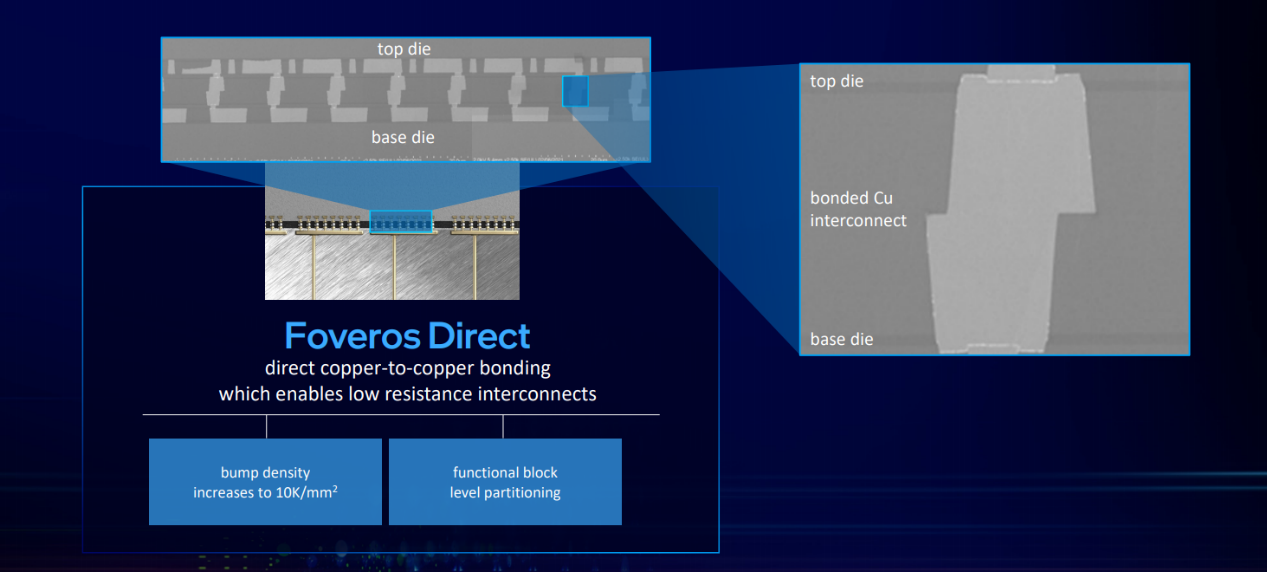
图8,Foveros Direct,来源:Intel
而更未来向的Foveros Direct(第四代Foveros,图8)应当会开始用hybrid bonding混合键合方案,采用直接的铜-铜键合,而不再是microbump键合连接,键合间距预计≤10μm,相比Foveros Omni有6倍密度提升(>10000 wires/mm²)。
此处hybrid bonding混合键合是值得一提的。这种不用bump,而是TSV铜铜直连的工艺难度相当大,相比于其他封装方法将实现高得多的集成密度。实际上AMD已经有应用了台积电SoIC方案的3D堆叠技术的芯片问世,AMD称其为3D V-cache:简单说,是将三级缓存die叠在处理器die的上面,增大了三级缓存的容量。3D V-cache已经用上了hybrid bonding键合方案。
此前台积电就已经在宣传,SoIC键合相比于用micro-bump连接,能够减少35%的热阻,以及高得多的互联密度。三星的hybrid bonding技术名为X-Cude。另外市面上能见到出货最多应用了hybrid bonding技术的芯片产品,是索尼的CMOS图像传感器:这在我们此前的图像传感器堆叠技术介绍里已多有涉及。
“Achronix认为先进的封装将支持开发出更复杂的、功能更强大的和基于FPGA的产品。我们相信,未来几代高性能FPGA将利用先进的封装技术来加快具有新功能的产品的上市时间。”Bob在采访中说,“半导体制造商无需重新设计整个芯片,而是可以重新设计一个较小的chiplet来添加新功能,同时使用先进的封装保持基本芯片不变。先进的封装技术是实现下一代高性能FPGA的关键。”这番话对先进封装技术未来的发展,是可做管中一窥的。
先进封装技术的崛起将持续提升封测环节的重要性。与此同时,如长电传递的信息,提升封测的价值不仅需要使前道工序和后道工序有更加紧密的联系,更需要把设计、制造、封测有机融合在一起协同发展,这样才能使得产业技术水平得到进一步的推广和提升。那么传统封测环节也就升级为“芯片成品制造”产业了。这是先进封装技术对整个行业的影响。
本文为《电子工程专辑》2022年8月刊杂志文章,版权所有,禁止转载。点击申请免费杂志订
