
自从Intel在半导体制造工艺技术上开始落后于台积电,以及Pat Gelsinger上任CEO以来,Intel对于自家制造工艺技术的“未来向”宣传变得越来越积极。各种会议上不停预告着新工艺很快就要诞生,生怕市场质疑Intel不行。
前不久的Intel Vision大会,我们报道了酷睿HX系列处理器的发布。不过这届Intel Vision真正的亮点在于,Intel在现场展示了代号为Meteor Lake的14代酷睿处理器——Intel当时表示这颗处理器已经点亮,虽说正式上市还是要等到明年。毕竟13代酷睿都还没发布。


通过先进封装技术将多个die“粘”起来的14代酷睿
看得出来,这是Intel为提振市场信心的又一次“未来向”宣传:Meteor Lake处理器除了会采用chiplet与先进封装技术,更重要的是,其上最为重要的一片die会采用Intel 4制造工艺(compute die)。Intel在活动上率先展示Meteor Lake实体芯片,就是为了向市场证明:新工艺进展顺利,完全可以按照此前的计划按时上市。可见Intel此前所说2025年要夺回半导体制造工艺的皇冠,还是有点眉目。
最近Intel在VLSI技术研讨会上,给出了有关Intel 4工艺的更多细节。在去年Intel工艺改名以前,Intel 4还被称为7nm;而7nm工艺的延后,又与其10nm的迟迟未能步入成熟有莫大关联。10nm与7nm的延后导致原本领先竞争对手数年的历史结束。所以Intel决心在尖端制造工艺上做更快的速度推进,近几年要完成Intel 4、Intel 3、Intel 20A、Intel 18A多个工艺的迭代。
市场当前格外关注Intel 4工艺的推进情况。此前我们对这代工艺的实现细节是一无所知的,仅知Intel 4是Intel首个采用EUV技术的工艺、相比Intel 7能实现每瓦性能20%提升,以及Gelsinger宣布去年二季度Intel 4进入tape-in阶段。这次公开Intel 4的更多技术细节,以及前不久Meteor Lake芯片的亮相,都在传递积极信号。
我们比较关心的是Intel 4相比于另外两家foundry厂的4nm和3nm工艺,究竟定位如何;Intel 4的这个“4”是否名副其实。
有关2倍晶体管密度提升
此前Intel调整工艺迭代策略以后,分析师普遍猜测Intel恐怕不会再以过去那么激进的步伐,来更新自家的工艺技术。比如Intel的10nm工艺,相比于14nm,晶体管密度提升2.7倍——这在台积电和三星看来,恐怕都是过于激进的数字。所以就晶体管密度方面,Intel未来应当会以更小的迈进步伐,来确保更稳健的技术推进。
去年7月,Digitimes发布的一份报告中预测Intel 4相比Intel 7的晶体管密度提升大约为1.8倍,达不到此前传说中的2倍。这个猜测就现在看来是错误的。

其中Intel 7工艺的CPP有两个值,TechInsights此前的分析指出不同代的10nm工艺,CPP间距有差异;初代10nm的CPP为54nm,而10nm SuperFin出现了60nm的版本,到Intel 7似乎已经不再启用54nm的CPP;同代工艺内的晶体管变得更稀疏也并不稀奇
上面这张图给出了Intel 4的(高性能HP单元库)器件及标准单元(cell)的关键尺寸变化。包括gate pitch(栅极间距)、fin pitch(鳍间距)、MMP(最小金属间距)之类的数据,对应于Intel 7,尺寸都相当于后者的0.75-0.88倍左右。
HP高性能单元库的单元高度240nm,相比于此前Intel 7达到了0.59倍的尺寸缩减。单元高度 x CPP,得到对应的单元面积为12000nm²——这个值相比于Intel 7刚好是约为0.5倍。所以Intel官方说晶体管密度提升了2倍。
这里有两个疑惑。其一,我们知道现在不会用这种方法来计算晶体管密度。Intel实际上也没有提供确切的MTr/mm²(百万晶体管每平方毫米)数据。
其二则在于,Intel只提到了HP高性能库的数据——一般来说,同代工艺节点里,高性能单元的晶体管密度是比较低的(高性能库通常越大,有更高的驱动电流,密度就更低)。高性能单元通常应用于处理器内,对性能有明确需求的关键路径。而我们日常所说的“晶体管密度”是指HD高密度单元——高密度单元的晶体管密度显著更高,但性能会稍差,可应用于诸如uncore之类的部分。
比如说Intel 10nm工艺,官方给出晶体管密度为100.8 MTr/mm²,这就是指HD高密度库;而HP高性能单元库密度为80.61 MTr/mm²;还有一种UHP超高性能单元库的晶体管密度为67.18 MTr/mm²。这次Intel给出有关Intel 4的数据是其中的HP高性能单元库。这样算来,Intel 4的HP库密度大约应该在160 MTr/mm²左右。
Intel表示将来会提供MTr/mm²数据,大致上就是2倍关系。其实HP库的数据对宣传不利,毕竟人家宣传的主要是HD库。那Intel为什么没有提HD高密度库呢?Intel 4节点只提供HP高性能单元,而没有HD高密度单元。
听起来是个挺诡异的事情。不过此前Intel就在投资者会议上提到,后续工艺要采用“模块化设计架构”,让工艺迭代节奏更快。所以HD高密度库准备留到Intel 3工艺去实施;而Intel 4会成为彻底的高性能节点。那酷睿、至强处理器上的部分I/O、uncore部分怎么办呢?总不能都用HP库吧?
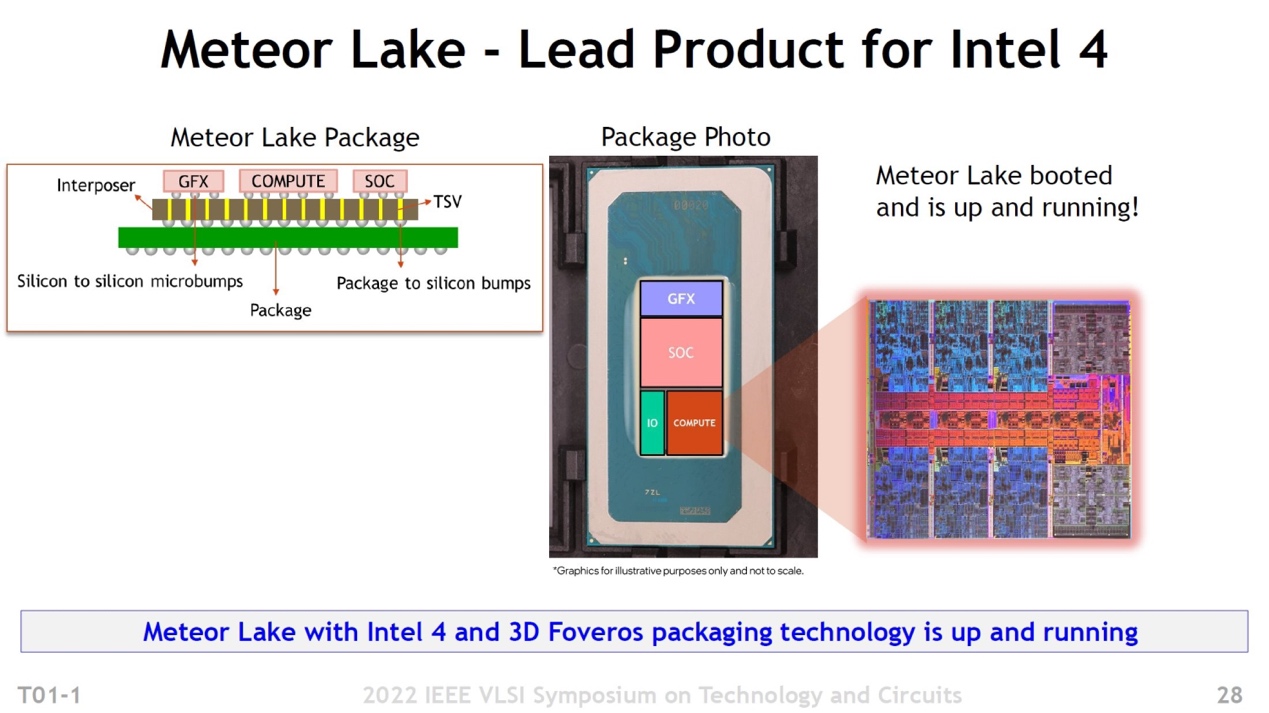
Intel连compute die的die shot都公布了
实际上,此前展示的Meteor Lake的chiplet方案就已经表明了,14代酷睿只有核心的compute die会采用Intel 4工艺,其余的die会基于不同的制造工艺,包括Intel自己更早的工艺以及台积电的先进工艺。这也是chiplet的主要价值所在。另外,Intel未来作为foundry厂(IFS)面向客户提供服务的主要将是Intel 3——而Intel 4在大部分情况下是给自己用的。
从这个角度来看,chiplet的发展趋势实则让近代尖端制造工艺的对比显得更复杂了。
和台积电4nm工艺的简单对比
IC Knowledge基于分析,给出了Intel 3工艺的HD高密度单元的晶体管密度数据:他们认为Intel 3相比于Intel 4,HP高性能单元还会有1.07倍密度提升,而相比Intel 7在HD高密度单元上,则会有1.4倍密度提升——单HD单元的密度提升还是比较保守(IC Knowledge的预测可能是值得商榷的)。

来源:IC Knowledge
另外IC Knowledge也给出了Intel 4相比于台积电5nm、3nm工艺部分关键数据的比较,如上图所示。台积电N5高性能单元CPP间距51nm,M2P(Metal 2 Pitch)间距34nm,单元高度9T。从CPP x 单元高度数据来看,以台积电的节点命名标准,Intel 4算是名副其实的4nm工艺,介于台积电N5、N3之间。单纯就面积数据,Intel 4其实更靠近台积电3nm工艺。
在器件尺寸缩减,另外值得一提的是,除了逻辑电路,Intel也提到SRAM单元方面,Intel 4节点有两种SRAM单元:其中高密度单元(HDC),相比上一代大约是其尺寸的0.77倍;高电流单元(HCC)的尺寸缩减幅度不明。
器件、单元尺寸之外的另一个重要指标是性能和功耗。IC Knowledge预测,Intel 4在性能方面可能还会略优于台积电N3。而基于三星当前公布的数据,Intel 4的高性能单元密度也会高于三星3GAE。但在此还是重申一点,间距和密度数据并不能真切反映工艺节点的性能和功耗表现。且IC Knowledge的数据也未必是准确的。
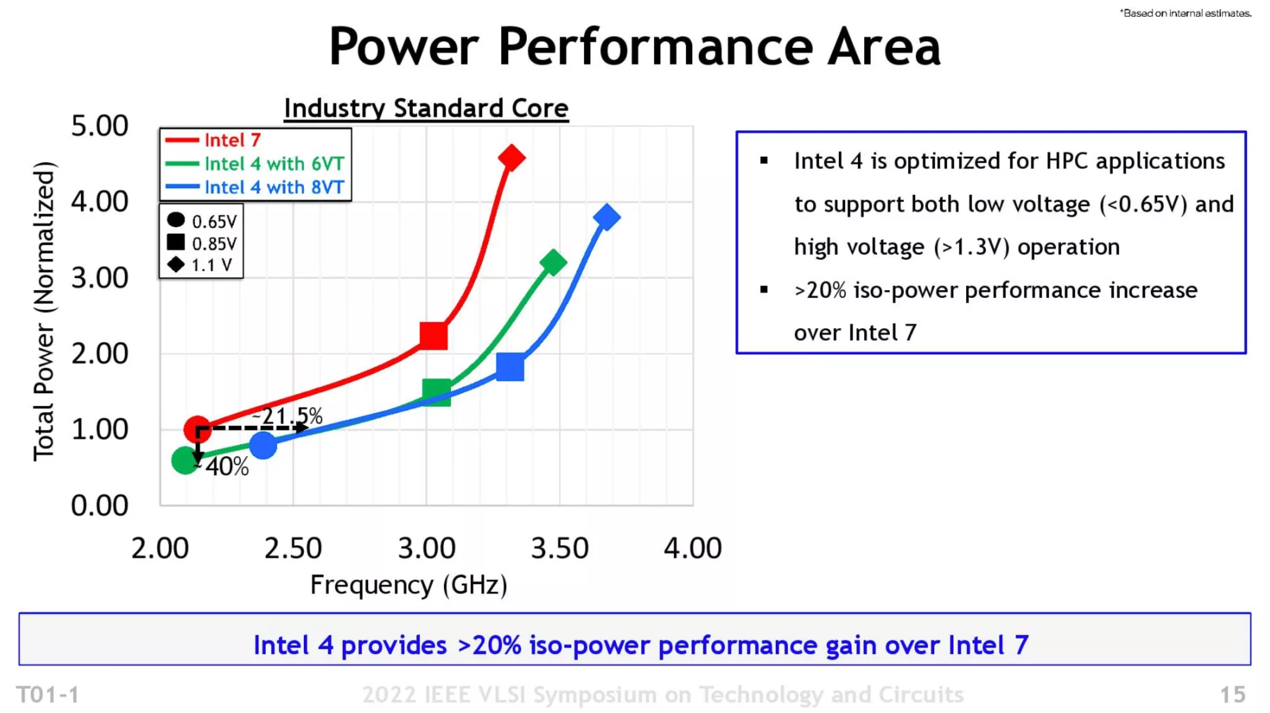
Intel官方给出的性能提升数据如上图所示,横轴为频率、纵轴为总功耗。同功耗下,Intel 4相比Intel 7在时钟频率方面最多可提升21.5%;同频率下至多降低40%的功耗。
具体的值为相对于Intel 7工艺0.65V的同功耗下,频率能够提21.5%,往后区间的百分比收益会降低:如0.85V,同功耗的性能收益缩窄至10%。另外,更高阈值电压(8VT)设计的单元能够以更高的总功耗换得额外5%的性能。
从功耗的角度来看,在大约2.1GHz频率下,Intel 4可以达成40%的功耗降低——更高频率区间也会有收益递减,不过从Intel的图来看似乎表现相当可期。或许明年的14代酷睿低压版处理器就能达成前所未见的Windows笔记本续航时间了,这是现在的Windows PC用户对Mac用户分外眼红的。
有关EUV、金属互联层、钴材料改进
众所周知,Intel 4是Intel第一个要采用EUV的工艺节点,所以Intel自然不会忘记提EUV相关信息。不过Intel这次给出的相关EUV的信息其实并没有太大的价值,基本就是在说EUV对工艺的帮助。Intel并没有提到哪些层、几层应用了EUV。
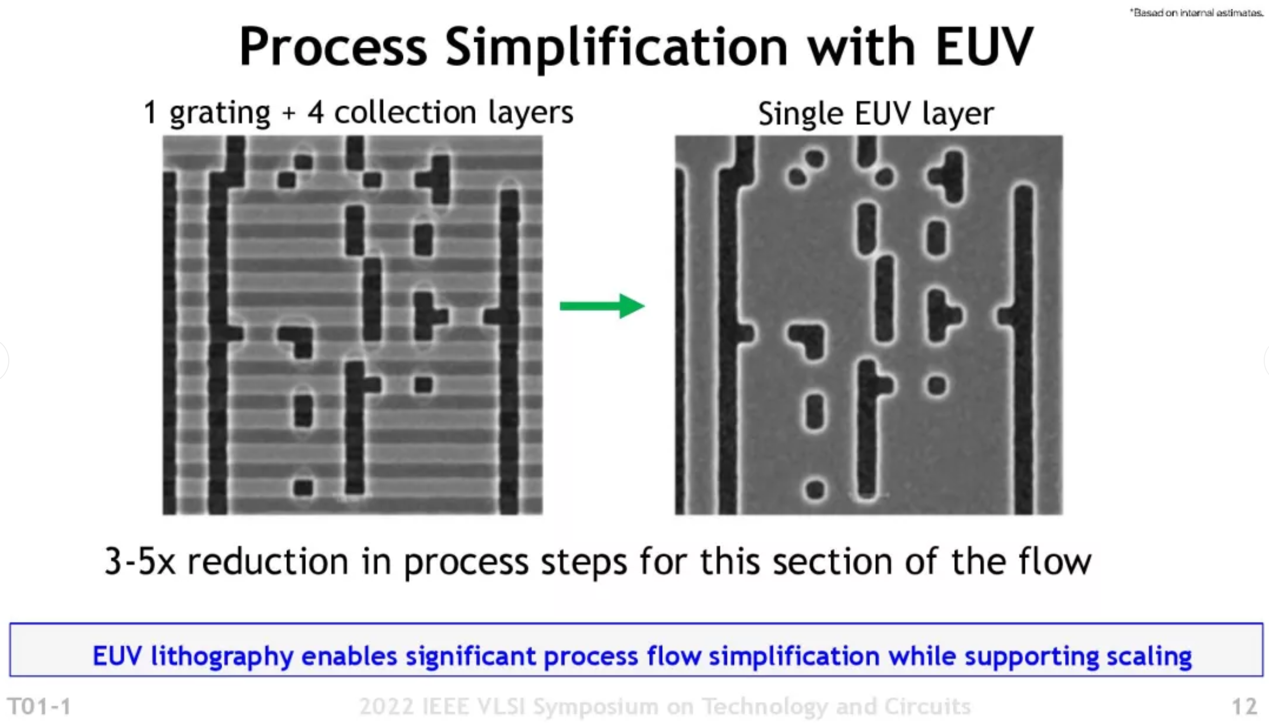
EUV相比于此前DUV多重曝光的价值,最直接的无非就是工艺流程步骤减少了。Intel表示EUV覆盖的生产流程里,步骤减少了3-5倍。另外EUV具备更高的图案保真度,实现更高的制造良率。所以从两方面来看,能够在大规模生产过程里节约良率和时间成本——虽然前期投入,EUV的成本还是会更高。

Intel还特别谈到对于良率方面的帮助细节,比如说下层金属层在具体的制造流程中每一步都需要对齐。而EUV技术之下,金属层对齐操作次数显著减少,自然就增加了产量和良率。
Intel 4的前端和后端制造流程都用到了EUV。Intel给出的数据是相比于Intel 7(DUV多重曝光)减少了5%的流程步骤,减少20%的掩膜数量。如果不用EUV的话,Intel 4所需的步骤和掩膜数量还会多不少。作为参考,此前台积电在谈N5工艺时首次谈到因为EUV工艺的采用,掩膜数量从7nm的87层,降低到5nm的81层——如果没有应用EUV的话,Wikichip预计N5可能需要115片掩膜。N5工艺用到了14层EUV层。

再来谈谈金属互联层的改进。早在10nm时代,Intel将部分偏底层的金属层,原本的铜线换成了钴线。这部分信息,我们在此前的Intel 10nm工艺解读文章里有非常详细的解释。有分析师认为,Intel在10nm时代采用钴材料的激进行为,是导致10nm工艺延后和迟迟不见成熟的根源之一——美国应用材料也提过,此前曾建议Intel不要过早采用钴材料。
简而言之,导线中心的主体部分换用钴的主旨,更多在于解决越来越细的导线所致的电迁移问题。不过大约在实施难度上比较大,以及钴相比铜还是有着更高的电阻率,Intel这次换用一种名为eCu(Enhanced Copper,加强铜)的材料,应该是一种铜外部覆盖钴的方案(更外部的阻隔层为钽)。
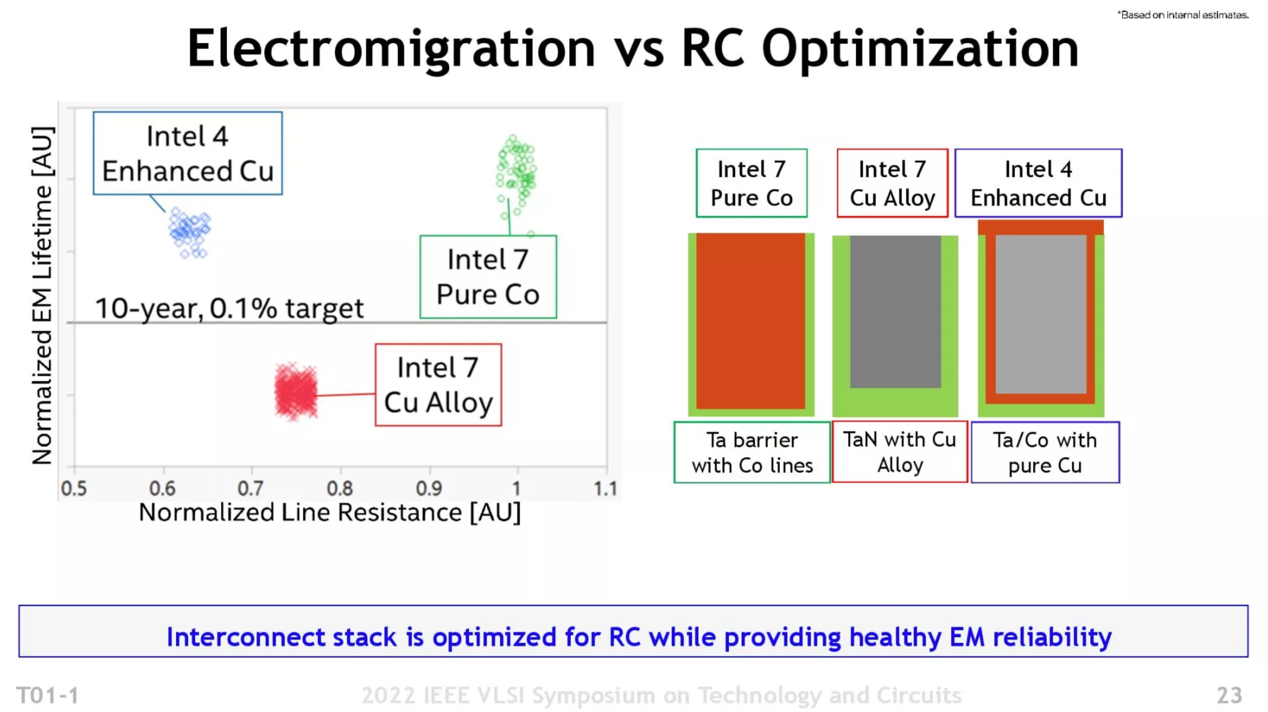
据说这么做能够吸取两种材料的长处,包括缓解电迁移问题,同时还能利用铜本身的性能。虽说相比于单纯的钴材料,这样的方案在缓解电迁移致电阻升高甚至断连的问题方面,表现会略有不及,但仍有超过10年的寿命。所以Intel 4的互联导线虽然相比于Intel 7变得更细了,但电阻值并没有发生多大变化。
Intel 4工艺的互联金属层部分,底下Metal 0到Metal 4的5层都会采用这种eCu方案。另外,Intel 10nm的栅极填充也用到了钴(与钨);但Intel 4已经完全不在这部分采用钴,而回到了单纯的钨。
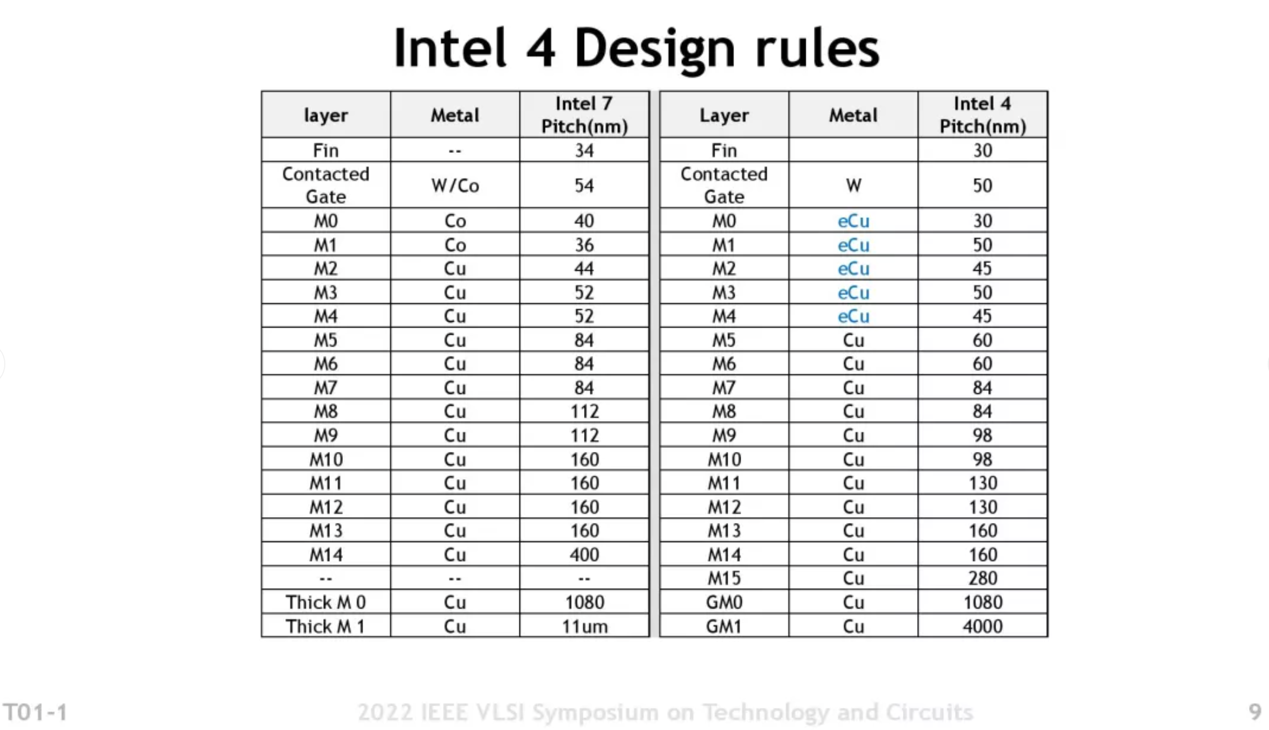
金属层部分改进中,另外值得一提的是Intel 4的金属互联层增加到了16层,比Intel 7多出1层(Metal 15);此外最上方还有两层电源布线的所谓“巨大”金属层(GM0, GM1),间距分别在1080nm和4000nm。
在金属互联层更高层,10nm SuperFin就开始采用一种名为SuperMIM(metal-insulator-metal)的电容。MIM用于对抗相对高负载时的Vdroop掉压,起到维持持续频率的作用。当时Intel就宣称,SuperMIM相比占地面积相同的标准MIM电容,电容量增加5倍。具体的是通过新型high-k高介电常数材料在<0.1nm的薄层中沉积,在两个或多种材料类型间构成超晶格(superlattice)结构。这次Intel 4在这方面又有了提升,电容密度据说提升2倍,来到了376 fF/μm²。
其他Scaling Booster改进
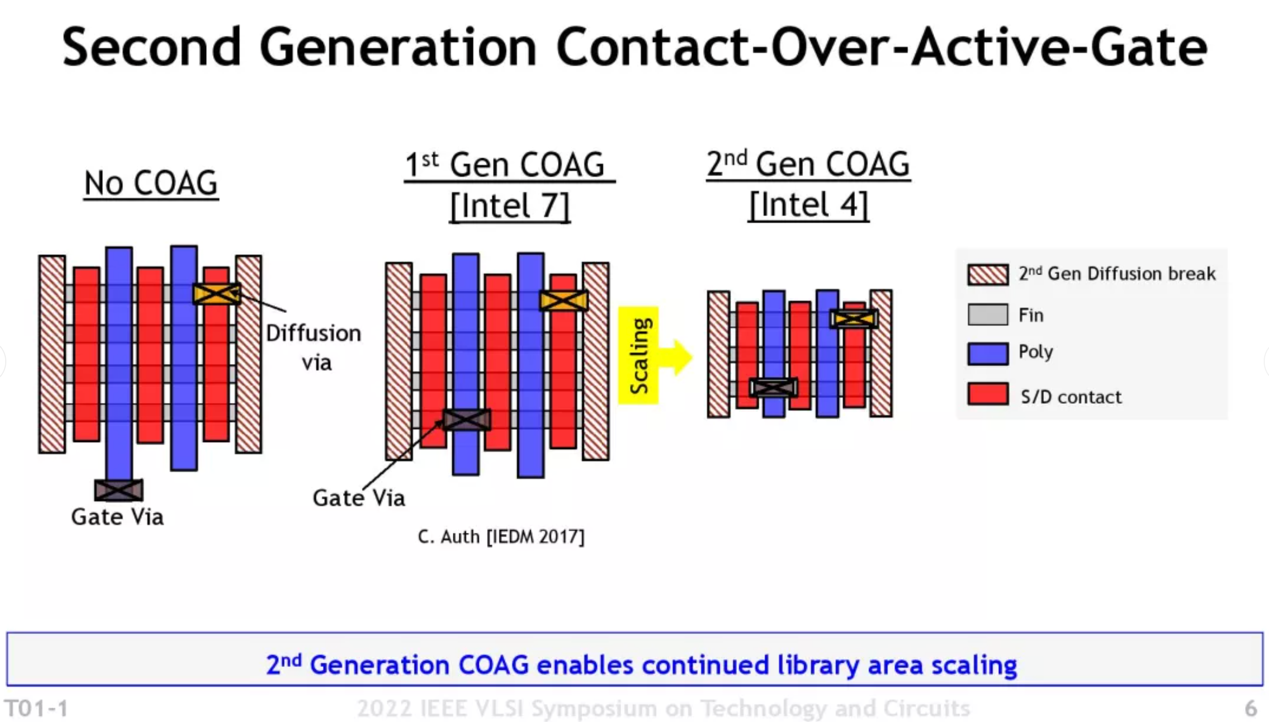
除此之外,Intel还提到了一些scaling booster相关的尺寸缩减方案改进(在Intel这里应该是叫Hyper Scaling)。比如说COAG(Contact-Over-Active-Gate)第二代——此前10nm的介绍文章里,我们也谈到过这个方案。这种方案是把原本伸出到gate栅极之外的接触点位置,改放到gate上方。此前有人认为,COAG也可能是Intel 10nm工艺走向量产的一大难点。这次的第二代COAG更进一步提升了空间利用率。
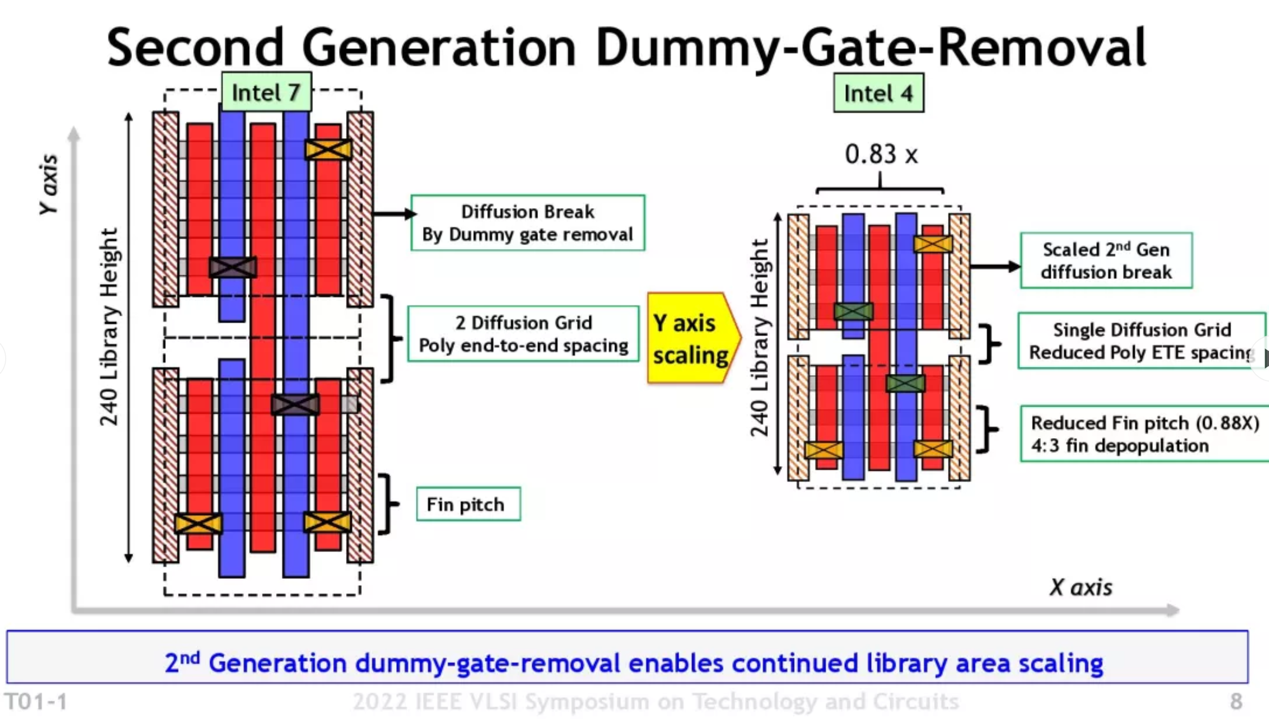
还有像是dummy gate单元间隔方面的改进(第二代diffusion break);n fin和p fin的间距调整;所谓的gridded interconnect设计,限定via的位置等。这些应当本身也都促成了单元高度和面积的缩减,是晶体管密度提升的重要组成部分。

本来想借此机会再聊聊Intel已经展示了die shot的14代酷睿处理器的,受限于篇幅就等将来另辟新章吧。最后值得一提的是,Intel希尔斯伯勒fab厂应该会率先开始Intel 4工艺的生产,随后是爱尔兰Fab 34工厂;更多生产计划未知。这似乎和Intel持有的EUV设备有很大关系。
ASML的EUV设备缺货现状,实则对Intel可能会产生最大的影响。而Intel未来几代工艺要提量的关键都在EUV设备上。希望EUV设备缺货不会成为掣肘Intel新工艺迭代的阻碍。毕竟从Intel展示的这些数据,以及成品现状来看,Intel的尖端工艺更新还是相当让人期待的。
