
数据中心的更迭周期相比消费电子——如PC、手机之类的产品——一般会更慢。感觉Ampere架构的A100加速卡还没到货,今年英伟达GTC的Hopper H100加速卡就已经来了。黄仁勋在今年主题演讲的答记者问阶段也提到,当前Ampere和Turing架构的GPU正在向全球的数据中心出货,“Volta应该几个月前才刚刚停止,Ampere和Turing估计还会至少再持续2年。Hopper是在此基础上的延续。”虽然Hopper架构的H100今年Q3就准备好开卖,它应当是更具未来向的一代芯片。
英伟达FY22财年Q4数据中心业务营收达到了32.6亿美元,较去年同期又涨了71%;整个财年数据中心业务营收则达到106.1亿美元,同比增长58%。这样的数据其实已经没什么可吃惊的了,国际电子商情去年10月刊封面故事《AI芯片竞争红海下的生存之道》一文,我们就已经总结过,英伟达的存在对一众AI芯片公司而言有着怎样的威慑力,无论是市场、技术,还是营收。


我们在看过Hopper的发布后,更为现存的AI芯片公司感到颤栗:倒不光是明面上Tensor Core的算力与HBM3、NVLlink传输带宽之类的数字提升,还在于英伟达如今也在芯片架构层面做出更具针对性的改进,比如新的FP8数据格式支持、特别针对Transformer模型加入的Transformer Engine,以及新的DPX指令。这在某种程度上已经是比较明确的DSA(Domain-Specific Architecture)的思路了(虽然Tensor Core的存在本身就已经是DSA),自然在某些特定项目上有着成倍的性能与效率提升;实在是让标榜DSA的那么多AI芯片公司(以及做GPGPU的企业)感到背脊发凉。
虽说我们认为,更多此类偏专用特性的加入,即便对英伟达这样的生态巨无霸而言,都充满了挑战和不确定性,尤其开发者可能Ampere都还没完全整明白的情况下,Hopper又加了一堆新东西;但应该没有人会说英伟达的思路是不对的,而且如果这样的生态连英伟达都做不起来,那应该也没有多少公司能做得起来了吧。
本文就着重谈谈新发布的Hopper架构GPU及其周边系统,并顺带谈一谈明年要发货的Grace CPU。本文篇幅较长,除了文章的第一部分外,其余部分皆可选择性阅读。
3倍性能提升是真的吗?
H100作为GPU加速卡称谓时,其上的GPU die部分名为GH100(或者习惯上常被称作GH100核心)。H100应该是Hopper架构的第一款产品,定位于旗舰级服务器加速卡。按照常规列一下其中GH100的主要参数和配置。完全体的GH100采用台积电4nm工艺——英伟达在Hopper技术白皮书中说是台积电为英伟达定制的4N工艺,die size为814mm²,800亿个晶体管;主要配置包括:
- 8个GPC(GPU Processing Clusters)、72个TPC(Texture Processing Cluster,每个GPC有9个TPC)、144个SM(Streaming Multiprocessor,每个TPC有2个SM);
- 每个SM有128个FP32 CUDA core,总共18432个FP32 CUDA core;
- 每个SM有4个Tensor core(张量核心,第4代),总共576个Tensor core;
- 6个HBM3(或HBM2e)die,最高80GB,5120-bit位宽,3TB/s带宽;
- 60MB L2 cache;
- 第4代NVLink和PCIe Gen 5;
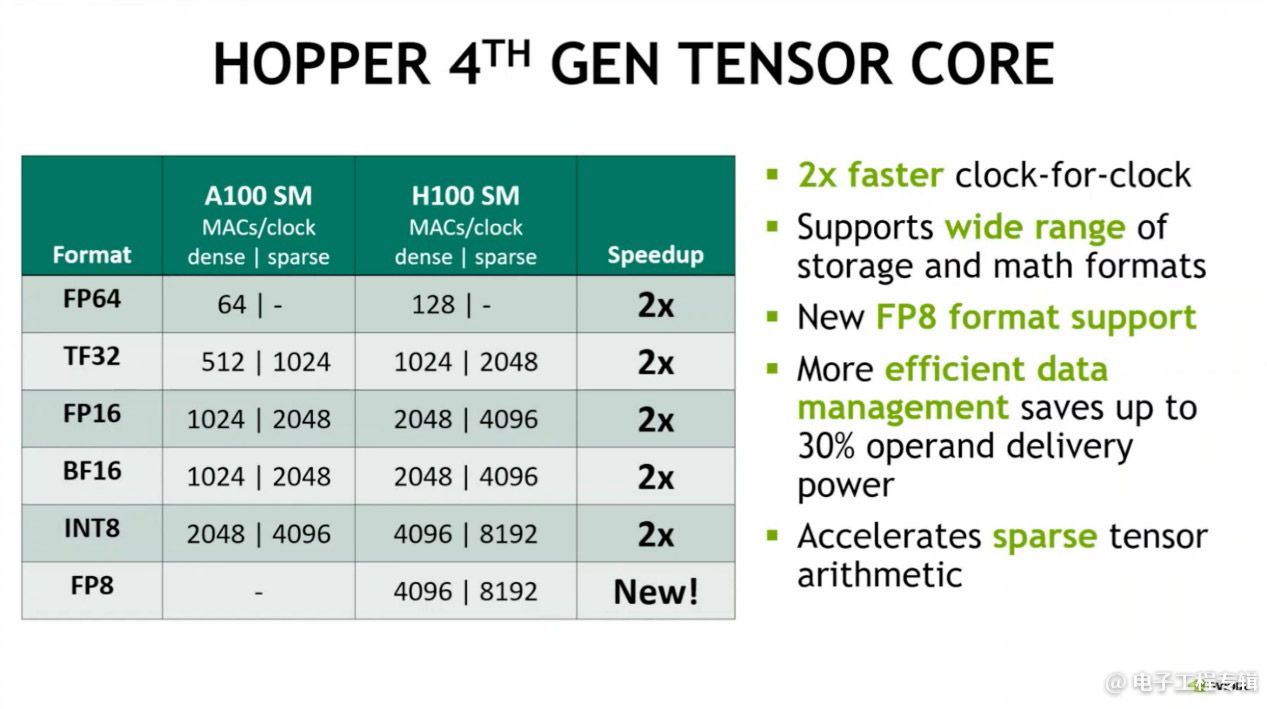
单纯从这些数据可以看出规模上的显著扩展,包括SM数量增多、每个SM的规模几乎翻倍——英伟达GPU架构高级副总裁Jonah Alben在架构简析中,也给出了两倍吞吐的一些数字(MACs/clock,每周期乘积累加),包括tensor core各种格式吞吐的2倍提升(如上图)。其实从晶体管数量相比前代(A100 542亿)增长就看得出规模上的显著变化。
两种插口形态,SXM5和PCIe Gen 5。其中SXM5版配HBM3存储(PCIe Gen 5版为HBM2e)——HBM3仍与GPU计算die一起,以CoWoS 2.5D封装;多GPU为NVLink连接,带宽可以达到900GB/s(较上一代提升1.5倍)。不过SXM5形态的H100板卡达到了700W TDP功耗,比Ampere架构时代还是高出不少的;PCIe Gen 5版H100的TDP为350W。
Alben在采访中说,虽然看起来功耗要求更高,但H100相比A100有着更显著的能耗比优势。“以相比过去快很多的速度完成相同量的工作,自然需要更高的功耗,所以H100增高到最多700W TDP。我们期望支持液冷方案的客户能够用上这样的性能,700W是给他们提供了一种选择。但具体要用多少功耗,都是由用户自行决定的。”“即便是SXM5,也可以限定功耗为350W。”
更具体的数据,感兴趣的同学可以去看看英伟达Hopper架构白皮书。黄仁勋在主题演讲中主要强调了Tensor算力数据相比前代的提升:

H100相比A100的“3倍”性能提升应该是这次会上所有人耳熟能详的数值了,源自上面这张slide所述的tensor core算力提升。这组数据描述的是SXM5形态的H100的第4代tensor core。
基于单个SM本身规模的翻倍,外加SM数量增多,以及更先进制造工艺可以再提一提频率,那么H100相比A100各项指标(主要是tensor)的3倍性能提升也是比较好理解的——总感觉现在有钱的芯片公司都在疯狂堆料…
这里有个6倍性能提升的FP8。FP8是Hopper引入的新的tensor处理格式。此处的6倍是FP8算力与上一代的FP16做比,则可使用FP8的AI应用性能在H100 GPU上,可以达到A100的6倍——相比其他项目的3倍,另外2倍是由于采用的FP8计算精度计算性能翻倍,并配合Transformer Engine计算带来的AI算力提升。
从FP8的加入,及此处“6X”性能提升的宣传,都能看出这代Hopper的主要着力点,就在AI上。我们听的几场GTC主题演讲,虽然也都有提HPC,但篇幅是明显不及AI的。估计这两者在晶体管数量配比上,也很难做到两全。而AI芯片性能,真切地被英伟达又拉到了另一个纪元。
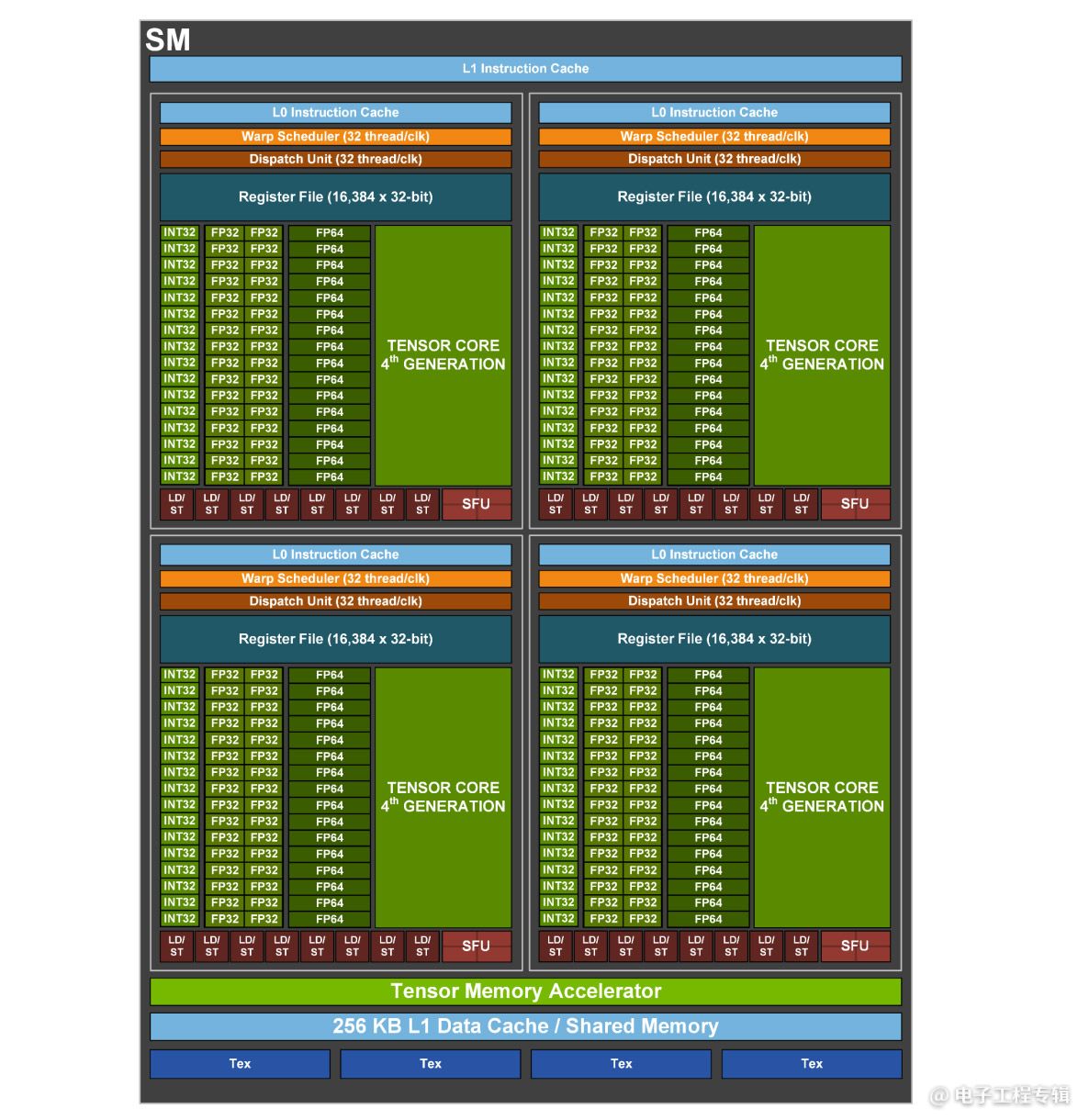
GH100的一个SM
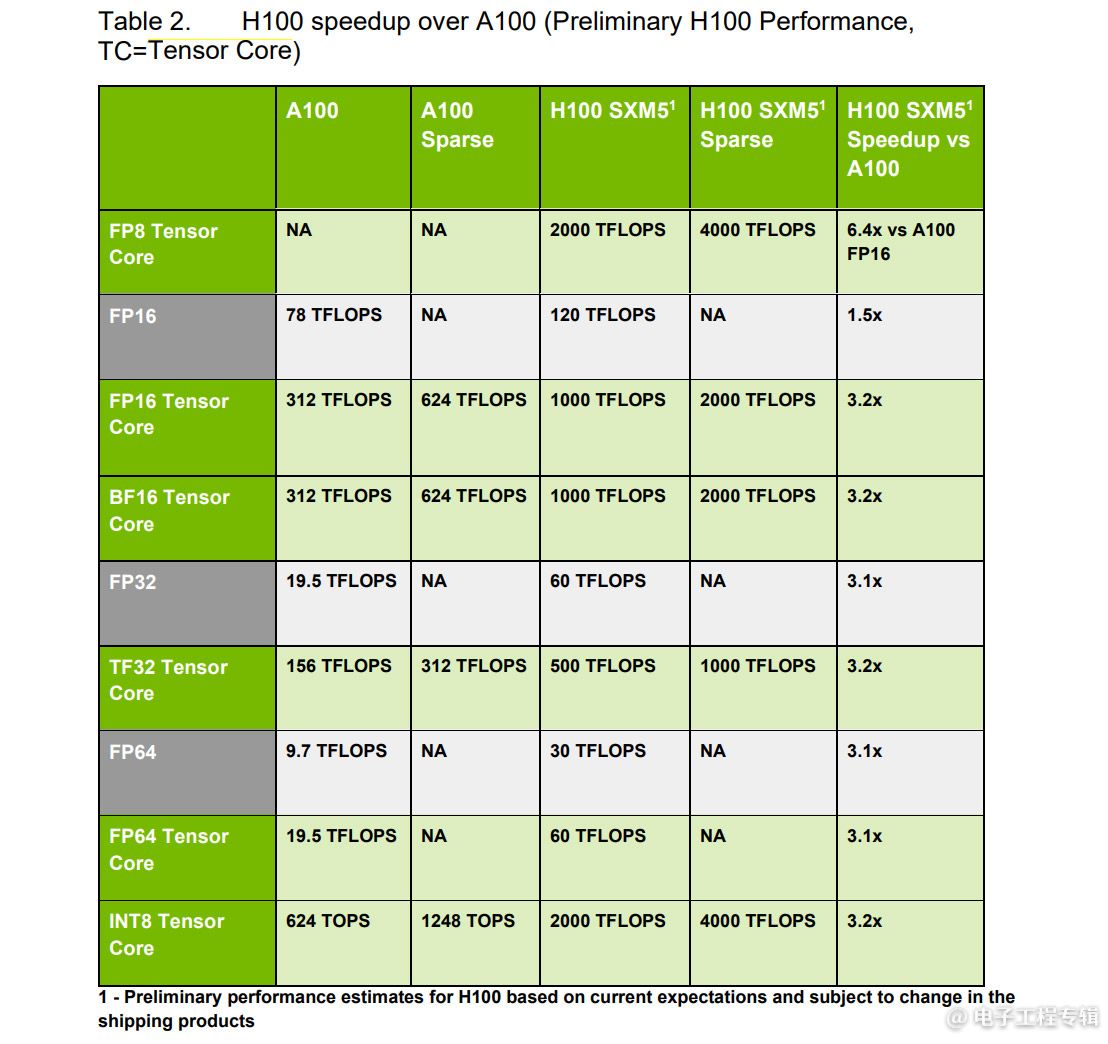
H100相比A100的性能变化:FP64同样有3倍性能提升
不过值得一提的是,HBM3带来了内存带宽的提升,NVLink相比上代也有1.5倍的带宽提升,但其实这些提升相较算力提升并不对等。这实际上要求英伟达在其他方面的努力:Hopper白皮书中有不少相关缓解带宽压力的技术点,下文也会部分提及。
为什么要加个Transformer Engine?
黄仁勋列出H100的6个主要技术点包括:(1)“全球最先进的芯片”,800亿晶体管;(2)加入Transformer Engine,提升6倍的Transformer性能;(3)确保数据与AI模型安全的confidential computing(机密计算);(4)第2代MIG(Multi-Instance GPU);(5)第4代NVLink,7倍于PCIe Gen 5的速度;(6)引入DPX指令,实现Dynamic Programming(动态编程)7倍性能提升。其中第1项就是本文第一部分的主要内容。先来看看其中的第2项,加入Transformer Engine。
对于Transformer Engine:从名字就不难发现,它是专为Transformer深度学习模型准备的。我们在以往报道AI芯片时经常提到Transformer。这是个主要应用于NLP(自然语言处理)和CV(计算机视觉)的深度学习模型,2017年由谷歌推出,现在的应用范围似乎又更广了。后续也有不少更大规模的NLP模型涌现,比如BERT、GPT-3、英伟达Megatron,但它们都基于Transformer。
黄仁勋也强调了Transformer的重要性,它“开启了自监督学习、消解了标记数据的必要性。我们可以使用庞大的训练集,学习更充分且可靠的表达。”

当前Transformer的处理越来越海量的参数,谷歌最新的Switch Transformer模型已经有1.6万亿参数了;Transformer相比其他所有模型,对于训练算力的需求,每2年就增长275倍。英伟达自己发布的数据是,用2048个A100 GPU去训练Megatron-NLG需要8个星期。
所以H100加入了Transformer Engine。这样的方向,感觉在AI芯片领域是由英伟达GPU提出来的还是有些让人意外。其实不少AI芯片公司很早就发现了Transformer的潜力,将其作为芯片架构的优化重点。而英伟达GPU针对Transformer做专门的架构改进,也能看出AI这条路上DSA对于性能、效率提升的必要性。类似这样的架构改进应当也是最让AI芯片赛道的参与者汗颜的。

所以Hopper的Transformer Engine将“新的Tensor Core与能使用FP8与FP16的数字格式的软件结合,动态处理Transformer网络的各个层”。最终让Transformer模型training过程“从数周缩短到数天”。
新引入的FP8数据格式,以及FP16混合精度一起跑,是期望跑的每一步都只用最低精度需求,同时又不损失精度的情况下来训练模型,以期达到最高的效率。其中具体如何决策网络的哪一层可以用FP8、用何种格式(所谓的Adaptive Format Conversion),是需要英伟达花功夫去研究的。
Alben说:“基本上,有个软件模块能够去分析Transformer,尤其要理解模型细节…”“这项技术是英伟达目前所掌握知识的精华。”“对应的软件单元需要去执行所有的工作,确保训练最终成功收敛。”Alben也给出了英伟达在研究过程中,针对各种大小的语言模型的FP8训练结果。这些都表明英伟达在Transformer Engine上的确是花了不少功夫的。
另外对于inference而言,Hopper可以直接用FP8训练的模型,不需要再做转换。有关FP8格式细节之类的问题,仍然建议去看一看Hopper白皮书。
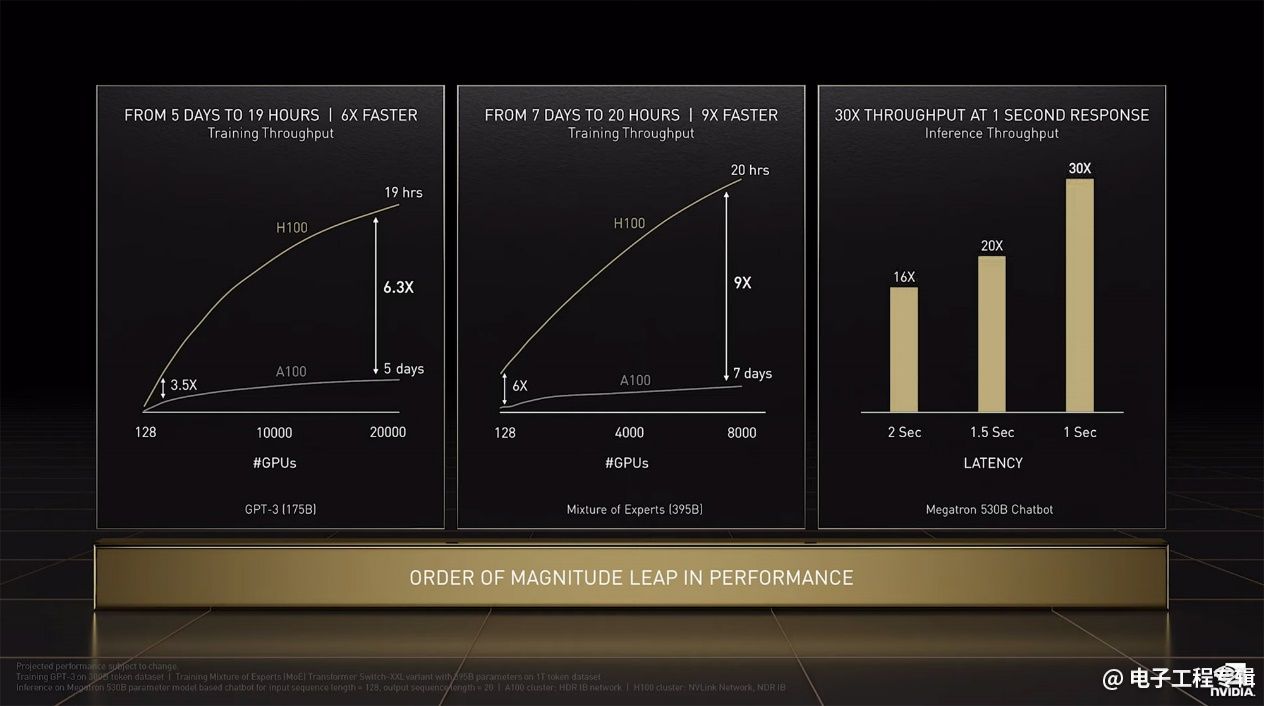
上面这张图是系统层面达成Transformer模型的性能提升:除了芯片本身的性能提升,还要再加上存储、I/O(Nvlink网络+NDR IB)等方面的考量,则GPT-3和MoE的training吞吐,基于H100的多GPU系统可以达到9倍提升;Inference方面,Megatron 530B界定响应延迟,有16-30倍性能优势。同时堆料,外加DSA就是如此神奇。
机密计算、DPX指令等特性
说完Transformer Engine,再来谈谈另一个比较有指向性的特性:DPX指令的加入。Alben表示英伟达一直有专注在基因学领域的强化上,我们知道英伟达GPU此前就有基因测序之类的应用了。
“其中的一大挑战在于把所有片段的基因对齐,构建整组基因——一种dynmaic programming算法,名为Smith-Waterman。”Alben说,“我们看到dynamic programming成为一类很重要的工作负载,所以我们加入了新的指令来加速这类负载。”

黄仁勋在主题演讲中还提到了Floyd-Warshall——一种可应用于机器人,在动态的工厂环境里最短距离优化的算法,这也是dynamic programming。所以H100在dynamic programming算法上的速度表现,相比A100提升了7倍。(PPT中所谓40倍的速度提升,对比对象应该是CPU)
Transformer Engine/FP8和DPX指令虽然是不同的方向,但这类新特性的加入基本可认为是半导体制造领域的摩尔定律放缓以后,DSA发展方向的必行之策。问题是究竟加些什么?为什么加Transformer Engine、DPX指令。这对英伟达而言应该是需要慎重思考的。
Alben对此是这么说的:“我们不可能把什么都干了。我们尝试去思考什么样的技术有价值,思考什么才是好的业务机会。可能10年以前,我们不会去加DPX指令,因为它还没有成长为一个重要的领域。但随着其发展,我们想要去对它做出支持。基于这样的想法,以及想法产生的可行的业务机会,我们会去赌这会是个很好的业务机会。”
与此同时Alben也强调了英伟达的灵活性(agile),很多芯片层面的特性增减不存在历史包袱,比如受限于芯片尺寸,加入FP8之后tensor core的某些其他特性就需要做出权衡——去掉的部分将来也还会回来。这种敏捷灵活的特性,也让英伟达可以去做这样的尝试。

有关H100,再谈谈其他改进。网络安全相关的confidential computing(机密计算)方面,英伟达表示这类解决方案以前都是基于CPU的, Hopper把confidential computing带到了GPU上,通过软硬结合实现计算加速。H100是“全球首个可保护使用中的数据与代码机密与完整性的GPU。”
“在confidential computing开启的情况下,藉由confidential虚拟机,会创建一个TEE(trusted execution environment)。节点内CPU与GPU、GPU与GPU之间的数据传输都会以PCIe线速加密、解密。”
“H100有个硬件防火墙,确保H100 GPU之上的所有工作负载安全,而且会对存储和计算进行隔离。除了TEE的owner之外,没有人可以访问内部数据与代码。这种设计确保了完全的虚拟机隔离,阻止任何未经授权的访问或篡改,包括hypervisor、主机操作系统,甚至是物理访问。”对这部分详情,仍建议阅读技术白皮书。
对于新特性之一的第2代MIG(Multi-Instance GPU),黄仁勋说此前Ampere就可以实现至多7个实例的切分;而Hopper则增加了完全的实例隔离、实例I/O虚拟化、以及搭配confidential computing,实现云上多租户。H100可托管7个云租户,且每一个在性能上都相当于2个T4 GPU。
以上这些只是Hopper架构H100改进的其中一部分,还有一些可列举的比如H100是首个采用HBM3片上存储的GPU。L2 cache增大,L1-D cache/共享存储增大。相比A100进一步异步化:包括Thread Block Cluster——一组并行的Thread Block,跨多个SM实现数据共享和协作;TMA(Tensor Memory Accelerator)可以在本地存储和共享存储空间内传输大型数据块,以及在Thread Block之间异步复制数据;还有Async Transaction Barrier实现片上加速器和通用线程不同组之间的高效同步等等……
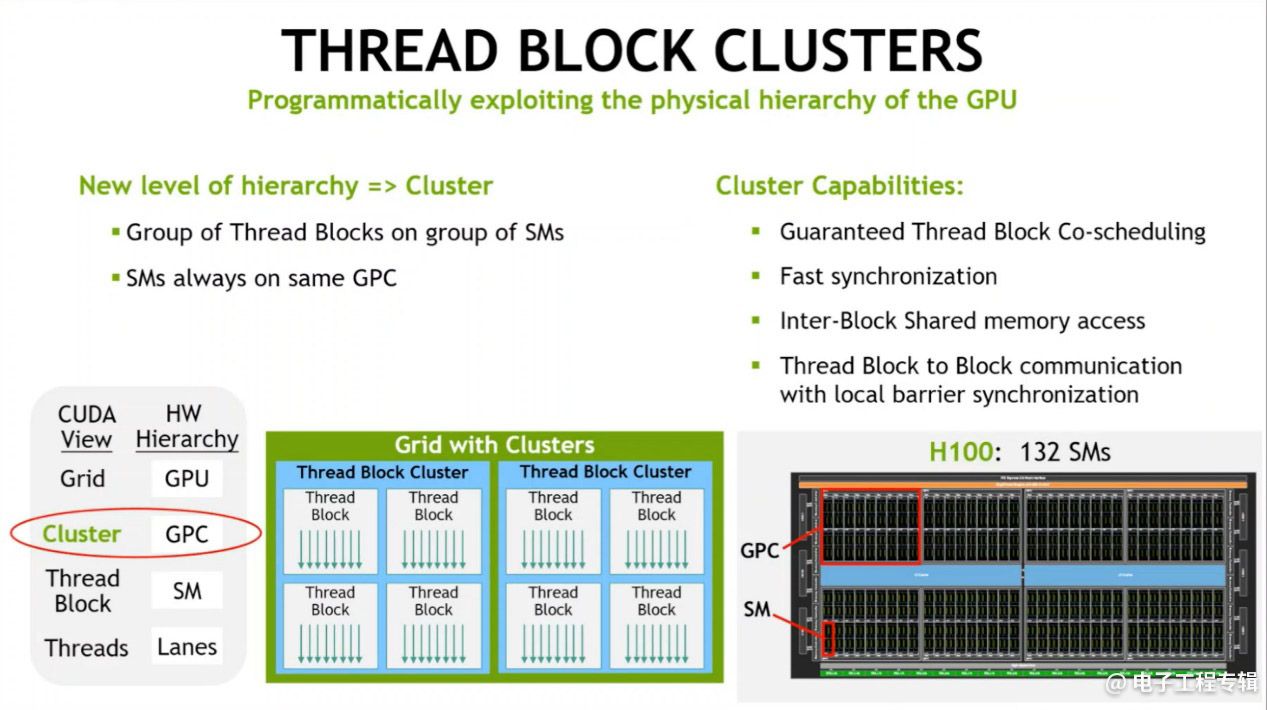
这其中不少相关CUDA编程模型的改进是值得去细谈的,比如说Thread Block Cluster。一个Thread Block包含在同一个SM中跑的多个线程,线程之间以barrier实现同步,用SM的共享存储(SEME)来交换数据。以前Thread Block是编程模型中唯一的本地单位(再往上是Grid),在SM多了以后,对执行效率而言就是不利的。所以H100引入了Cluster单位,以更粗线条的粒度,为开发者提供控制调度。一个Cluster包含一组Thread Block,是以一组SM的方式并行的,最终目标是实现跨多SM的高效协作。
它可以实现的一些特性如上图所示,比如说其中的Block to Block communication with barrier。由于共享存储的虚拟地址空间是分布在Cluster内部的所有Block上的,则所有线程就能直接访问其他SM的共享存储:
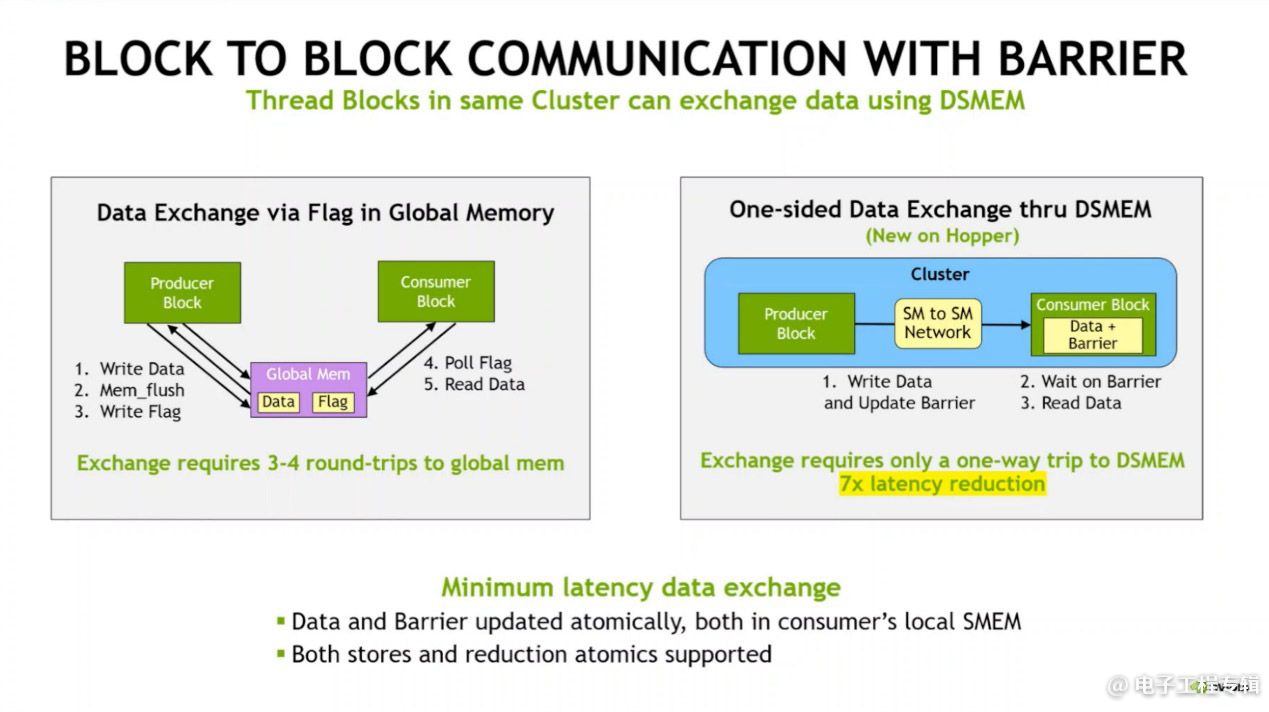
像Thread Block Cluster这种控制单位的引入是实实在在提升了不同算法的性能的;且类似这样的特性也算是缓解内存带宽提升与算力提升不同步的方案之一。受限于篇幅,更多内容此处不再多做介绍。
NVLink与系统性能:再2倍
前文已经把黄仁勋在会上列出H100改进的几个主要项目说得差不多了,还有最后一个没谈:第4代NVLink,相比PCIe Gen 5有着7倍的速度优势。很多企业构建的系统可能仍然没有采用NVLink网络:实际在系统层面,在芯片性能之外,NVLink是提供了不少加成的。
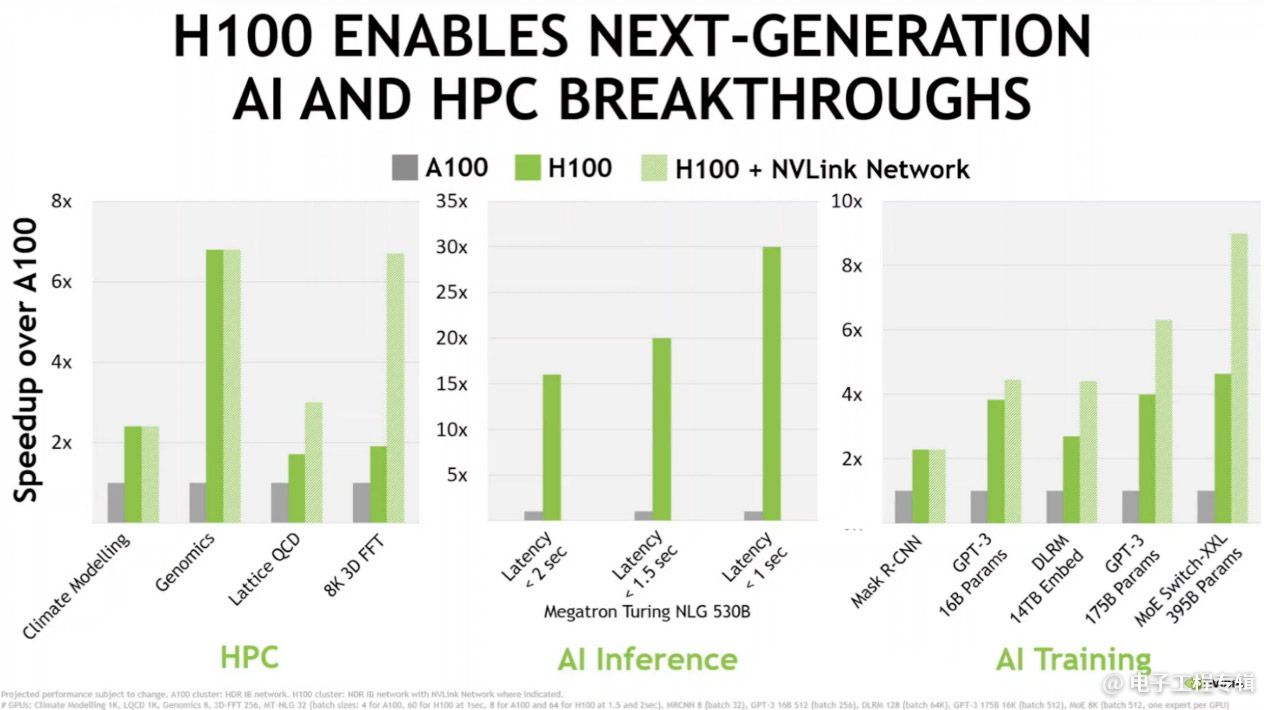
这组对比给出了HPC、AI inference、AI training三类不同应用,H100与上一代产品,以及加了NVLink网络以后的实际性能变化。某些应用,比如HPC中的基因相关应用就不会受到NVLink的影响,而像比较大规模高精度的3D FFT就明显受到带宽的影响;AI training中海量参数的大模型(比如DLRM这种推荐模型),相比不用NVLink的H100,会有将近2倍的性能优势。
那么接下来就聊聊NVLink网络构成的系统。这次GTC新发布的产品中,系统级变化实则也是亮点。
英伟达这次特别谈到了模型并行(model parallelism)的问题。早年ResNet-50这种小模型,一个GPU就装下了,则整个模型都可以跑在一个GPU上,规模化扩展是多GPU去跑不同的数据,实现数据并行——这种情况对I/O带宽的要求仍然不高,大家一起跑的过程里其实是不需要通信的。
但像前文提到的NLP模型,几千几万亿参数,那就需要对模型做切分了,于是就有了模型并行。在不同的GPU上去跑模型的一部分,每层输出都可能需要在GPU之间去共享结果才能进入到下一层。Alben说类似NLP模型的存在,就是NVLink发展的动力。

8个H100 GPU(外加ConnectX-7和系统其他组成部分)构成DGX A100,其内部用到了4个NVSwitch做互联,连接则采用NVLink,具体如下图所示。这个连接方案本质上与上一代DGX A100差别不大,不过吞吐仍然有提升。
第4代NVLink将H100的IO带宽提升到了900GB/s,相较上代提升50%:
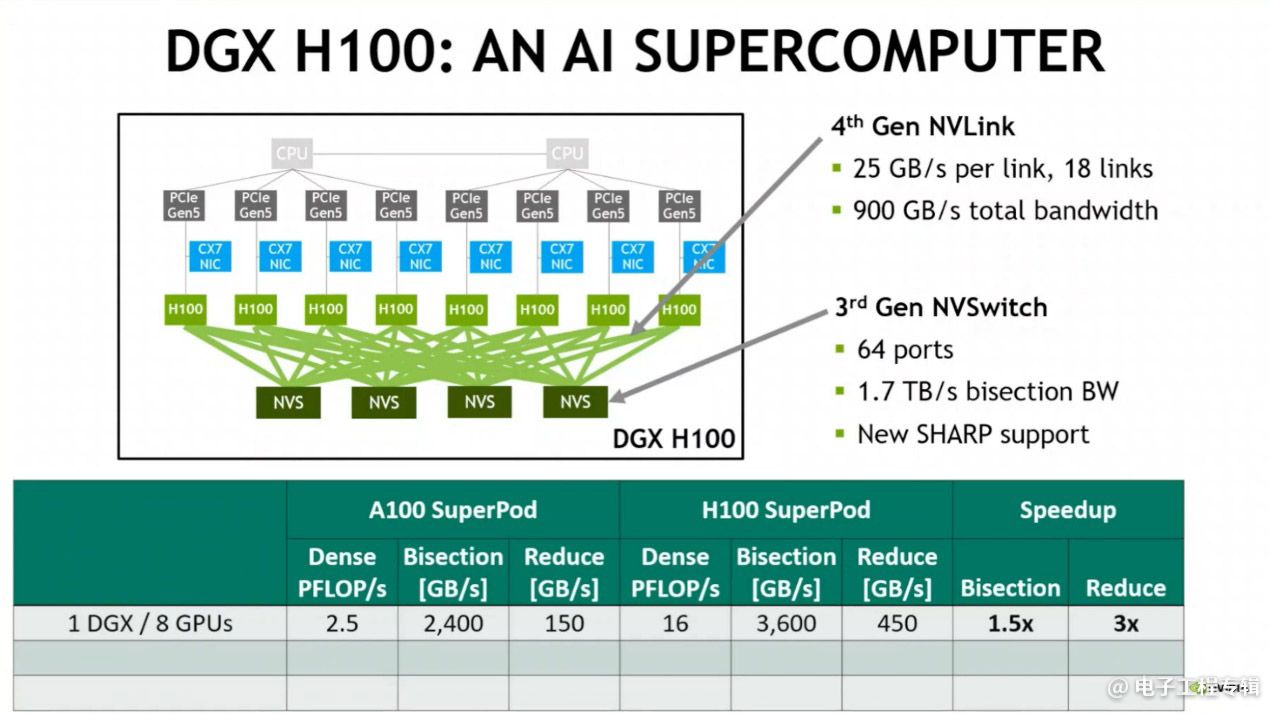
规模化扩展,32个DGX H100节点(256个H100 GPU)则构成DGX POD。这些DGX H100节点之间的连接是本次系统层面一个较大的转变,即在于他们连接到了这次新发布的、外部的NVLink Switch系统。
和此前DGX A100比起来,NVLink扩展到了更高层级,配合Infiniband为分布式训练提供更高效的通信效率:


如此一来,NVLink也就实现了跨节点连接,所以DGX H100 Pod相比DGX A100 Pod有着系统层面9倍的带宽提升。再往上做扩展,就用InfiniBand系统(Quantum-2 400Gbps Infiniband switch),把Pod连起来构成更大规模的DGX SuperPOD,得到以下结构和带宽数据:


上面图中给出了每次规模化扩展后,NVLink连接跨节点以后对于整个系统带来吞吐上的提升。不同系统的性能数据已经标在图中。黄仁勋将DGX SuperPOD形容为现代AI工厂。

英伟达自己用18个DGX POD(总共4608个H100 GPU)打造了Eos大规模集群,提到其18.4 ExaFLOPS AI算力,是全球最快超算Fugaku(富岳)的4倍。不过实际上以HPC的FP64算力来计,Fugaku仍然有着相当的优势(442 PFLOPS)。这一点其实也多少能窥见,H100虽然在HPC方面有提升,但这显然不是这次的重点。
有关明年要上市的Grace CPU
既然这篇文章主要是谈芯片,最后再简单谈一谈英伟达尚未问世的Grace CPU——去年GTC上黄仁勋就已经介绍过这颗CPU。Grace在定位上仍然是面向HPC和AI。黄仁勋在接受采访时再次强调了,Grace并不用于取代谁,“我们将支持所有需要我们支持的CPU。记住,英伟达是一家做加速计算的企业,我们热爱所有类型的CPU:是CPU,我就能连接做加速。”
而英伟达设计Grace,只是“设计市场上并不存在的CPU”而已。“Grace是个超级芯片(superchip),和市面上其他已有的CPU是不一样的。比如存储系统就不同:这是第一颗用LPDDR5的高性能CPU,内存和CPU集成到一起。两颗superchip中间用NVLink相连。内存带宽也很出色。所以其应用方向就是数据密集型应用,比如数据分析、数据处理、数据科学、AI、大型模型训练等等。”黄仁勋说,“市面上现有的CPU并不十分适合这样的应用,所以我们决定打造一款全新的CPU。”

英伟达所做有关Grace的发布包括NVIDIA Grace Hopper超级芯片,就是把Grace CPU和Hopper GPU放在同一个系统上,用“NVLink-C2C”(chip to chip)互联,带宽同样是900GB/s。相较DGX A100服务器里GPU的系统内存带宽有30倍的领先——这原本也是去年我们惊叹Grace与英伟达GPU协作时,在带宽方面的显著优势。

另一个重头戏是新款NVIDIA Grace CPU超级芯片的发布,由两颗Grace CPU构成,通过NVLink-C2C连接。这颗超级芯片总共就有144个CPU核心,1TB/s的内存带宽——从带宽数字来看,应该足够秒杀尚未问世的Xeon和Eypc了。
黄仁勋说Grace超级芯片的SPECint 2017得分大约在740分左右。单纯以此性能分数战明年的Epyc Genoa平台,可能还需要再观望一下;不过Grace超级芯片的能效表现大约会有很大优势。黄仁勋表示:“我们预计Grace超级芯片将成为最高性能、相比届时最佳CPU有着2倍能效优势的CPU。”
接受采访时,黄仁勋还说:“两颗芯片一旦连起来了,表现得就像一颗芯片一样。”虽说性能、延迟仍会有较小的差别,“但编程模型是一致的。”
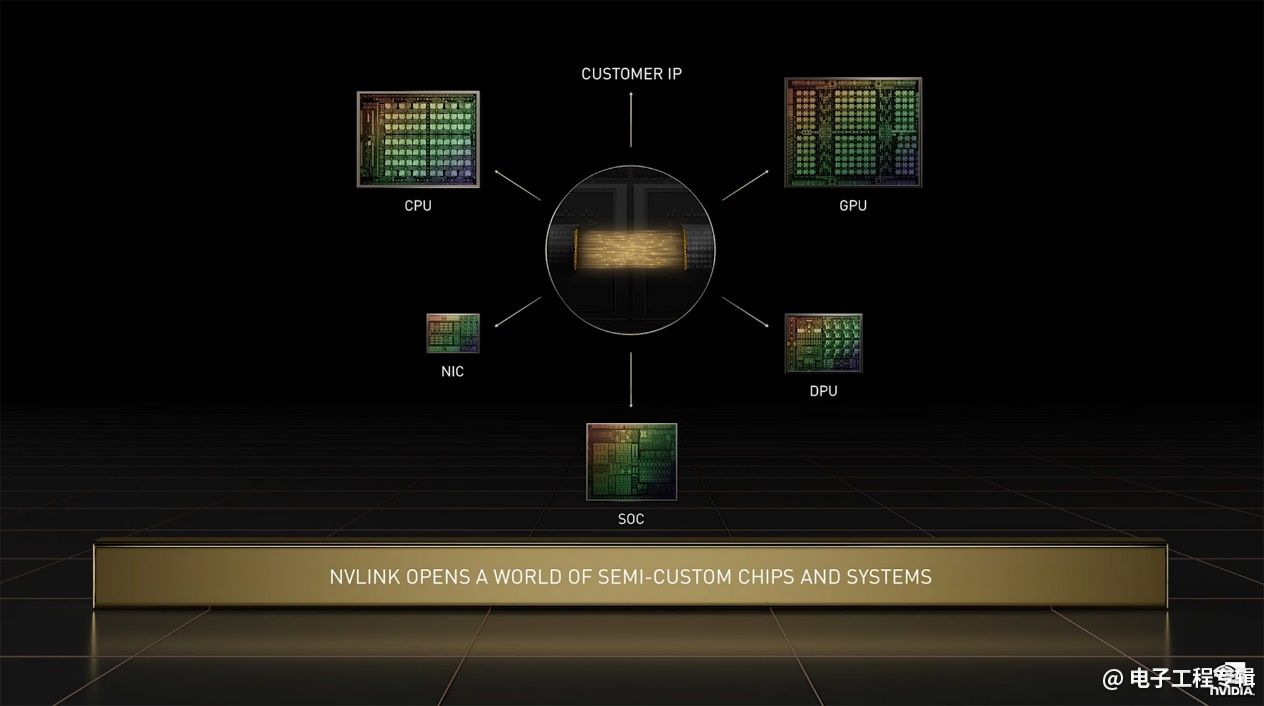
这里的NVLink-C2C互联也算是本次发布的一个热点了,毕竟多die先进封装就是半导体领域的热点。英伟达对NVLink-C2C的介绍不多。在GTC之前的一场pre-briefing上,英伟达数据中心计算资深总监Paresh Kharya给出的一张PPT提到几个关键点:
• 超快chip-to-chip互联,可将第三方芯片与英伟达的芯片连接;
• 基于英伟达SERDES与LINK设计技术打造;
• 支持Arm的AMBA CHI协议,达成Arm Ecosystem集成;
• 可以用在PCB、MCM、Interposer或晶圆级上;
• 相比于先进封装英伟达芯片的PCIe Gen 5 PHY,有着25倍更高的能效,与90倍的面积效益;
• 英伟达将支持开发中的UCIe标准。
看起来英伟达在此掌握的互联IP是偏上层的,各类基于chiplet的2D、2.5D先进封装都可行。另外就是将来我们有机会看到有不同的IP出现在同一颗芯片上,且以英伟达的技术做互联,打造“半定制系统设计”。

除了GPU、CPU硬件产品资讯外,我们还将对GTC 2022的其他内容做更进一步的报道,包括Nvidia AI、Omniverse等,毕竟这些生态构成,才是维系如今其硬件产品大卖的基础,也是其占领市场、寻得先机的绝对主力。
