
Intel要发布独立显卡已经不是什么新鲜事了,毕竟Intel不仅做了这么多年的核显/集显,2020年也有试水性质的Xe DG1独立显卡问世。去年的Intel Architecture Day之上,Intel就宣布了面向PC的独立GPU发布计划,GPU产品名为Arc——中文名“锐炫”。初代Arc GPU产品代号Alchemist。
当时我们就知道了这是将采用台积电N6工艺、基于Intel Xe-HPG架构的GPU产品——这还不是11代、12代酷睿处理器Xe-LP核显简单的规模化扩展;与此同时我们也撰文剖析了Xe-HPG架构本身。
今天Intel正式发布了Intel Arc A系列移动端独立显卡,面向笔记本设备。配置有Arc 3、Arc 5、Arc 7之分——这样的数字标识也算是Intel的老传统了。其中搭载Arc 3 GPU的笔记本已经准备好推向市场,更高性能的Arc 5/7则会在初夏上市。首款采用Arc 3的三星Galaxy Book 2 Pro已经上市,不过并不面向中国市场。预计从今年第二季度开始,国内会看到采用Arc独显的笔记本产品。

值得一提的是面向笔记本的Arc不会适配12代酷睿的U系列处理器(而仅搭配更高TDP的Alder Lake-H与Alder Lake-P),Intel对此的解释是搭载U系列低压处理器的轻薄本的功耗余量有限,故不会有搭配Arc独显的笔记本问世。这可能和低压处理器的I/O限制也有一定的关系。
另外Intel也确认了,Arc GPU可以在其他平台使用——也就是和别家CPU搭配。只不过考虑到后文将提到的Deep Link技术让Intel GPU和CPU配合致性能和效率最大化,以及操作上的可行性问题,我们认为笔记本平台恐怕很难会看到AMD CPU+Intel GPU的奇怪组合。
未来面向桌面PC的板卡产品自由搭配,倒是有这种可能性。但Intel Fellow Tom Peterson在评价这一问题时则说:“这个问题更多取决于OEM和ODM的规划,从技术角度来说并不难实现。随着Intel推出独立显卡产品,我们很期待接下来在市面上看到更多可能性。”
Arc 3先到,Arc 5/7要等到夏天
先来看看这次新发布的GPU产品。Intel自己对于Arc 3/5/7的定位分别是:Arc 3面向“主流游戏”,Arc 5可应用于“性能游戏”,而Arc 7则针对“硬核性能游戏”。

这次发布的Arc “A系列”移动独立GPU产品包含了上面这几款:A350M、A370M、A550M、A730M、A770M。不同型号在Xe内核数量、频率、光追单元数量、显存容量与位宽,以及显卡功耗上均有差异。
按照英伟达的常规,他们还会列个tensor core数量。对Intel Alchemist而言,每个Xe核心都配16个矢量引擎+16个矩阵引擎(XMX),所以看Xe核心数大致也就知道了矩阵引擎数量。Alchemist在AI单元方面的堆料,看起来比Ampere要猛一点。
举例说,其中A370M有8个Xe内核与光追单元,GDDR6显存64bit位宽、4GB容量,功耗设计35-50W。Intel并未给出与竞品之间的比较。单纯从显存容量、位宽以及功耗来看,Arc 3比较可能的对标对象是GeForce RTX 2050 Mobile和MX570(但后者并没有光追、超分这些特性,显存容量也低很多)。
不过现在的GPU,在光追、AI专用单元之类的配比上都比较“个性化”,很难有综合的性能评定与比较;加上不同GPU厂商与架构对于“核心”定义差别甚大;而且Arc独显率先用上N6工艺也会有功耗和效率方面的优势;最终还是要看不同应用的实际性能比较。
而A550M则在各方面的用料上,都比A370M翻了一番。目前最高配的A770M则有32个Xe核心,256bit位宽、16GB GDDR6显存,以及最多150W的参考功耗。Arc 5和Arc 7应该会以GeForce RTX 3060及以上定位的GPU为竞争目标。
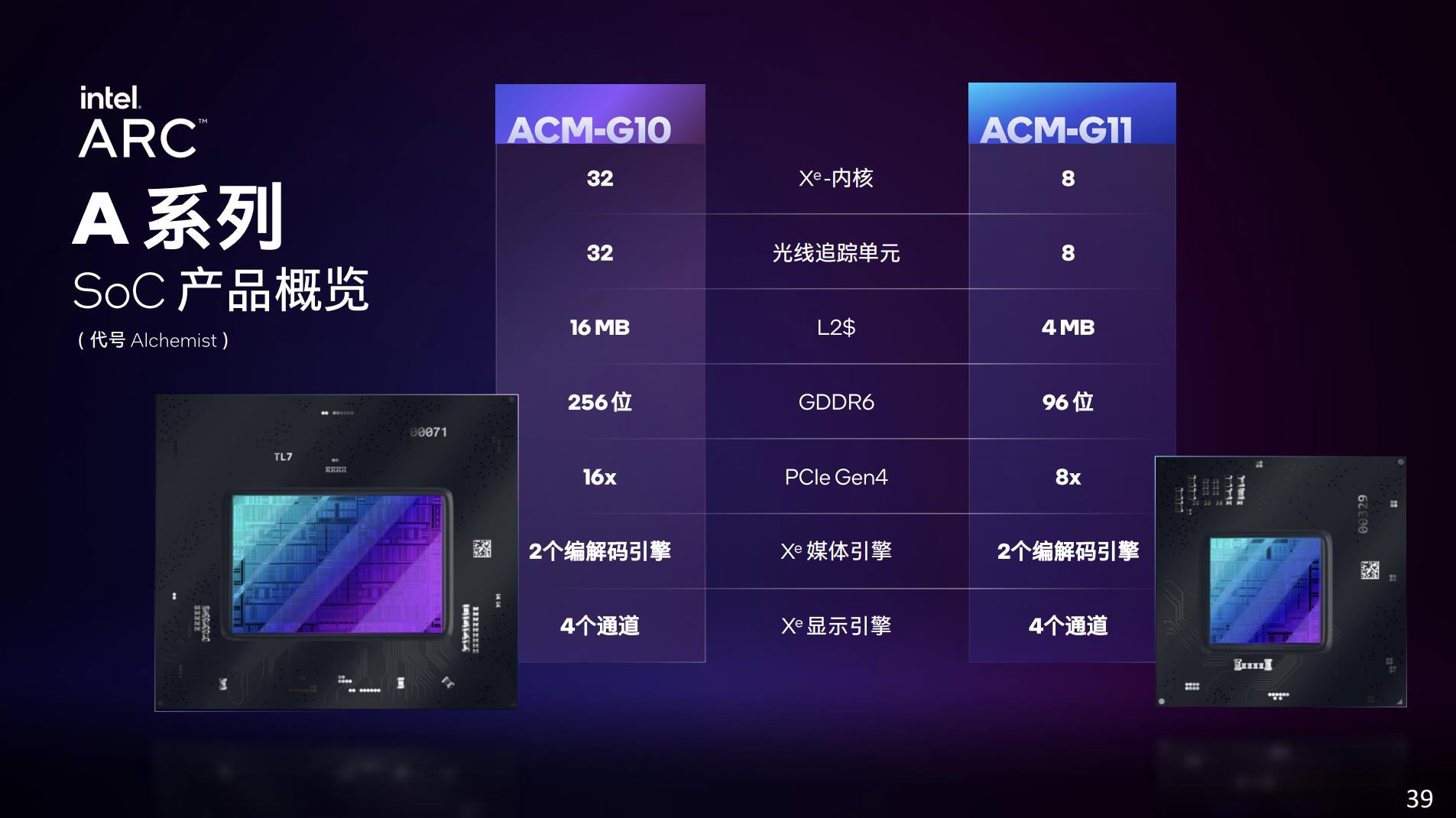
Intel展示了两种尺寸和规格的die(ACM-G10/G11),对应于不同的规格。有可能其中的ACM-G11是专门用于Arc 3的,而ACM-G10则通过binning process做成Arc 5/7更多的SKU。

值得一提的是,Intel特别提到了显卡时钟频率的定义问题。Intel强调GPU在间歇性的轻度负载状态,可以跑在比较高的频率下;而游戏这类负载很重的场景,在大量运算单元发挥作用时,频率就会比较低;于是GPU的时钟频率在一个动态范围内;接近中间的频率出现的概率会更高。
Intel表示:“考虑到这种分布情况,我们制定独立显卡参数配置时,先标定一个有代表性的负载,然后在该负载运行时,全程测量并统计时钟频率分布。最终将平均时钟频率作为参数配置中的定义。”于是前面我们看到的频率,应该并不是指其最高频率。另外OEM厂商的不同功耗设定下,频率的分布范围可能也会有变化。
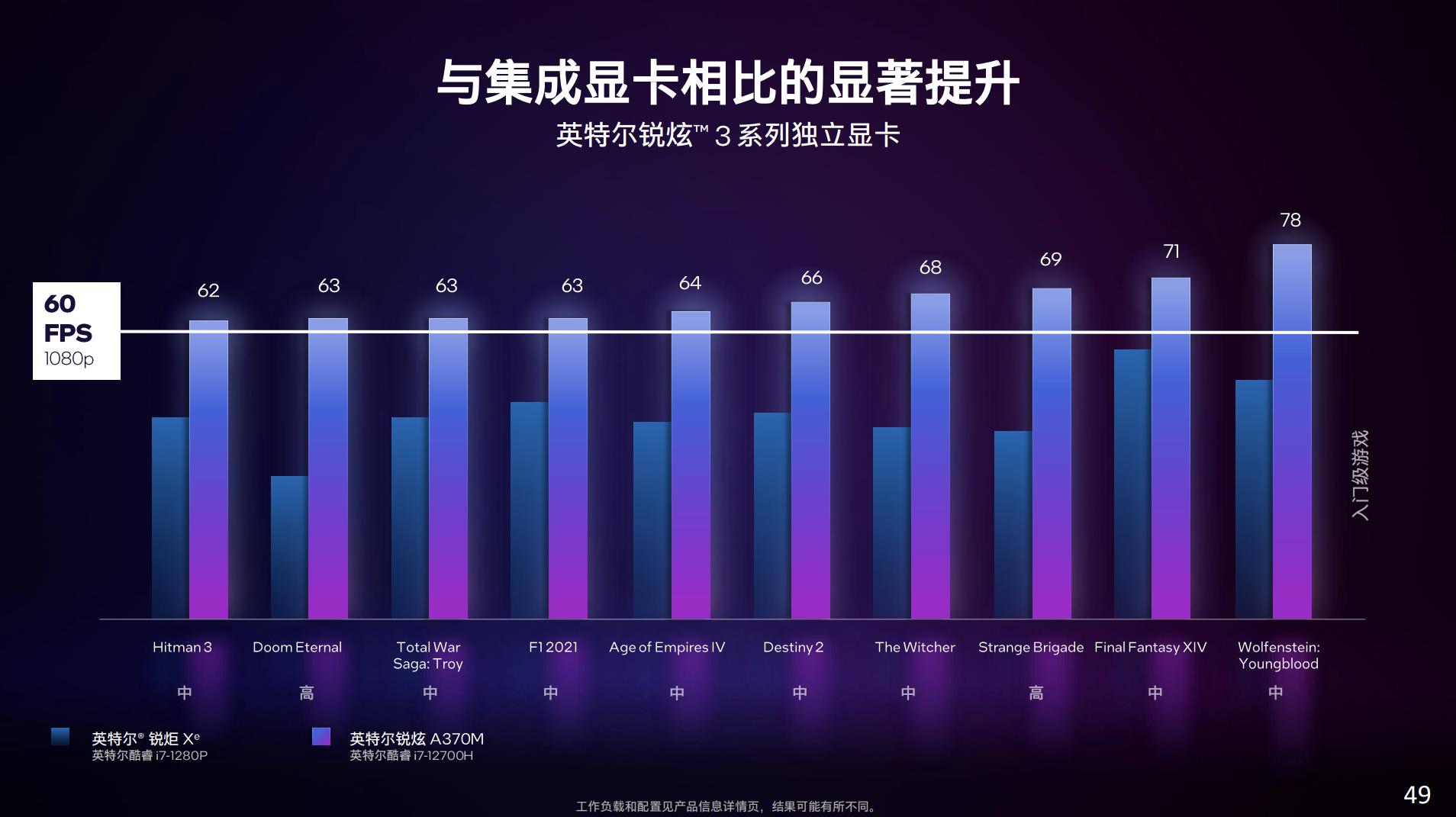
以上是Arc 3 A370M相比12代酷睿的Xe核显(96EU)在部分游戏中的性能比较。包括《杀手3》《F1 2021》《最终幻想14》等游戏,都有不同程度的帧率提升。尤其《毁灭战士:永恒》《巫师》之类的游戏,理想情况下最高有2倍帧率提升。注意其中的画质设定是有差异的,不过都是以1080p分辨率去测试的。
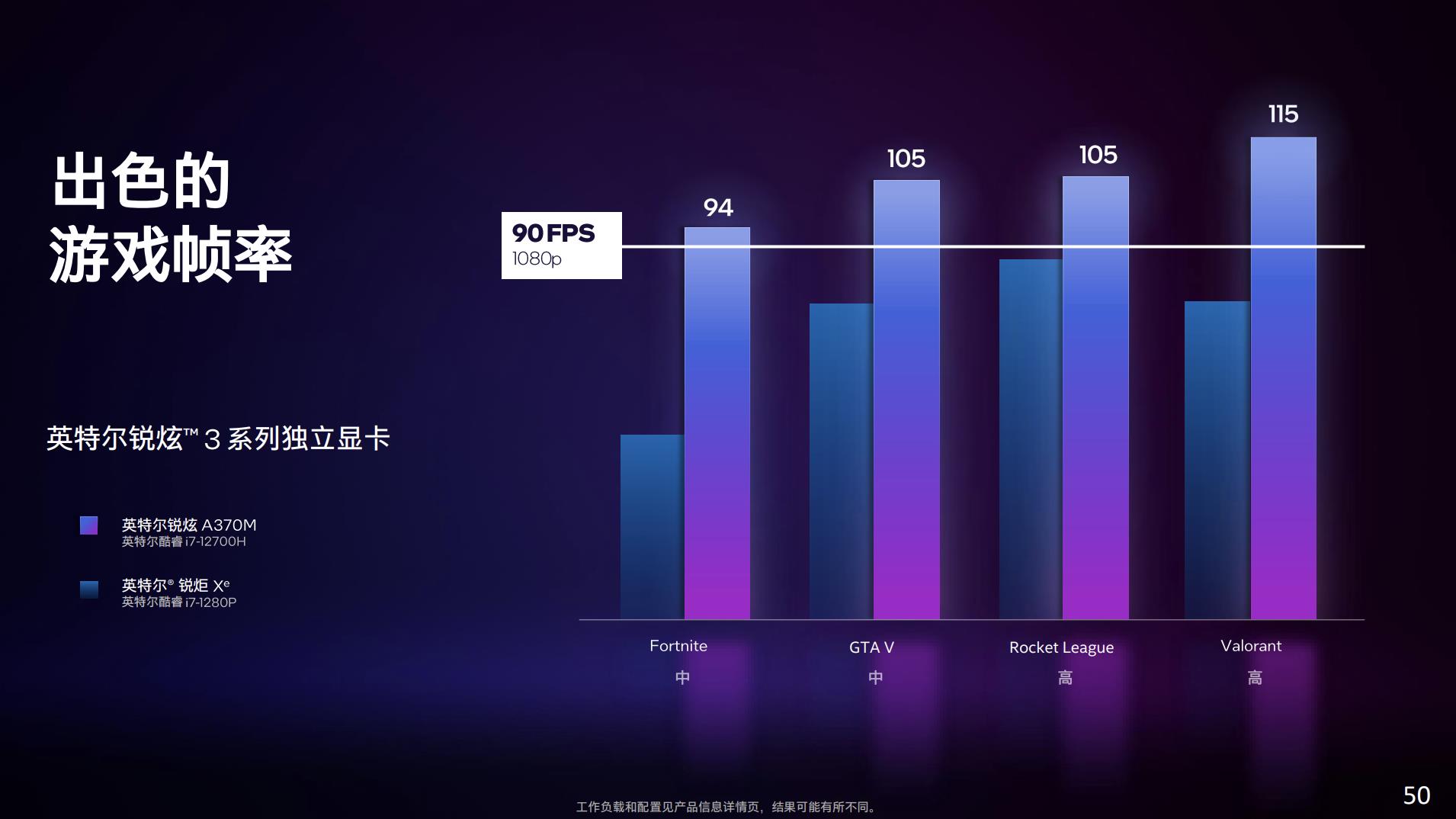
《堡垒之夜》《GTA5》之类的竞技类游戏,在1080p中等画质下也能越过90fps的帧率。这两组对比的样本量感觉还是太小,也没有非常近代的3A大作,毕竟Arc 3在定位上还是偏向于入门的。另外就是这些测试也没有发挥XeSS、光线追踪特性。与隔壁N厂和A厂笔记本独立GPU对比可能还需要等更多的实测数据。
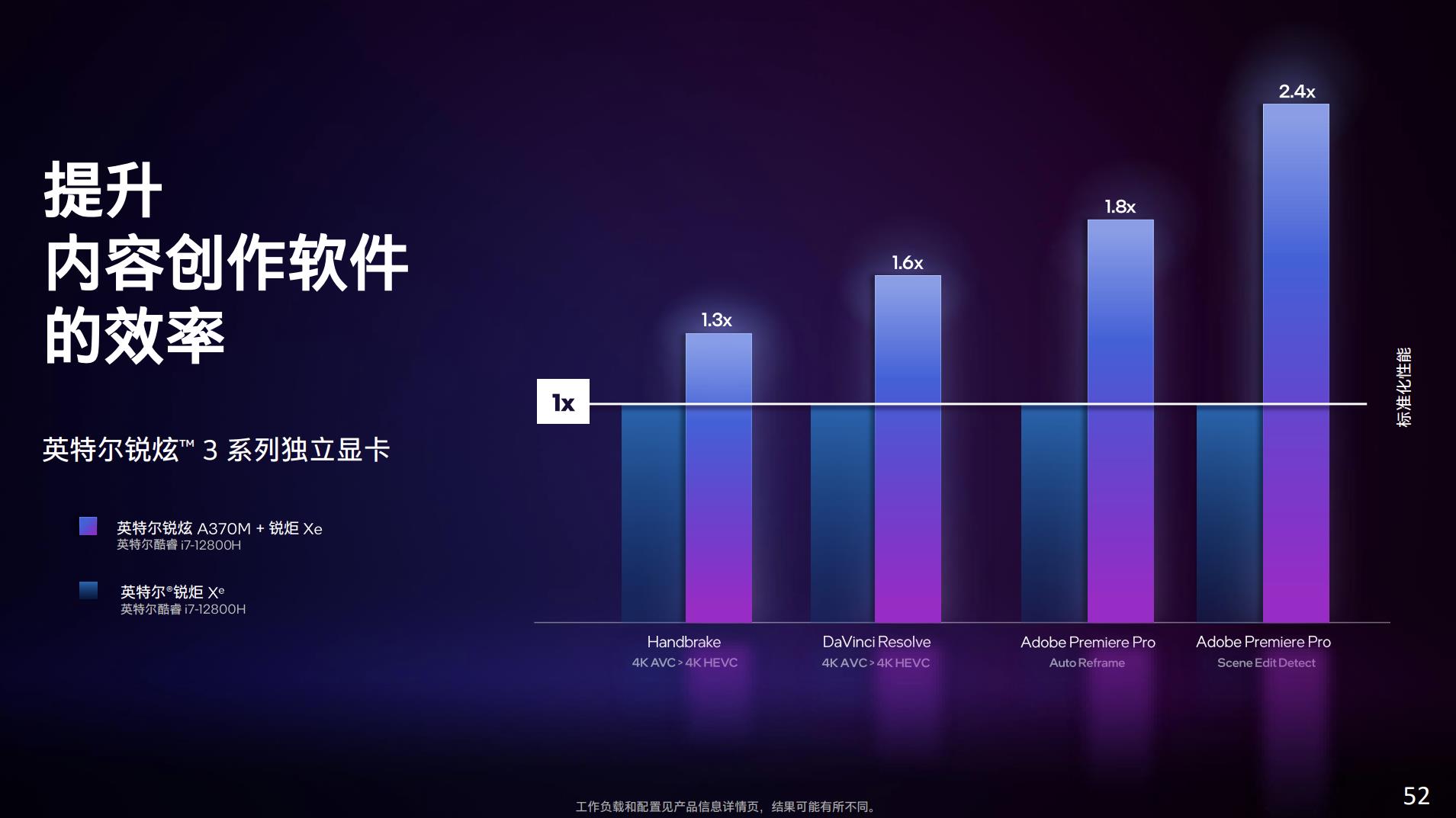
除了游戏之外,Intel也给出了内容创作应用的性能对比,包括用Handbrake和达芬奇进行4K H.264→4K H.265转码测试,还有用Premiere执行两个特定功能操作——这里的Auto Reframe和Scene Edit Detect应该都是需要用到AI加速的——Arc GPU的XMX矩阵引擎就能发挥作用了。
这几个场景下,A370M相比12代酷睿的Xe核显有不同程度的性能优势,虽然感觉这几个场景都好具体,并非很综合的系统性能测试。
另外值得一提的是,这两者的对比并不单纯是Arc 3与核显之间的较量。后文将会提到Intel的酷睿处理器和Arc GPU有一些特别的协作特性(Deep Link),所以Arc独显可以和Xe核显一起对某些工作负载做加速。
Intel这次并未给出Arc 5和Arc 7的性能比较数据。
光追、超分、Smooth Sync等特性
Alchemist全系GPU都支持DirectX 12 Ultimate的那些知名新特性,包括光线追踪、VRS(可变速率着色)Tier 2、mesh shading(网格着色)、sampler feedback(采样器反馈)等。这些我们在此前的架构解析文章里也都已经提到过。
尤其其中的光线追踪实现,Intel也为Arc GPU加入了专门的光线追踪硬件单元——用于光线遍历(ray traversal)与包围盒相交(bounding box intersection)与三角形相交运算。
光线追踪之外的另一个重要特性就是超分(或超级采样)技术了,即通过计算将低分辨率画面升格到高分辨率的过程,GPU只需要渲染低分辨率的画面,最终也能获得近似于原生高分辨率画面的观感,节约资源的同时提升了帧率。
Intel的XeSS即是应用了AI的超分技术:XeSS原理是藉由画面中的临近像素,以及过去帧进行运动补偿,来重建像素细节,该过程也需要通过神经网络进行,和英伟达的二代DLSS比较类似。此时,Xe核心内的XMX矩阵引擎(或也可以是DP4a指令)就能发挥作用了。
当然我们很难搞清楚Intel XeSS在实现细节和效果上与DLSS的区别。Tom Peterson在接受采访时说:“我们利用AI和深度学习技术已经训练过各种不同的游戏了,相信我们的网络模型能够很好地适配不同类型的游戏。”至于与别家比较,基于AI做超分“将来会成为激烈竞争的领域”…“这对对比、评估、基准测试来说,其实都是个全新的领域”,“很难去直接比较我们的AI网络和别家的同类技术。”

从Intel的演示来看,效果还是相当不错的。具体表现如何,其实还有待对游戏的更多复杂场景做测试。毕竟我们知道DLSS一代在某些动态场景下也是会翻车。而且这项技术要以最高效率跑起来,也依托于Intel的GPU生态构建能力,作为一个新的入局者,Intel有待市场考验。
Intel在会上宣布了首批支持XeSS的14款游戏,如下图所示。“预计未来几个月还会有更多游戏加入。”

另外值得一提的一项特性,是为解决帧率与刷新率不一致导致的画面撕裂问题相关的同步技术。Intel独显除了支持VESA标准的Adaptive Sync(调整显示器刷新率,令其与GPU输出帧率吻合的技术),另外有个Speed Sync。
Speed Sync是Intel自家的技术,其目标也是解决垂直同步导致更高响应延迟的问题。“Speed Sync通过关闭V-Sync来改善这一点-减少排队-我们将始终显示最后一个渲染帧的整体,而不是撕裂。”不过在媒体沟通会上,Intel并未详述是如何“改善”的。
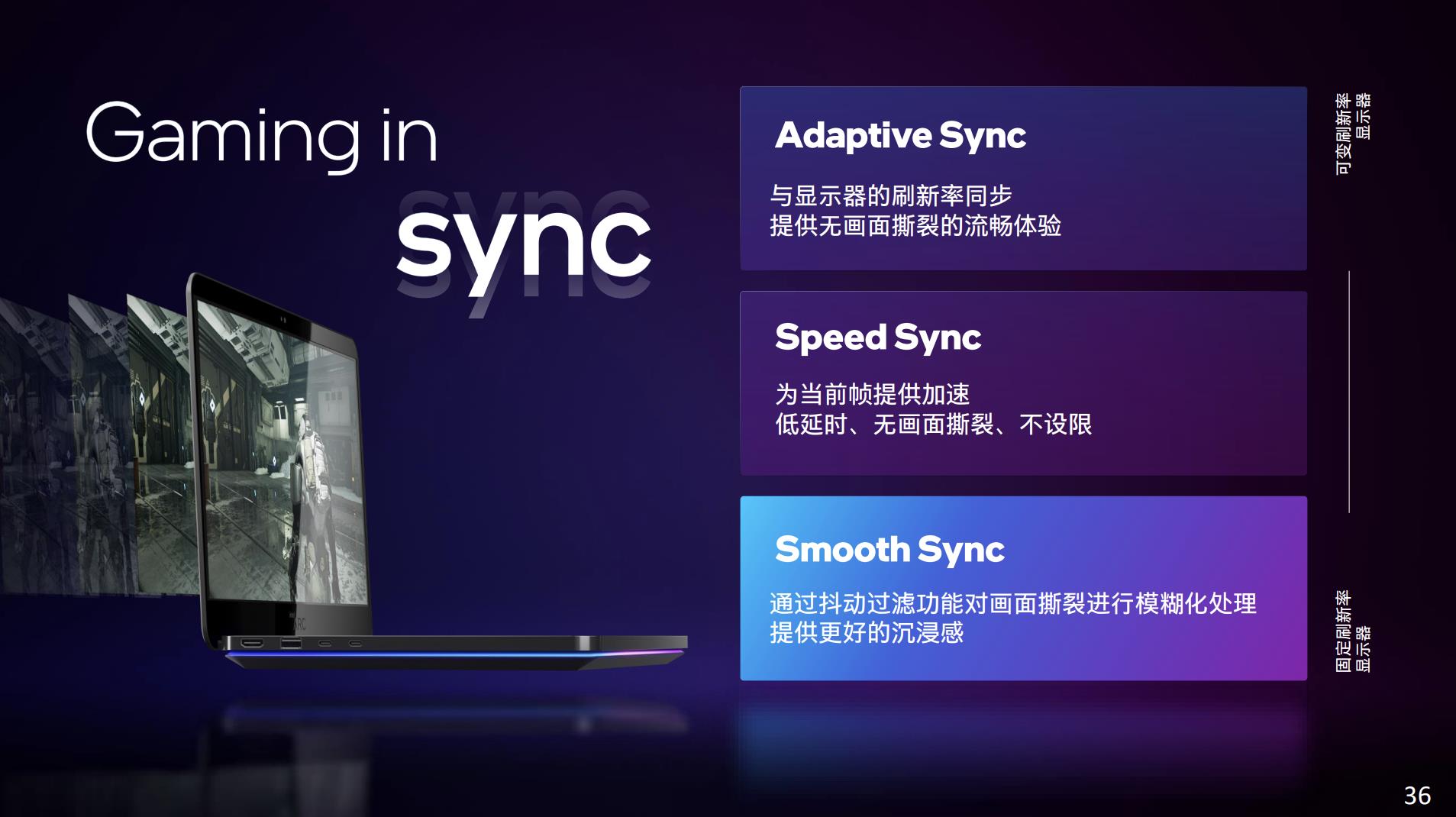
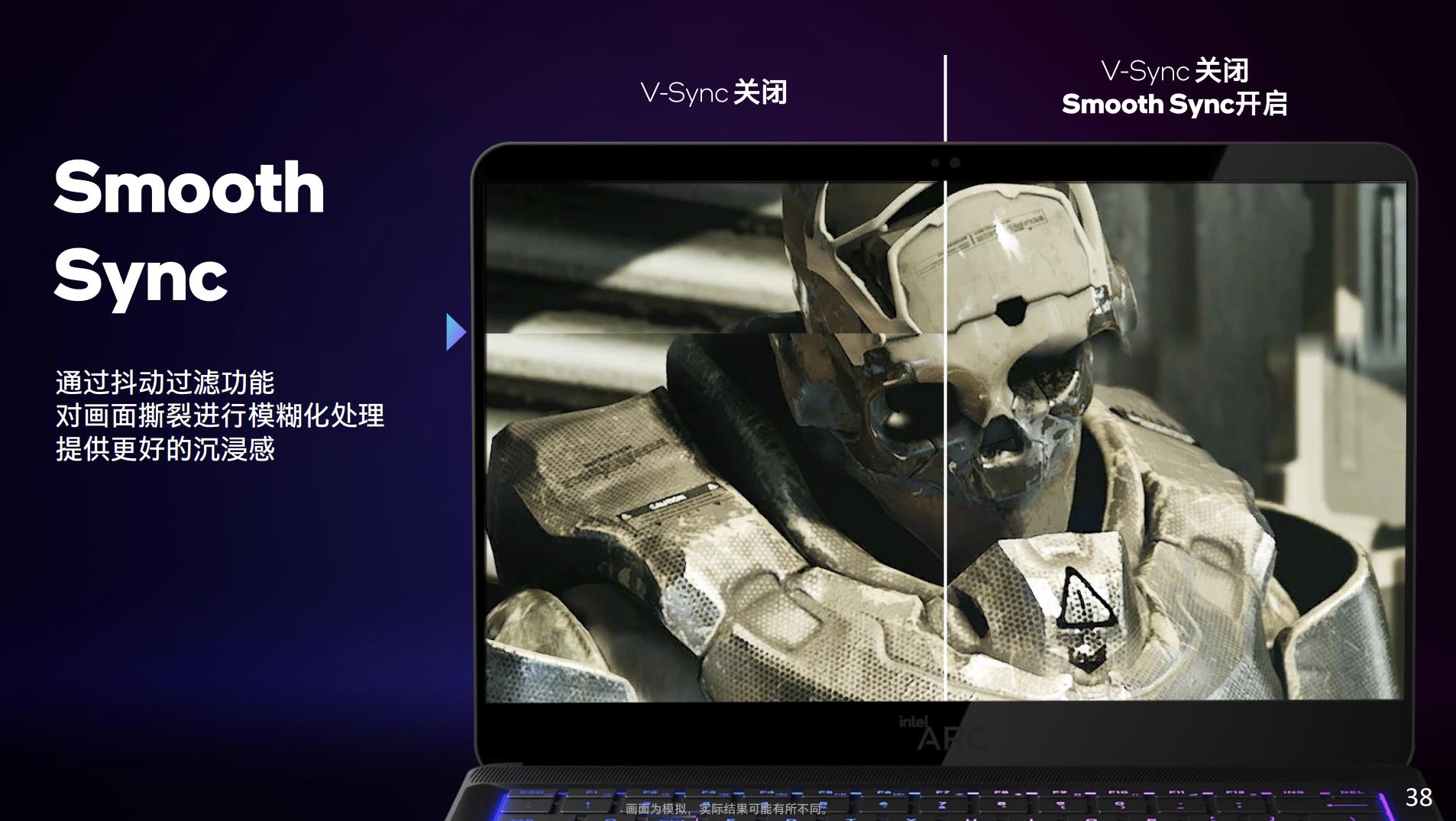
除了Speed Sync以外,还有个“与锐炫一起推出的一项全新的Intel技术”Smooth Sync。这种技术的方案是对两个撕裂帧之间的边界做模糊化处理,降低画面撕裂带来的体验影响。思路还是相当新奇…静态画面看起来基本可接受,不知道画面动起来体验效果会是怎样:
CPU与GPU应该搭配干活
AMD这两年正努力发挥同时造CPU、GPU的优势,推一些专属于自家平台的优势技术,比如说SAM(Smart Access Memory)。不难想见Intel开始造面向PC的独显,也必然全力发挥这方面的优势——尤其在CPU还另有核显的情况下,不能让真金白银的die白白浪费了。
如前文提到的,Arc独显可与12代酷睿及其核显搭配,优化效率或协同完成某些工作。这类技术统称为Deep Link。Intel主要列举了Deep Link的动态功率共享、超级编码、超级算力三项特性。
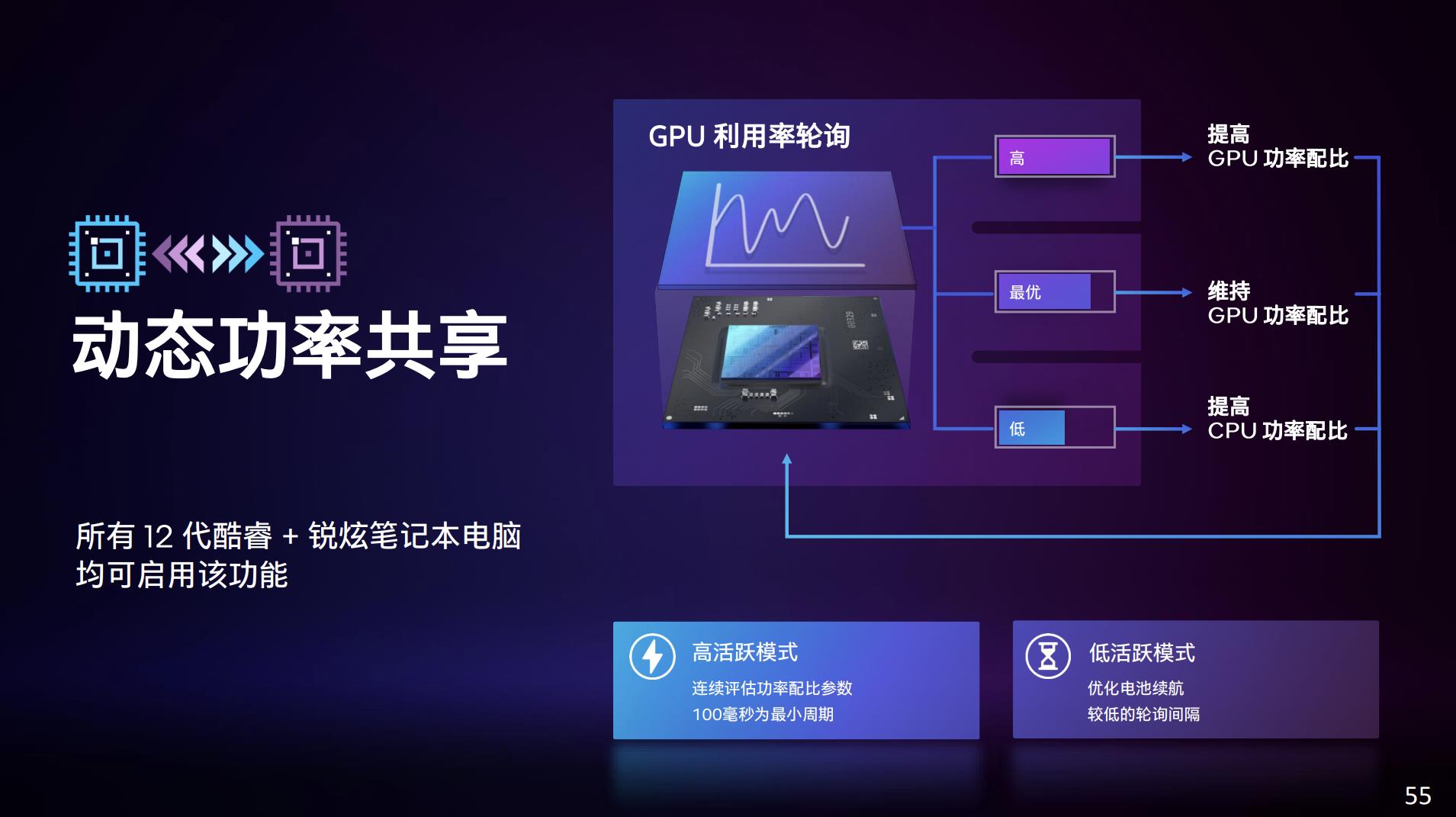
其中动态功率共享是个类似于英伟达Dynamic Boost的技术。Intel说当年的Kaby Lake G(就是传说中加上了隔壁Vega die的处理器)之上,就已经在用自家的“第一版动态功率共享”技术了;后续Tiger Lake(11代酷睿)、Alder Lake(12代酷睿)一直在做技术改进。这类技术的本质都是在CPU或GPU任何一方更需要功率的情况下,有个动态分配机制。
另外在系统处于高负载状态下,如游戏场景,为加快响应负载变化,系统会以100毫秒为最小间隔来动态调控功率配比;而在轻载场景下,不需要快速响应时,为实现节能则该时间窗口会变大。这也更符合笔记本这类形态设备的需求。
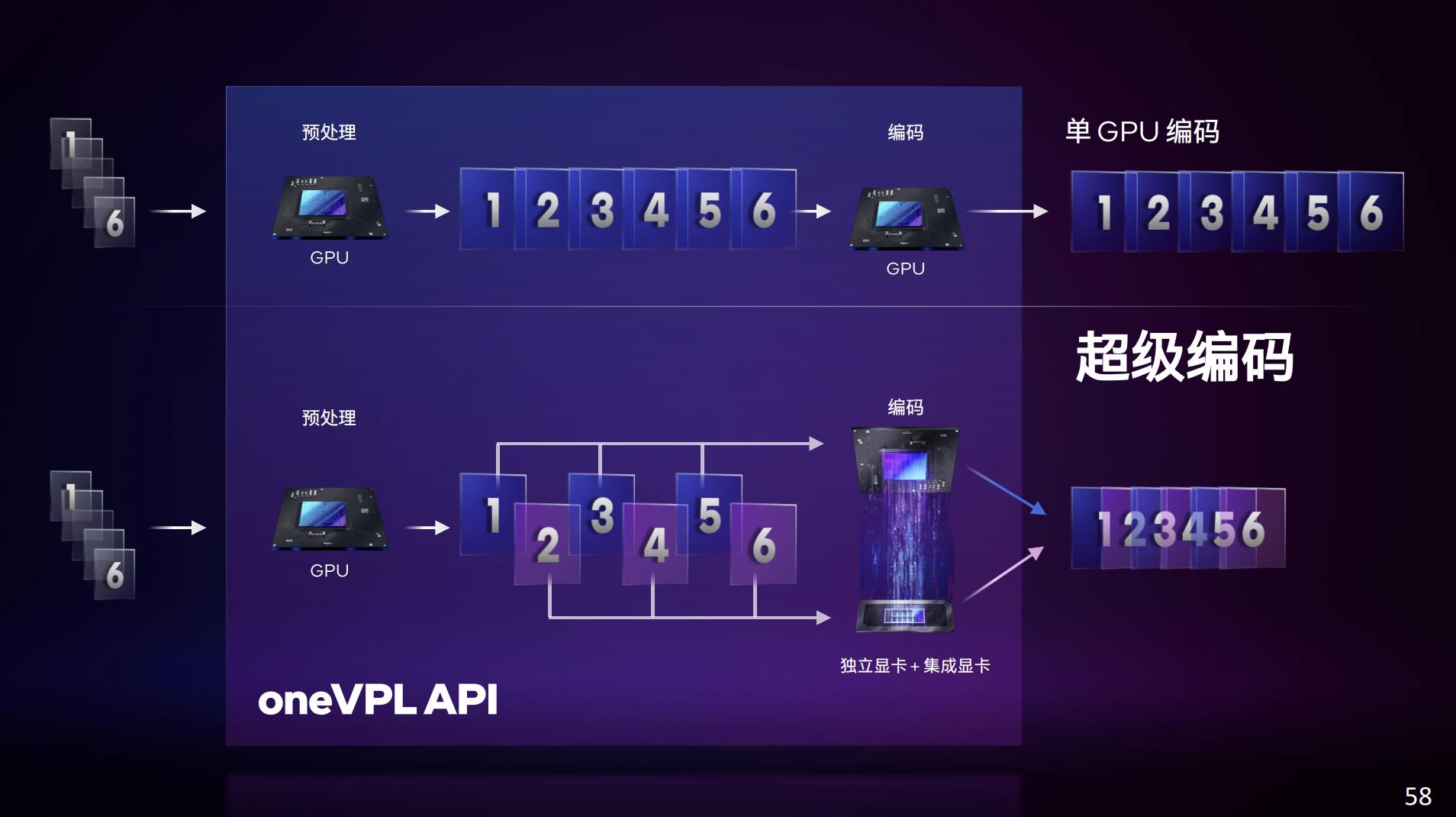
而超级编码技术,在Alder Lake-H处理器报道文章里曾谈到过。这项技术是把媒体编码工作交给Arc独显和酷睿处理器的Xe核显去协同完成。我们知道以苹果为代表的处理器SoC,越来越看重媒体引擎的性能。11代酷睿之后,Intel就在刻意加强酷睿处理器某些格式的媒体编解码能力。
所以核显与独显的配合工作就显得顺其自然了。不过该特性要求开发者去调用oneVPL的API。原始帧通过API交给oneVPL,把工作按组分配给独显与核显;oneVPL最后完成打包工作,把编码后的帧拼接成最终视频并输出。
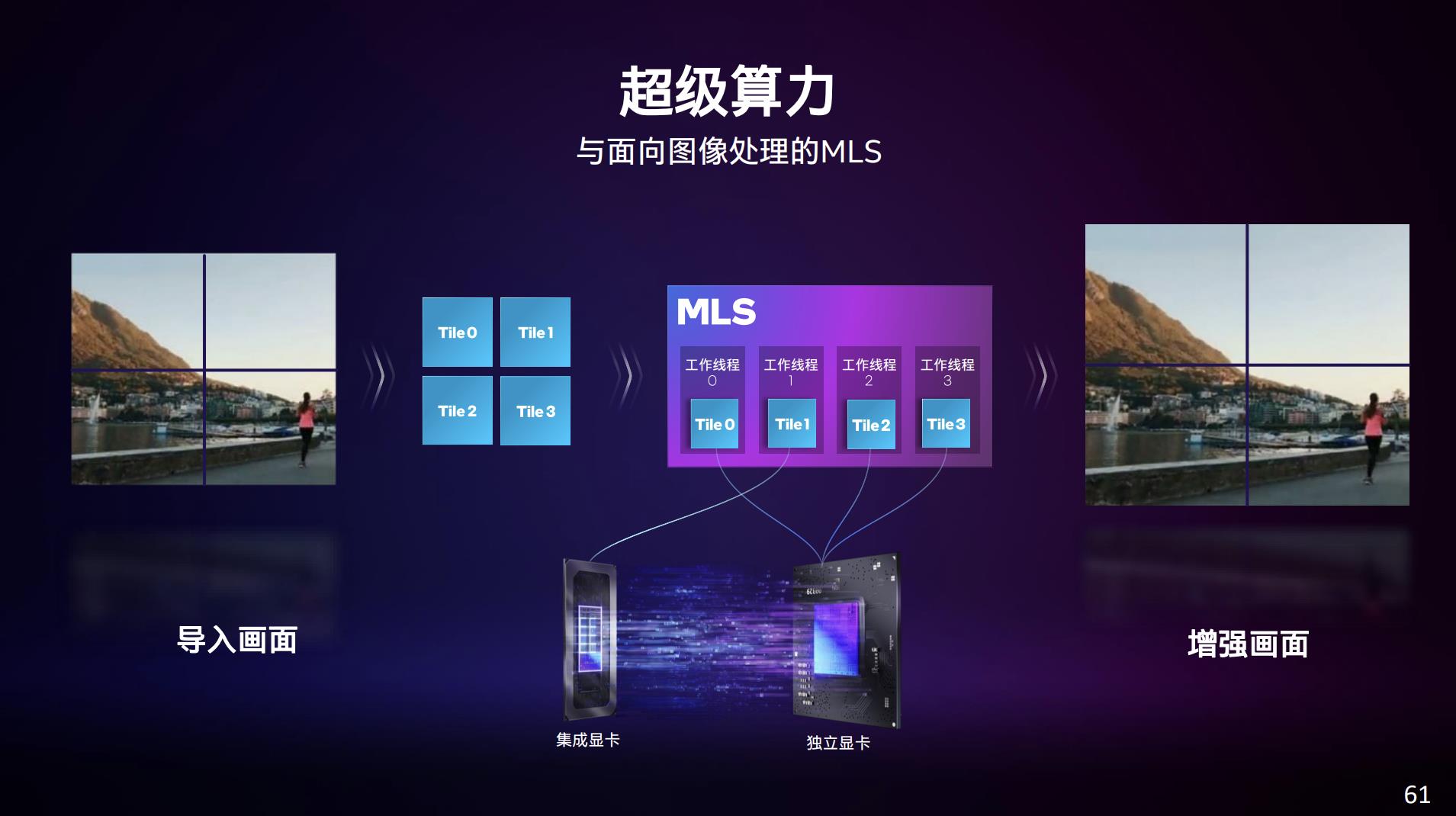
Deep Link技术中还有一项具代表性的特性是“超级算力”,在某些应用中同时结合核显与独显的算力。比如说对一段视频做去噪、超分之类的处理,则由MLS(机器学习服务,OpenVINO中的一个框架)获得视频每一帧切分成的tile以后,将这些tile智能地分配给不同的算力模块——这个过程会考量负载的延迟敏感度、吞吐量、性能要求、功率消耗等因素进行分配。

似乎“超级编码”“超级算力”这类特性本质上都属于Intel XPU生态的组成部分和在PC平台上的延续。这种不同算力模块的协同、配合方式,就Intel的介绍来看,性能和效率的提升幅度都还挺大。
具体到Deep Link技术生态的扩展上,Intel表示会跟不同的ISV合作,实现这些技术在不同系统上的支持。“我们现在已经在达芬奇、Handbrake这些软件上做了赋能。未来会在更多的软件里看到这些功能的实现。”所以说前文对比达芬奇和Handbrake的转码能力是有原因的。我们认为,Deep Link只是整个Intel大生态的一个组成部分罢了;而这部分的成功与否其实能够很大程度窥见Intel现如今的号召力,我们也拭目以待。
与此同时,Deep Link技术在我们看来可能会成为Intel在PC独显市场竞争成功与否很重要的一个组成部分。毕竟英伟达的GPU生态已非一日两日,而AMD则有游戏主机这一天然优势市场。Deep Link则属于Intel这名新入局者的优势项。
Alchemist GPU的其他能力
其实Intel本次媒体分享会的一个重点,也在于花比较大的篇幅去谈了Xe-HPG架构。不过相关Xe核心、L1 cache/共享存储、内部的XMX、及Xe核心构成的render slice、光追单元等大部分内容,我们都已经在《Intel GPU的野望:从游戏到数据中心》一文做过解析,本文不再多做赘述。

不过去年的Intel Architecture Day上,Intel并未谈到配套的Xe媒体和显示引擎。Intel在本次的产品发布中,强调Xe媒体引擎是“业界首个为AV1构建硬件编码支持的GPU供应商”,强调比软件编码“快50倍”。FFMPEG、Handbrake、Premiere Pro、达芬奇、Xsplit都已经对Arc的硬件级AV1加速做出支持。

而在Xe显示引擎方面,Arc独显当前主要支持HDMI 2.0b、DP1.4a规格,“游戏玩家能够享受1080p@360Hz,或4台具有4k@120Hz HDR的显示器。”
除此之外值得一提的是,Intel当前已经发布了Arc Control锐炫控制面板app,提供各种相关Arc GPU的设定、性能调整、驱动升级等特性,有性能监测、虚拟摄像头、直播设置等功能。

这一阶段发布的独显主要针对的是笔记本市场,而且首先以Arc 3为主。如果笔记本如期上市,则最应感到压力的应该是英伟达目前应用于入门市场的一众独显产品——虽然最终还是要看带Arc独显的笔记本产品售价。
不过在更高端的市场上能否抢占先机,还要看Intel的动作是否足够快,尤其是在如今RTX 4000系列尚未问世的利好时期。无论如何,PC GPU市场多出一个市场参与者对消费者而言终归是好事,像Tom说的“接下来,大家可能需要更加习惯听到关于‘I+I’的故事了”,更何况这还将有利于显卡价格的进一步平稳。

