
几十年来,半导体行业每18-24个月芯片制造工艺都有一次迭代,实现更高的晶体管密度,达成更低的晶体管成本。虽说最近我们探讨了单晶体管成本这些年是在增加的,摩尔定律的某些组成部分也还在延续。
每个节点之下,某个维度的晶体管尺寸(gate length)缩减至上一代的0.7倍,在相同功耗下要达成性能40%的提升,与此同时面积有50%的缩减。这个“定律”推动了大量电子产品的发展,功耗更低、速度更快、功能更多...


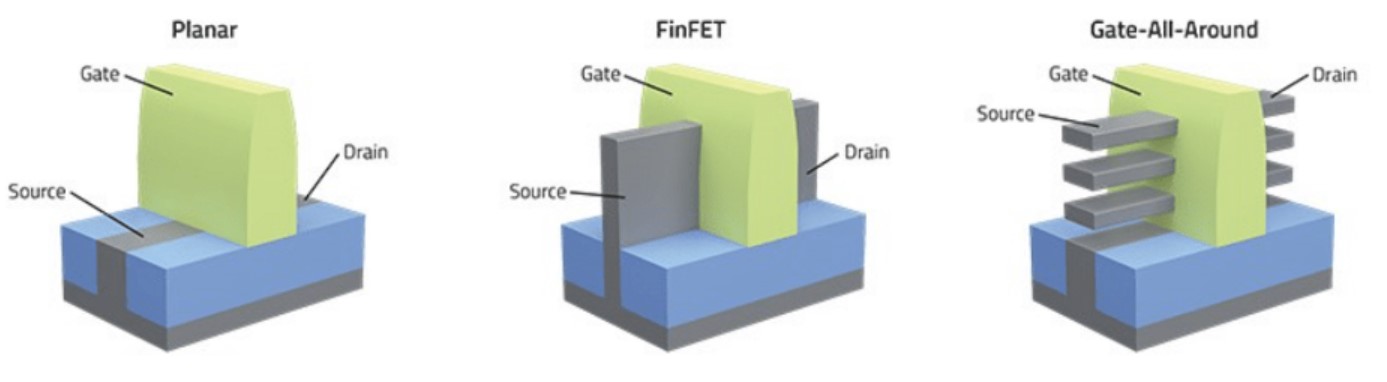
传统的2D平面结构晶体管(planar transistor)在多个工艺节点上延续,藉由更先进的lithography设备和其他工艺技术进步来实现。但2011年,行业在20nm节点遭遇瓶颈。这种结构的晶体管开始出现短沟道效应(short-channel effects)。如果将晶体管视作一个开关,则在开关原本应当处在关断状态时,晶体管的源极和漏极却仍然存在漏电流。
于是Intel率先从平面结构晶体管转向了FinFET,诸多foundry厂也在16/14nm节点完成了这一晶体管结构的转向。相较平面结构晶体管,晶体管上fin(鳍)的出现令其3个面都与gate(栅)有接触,实现了更好的开关控制。这种结构的晶体管一直沿用至今,如今最尖端的7/5nm工艺都还在用。
但在7nm工艺以下,静态漏电的问题越来越大,原本工艺迭代的功耗和性能红利逐渐消失。这也是近些年摩尔定律失效之说甚嚣尘上的主要原因。当代尖端工艺迭代实现的同功耗性能提升,的的确确就只有15%-20%,甚至可能还不到。
但时代发展的步伐显然是不允许摩尔定律停滞的,全社会的数字化转型、AI对算力的贪婪需求、自动驾驶技术突飞猛进,都要求半导体制造工艺持续更快速地迭代。这个时间节点之下的关键技术热点便是GAAFET(和chiplet)。
来源:Lam Research
3/2nm时代下的GAAFET晶体管
上面这段话是老生常谈,不过我们还是期望把逻辑理清楚。在上篇《展望来年的3nm之争,好像还是一边倒的局面》一文中,我们大致谈到了台积电、三星、Intel的3/2nm工艺计划。台积电N3工艺预计于今年下半年量产,明年一季度上市;三星的初代3GAE极有可能已经在内部试生产,且三星量产版3nm工艺可能跳过该节点,最终其大规模量产的3nm工艺上市时间可能会比台积电稍晚,但整体应该是差不多的;Intel 3量产时间则要等到明年下半年。
其中台积电和Intel仍将在3nm节点上使用FinFET晶体管。此前台积电就谈到过,3nm节点应用FinFET,能够降低风险,客户不需要迁移到新的晶体管类型就能开展3nm芯片的设计工作。不过如上篇所言,我们仍然有机会在台积电3nm节点上看到较大程度的改进,和晶体管密度的显著提升。
三星是唯一一个要在3nm节点就迁往GAA(gate all around)结构晶体管的foundry厂。不过台积电和Intel也将在2nm节点做相同的转向。我们期望在未来制造工艺介绍文章里,用更多的篇幅来谈GAA结构晶体管和制造工艺;只不过在三星3nm GAA正式面世之前,目前掌握的资料还并不多。
来源:Lam Research
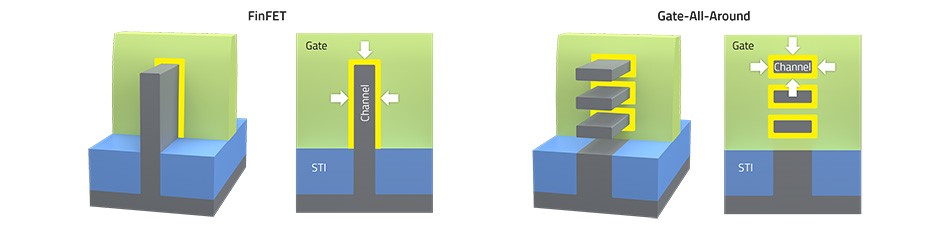
GAAFET有多种不同的称谓,比如说有人叫他nanosheet FET,Intel则称其为RibbonFET。GAA结构晶体管的本质,就是把FinFET的fin转90°,然后把多个fin横向叠起来,这些fin都穿过gate——或者说被gate完全环抱,所以叫做gate all around;另外每个翻转过的fin都像是一片薄片(sheet),它们都是channel,叫做nanosheet FET也是顺理成章的。
从结构上来看,GAAFET晶体管的gate与channel的接触面积变大了,且每一面均有接触,也就能够实现相比FinFET更好的开关控制。而且对于FinFET而言,fin的宽度是个定值;但对GAAFET而言,sheet本身的宽度与有效沟道宽度是灵活可变的。更宽的sheet自然能够达成更高的驱动电流和性能,更窄的sheet则占用更小的面积。而且对FinFET而言,fin的数量还实实在在影响到了晶体管的面积。
作为业界主流发展方向,GAAFET看起来是十分美好的。不过在3nm这个临界工艺上,GAAFET和FinFET相比,并不能带来什么实质性的性能和功耗变化。分析师预测,在该节点下,CPP(contacted poly pitch,一般可理解为栅间距)差不多都在48nm附近,metal pitch金属间距则为22nm左右。(下图提供5nm节点,晶体管各部分间距的参考)
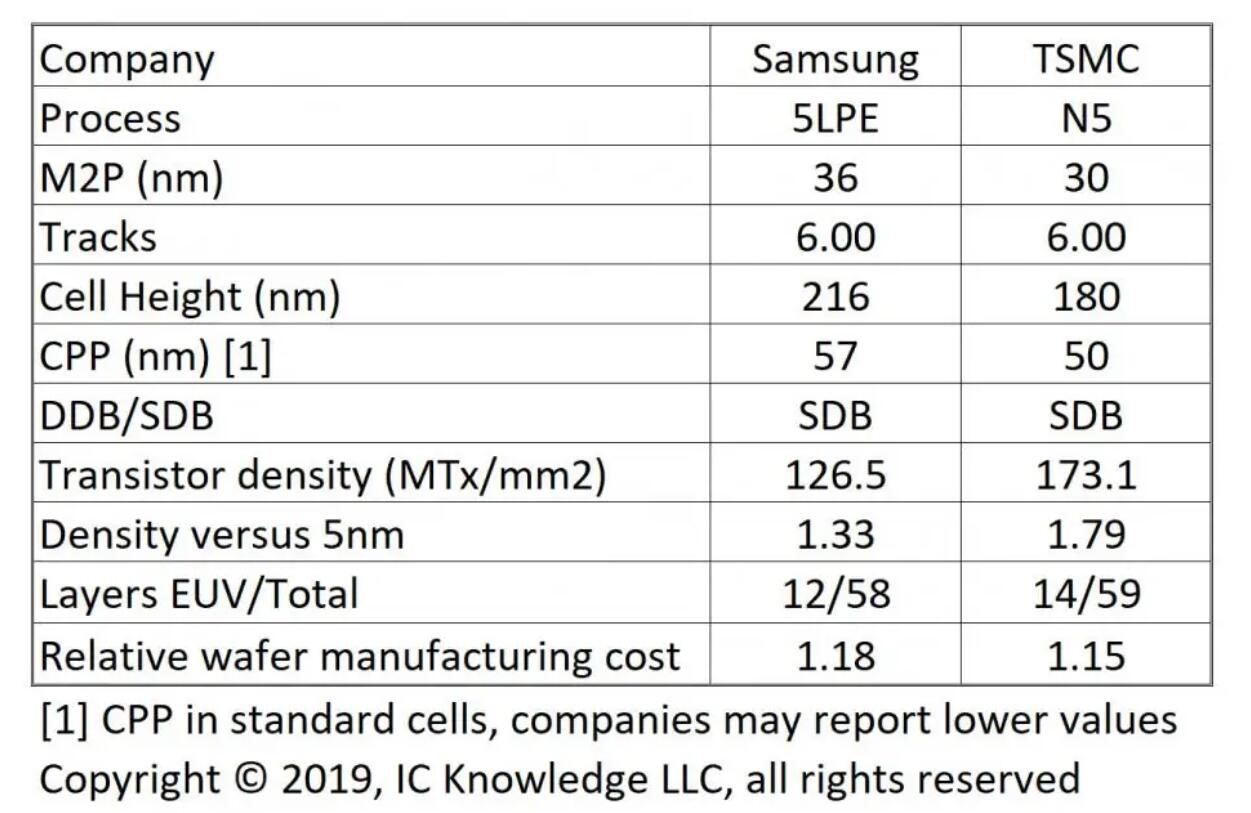
来源:Scotten Jones, IC Knowledge via SemiWiki,发布于2019.5
另外,三星作为GAAFET晶体管生产制造的马前卒,必然面临更多的技术挑战。比如说硅基沟道中较低的空穴迁移率(hole mobility),致pFET性能表现不佳。IBM在此前的IEDM上表示,这一问题的解决方法在于pFET可应用压缩应力的锗化硅(SiGe)沟道材料:“pFET锗化硅沟道能够实现40%的迁移率提升,相较硅基沟道有10%的性能优势,而且有更低的阈值电压(Vt),NBTI(负偏压温度不稳定性)表现也有提升。”
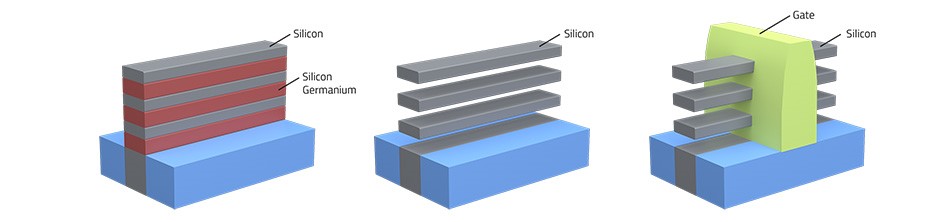
GAAFET的制造流程,首先在substrate上沉积超薄的锗化硅与硅的交替层,形成一种超晶格结构(super-lattice),每种材料叠多层。sheet就是在超晶格结构中曝光与蚀刻的。随后内部spacer隔层构成;在spacer蚀刻时,超晶格结构中,锗化硅层的表面部分凹陷,再填入介电材料。随后源极漏极形成;超晶格结构中的锗化硅层移除,留下硅基层sheet,也就是channel沟道。最后,通过沉积high-k(高介电常数)的介电与金属gate材料来构成gate。
来源:Lam Research
每一步都存在相当多的工程问题,也就要求工厂有完美的工艺流程控制策略。材料供应商Brewer Science说越小的节点,工艺控制存在的挑战就越大。在3nm节点以后,EUV微影、原子层沉积(atomic layer deposition)、检测与量测等等技术都需要持续进化。
三星GAAFET的部分已知信息
三星宣传中的GAA结构晶体管叫做MBCFET,multi-bridge channel FET。此前三星曾表示:“MBCFET技术是进入生产和量产的卓越进步。实现了出色的器件特性。我们用一颗256Mb SRAM测试芯片和一颗逻辑测试芯片,来推动3nm工艺生产的准备工作。”另外,去年年中三星和Synopsys共同宣布,应用三星3nm工艺的首颗高性能、多子系统SoC芯片流片。
在IEEE ISSCC 2021上,三星也展示了SRAM测试芯片。只不过三星在这次会上并未提供任何可比较、可参考的数据信息;会上所提的主要都是已知的一些相关GAA晶体管结构、大方向的资料。比如说channel接触面更广、四面都接触;而且因为sheet堆叠的方向和此前的fin是不同的,所以更少受制于channel宽度,在旗舰功耗和性能方面提供了更大的灵活性。这在前文及本文的上篇中都已经提到了。
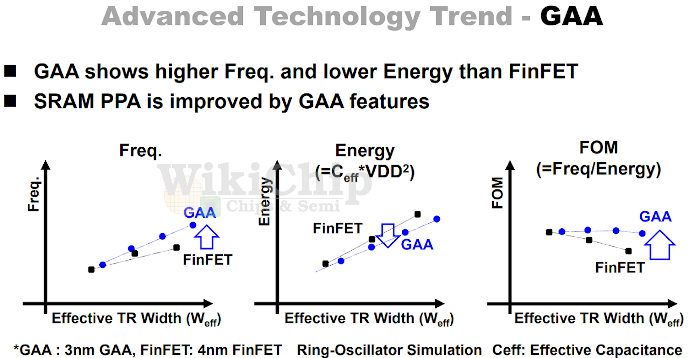
来源:三星 via Wikichip
三星在会上谈到了3nm GAA工艺,相比于4nm FinFET在频率和功耗方面的优势,具体如上图所示。不过也就真的只是如图所示了,绝对值和相对值都没有提供。大致上只能笼统地说,3nm GAA相比4nm FinFET晶体管,在相同的有效沟道宽度(Weff,fin/sheet的宽度 x fin/sheet的个数)下,3nm GAA能够达成更高的频率;与此同时达成更低的功耗。
GAA晶体管sheet这种可宽、可窄的特性,决定了在逻辑电路之外,可利用更小宽度sheet的晶体管,实现高密度SRAM存储,达成功耗和面积的降低;对于高性能SRAM的bitcell而言,则可使用更宽的sheet。从Wikichip对于三星3nm GAA的报道来看,SRAM电路是三星在ISSCC 2021上谈论的重点。
相比FinFET实现高密度SRAM设计需要用1:1:1的比例,GAA可使用1:α:α甚至1:α:β比例。这里的α应该是代表pu(pull up晶体管,也就是load transistor高电位状态晶体管)沟道宽度比值,β代表pd(pull down晶体管,也就是drive transistor低电位状态晶体管)大于pass gate(access transistor,用于bitline接入实现读写)宽度的某个比值。(* β ratio应为Wpd/Wpg,α ratio应为Wpu/Wpd)
1:α:α比值下,更宽的沟道提升了access disturb margin(访问干扰裕度);更优的比值下,disturb margin可在不影响write margin的情况下得到提升。有了更好的distrub margin表现,也就能专注于优化写入辅助(write-assist)电路。针对写入辅助电路,三星谈到一种ADBL(adaptive dual-bitline,自适应双位线)SRAM方案,写入操作时auxiliary bitline(辅助位线)与bitline并联,能够降低有效位线电阻,实现write margin的提升。读取操作时auxiliary bitline断开,所以不会影响到速度或功耗。三星展示的256Mb SRAM测试芯片应用新的辅助电路。
三星有篇paper(A 3-nm Gate-All-Around SRAM Featuring an Adaptive Dual-Bitline and an Adaptive Cell-Power Assist Circuit)是专门谈这种方案的,可搜索阅读。
台积电的灰烬版FinFET
谈了这么多,可能仍然没有很多同学最想了解的关键。毕竟3nm工艺现在还没有成品芯片问世。即便问世了,恐怕我们也很难搞清楚三星当前遭遇的主要技术挑战在哪儿。
本文的上篇已经谈到了三星3nm GAA工艺与台积电N3,预计在晶体管密度方面的变化——还算是比较直观的比较。总的来说,三星虽然在3nm节点上转向了GAAFET,在晶体管结构和密度潜力上占据优势。但预期的晶体管密度、功耗与速度提升,都和台积电N3 FinFET有着较大的差距。
只能说三星现阶段相关GAAFET的技术储备,在未来有机会发挥作用,并赶上台积电。但一方面在于早做新技术探索总是充满更多的不确定性,如前所述,foundry厂也需要解决大量GAAFET晶体管制造流程中的技术挑战。
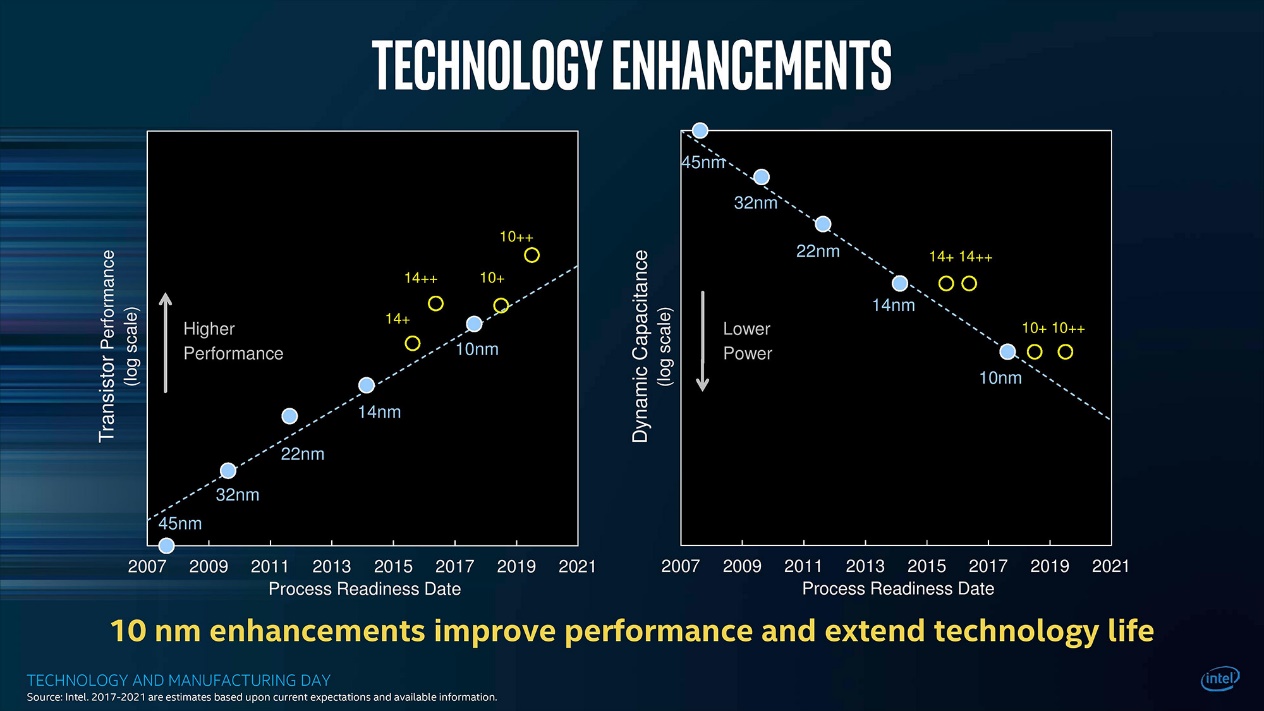
与此同时,早年Intel有公布一张节点演进图。Intel的工艺节点迭代过程里,完整工艺迭代节点的第一代(比如上图中的10nm),在性能表现上是完全有可能落后于上一代工艺的增强节点(14++)的:Intel十代酷睿的Comet Lake和Ice Lake两种芯片就证实了这一点。
所以初代GAAFET探索,在性能上落后于性能挖掘到尽头的灰烬版的FinFET,也是合情合理的。更何况通常我们都认为,三星foundry的技术实力应当不及台积电。从两者的成本投入、客户名单、芯片成品的实际表现都能看出差异。
最后再来简单谈一谈有关台积电N3工艺的已知信息,可结合本文的上篇来看:
台积电的3nm FinFET,逻辑电路密度提升1.7倍,同功耗下性能提升10-15%(可对应文首的数字),同速度下功耗降低25-30%。更具体地看,台积电N3会提供3种不同的标准单元库,HD(高密度)、HC(高电流)和HPC(高性能)。HD当然是负责推升最高密度的,HPC则以更低的密度实现最大的性能提升。1.7倍说的是HD单元库(去年更新的值似乎已改为1.6倍),而HPC的密度提升为1.56倍(这个值估计还要打折扣)——高性能单元库的晶体管密度提升幅度这次还是比较大的,比N7→N5的提升更大。
此外,台积电提供N3的数据还包括1.2倍SRAM电路晶体管密度提升,与1.1倍模拟电路密度提升。其中的SRAM密度,最近两次工艺节点的提升则相比此前可谓是非常小幅度的变化(N16→N7 4x,N7→N5, 1.35x),或者说一代比一代差。这对整个行业而言大概都不是什么好消息。
对于模拟电路部分,N5和N3算是连续两代提升,虽然每次幅度都不大,但实则在N5之前模拟电路的密度提升已经停滞了很久。1.1倍都算是比较不错的数字了。这可能很大程度表明,模拟电路的密度发展几近到头。所以我们现在总说把非关键的模拟电路,主要是I/O相关的部分,以旧工艺做成单独的die,以先进封装工艺和逻辑电路die封装到一起。这也算是异构集成、chiplet、先进封装技术必然成为时代主流的一个原因。
从更实际的角度来看,台积电此前以Arm Cortex-A72处理器核心为例给出了一些数据。台积电表示,A72应用其高密度单元库,如果是N7→N5,则该处理器核心达成1.8倍的逻辑电路密度提升,15%的性能提升(同功耗下)和20%的功耗降低(同性能下)。N5→N3,同样是A72核心,可实现1.6倍逻辑电路密度提升,27%的功耗缩减和11%的性能提升。
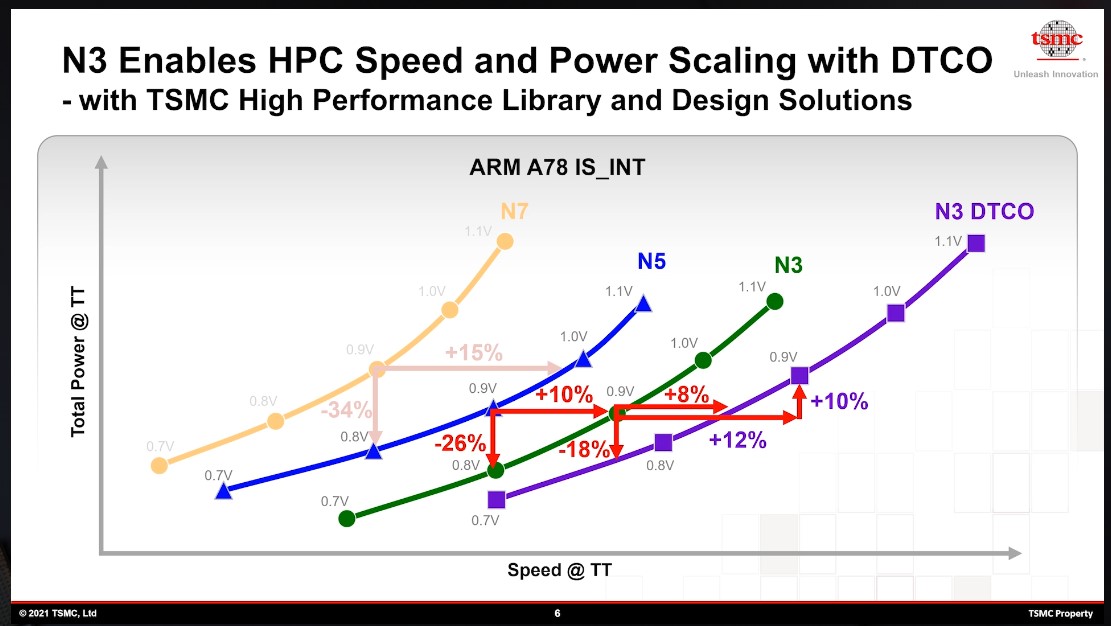
如果换成Cortex-A78 IP的话,选择高性能单元库,则N7→N5实现了15%的性能提升、34%的功耗缩减;N5→N3实现了10%性能提升、26%功耗降低。这个值是台积电去年10月公布的,早几个月公布的值是12%性能提升、32%功耗降低,2020年公布的值又不一样。不过更新过后的信息出现了更新版N3 HPC DTCO,据说有额外12%的性能提升。依据这些值的多次变动,最终量产N3的实际表现可能还会有变化。
这些数字其实也更能解释,像天玑8100这样的芯片,究竟是怎么在仍然使用旧IP的情况下,实现看起来还挺不错的性能和效率表现的。
这些数字相信对于各位读者预期来年的3nm工艺实际表现应当会有好处。这也可能将是我们能看到的最优质的FinFET晶体管工艺了,三星3nm GAA大概是无法匹敌的。虽然或许Intel 3可能会有更好的表现,那就等将来Intel公布更多信息时再做解析吧。
- 水平的GAA FET包裹沟道的金属栅极和氧化层的层积厚度不均,很难控制,Vt分散,这是纳米片水平层叠的致命缺陷。。。
