
当年iPhone 6发布会,苹果说A8芯片上有20亿晶体管,尚且让我们为人类制造精密技术慨叹和惊讶于苹果舍得堆料;转眼iPhone 13的A15芯片就已经把数字推进到150亿。
好像这些数字在真正的“大芯片”面前还是不够看。比如PC设备上的知名大芯片,有283亿晶体管的英伟达GeForce RTX 3090,发烧友们梦寐以求能玩8K游戏的大芯片。
但或许单个民用芯片的晶体管数量级还是不够大:上周Graphcore发布用于大规模AI训练和推理的Bow IPU芯片则有晶体管600亿个…是不是也还好?去年Intel发布应用于数据中心、尺寸看起来超级巨大的GPU Ponte Vecchio在宣传中说晶体管数量“超过1000亿”……
然鹅,昨天的苹果春季发布会上,最新发布的M1 Ultra芯片在民用领域就把这个数字推升到了1140亿个。要知道M1 Ultra只是一颗应用于PC的芯片。有没有感觉到苹果在堆料上的压迫感?这大概跟其他芯片公司都不处在同一竞争量级吧?
前年我们分析M1芯片的时候就提到,苹果对芯片设计的态度,与大部分芯片公司需要仔细权衡PPA(性能、功耗、面积/成本)略有不同;苹果真的是可以在某种程度上无视其中的“A”的,竞争对手直呼坑爹。
不过M1 Ultra真的有苹果吹得那么神乎其神吗?动不动就比谁谁谁有几倍性能/功耗表现的优势…本文就来谈谈这颗最新发布的苹果M1 Ultra,尤其是苹果在发布会上没告诉你的那些事。

M1 Ultra的核心已经用了2年
照例先罗列一下M1 Ultra的基本配置,虽然苹果在公开处理器数据和技术细节上一向都十分吝啬:
▪ CPU:16个Firestorm大核(192KB I-cache,128KB D-cache,48MB L2 cache),4个Icestorm小核(128KB I-cache,64KB D-cache,8MB L2 cache);
▪ GPU:64核(8192个执行单元,最多196608个并行线程);
▪ Neural Engine(AI单元):32核,22TOPS;
▪ 媒体引擎:硬件加速H.264, HEVC, ProRes, ProRes RAW;2个视频解码引擎;4个视频编码引擎;4个ProRes编解码引擎;
▪ 内存:UMA,统一内存架构,800GB/s带宽,最大容量128GB。
这颗芯片之所以叫做M1 Ultra,而不是叫M2 Big,是因为其CPU、GPU、NE单元的架构是不变的。M1、M1 Pro、M1 Max和M1 Ultra可认为是规模化扩展的关系。已经看过M1 Ultra前期报道的各位应该很清楚,两个M1 Max相加就得到了一枚M1 Ultra。感觉M1已经成为1个性能单位,随后逐层叠加堆料。
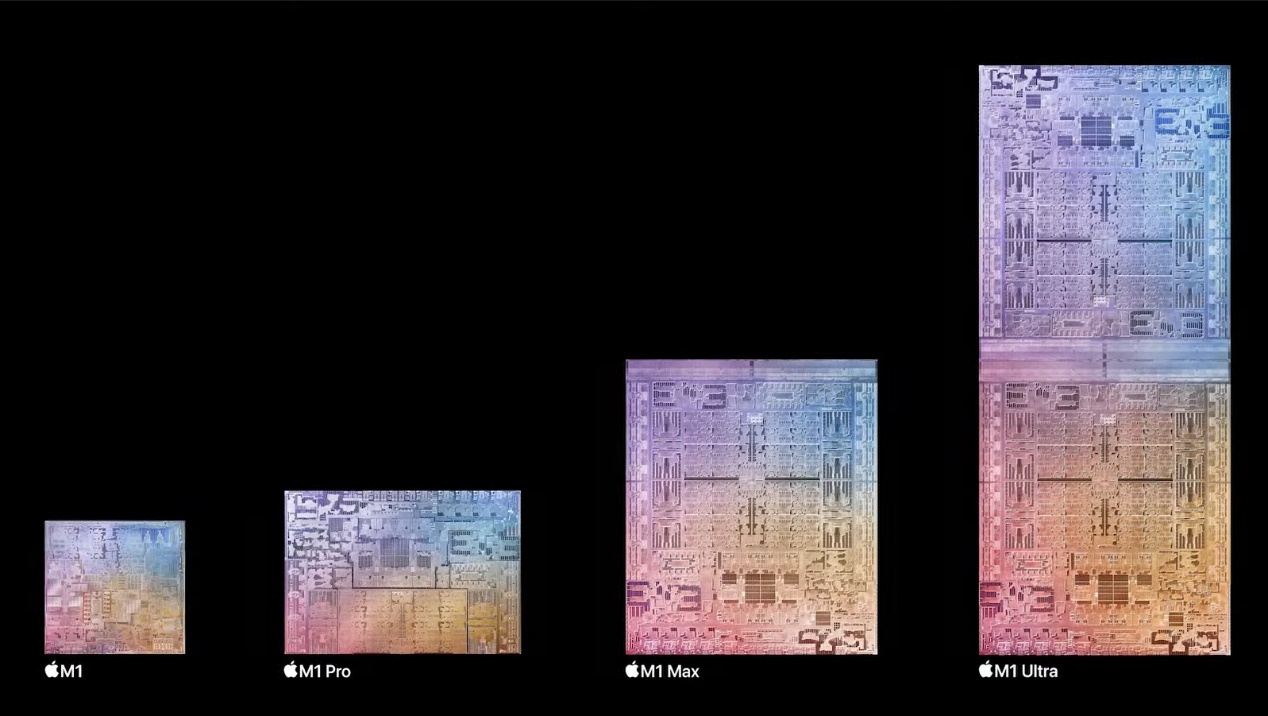
它们之间不存在迭代关系,尤其表现在M1 Ultra仍在用Firestorm/Icestorm处理器核心。核心层面,M1 Ultra与M1没什么区别(而且大概率他们的频率也不会有多大差别)。要知道这可是2020年的核心了,苹果一用就是两年。
CPU核心用2年带来的一个后果就是单核性能变得落后。M1 Ultra即便规模很大,单核性能却也就是M1相当的水平。或许2年前Firestorm大核在性能方面还堪称惊艳,但这两年Intel核心改进动作频繁,每年IPC都提10%-20%。
苹果在发布会上对单核/单线程性能只字未提,展示的数字全都是多核性能——这或许和Mac设备适配的用户人群也有关。不过类似Photoshop这样的应用,对单核性能仍然更加敏感。我们前不久针对12代酷睿的测试发现,12代酷睿大核的单核性能,比M1家族大核领先大约23%。
虽然苹果在发布会上并没有提M1 Ultra的CPU频率,不过以苹果的CPU核心超宽架构来看,他们的CPU更难以提升频率;以及在频率提升后功耗更容易崩。所以即便有提升,幅度也不会多大。则其单核性能基本就是原地踏步。
规模化扩展,带来的巨大性能收益
把M1 Max复制一份,得到一颗M1 Ultra,在PC CPU处理器及大型SoC芯片上似乎还没见过这么粗暴的方案(虽然规模化扩展对于GPU之类的处理器而言就很常见)。苹果在发布会上提到M1 Max有个秘密一直没公开,它藏了个特性,就是die-to-die interconnect技术,得以实现M1 Max两片 die相加变身M1 Ultra。
2.5D先进封装技术相关的部分后面再谈,这种方案虽然粗暴但很有效。而在“粗暴”之外,其实能看到苹果在M1芯片规划之初的长远设定,因为这种“粗暴”并不是真正的粗暴。这种规模化扩展并不是任何芯片都可以做的,存储一致性、数据同步之类的实际问题就一大堆。
于是我们就看到了苹果展示的一系列PPT。必须肯定苹果M1 Ultra在PC领域的CPU多核性能/效率、GPU性能/效率(尤其是效率上)出类拔萃的能力,毕竟堆了那么多的料。但苹果在发布会上呈现动不动几倍的数字,实在是半导体行业难以承受之重…
那就来看看性能与功耗,以及苹果在其中隐藏的一些猫腻:
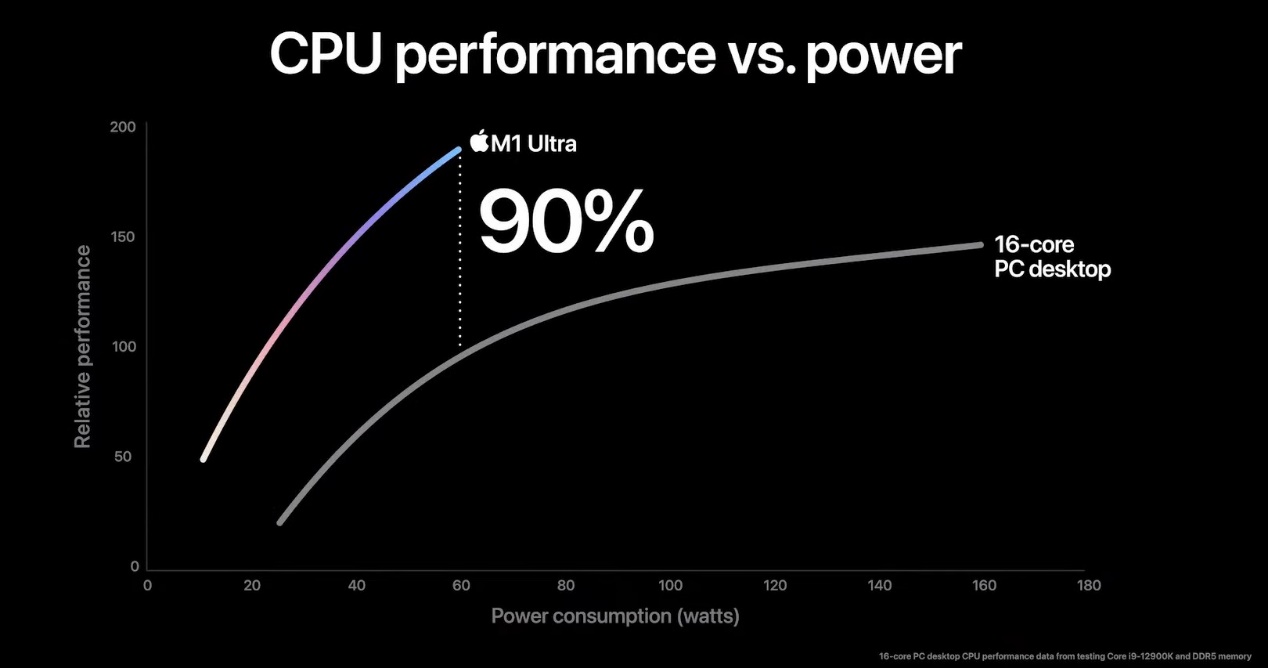
这张图对比的是苹果M1 Ultra和Intel酷睿i9-12900K。苹果表示两者相比,前者在相同功耗下能够达成最多90%的性能领先。图中可见,应该是60W这个功耗段。(只不过苹果在脚注里也完全没有提到,对比的是什么项目,而只是说“Performance measured using select industry-standard benchmarks”;这就不厚道了)
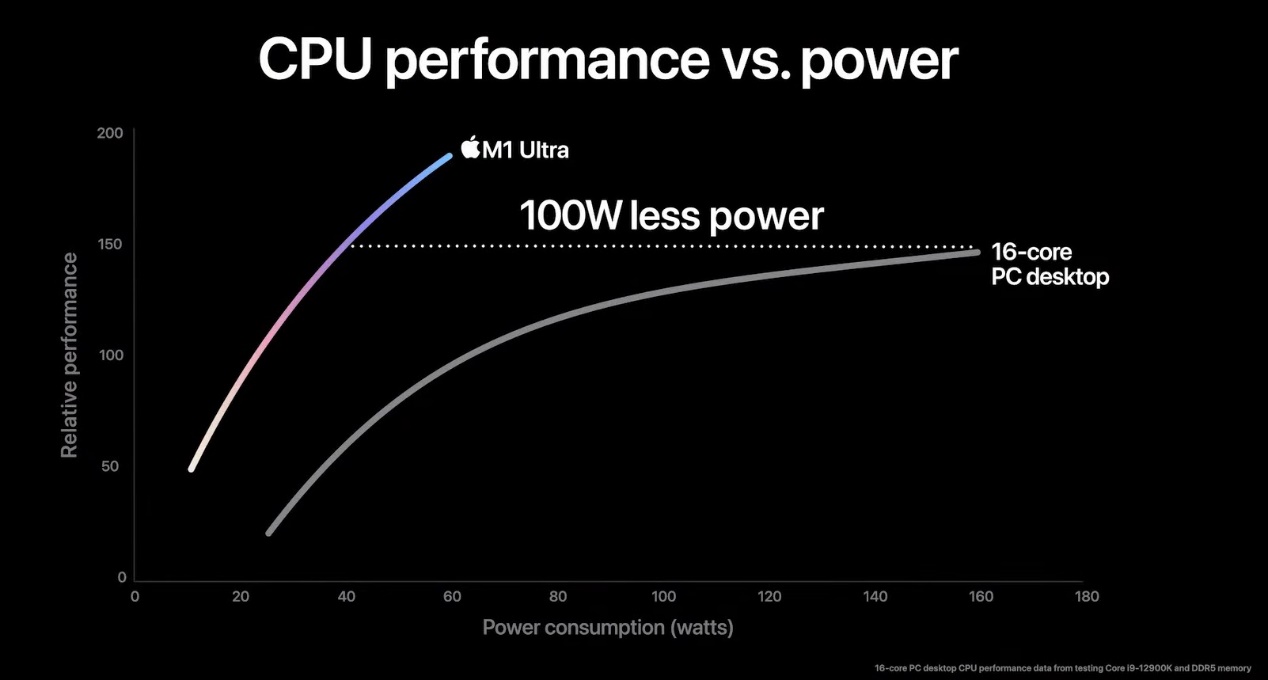
与此同时,苹果表示M1 Ultra在达到酷睿i9-12900K相同的峰值性能时,功耗低了100W。从这张图来看,是i9-12900K在160W功耗下的性能,与M1 Ultra在40W功耗下的性能相等(这不都超过了100W?)……
12代酷睿桌面版发布的时候,我们拿到过这颗芯片,不过当时没有仔细去测i9-12900K。但我们后来测了面向笔记本的 i9-12900H几个功耗段下的性能表现。至少在35W-130W功耗段的性能表现,和苹果呈现的这根曲线是不大相符的;苹果画的曲线还真是放飞自我。
另外i9-12900K的峰值性能应该在最大睿频功耗的241W,而不是图中标的180W。即便按照苹果画的这条性能/功耗曲线延伸,酷睿i9-12900K最终达到241W时的峰值性能可能也高于M1 Ultra。
不过有一点可以确认,就是M1 Ultra的能耗/效率表现非常出色,可能相较i9-12900K遥遥领先。毕竟Firestorm是架构超宽的核心、频率又低很多。另外,台积电在制造工艺上目前相比Intel也有比较大的优势。

感觉比较有趣的是,日常我们说桌面级PC对于功耗其实是不敏感的,这和笔记本、移动平台很不一样。CPU功耗飙到200W+,GPU功耗飙到300W+,问题都不大,反正也是墙插供电;耗电也比不上电暖气、电磁炉吧。
对桌面PC平台来说,功耗低带来的直观体验提升也很小,因为这种平台天然的更少受制于噪音、发热(因为用户通常离主机会比较远,大体积也抑制了风扇噪音的传播),而且也没有续航问题。不过苹果在发布会上仍一再强调M1 Ultra效率很高,还特别提到搭载M1 Ultra的Mac Studio主机相较高端桌面级PC,每年能减少1000kWh的能耗。
这才叫向绿色生活看齐啊,符合时代碳达峰、碳中和的主旋律。从苹果在M1 Ultra之上强调效率与能耗,也更能看出苹果造芯片的基因的的确确是从移动/低功耗,向桌面/高性能转变的;Intel、AMD的发展历史则决定了,他们的发展方向和起源有着很大的不同。
GPU性能据说比3090还牛?
GPU方面,苹果选择的对比对象主要是英伟达GeForce RTX 3090——个人用户GPU市场目前能买到最高端的显卡。苹果表示M1 Ultra的GPU性能不仅比3090还强,而且功耗还低200W。
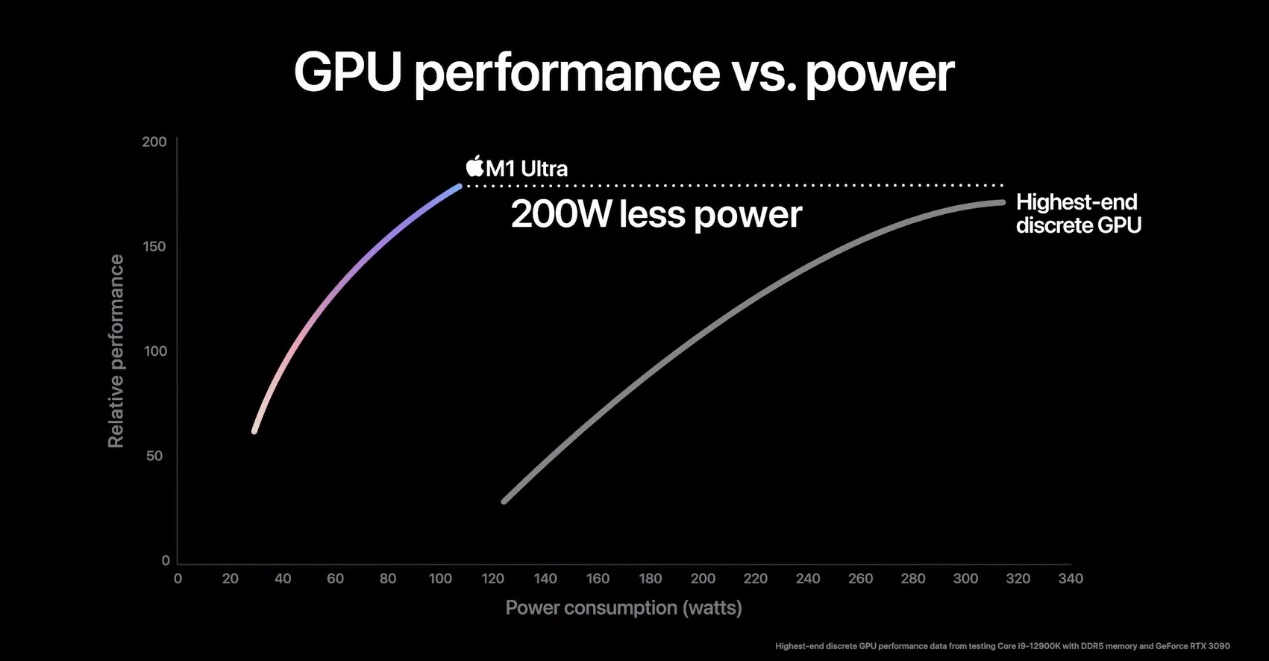
我们认为在苹果发挥出最大生态能力时,这个数字可能是合理的。一方面在于GeForce RTX 3090用的是比较陈旧的三星8nm工艺(相当于10nm工艺的小改款);M1 Ultra已经在用台积电5nm工艺。另一方面,M1 Ultra给GPU的堆料相当充足,苹果给的示意图如下:

看看这个占die面积,虽然不清楚1140亿晶体管有多少分给了GPU;但GeForce RTX 3090的计算die也不过283亿晶体管;要说规模苹果也从来没怕过谁。
另外,M1 Ultra的统一内存架构UMA实现了800GB/s的存储带宽吞吐,虽说这个数字还是比不上RTX 3090显卡搭配GDDR6X显存的936GB/s,但后者是单纯的显存带宽。而且对于GPU而言,M1 Ultra还有128GB的容量优势。
但请注意,这是最理想的情况。M1 Ultra的GPU存在两个比较大的问题:
第一,M1 Ultra是由两片die组成的,GPU位于两片die之上。也就是说M1 Ultra的GPU分成了两半。这叫MCM GPU(Multi-chip module,或者叫chiplet-based GPU),去年我们介绍过GPU发展的这一趋势。
这种GPU在民用市场上还从未出现过,数据中心唯一用了这类方案的Intel Ponte Vecchio也才刚刚开始启用。像这种需要die间通信,还得解决数据一致性问题,实现不同die计算单元充分利用,并且对开发者保持友好的设计,这时候大概也就苹果hold得住。
MCM GPU本身几乎无法实现堆料加倍,性能就加倍的目标。相信苹果宣传中提到的2.5TB/s的die间通讯带宽、800GB/s的内存带宽都是为此准备的;最终要看苹果的设计能否承载双die GPU可实现的极限性能扩展需求。所以是否如苹果所言,达到3090的性能水平,在这一点上还相当值得观察。
第二,我们不止一次撰文提过,苹果GPU的生态和英伟达有着云泥之别。或许摄影师、设计师们在某些特定软件上做做视频、3D设计,M1家族芯片的速度和性能都堪称一绝。但如果是做别的呢?且不说游戏这种苹果生态荒地:苹果在发布M1 Max的时候就说其GPU媲美移动版GeForce RTX 3080。
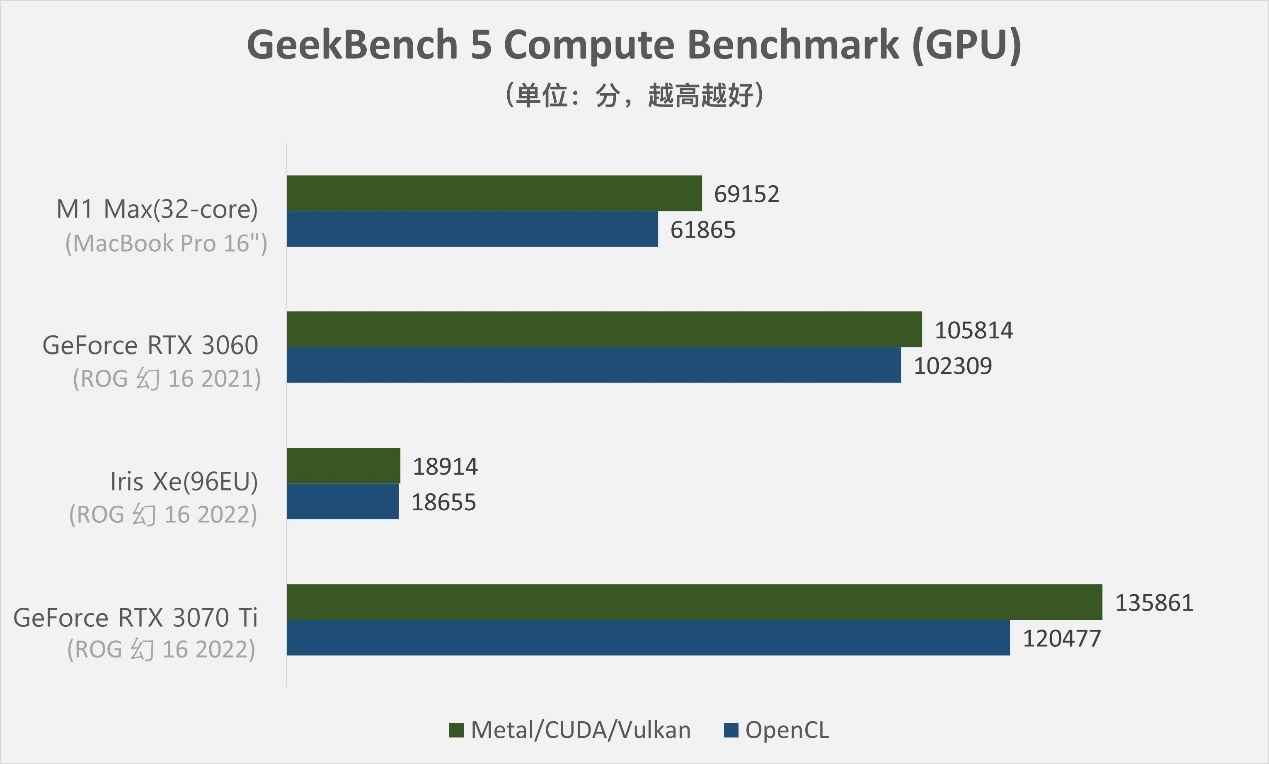
从实际测试来看,在Geekbench 5 GPU通用加速测试、Blender渲染测试这种用GPU去做加速的工作里,不要说3080,M1 Max GPU的实际表现可能连移动版3060都比不上。这是生态缺失造成的“空有一身肌肉却无处发挥”的尴尬。
另可做个极端对比:RTX 3090 GPU芯片内有专门的光线追踪硬件单元(RT core)。如果M1 Ultra的GPU真的有3090这样的硬件算力与生态支持,那么在跑那些光追应用时,它又将置身何地?说到底,双方的对比仍然不在一个水平线上。
“几倍”性能提升的那些猫腻
相较于单纯的芯片性能比较,苹果还给了不少Mac Studio的系统性能对比。这些数字看起来就比上面的惊悚多了。比如苹果说Mac Studio(M1 Ultra)CPU性能,是27寸iMac(10核酷睿i9)的3.8倍,比Mac Pro(16核至强处理器)领先90%,比Mac Pro(28核至强处理器)领先60%。

这两年苹果一开发布会,Intel从来是风评被害最严重的(早知道2005年不跟你们合作了)。也怪Intel以前不求上进。不过这系列的对比有几处猫腻应当是很多人不了解的。
第一是对比对象。上一代27寸iMac(2020),所用的“10核酷睿i9”,具体乃是第10代酷睿(而且是更老的Comet Lake架构-同属Skylake家族),距今有2年代差。这2年对酷睿处理器意味着什么,应当是关注行业的很多读者都十分清楚的。而上一代Mac Pro(2029)所用的至强处理器具体为Cascade Lake,核心本质上也属于著名老架构Skylake。
这就让这些对比数字非常传奇:用苹果最新的芯片,去比较Intel新三年旧三年缝缝补补又三年的Skylake,真的好吗?或许这些对比对Mac老用户而言有价值,毕竟他们面临设备更新的问题;但对更广阔的PC市场而言,这些数字又非常容易造成误导——总让人觉得苹果芯片早就开始用天顶星科技了。
第二是对比项目。苹果官网的脚注小字部分有说明所谓的x.x倍提升具体比的是什么。苹果官网给的综合数字是,CPU性能3.8倍的提升。对比项目乃是Houdini FX 19.0.524软件中窄带FLIP模拟场景。Houdini是个3D动画软件工具,用其中的FLIP求解器性能表现,来代表CPU的性能提升。这么“精准”的制导和对比,真的说得过去吗?
当初M1发布的时候,苹果说CPU性能提升3.5倍,选的对比项目包括Final Cut Pro中的ProRes 4K视频转码这类操作;苹果说GPU性能提升5倍,所谓的5倍,其实是Final Cut Pro里某个3D字幕功能渲染速度。
系统性能GPU对比部分,这次受伤的总算轮到AMD了。我们认为,芯片层面的性能对比,尤其GPU部分以AMD做对比对象,其实是个更明智的选择。这部分就不展开了。Mac的GPU性能提升本质上更是其macOS、metal API等生态内部的问题。
对比对象、对比项目的双重不靠谱,造就了数字上非常有效的市场宣传效果:几倍提升让摩尔定律都甘拜下风。不过我们认为,一方面在于苹果芯片本身在性能上是足够彪悍的,稍作夸大也没什么大不了。况且这本身就是乔帮主留下的传统(当年乔布斯说PowerPC G3比奔腾2要快2倍…);
另一方面,则在于Mac及苹果芯片在面向用户时,具备了更高的针对性。比如苹果很喜欢选Final Cut Pro、Lightroom、Cinema 4D这类软件来作为其性能更好的依据,还是存在一定合理性的。因为其目标用户群很大一部分就在内容创作者和设计师群体。苹果总不可能自己去和Intel、英伟达比游戏吧?

在谈M1 Ultra配置时,苹果就特地把媒体引擎拿出来说了一番——ProRes成为苹果反复在提的重点,且其占die面积也同样十分可观。这表明苹果太清楚Mac要卖给谁,M1 Ultra要为谁服务了。这对面向大众的CPU、GPU芯片厂商而言是不可想象的。
做更宽的架构、无视面积,以及加入更多专用硬件单元适配目标用户群体,这两点本质上就是苹果芯片得以鏖战PC市场的根本。这是其封闭生态特性决定的独有优势。
“胶水粘”起来的M1 Max
“胶水”一词作为对处理器的戏谑,最早似乎源于2005年Intel奔腾D处理器的“胶水双核”。当年Intel为了应对AMD的Athlon64 x2双核处理器,很仓促地推出了奔腾D——尤其2006年代号为Presler的奔腾D,是真正的MCM:同一个基板封装上有2个die,一个die一个核心。有没有感觉格外新潮?

当年的奔腾D“胶水双核”
奔腾D的双核之间的通信需要依靠FSB前端总线和主板上的北桥,也就是去芯片外面绕了一大圈,通讯效率格外低下。感觉就像是把两颗奔腾4用胶水粘在一起一样,所以被人戏称为胶水双核。
时代在变,从“复制粘贴”这种方式来看,有没有感觉苹果M1 Ultra还挺像当年胶水双核风范的?只不过这次复制粘贴的是一整个SoC…当然如前文所述,称其为胶水只是开玩笑,苹果在设计M1 Max之初就留了一手, 即die-to-die interconnect。按照苹果标称的双倍性能提升,必然是要在两颗die协作方面做很多工作的;我们认为苹果对M1的早期定义和规划应该就已经做得比较出色。
苹果说将两颗die连起来,用的是“创新的、定制打造的封装架构”,并且将这种多die架构称作UltraFusion。苹果在发布会上明确提到了UltraFusion是用Silicon Interposer互联。那么猜测应该就是台积电的CoWoS技术了吧。
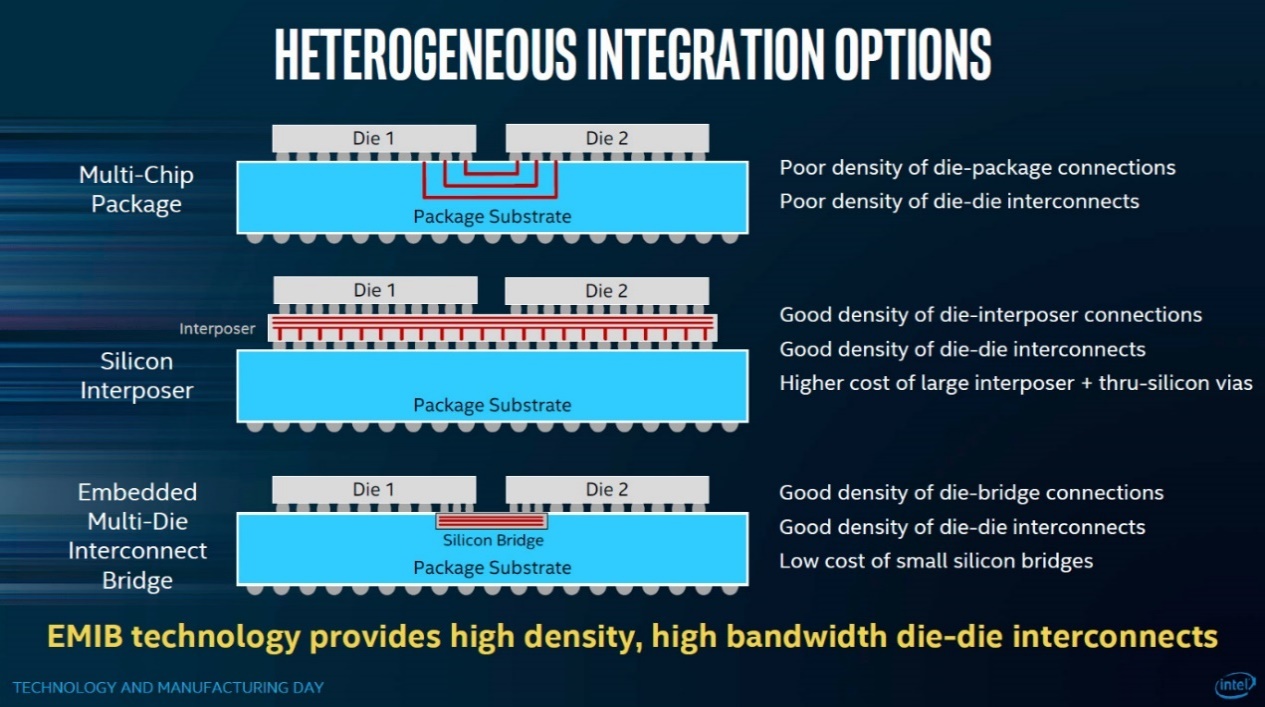
我们以前也介绍过CoWoS。如上图中间的这个方案,是将不同的die放在硅中介上,这个硅中介内部可实现die之间的互联(RDL,redistribution layers)。但从苹果的互联示意图来看,反倒更像是Silicon Bridge(硅桥)方案(下图),也就是上图中的第3个。Intel EMIB是Silicon Bridge技术中的代表。当然,或许苹果也只是形象地做个易于理解的表达罢了:


基于chiplet——也就是这种多die“拼”到一起的方案,在半导体行业并不罕见。尤其这么大的芯片,要是做成整片monolithic,良率会让苹果这种土豪都吃不消。所以把大die切成小die,再封装到一起才是行业趋势。
AMD的CPU处理器这两年也普遍基于chiplet来堆核——但AMD民用处理器的多die互联封装比较低端;而且AMD也不是像苹果这样直接做SoC的复制粘贴。硅中介、硅桥这类方案在大芯片上正在普及,但消费级处理器上还比较罕见。Intel好像到现在都没有做chiplet式酷睿处理器的打算。
苹果在发布会上还特别强调了UltraFusion相比于行业内任何其他同类方案都要领先,而且相比任何现有技术都有着2倍的互联密度:表现在连接超过10000个信号点,达成两颗die之间2.5TB/s的低延迟、互联带宽,而且功耗很低——“相比主流多chip互联技术提供超过4倍带宽”。
通过这样的复制粘贴,M1 Ultra达成了相比M1 Max各方面的两倍。晶体管数量是2倍,AI算力是2倍,同时支持的8K ProRes视频流数量是2倍,价格是2倍(Mac Studio),支持的内存带宽是2倍,CPU/GPU核心数量是2倍……

内存带宽的800GB/s算得一大亮点——很多同学可能对这个值没有量级概念。12代酷睿处理器L3 cache读写速度都还没有这么高(当然延迟应该不在一个量级);至于内存,至强平台把8通道的内存条全部插满,也就200GB/s的带宽;普通PC平台双通道内存带宽不到80GB/s。
其实M1 Max的400GB/s已经足够让人咋舌。感觉对CPU来说,已经消受不起这么高的带宽;800GB/s更像是为GPU准备的,前文已提到800GB/s与顶配GPU显存带宽接近。说到这儿,前文的GPU部分已经提到了M1 Ultra的MCM GPU方案在行业内是走在前列、十分大胆的。但把GPU切开去用的效果,仍然要看实际表现;毕竟我们也不知道苹果针对这部分具体是怎么做的。
MCM GPU,乃至其他相同模块的简单复制其实在性能上都很难做到1+1=2。而且苹果还特别谈到,M1 Ultra对开发者来说不需要改动代码,这对苹果更是考验。或许行业变革的开端也从这里被打开,即便苹果生态又有着巨大的特殊性。

最后稍做个总结。苹果在本次发布会上提到了板级的双芯方案,就像上图这样——通过主板来互联通信。苹果吐槽这种方案增加延迟、带宽受限,而且功耗很高,与此同时对开发者而言构成了更大的负担。不知道这是不是在吐槽服务器平台。
此前我们写iPhone芯片前传时提到,苹果早在1986年想要自己做处理器名为Scorpius。这颗芯片在设计上就有可扩展的多芯系统,包括互联通信,在当时十分新潮。只不过苹果那会儿没有能力把这样的芯片设计出来。
随着封装工艺的进步,先进封装成为摩尔定律延续的重要组成部分,连silicon interposer本身都在不断突破reticle limit,2.5D/3D封装还在进行着互联密度的军备竞赛。既然晶体管层面的制造工艺进步放缓,先进封装成为芯片设计和制造的未来也成为趋势。
现在的苹果有能力在民用芯片市场率先走出这一步——步子走得比AMD明显更大;与此同时还在AMD、英伟达这类企业研究了那么多年的MCM GPU议题上第一个做出迈进。虽然苹果对于M1 Ultra的市场宣传实在是很浮夸,但这也不妨碍它切实地给行业添了浓墨重彩的一笔。
- 膜拜下洋葱老师

