
今年年初Graphcore在媒体分享会上就预告了很快要发布新的IPU硬件,AI芯片、计算刀片和系统。这款名为Bow的IPU芯片,据说是全球首款基于台积电3D Wafer-on-Wafer的处理器;在整个芯片构成上,叠了2片die——像IPU这类大芯片,采用2.5D/3D封装工艺在行业内本身也是大趋势。
Graphcore表示,Bow IPU在系统层面上的性能至多提升40%,电源效率提升16%;与此同时软件和系统实现了向前兼容,“开箱即用”“不需要修改代码”。


Bow IPU:3D WoW带来的提升
有关IPU芯片本身大方向的架构,建议不了解的读者去看一看此前我们对于上一代Colossus MK2 IPU的解读。IPU是较早且在近存计算上颇具代表性的一类兼具可编程性的AI芯片。这次迭代的Bow IPU应当属于上一代的改款,在计算、存储架构方面都没有什么大的变化。
Graphcore大中华区总裁兼全球首席营收官卢涛说,Bow这个名字源自伦敦的地名,未来的IPU也会沿用这样的命名方式。在卢涛接受采访时,他仍将Bow IPU的计算die称作“Colossus die”,大概也可以说明这代产品属于前代产品的一次优化型改款。
对于Bow,Graphcore给出的一些数据包括:单个封装中超过600亿个晶体管;350 TeraFLOPS AI算力(FP16);0.9GB片内存储-带宽65TB/s,1472个独立处理器内核(IPU tiles),8832个独立线程;3D硅晶圆堆叠,优化的硅供电;10 x IPU-Links支持,可达成320GB/s芯片到芯片的传输带宽;制造工艺仍是台积电7nm。

这些关键参数相较于上代IPU,在内核、线程数量、片内SRAM容量、外围I/O方面相比于上代产品是没什么变化的。不过片内存储达成的带宽从过去的47.5TB/s提升到了65TB/s——具体如何实现提升的未知,可能是频率提升带来的;理论AI算力也从250 TeraFLOPS提升到了350 TeraFLOPS。
尤为值得一提的是“3D Wafer-on-Wafer”工艺,卢涛说Bow IPU是全球第一款基于台积电3D WoW的处理器。我们在此前的文章中具体谈过台积电把die叠起来的SoIC技术,WoW就是其中之一。SoIC的特点在于Cu-Cu hybrid bonding混合键合,实现更小的键合间距。应用SoIC技术的芯片有个特点,其设计弹性不像普通micro-bump方案那么高,需要芯片设计从头做配合。
不过从介绍来看,Bow IPU的堆叠并不算特别复杂。如前文所述主要负责计算、存储的IPU die位于下层——也就是卢涛所说的Colossus die,“这是个大小die的设计,大die是计算die,小die主要做电源、能耗等方面相关的一些管理”,而且它能“提高跨Colossus die的电源功率传输,优化Colossus die的操作节点,转化为有效的时钟加速。”
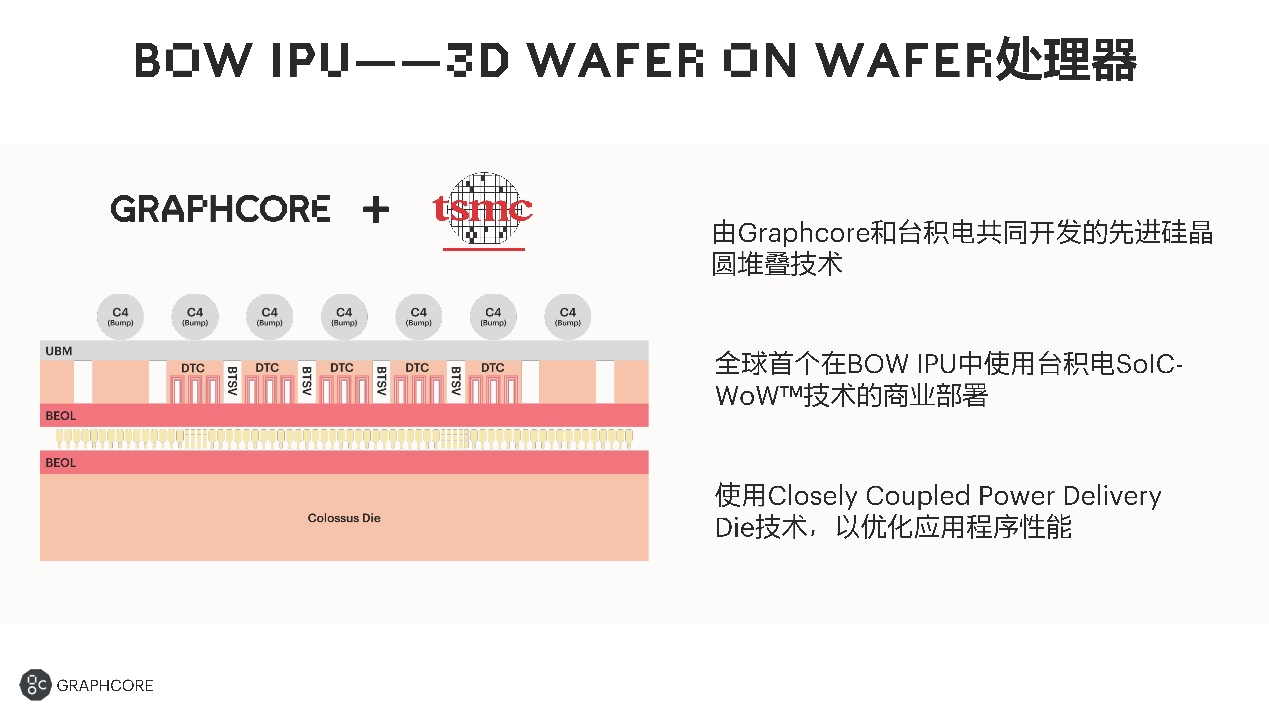
Graphcore官方给出的这张图信息量比较少,这里的几个主要关键词包括DTC(Deep Trench Capacitor)、BTSV(backside through silicon via)(另,UBM应该是指under bump metallization)。台积电这两年倒是在推一种名为iCAP(Integrated Capacitor)的DTC,能够实现显著更高的电容密度(虽然这项技术好像主要应用在CoWoS上)。以我们对Graphcore官网blog更新节奏的日常了解,预计很快还能看到相关这方面更多的技术细节。
Graphcore中国工程副总裁、AI算法科学家金琛告诉我们,Bow的性能提升“基本上是由于Wafer-on-Wafer技术,以及新的DTC晶圆带来的电源管理上的提升,包括功耗等都是跟电源管理直接相关的。这些都直接影响到芯片的性能。”或许效率的提升令原有计算单元可获得更高的频率余量,也就能够达成性能的提升,顺带在效率上仍保有优势。
系统性能最高提升40%
Bow IPU构成1个1U的计算刀片,构成方式是类似的。1U刀片(也就是一台Bow-2000 IPU Machine)内同样用了4颗Bow IPU芯片,理论算力从上一代的1 PetaFLOPS提升到1.4 PetaFLOPS。其他配置包括3.6GB的片内存储,260TB/s的带宽;以及256GB流存储DRAM,2.8 Tbps IPU-Fabric。


那么再往系统层级的规模化扩展方向去,就对应的有了BOW Pod16、Bow Pod32、Bow Pod64、Bow Pod256和Bow Pod1024。具体规格如上图所示,比如搭配1个CPU服务器的Bow Pod16,共4台1U Bow-2000,总共5.6 PetaFLOPS算力;到最大规模的256台1U Bow-2000 358.4PetaFLOPS算力。
不过Bow Pod1024尚为“早期访问版本”,其他规模的系统均“已经量产”。
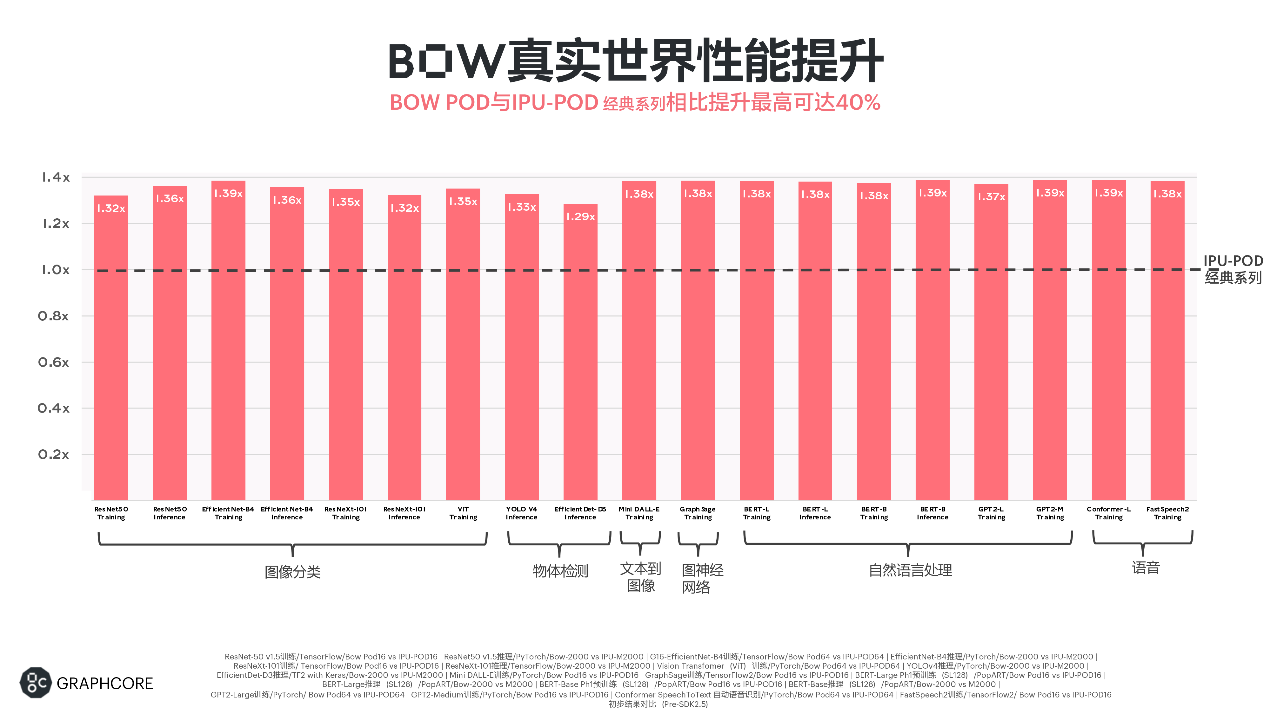
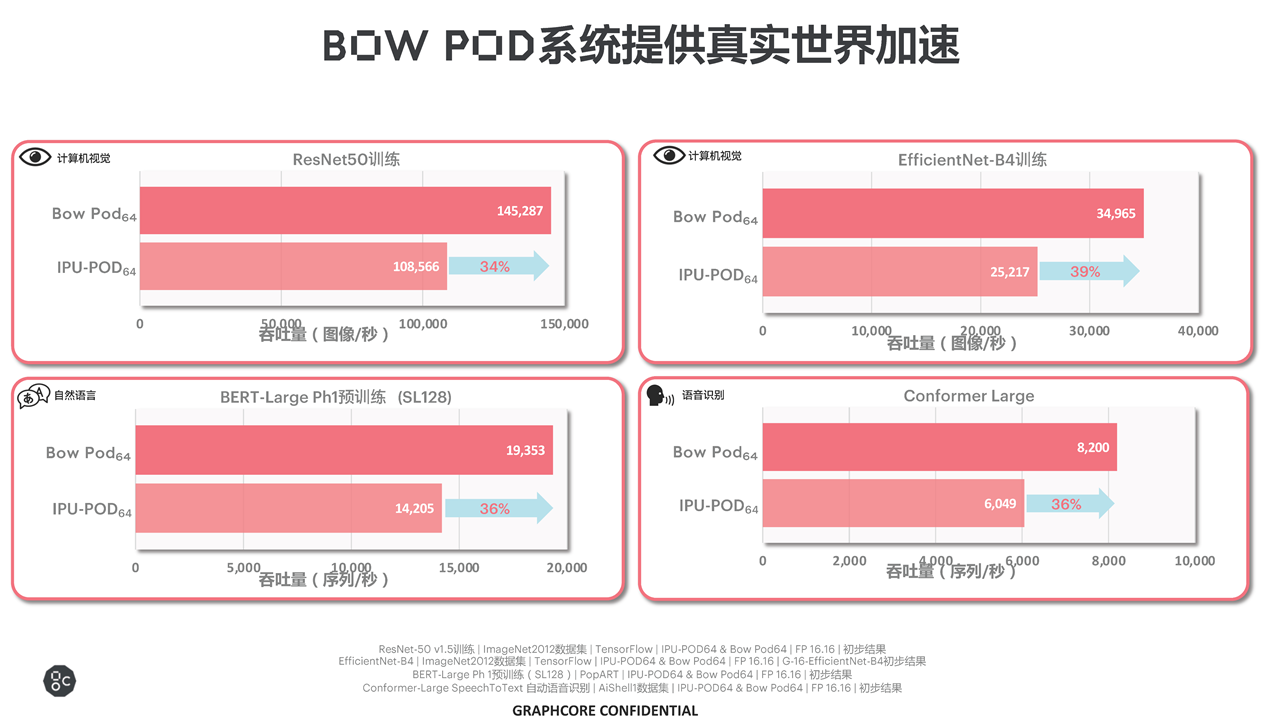
上面这两张图比较了Bow Pod和上一代的IPU-POD,不同网络的training与inference性能表现——包括计算机视觉、自然语言、语音识别的实际吞吐表现。
金琛表示在“不同的AI垂直领域,每个应用基本都得到了30-40%的性能提升”。以上列出的除了CNN网络,还包括“最近比较热门的Vision Transformer网络”;其中“EfficientNet-B4基本可以达到39%”的性能提升,“接近理论上限值”;自然语言处理、语音识别、文本转语音等模型上的性能提升看起来也比较一致。
第一张图中的对比,选择的系统规模是有差异的,比如其中达到39%提升幅度的EffcientNet-B4模型训练,对比的是Bow Pod64与IPU-POD64;其他还有一些对比选择的主要是Bow Pod16。不过从Graphcore提供的数据来看,Bow IPU规模化扩展达成的性能提升也保持了相对比较好的线性度和较低的性能折损,这也一直是IPU系统的传统:
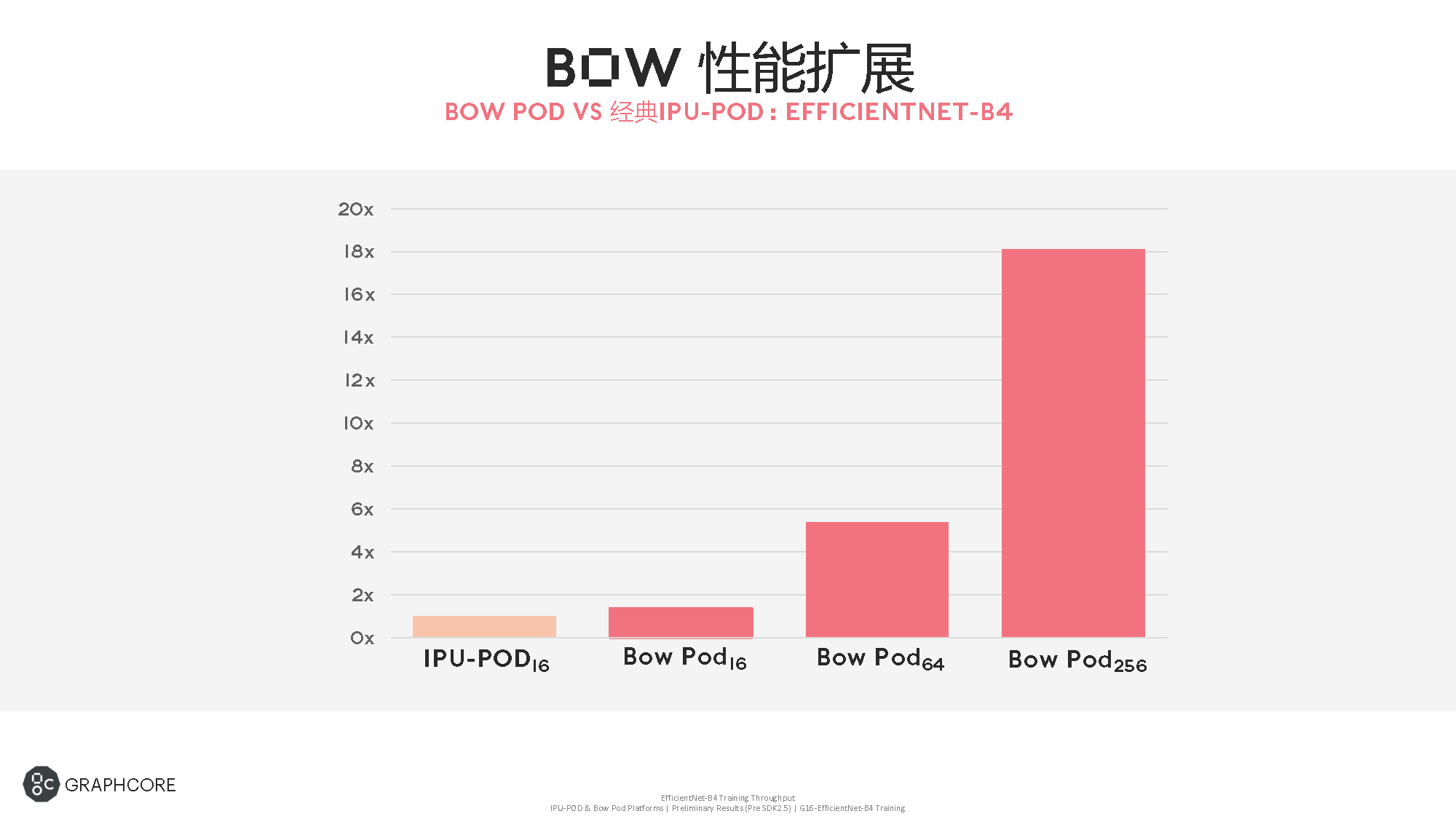
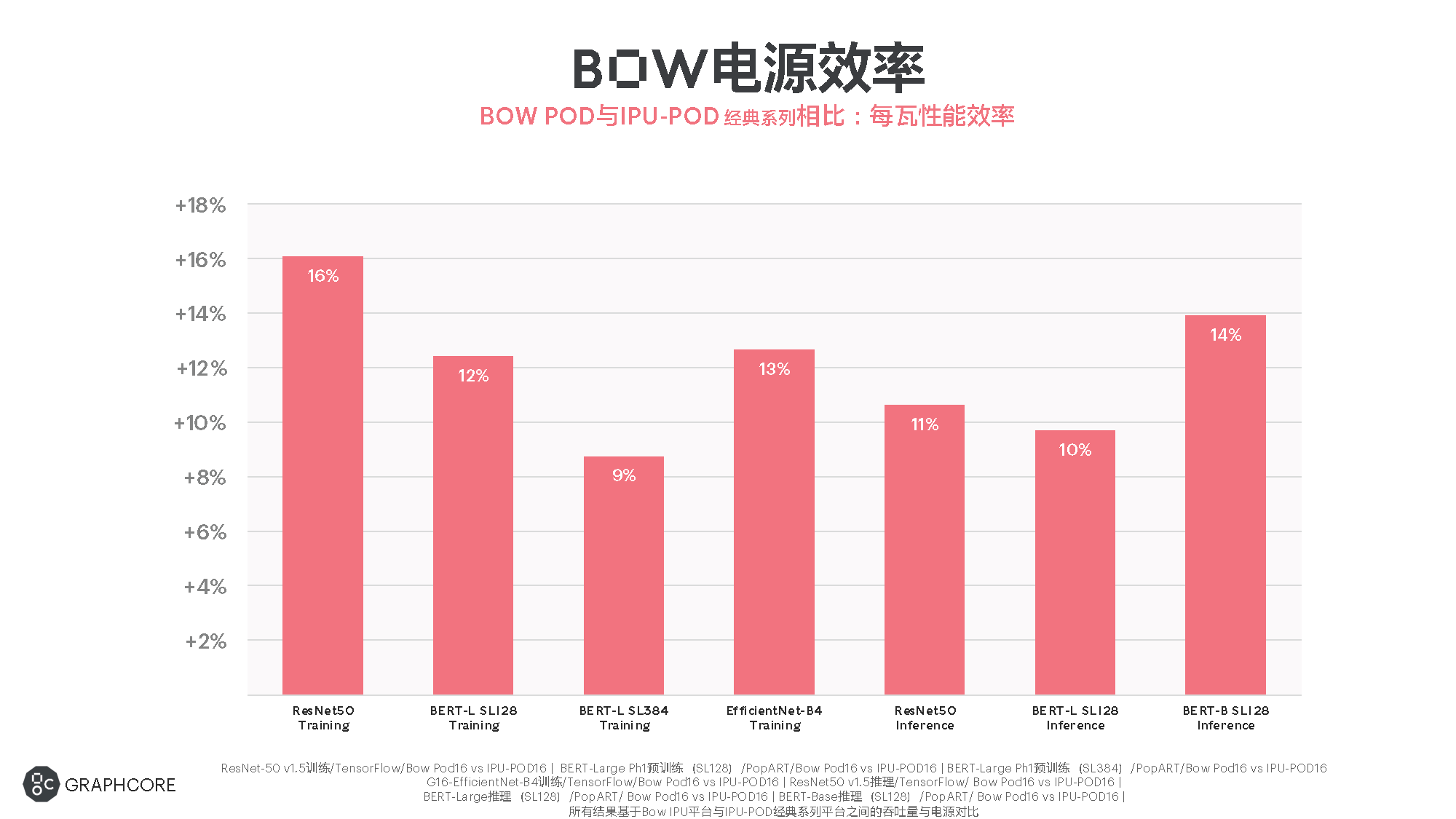
性能之外的效率方面,Graphcore也给出了Bow Pod(主要是Pod16)跑某些模型时相较上一代IPU-Pod的每瓦性能提升。最高提升为ResNet-50 v1.5(TensorFlow/Bow Pod16 vs IPU-Pod16)的training,每瓦性能比旧系统高出16%,如上图所示。
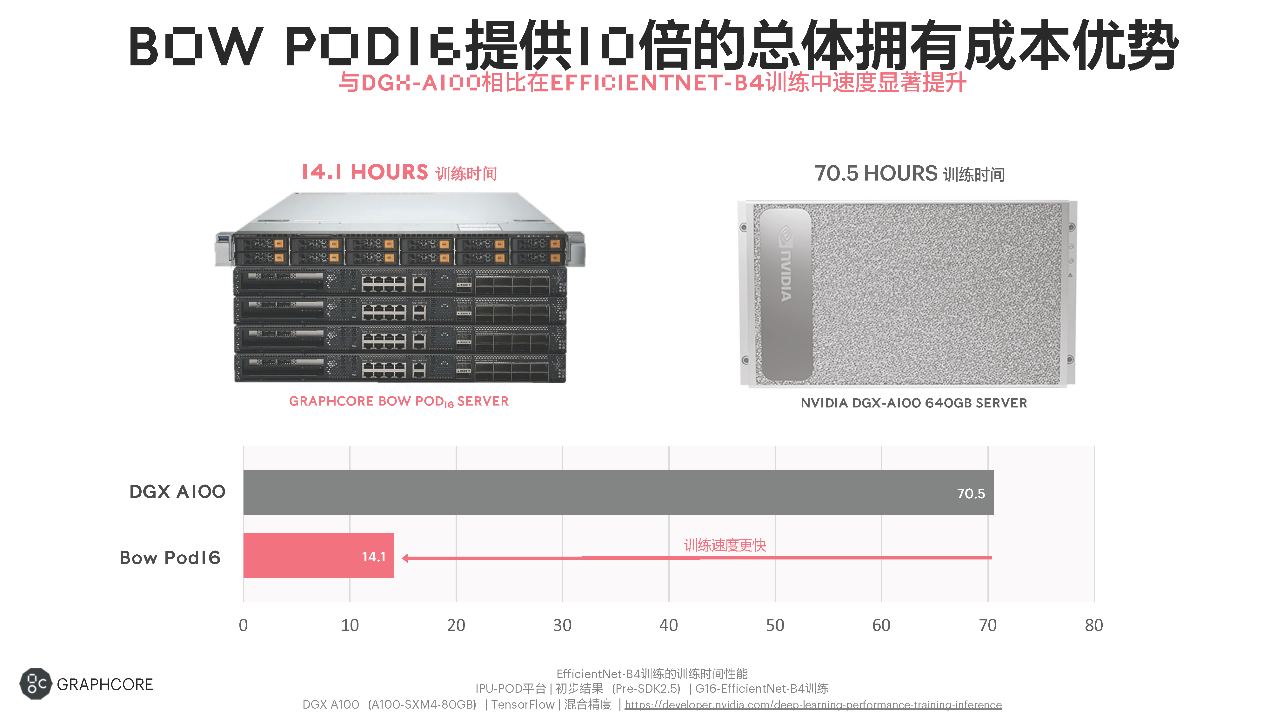
最后是对比的保留项,就是与英伟达GPU去比TCO总拥有成本。虽说这里对比训练时间的模型必然是对Graphcore IPU更有优势的(EffcientNet-B4训练),但这对特定市场的客户而言是有实实在在的价值的。基于这一数据,卢涛表示:Bow Pod16服务器相较英伟达DGX-A100 64GB服务器,“TCO增益可以达到接近10倍左右”。
不过还是要注意,这里的40%、16%和10倍三个最重要的数字实际都是取最优值的结果;包括系统规模、网络模型及配套软件生态最优状态下所能达成的性能、效率与性价比优势。
另外值得一提的是,Bow IPU及对应系统与上一代实现了“百分之百的软件兼容”,“开箱即用,不需要修改代码”,“不仅是应用软件,包括底层的软件、驱动等都不需要做任何修改,就能无缝集成到正在不断变化、更加广泛的IPU软件合作伙伴生态中”。
卢涛表示:“如果一位用户已经在使用我们上一代的IPU,他在未来购置新的Bow IPU后,实际上是不需要做任何软件适配工作就能获得性能提升的。”以及另一个重点:“价格不变”,属于加量不加价。
展望中的Good Computer
有关IPU的软件生态及具体应用,此处就不再列举了,年初的报道中我们已经比较详细地谈到了IPU当前的开发生态发展情况,及一些实际的IPU应用和合作。基于Bow的向前兼容,对应生态的工具和软件应当也不会有什么变化。
除了Bow IPU的发布以外,Graphcore这次还特别谈到了“通往超级智能AI的路线图”。“Graphcore正在开发一款可以超越人脑处理能力的超级智能计算机。”卢涛说,“目前最大的人工智能模型的参数和真正的人脑比起来,可能还有100倍左右的差距。”

Graphcore准备推出的Good Computer(中文古德计算机,这里的Good是指计算机科学家Jack Good)以8192个IPU(未来的IPU),提供超过10 ExaFLOPS的AI算力,“也许会继续往3D Wafer-on-Wafer演进,可以实现4PB的存储,助力超过500万亿参数规模的人工智能模型的开发,我们的Poplar SDK完全支持。”
或许在Good Computer正式问世以前,IPU还需多次迭代,以实现效率的进一步优化。而这次发布的Bow显然是通往这条路上的一步。
