
最新一回合的MLPref人工智能(AI)训练性能测试基准跑分结果出炉,微软(Microsoft) Azure利用大规模的Nvidia驱动实例,展现了世界速度最快的AI云端系统。Azure的NDm A110 v4系列虚拟机以2,048颗Nvidia A100-80GB绘图处理器(GPU)进行跑分,每一项测试都是在18分钟之内完成。
在8项不同工作负载的封闭赛程(closed division)性能测试中,Nvidia以内含高达4,320颗A100加速器的系统,拔得其中7项测试的头筹。微软Azure则于第八项测试(医疗图像)取得领先地位。AI芯片新秀Graphcore与Habana Labs也在ResNet-50和BERT两项性能测试上取得了进步的成果。
微软Azure
微软Azure的MLPref跑分结果在全球前100大超级计算机中排名第十。Nvidia内部的AI超级计算机Selene,规模是前者的两倍,目前排名世界第六。

Azure的NDm A110 v4系列虚拟机,依需求可从1台扩充到256台,或者说从8颗GPU扩充至2,048颗。在Azure云端就利用了2,048颗GPU,展现了在仅超过25秒多一点点的时间内,就能完成整个BERT自然语言处理模型训练的能力。而最困难的MiniGo性能测试基准,Azure以1,792颗GPU、在低于17.5分钟的时间内完成训练。
此外Azure在3D医疗图像的3D Unet性能测试基准项目上取得第一,利用768颗GPU,以1.262分钟完成训练(Nvidia采用768颗GPU的系统在3D Unet项目跑分结果是1.373分钟)。而微软的目标之一,就是展示Azure云端性能可以与现场部署设备媲美。
Nvidia
Nividia参与测试的系统则是为了展现执行大规模AI训练的能力。“扩充至更大的丛集实际上是AI训练时最困难的部分,而Nvidia的AI平台在这方面拥有庞大的优势;”Nvidia加速运算产品管理资深总监Paresh Kharya表示:“扩充性真的很重要,因为所有事情都会成为瓶颈,这是很困难的问题,从分配、协调工作到数据的移动,每件事都会成为瓶颈。”
Kharya表示,就算是Selene系统,进行庞大、最先进模型的训练可能也会需要花费几个月的时间,而不具备扩充性,就无法让最新AI模型有所进展。规模也很重要;他指出,AI项目的快速进化能力是关键,“我们常见的一个错误认知是,只利用训练模型的基础建设成本来考虑(投资报酬率);但使用者不只该关心基础建设成本,也要注意他们昂贵的数据科学团队生产力,以及最终的产品上市/更新时间是否能比竞争对手更快。”
Selene以4,320颗GPU进行性能测试基准跑分,是这一回合测试中规模最大的系统。Nvidia表示,与Graphcore最快的系统(采用256个加速器)相较,其跑分结果在速度上快了30倍,而比起Habana Labs的最大系统(同样采用256个加速器),Nvidia系统则是快了53倍。
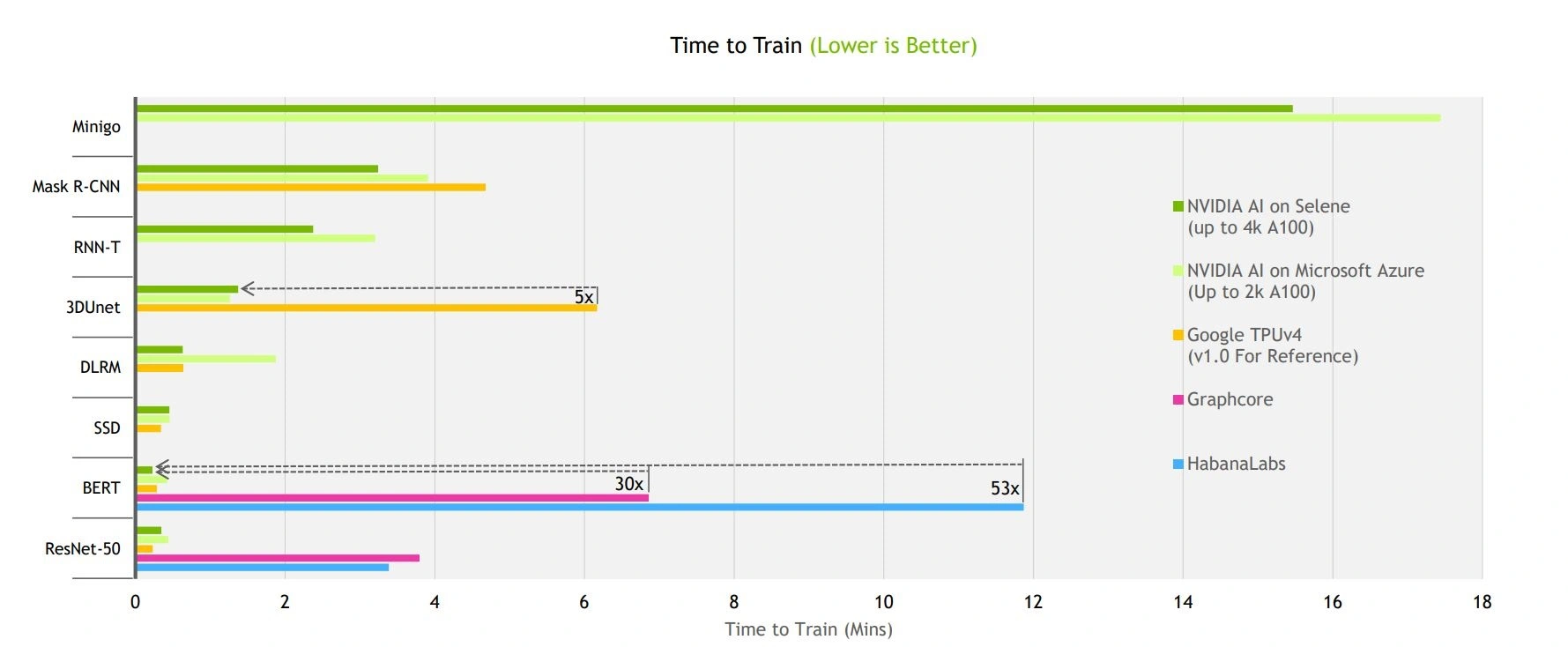
所有项目的AI训练性能基准检验跑分结果,时间越短表现越好。这里的跑分结果比较了配备不同数量加速器的系统,其中Google TPU v4的跑分结果来自于前一回合MLPref的测试。
(数据源:Nvidia)
在个别加速器芯片的效能上,Nvidia则宣称它胜过了Graphcore和Habana Labs的加速器;不过仍落后Google TPU v4在前一回合性能测试中的ResNet-50训练模型跑分。而Nvidia强调,自2020年7月(A100问世时)以来,其MLPref训练跑分的表现稳定进步,以Nvidia A100为基础的系统性能表现整体快了五倍,在芯片层级则快了两倍。
其性能的提升得益于软件上的变化,包括透过同步而非连续地启动整个核心序列的CUDA绘图技术减少CPU的瓶颈,因此整个训练演进都直接在GPU上执行。CUDA串流透过导入一个微调过的运算与通信的重迭,来改善其平行性。
此外Nvidia的NCCL和 SHARP技术被用来改善多GPU和多节点的处理作业。NCCL利用现有的带宽和网络等待时间来优化数据聚合;SHARP则透过将CPU的运作分摊至交换器,来免除不同端点和服务器间多次传送数据的需要。同时,更新版的MX网络配置,改善了串接(concatenation)和区分(split)等运作的所需的内存复制效率。
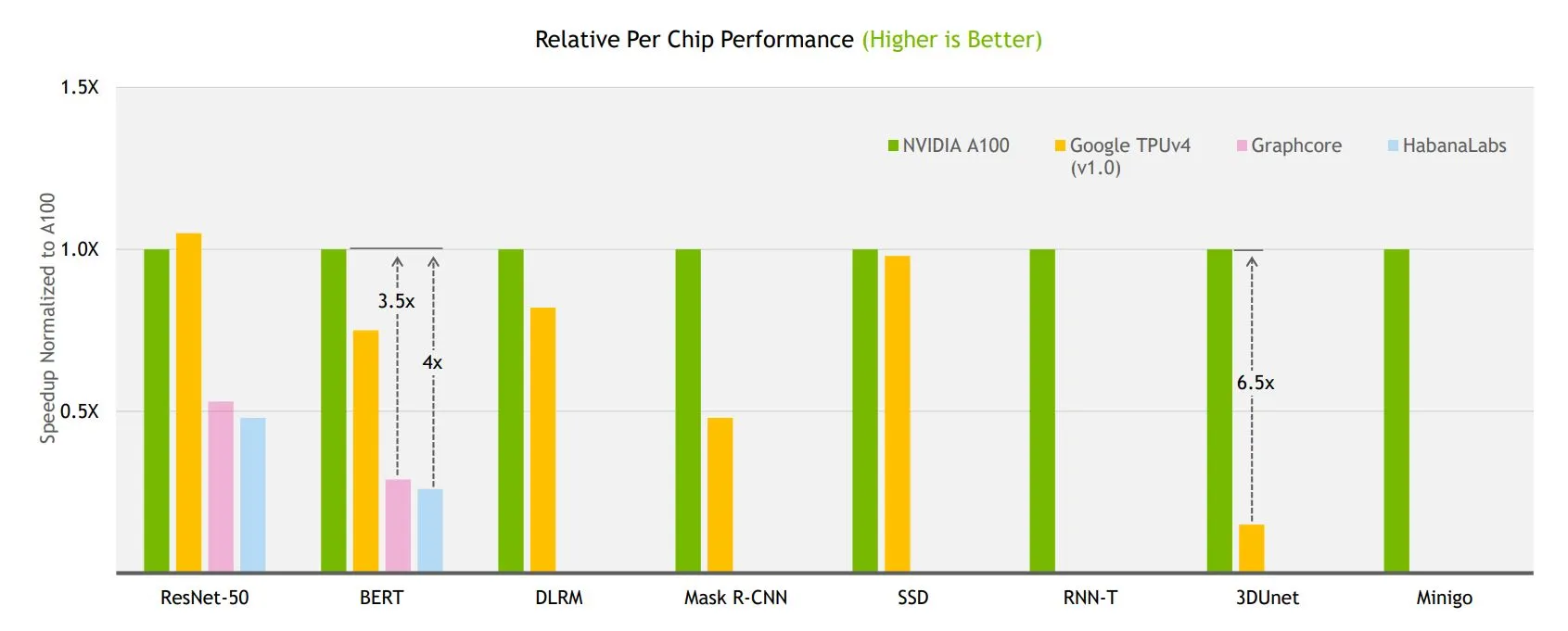
以Nvidia的A100作为基准之性能正规化(normalized)至每个加速器芯片的结果;数字越高表现越好。其中Google TPU v4的跑分结果也是来自前一回合的MLPref测试。
(数据源:Nvidia)
Graphcore
Graphcore则展示了较大系统的可扩充性,包含那些具备128和256颗IPU加速器的系统。在16和64颗加速器的系统方面,Graphcore的IPU-POd16在ResNet-50模型的跑分进步了24% ,IPU-Pod64则进步了41%。BERT模型部分,IPU-Pod16的跑分进步了5%,IPU-Pod64跑分进步了12%;这再次说明,软件优化助力了性能提升。
Graphcore将IPU-Pod16的性能基准检验跑分结果与Nvidia的DGX-A100进行比较,就算前者的加速器芯片数量是两倍。Graphcore主张两套系统尺寸差不多(IPU-Pod16是5U,DGX-A100则是6U),在功耗和价格上也相当。不过应注意的是,Graphcore唯一做这种比较的公司。
在以ResNet-50模型进行的性能测试上,Graphecore宣称其IPU-Pod16表现优于Nvidia的DGX-A100 (Graphcore系统花了28.3分钟进行训练;Nvidia系统完成训练的时间则是29.1分钟)。
不同于ResNet-50模型,Graphcore的BERT模型测试跑分,反映了每个加速器配备较少主CPU的系统表现。BERT的跑分是以每32个IPU有一个主CPU的系统为基准,ResNet-50模型的跑分则是以每8个IPU有一个主CPU的系统为基准。
“我们拥有依据每个工作负载变化该属性的弹性,这不常见;” Grapgcore首席软件架构师Dave Lacey指出,“这让我们能够实验…并取得这些效率点。”他强调这种方法允许使用者在单一主服务器上执行更多运算,不需要转移至需要额外基础建设的分布式CPU运算。“
“这也是一个重要的成本因素,”Lacy表示:“所有这些系统都搭载了繁重的CPU,这对系统而言是一个显著的成本。如果你能以最佳比例、最小数量的CPU来摆脱负担,让繁重的任务实际上由加速器来执行,就能针对特定工作负载进行成本优化。”
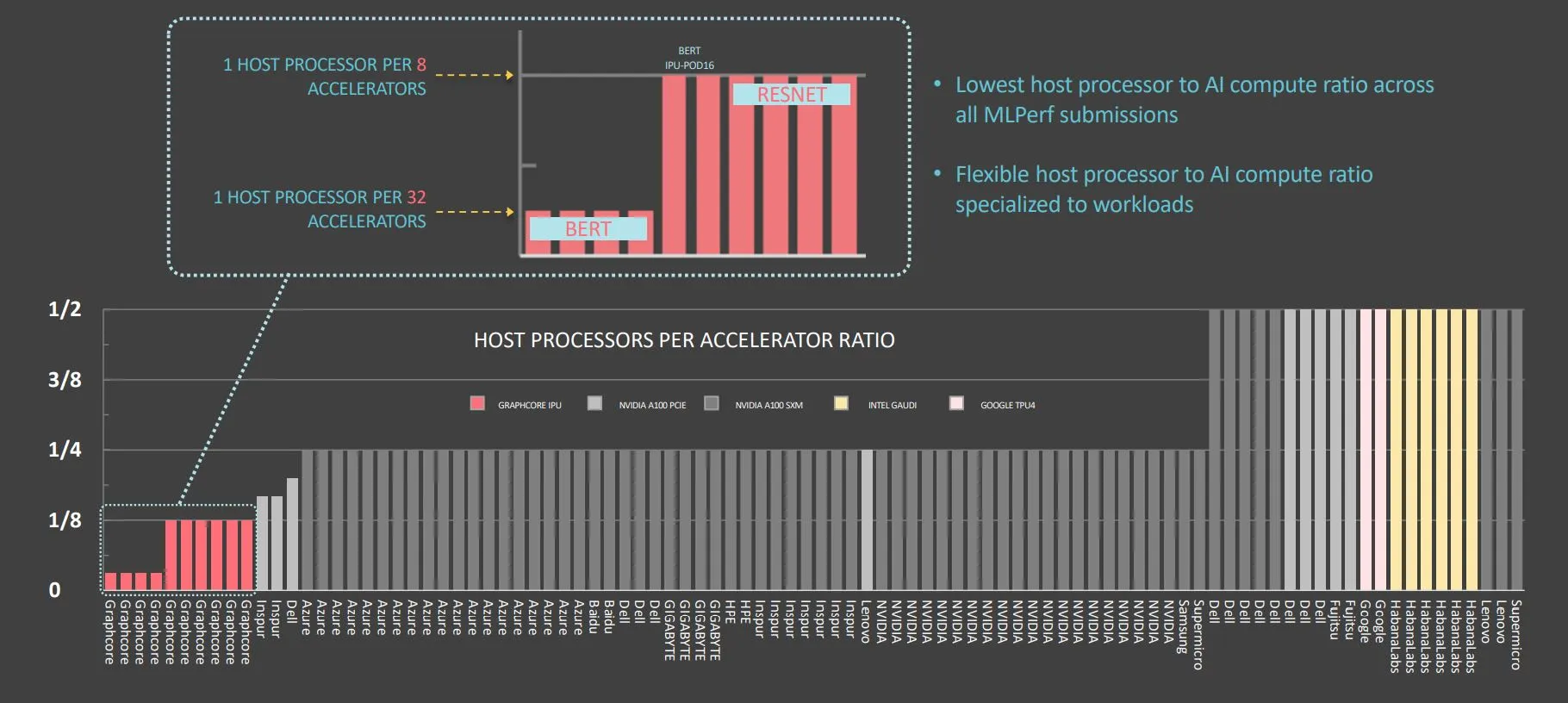
进行BERT模型训练时,每个Graphcore加速器所需的主CPU数量较少。
(数据源:Graphcore)
Lacey表示,Graphcore的IPU设计是经过深思熟虑,把应用逻辑放在加速器上;主处理器和加速器之间的链接只用于训练数据──他强调,没有程序代码、没有繁重的同步,只有数据。
另一个议题是,减少CPU的数量是根据工作负载以及工作负载使用的数据来决定。Lacey指出:“它是依据需要多少准备,或是有多少其他非AI类型的任务需要在CPU上完成;还有在CPU和加速器之间有多少数据传输。”
其效果对于执行BERT模型的工作负载而言特别显著,其中输入的数据会比其他类别的工作负载所需的图像来得小。像是ResNet-50模型的图像处理工作负载需要额外的非AI任务,例如图像解压缩就比较适合在CPU执行,因此需要更多的主机。在主机与加速器间的以太网络链接,也提供了相应地重新配置主CPU数量的弹性。
Graphcore比较了主CPU和加速器数量的比例,是以单一颗Graphcore芯片对Nvidia芯片或Habana芯片为基础。如果单一Graphcore IPU-Pod16等同于单一的Nvidia DGX-A100,当Graphcore寻求ResNet-50训练时间比较,就需要同样数目的主CPU (但在这个例子中任何优势只针对BERT)。
Habana Labs
英特尔(Intel)旗下的Intel的Habana Labs在第二回合的MLPerf训练性能基准检验,是采用其Gaudi训练加速器芯片。与上一回合相较,Gaudi的BERT模型跑分成果加倍,ResNet-50跑分也提升了11%。Habana也展现出它的Gaudi技术的可扩展性,在朴素缩放(naïve scaling)与弱缩放(weak scaling)上呈现类似的结果(weak scaling并未包括在MLPref的跑分结果中)。
Habana资深研究员Itay Hubara表示,朴素缩放考虑在不同规模系统中所需的训练时间,弱缩放则是来自朴素缩放的结果。通常伴随着样本总数(batch size,即同时馈入系统的训练数据样本数目)增加,加速器的数量也会增加,才能保持硬件充分发挥性能。
但是增加样本总数往往需要更多的反复训练,因为在处理更多数据样本之后,权重会被更新;这意味着需要更多的训练数据,以便在较大的系统当中达到相同的结果。weak scaling是每一次数据处理或相同数据量被处理的朴素缩放分数正规化结果。
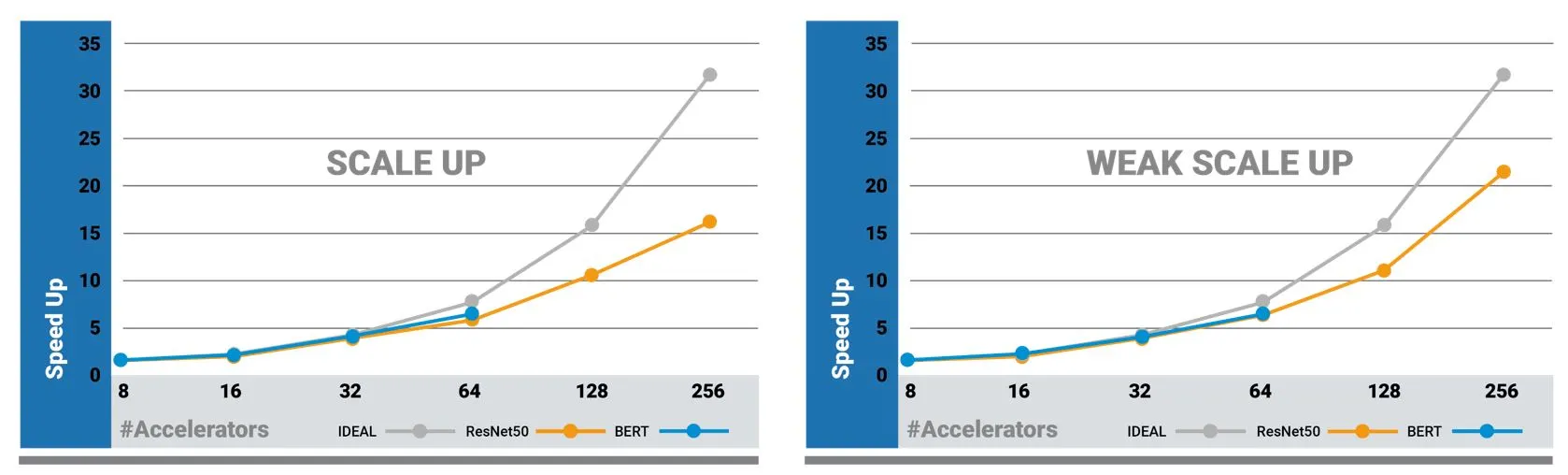
在每一回合的MLPref性能基准检验中,Habana的朴素缩放(左)结果与弱缩放(右)结果类似。
(数据源:Habana Labs)
“我们高达64颗Gaudi芯片的系统弱缩放和朴素缩放表现很接近,因为我们不需要增加样本数目,我们能够以一个小的本地样本数目执行;”Hubara表示:“当加速器从8个转换到16个的时候,我不需要将整体样本数目增加到两倍…Guadi的架构让我们能够实现高利用率,甚至我们不需要将馈入设备的样本数目最大化。”
Habana的跑分结果也比上一个回合进步,这又是得益于软件优化的结果。由于数据封包的技术,BERT训练时间少了一半;在训练数据中较短的句子,被以多序列(multi-sequence)方式打包(较短的句子会以0来填充,以达成一个固定的输入尺寸)。数据封包是在预处理过程中进行处理,不算在性能基准训练时间内。
此外Habana也实现了轻度的检查点(checkpoint)节约;减少检查点可显著节省时间,不仅是节省一个检查点,每个工作节省一组模型权重子集,能使速度大幅提升。
而被问到Habana加速器是否能以较少主 CPU来运作,该公司的回答是:“主CPU对Gaudi卡的比例是可以改变的,对我们的Gaudi卡来说不是限制。一套典型的系统有两个Xeon 插槽供8个加速器所用。我们利用这个配置是因为我们的目标是取代以GPU为基础之系统,而且我们的客户偏好双插槽系统。”
Google在这一回合的MLPref训练性能测试中,并未参与封闭赛程的跑分,不过在开放赛程公布了两套非常大型之模型的跑分结果;这两套模型在架构上与MLPref的BERT模型相似,但有更大的维度和更多层数。
其中之一是利用TensorFlow框架,在一套配备2,048个加速器的TPUv4系统上,进行4,800亿参数、以Transformer架构为基础、仅编码器的性能测试基准训练,花费时间约55个小时。另一个跑分结果是以配备1,024颗芯片的TPUv4系统,进行2,000亿参数的JAX模型训练,花费时间约40个小时。Google表示,每一场训练的系统执行可达到63%的计算效率。
完整的MLPref AI训练性能测试基准跑分结果请参考此连结。
(参考原文:MLPerf Training Scores: Microsoft Demonstrates Fastest Cloud AI,By Sally Ward-Foxton)
