
在大约50年的时间里,半导体行业一直依靠不断缩减晶体管的几何尺寸,以可接受的成本去实现更高的设计复杂性和处理器性能。这些都可以用摩尔定律(Moore’s Law)、登纳德缩减定律(Dennard Scaling)和阿姆达尔定律(Amdahl’s Law)来描述。这些成功的和可预测的尺寸缩减定律正在被打破——那么展望未来,我们如何才能实现性能改进呢?

Rupert Baines,Codasip首席市场官
半导体缩放比例定律的终结
二十年前,系统级芯片(SoC)通常由单个处理器内核、相关指令和存储器、外围设备和混合信号子系统组成。新一代产品都按照摩尔定律在下一个工艺节点提供了更高的密度。摩尔曾预测,大约每两年芯片上晶体管的密度就会翻一番。
与摩尔定律密切相关的是登纳德缩减定律(Dennard Scaling)。通常随着硅芯片上晶体管几何尺寸的缩减,电源电压也会降低。他预测道:这将使得从一代硅芯片到下一代硅芯片的单位面积功耗保持不变。这样做有两个好处,其一是新一代芯片的功耗与上一代芯片大致相同,其二是可以通过增加时钟频率来提高性能。
此外,阿姆达尔定律指出可以通过使用并行处理器来处理潜在的执行加速问题,这给人们带来了希望,即在给定的硅芯片尺寸下,添加额外的并行处理器将增加更多的性能。
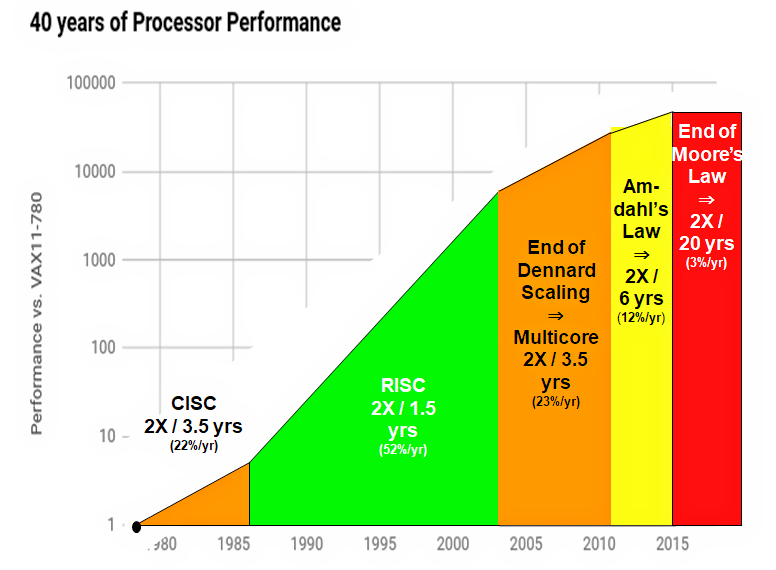
资料来源:John Hennessy和David Patterson合著的《计算机体系结构:量化研究方法(第6版)》,2018年
不幸的是,今天的设计师不能再依赖于曾经成功的、可预测的缩放比例。出现的第一个问题是Dennard Scaling的终结。这是由于以前可以忽略不计泄漏电流(leakage current)在90 nm及以下的几何尺寸中变得非常重要。在功率密度随着几何尺寸的减小而增加时,如果时钟频率太高,就会存在热失控的风险。这意味着时钟频率有一个实际的上限,很少有设计能达到2 GHz以上。
摩尔定律被预测要到终结已经有一段时间了,而且已经很大程度上放缓了。同样重要的是,一颗全新的、尺寸更小的芯片的制造成本,与从上世纪七八十年代开始的前代尺寸相同的芯片的成本相比,已经不再能以相同成本进行制造了。晶圆厂的成本呈指数级增长,只有台积电(TSMC)、三星(Samsung)和英特尔(Intel)能够计划在最小的节点上进行生产。
尽管如此,半导体行业已经通过在单个SoC设计中使用多个处理器来提供更高的性能。一个很好的参照示例是手机芯片,它集成了多个应用处理器来运行诸如Android或iOS等富操作系统,用于基带处理的数字信号处理器(DSP),用于显示的图形处理器(GPU),以及用于无线协议和安全的多个嵌入式内核。
然而,每一种处理器内核都被设计用于处理相当多元化的工作负载。结果,在某些情况下,内核的全部潜力没有得到充分利用。
此外,这种方法也有局限性。为了运行操作系统在手机上创建4核对称多处理器集群是很常见的,但很少有半导体厂商能够实现更大的集群。
根据Hennessey和Patterson合著的《计算机体系结构:量化研究方法(第6版)的说法,处理器的改进速度下降到每年仅为3%。
专业化是唯一的发展方向
如果半导体缩放比例定律失败,设计人员如何在不花费高昂成本的情况下去实现更高的性能呢?对于诸如运行操作系统等一些广泛应用的工作负载,仍然需要通用内核。但在其他情况下,通用内核可能是很浪费的。相同的通用微控制器内核已被用于音频处理、电机控制、安全和无线协议等各种应用。
而对于许多新兴应用,诸如人工智能、AR/VR和先进驾驶员辅助系统(ADAS)等,它们都涉及到对计算能力要求很高的算法,而这些算法与通用内核并不匹配。在某些情况下,可以通过专用的硬接线模块单元提供性能,但在大多数情况下,需要一定程度的可编程性。
Hennessey和Patterson设想了一种基于特定领域加速器(DSA)的新型处理器内核。这些内核是经过优化的,可以处理非常具体的工作负载。通过专业化处理,此类内核省去了对运行在其上的软件无益的功能。这样就提高了功耗效率,减小了硅芯片面积。
Codasip
此方法Codasip集团CC by - nc - sa 4.0
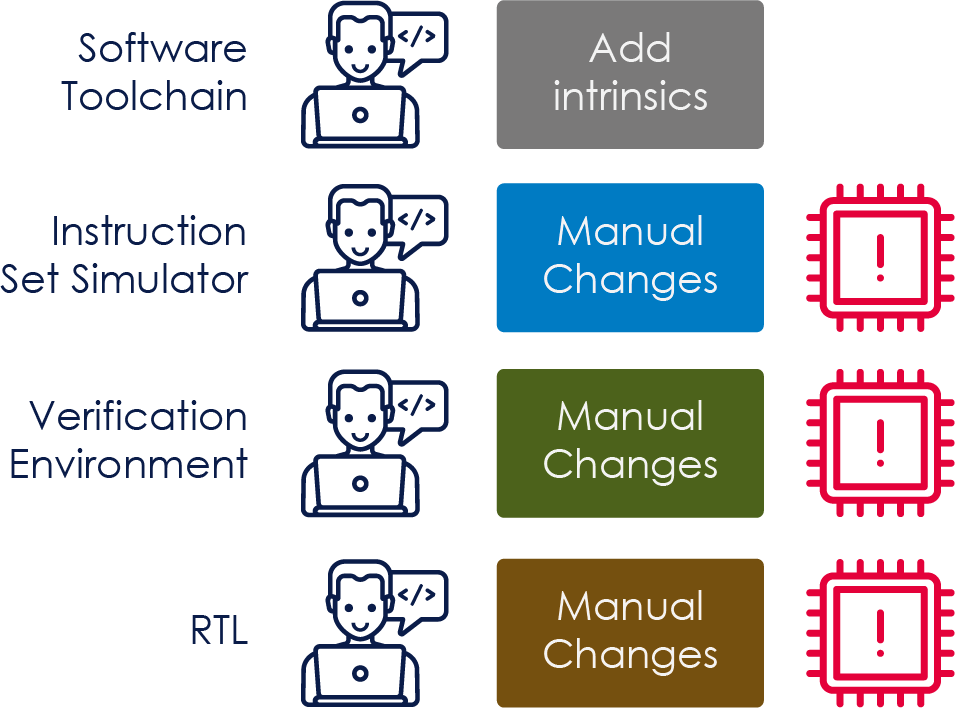
一些公司已经开发出了非常专注于特定应用的内核,通常被称为专用指令集处理器(ASIP),以有效地处理被定义在某个特定领域计算工作负载。然而,开发这样的处理器内核需要非常专业的技能来定义指令集、开发处理器内核和相关的软件工具链,并最终还要完成处理器验证。这需要处理器架构师、RTL开发人员、编译器开发人员和验证工程师协同工作。很少有公司能够负担得起这种方法,特别是当这个开发是由人工进行的,这会非常耗时且容易出错。
为了在半导体缩放比例定律终结时还能提高性能,就有必要开发许多不同的专用处理器内核/加速器。为了实现这一目标,就有必要让更大范围的芯片设计人员能够去完成处理器的设计和验证。实现这一目标主要有两种途径:
a) 处理器设计自动化
b) 处理器定制
开放和灵活的标准有助于专业化发展
开发ASIP不得不面临重重挑战性的原因之一是,需要从头开始开发指令集。如果没有非常昂贵的架构授权,诸如Arm等商业指令集架构(ISA)是无法使用的,而且很少有公司具备开发自有ISA的能力。
市场已经提供了诸如OpenSPARC和OpenRISC等一些开放的架构,但是它们还没有被广泛采用,部分原因是它们缺乏领域专用架构所需的灵活性。
在我看来,RISC-V完全改变了游戏规则,它为创建DSA提供了必要的功能,并从免费和开源中获益。

该指令集Codasip集团CC BY-NC-SA 4.0
RISC-V ISA的第一个好处是它具有三个类别的模块化:
a) 对于一个特定的字长,必须始终使用基本整数指令集。像早期的、只有40条32位指令(RV32I)的RISC ISA一样,只有很少的指令。但是对于大多数应用而言,这种基本整数指令集不太可能有效。
b) 通过使用可选的标准扩展项以获得更高的性能。现在有许多指令集,包括单精度、双精度和四精度浮点、压缩SIMD、压缩、位操作等。
c) 对于可选标准扩展项没有很好覆盖的特殊指令,可以创建非标准的自定义扩展项。
这种模块化与DSA的需求非常吻合,因为它可以根据计算工作负载调整指令集。您可以选择加速器所需的标准扩展项,并且可以创建用于微调和差异化的自定义指令。
与创建自定义ASIP ISA不同,在为加速器创建特殊ISA时,您有一个很好的起点。从现有指令集中进行选择远比从头开始开发ISA的成本要低得多。
实现设计自动化
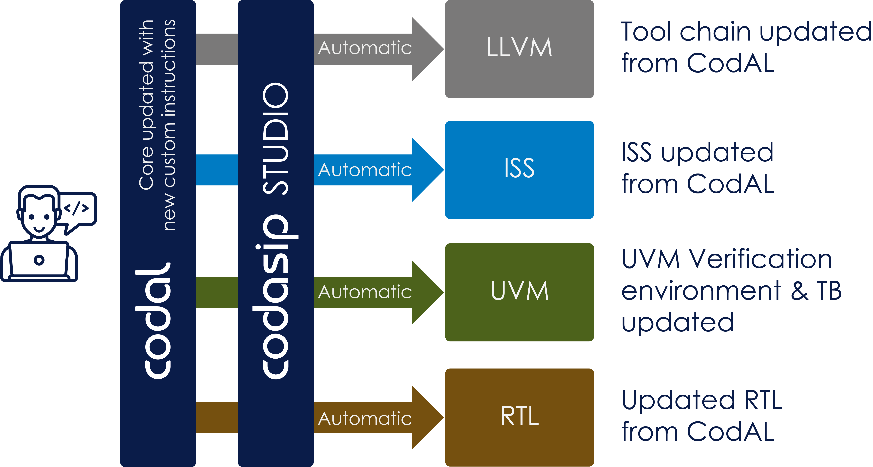
即使具有RISC-V的灵活性和开放性,但是在没有设计自动化的情况下,创建一个处理器或DSA也具有很多挑战性。一种替代手工创建设计的方法是使用一种高级架构描述语言,例如CodAL等。
成熟的高级架构描述语言的主要优点是,处理器的所有方面都可以从一个单一的来源得到解决。该描述语言涵盖了指令集、资源、语义和微架构,并由此可以自动生成软件开发工具包(SDK)和硬件开发工具包(HDK)。对架构描述的任何更改都可以自动反映在编译器、RTL、仿真器和验证环境中。
此方法Codasip集团CC by - nc - sa 4.0
展望2022年,为了通过创建专用于领域专用的加速器来克服半导体缩放比例定律的限制,设计团队可以从他们的软件开始着手。可以定义一个初始指令集(例如RISC-V基本整数和一些有前景的标准扩展项),并在该目标ISA上进行软件分析。设计人员可以用其他指令进行试验,以便根据目标应用的需要对其进行调整。
一旦ISA被固定,设计人员就可以专注于定义微架构并对其进行微调。当微架构稳定时,RTL可以自动生成,并根据黄金ISS参考进行验证。
如果一个现有的处理器内核接近于满足特定工作负载的要求,那么如果它是用架构描述语言设计的,则可以使用相同的自动化设计方法进行定制。这可以显著缩短DSA的上市时间。
总结
我确信,需要用一种全新的设计方法来克服半导体缩放比例定律终结所带来的限制。如果要通过创建针对特定领域的加速器来克服这些限制,并需要根据其计算工作负载来进行微调时,就需要许多不同的设计。传统的ASIP设计在这方面不具有高性价比,此类设计需要由更广大的工程师团队来进行。
开放的、模块化的RISC-V ISA、高级架构描述语言和设计自动化工具的结合能够为处理器设计开启一个全新的时代。
Codasip高级市场总监Roddy Urquhart 的展望视频版:
本文同步刊登于《电子工程专辑》2022年1月刊杂志
责编:Luffy Liu

{kind=link}