
去年初我们写过一篇文章《一场硬仗:华为和高通的GPU差距还有多大?》用以谈手机GPU的发展现状。到如今差不多2年过去了,移动GPU格局是否已经发生变化?或者说苹果独孤求败的地位在否?
恰逢高通和联发科前不久都相继宣布了新品,是时候来看看如今的手机GPU相比2年前发展成了什么样。


主流移动GPU一览
要做对比,自然要先明确对比对象。今年这个时间点的对比对象还是相当明确的,我们分别取主流手机SoC的近两代GPU,则其名称和配置大致是这样的:
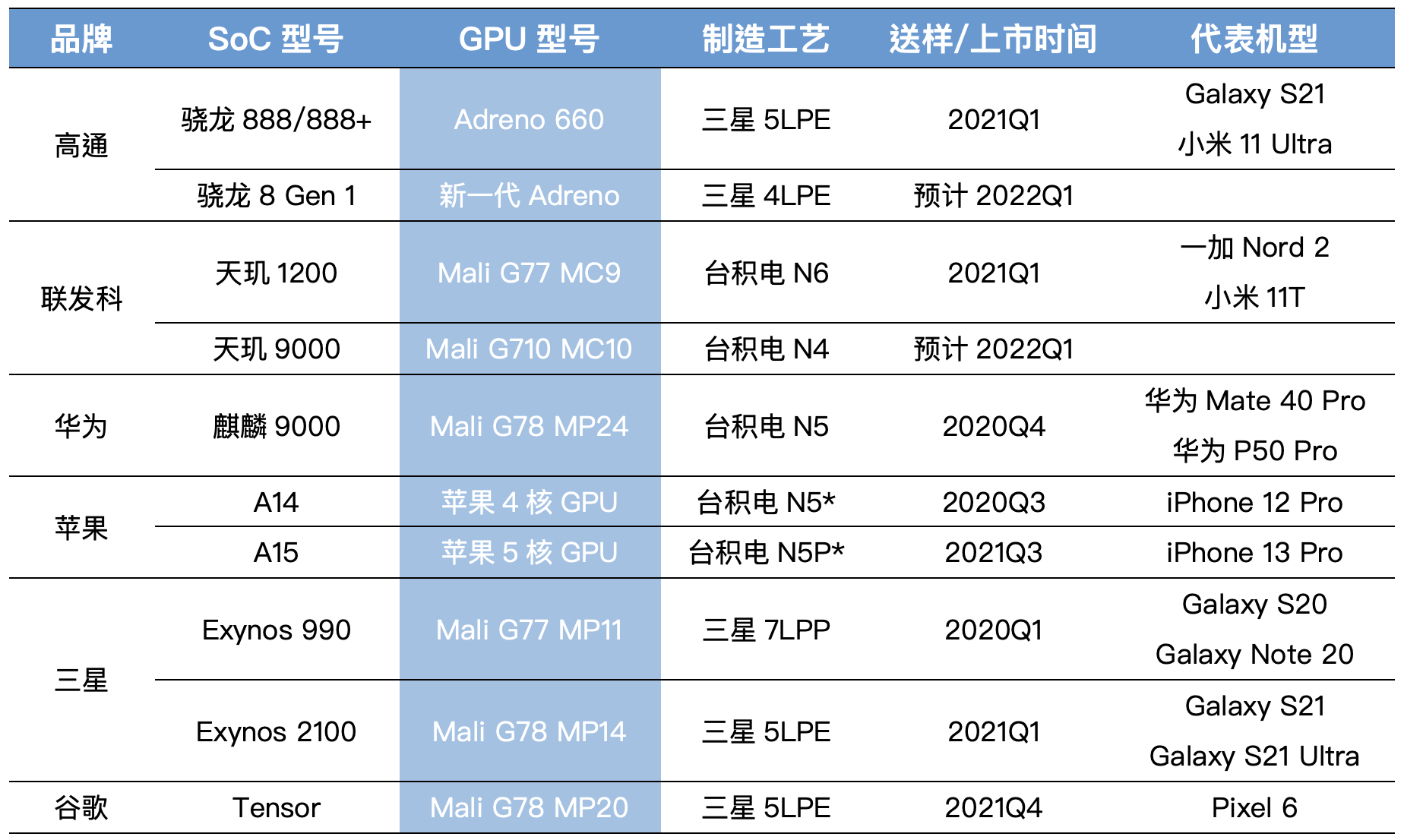
Imagination的GPU IP虽然有出现在展锐虎贲T710这样的芯片上,但其高端IP并不见于主流旗舰智能手机产品,所以此处未列出Imagination的产品。华为则因为众所周知的原因,自去年发布麒麟9000芯片后便再未有新品更新,所以这个对比或许对华为而言没那么公平。
谷歌是最新加入战局的,今年为其Pixel 6手机推出了自家的Tensor芯片,这颗芯片实际上是谷歌和三星LSI的合作产品。
联发科、华为、三星的手机SoC所用GPU IP都来自Arm(以及最新加入的谷歌);苹果和高通都用自家的GPU IP; 苹果GPU基因较大程度沿袭自Imagination。值得一提的是,三星和AMD此前已经达成合作,可能明年的三星Exynos芯片上就能看到AMD GPU的成果。
注意本文只专注于GPU的图形性能,而不探讨AI性能——像高通骁龙这样的芯片,也着力于强调GPU对AI加速的帮助。
先看看各家的纸面数字
移动GPU的纸面数字其实没什么好看的,包括核心、频率等都极大程度受到架构的影响。比如Arm Mali系列GPU核心这么多,麒麟9000所用的Mali G78用上了顶配的24个核心;而苹果和高通Adreno GPU的核心都是个位数。这种对比就显得没有意义。
移动GPU产品中,Arm Mali的架构透明度还相对大些,高通和苹果家的GPU几乎不对外披露任何架构层面的技术细节。不过我们从隔代性能、效率提升,多少还是能有一些简单的认知。

先说说Arm Mali。上面这张产品表中,这两年Arm Mali家族出现最多的是Mali G77和Mali G78,明年预计Mali G710将全线上马。对于这三款GPU IP,过去我们都已经分别撰文做过解析。
这3代GPU IP实则都属于同一个架构:Arm也是从Mali G77开始推行这种Valhall架构的。Valhall架构除了在ISA方面的改进,还包括执行引擎的变化,warp size拓宽到16-wide,每个执行引擎两条数据通路。
Mali G77发布的时候,我们曾预测Arm Mali GPU将有机会改变性能孱弱的现状,甚至赶超高通。像麒麟9000这种将Mali G78堆满核心(24核心)的SoC的确在性能上开始逐步赶超高通Adreno GPU。但实际情况会更复杂,后文将会提到。
事实上此前G72 -> G76 -> G77 是两次比较大的性能跃进,也是追赶高通的几代重要产品。而G78相比G77的变动其实不大,属于原有架构的改款。不过G78支持的最大核心数目增大至24个。麒麟9000就把GPU的配置拉满了。
而三星Exynos 2100仅配了14核心的Mali G78。从这一点至少可知Exynos 2100的GPU理论峰值性能会显著弱于麒麟9000。联发科天玑1200则因为产品定位差异,几乎没有和麒麟9000、Exynos 2100站在同一起跑线上。
比较值得一提的是谷歌Tensor芯片,所用的Mali G78为20核心,规模仅次于麒麟9000,而且频率也不低。Tensor所用的Mali G78MP20可能是市面上唯一选择了Mali G78不同步时钟域方案的产品——这个特性此前我们也提过,就是shader核心与GPU的其他模块可以跑在不同的频率下(shader频率848MHz,tiler与L2 cache频率996MHz)。
来年联发科天玑9000将要采用的Mali G710是G78的迭代产品。G710虽然也是Valhall架构,但规模上是有变化的,包括shader核心中的执行引擎、执行引擎内部结构等,整体较大程度提升了shader性能、纹理单元吞吐(理论翻倍),还有一些节能设计。Mali G710的可配置核心为7-16个。
不过从总体来看,Arm说G710相比G78有20%性能提升(可能主要是因为可选配的核心数变少了),且同性能达成20%功耗下降。这个数字相比竞品是相当保守的。从这个角度来说,天玑9000的图形算力在明年的竞品中可能会很被动——天玑9000选配的是10核心的Mali G710,单纯从这个数字来看,绝对性能是否足够应付上一代的麒麟9000都有待观察——当然理论上能效会有提升。

接下来聊聊高通Adreno GPU。骁龙888的Adreno 660仍然是6字头,这好像还是高通历史上头一次一个大版本号用了这么多代的GPU。从骁龙845的Adreno 630,到855、865、888都在用Adreno 600系列。
不过Adreno 660发布之际同时引入了VRS(可变速率着色),这对移动图形计算是很有价值的。性能方面高通宣称Adreno 660相比上代(骁龙865,Adreno 650)提升性能至多35%;能效提升20%。单看这个数字,必然是比A77 -> A78的提升幅度要大不少的。具体如何,后文再看。
而前不久随骁龙8 Gen 1而来的新一代Adreno(有说是Adreno 730)应该在架构上有了较大的改进。像是GMEM(高速缓存)容量增加,而且可读可写,以前仅作为回写cache存在。高通表示这次新版Adreno带来的性能跃进,可能无法直接反映到跑分上。
高通给出的数据是新一代Adreno的峰值性能提升30%,在与骁龙888达到相同性能的情况下节能25%。这回高通还特别强调要改变现如今移动GPU市场恶性追求峰值性能的现状,力求改变GPU性能与功耗曲线的行为方式,争取让曲线平滑化,在3-5W功耗区间内实现切实的性能提升。

苹果这边能聊的就更少了。苹果今年对A15的说法,普遍是在对比市面上所谓“主流”竞争对手,连与A14的比较数值都没有提供。我们知道A14的GPU,无论效率还是性能都已经十分彪悍了,是高通都难以望其项背的,预设A15的表现自然不会差。
苹果此前有发布过一个视频,谈到了架构方面的变化,包括A15相比前代FP32 ALU翻倍;而且A15还引入了有损可渲染纹理,以节约存储和带宽等。从SemiAnalysis发布的die shot来看,A15的GPU整体增大了30%的面积,毕竟这回满血版A15的核心数也多加了1个。在不增加带宽资源的情况下,据说就能实现性能的极大提升。
是骡子是马,拉出来溜溜
说了这么多废话,照例还是援引收集AnandTech的测试数据。以上表格中列出的芯片和GPU,唯有天玑9000还没有实测成绩。骁龙8 Gen 1目前也没有手机产品问世,不过前几天AnandTech和极客湾都拿到了骁龙8 Gen 1的手机设备(或高通参考设计),做了一轮测试——测试数据仍不完整,以下仅作参考。
需要指出的是,芯片性能发挥很大程度受制于OEM厂商的系统设计(包括机型尺寸、用料、散热设计等;例如小米11 Ultra和三星Galaxy S21 Ultra虽然都采用骁龙888,但前者的功耗控制更激进,游戏中允许长时间停留在在5-6W间;而后者则只允许整机功耗长时间持续在3.5W水平上,则性能表现自然就有差异),以下援引的成绩无法保证代表了该芯片的最佳性能和效率,但作为已经量产的终端产品,还是具备了参考价值的。
本文的机型选择上,骁龙888对应Galaxy S21 Ultra(骁龙版),麒麟9000对应华为Mate40 Pro,苹果A14对应iPhone 12 Pro,苹果A15对应iPhone 13 Pro,Exynos 990对应Galaxy Note 20,Exynos 2100对应Galaxy S21+(Exynos版),谷歌Tensor对应Pixel 6。
我们没有找到天玑1200的数据:天玑1200的GPU为Mali G77MC9,从与其配置比较类似的Exynos 990(Mali G77MP11)可以做简单的推测。天玑1200在以下对比中,整体图形与游戏性能都将排在最末的位置,无论其能效表现如何。
对比项目为GFXBench Manhattan 3.1离屏渲染测试,以及GFXBench Aztec Ruins高画质离屏渲染测试。这两个测试无法完整代表GPU图形性能,但受限于精力和资源,我们也只能收集这两项测试的数据,对比结果如下:
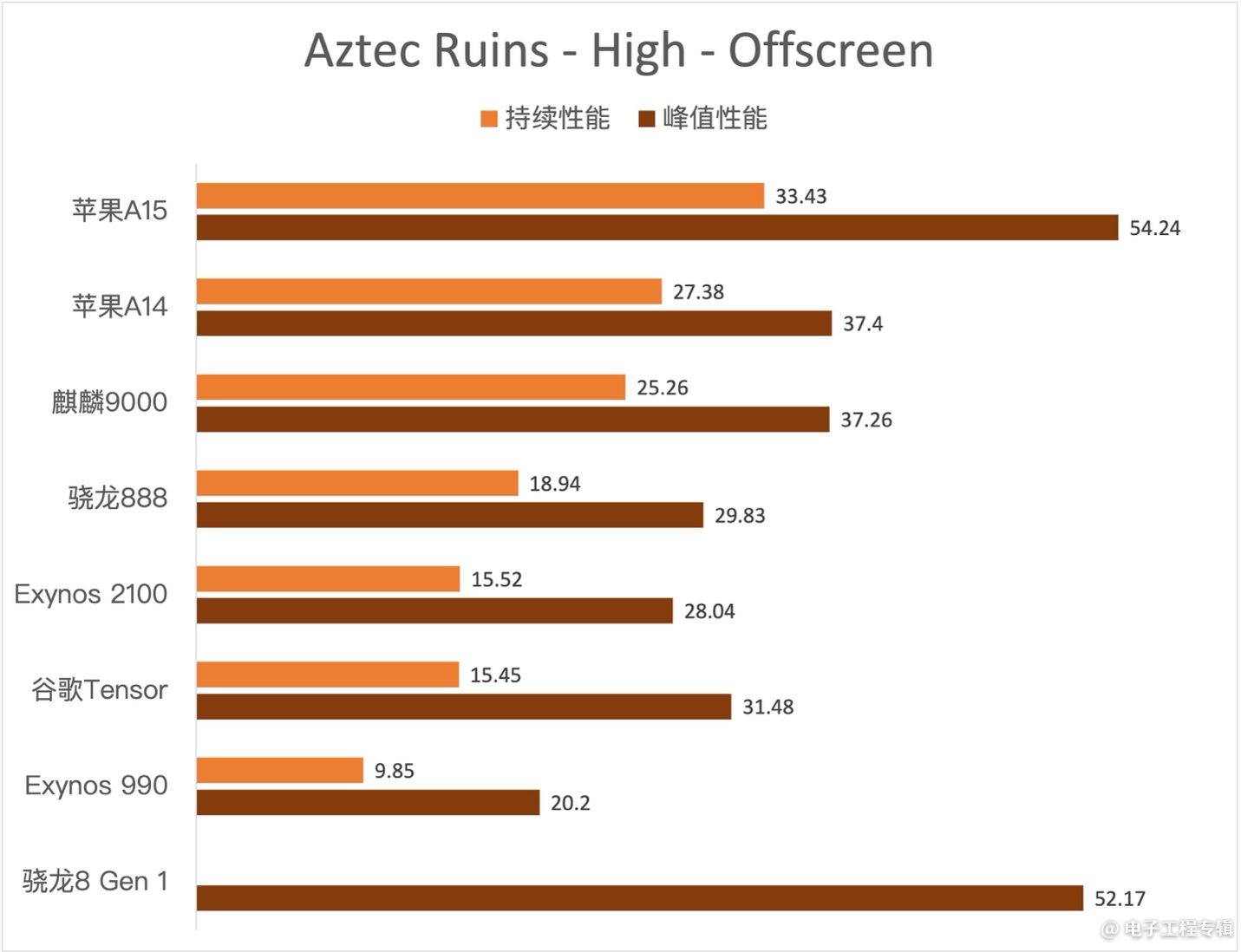
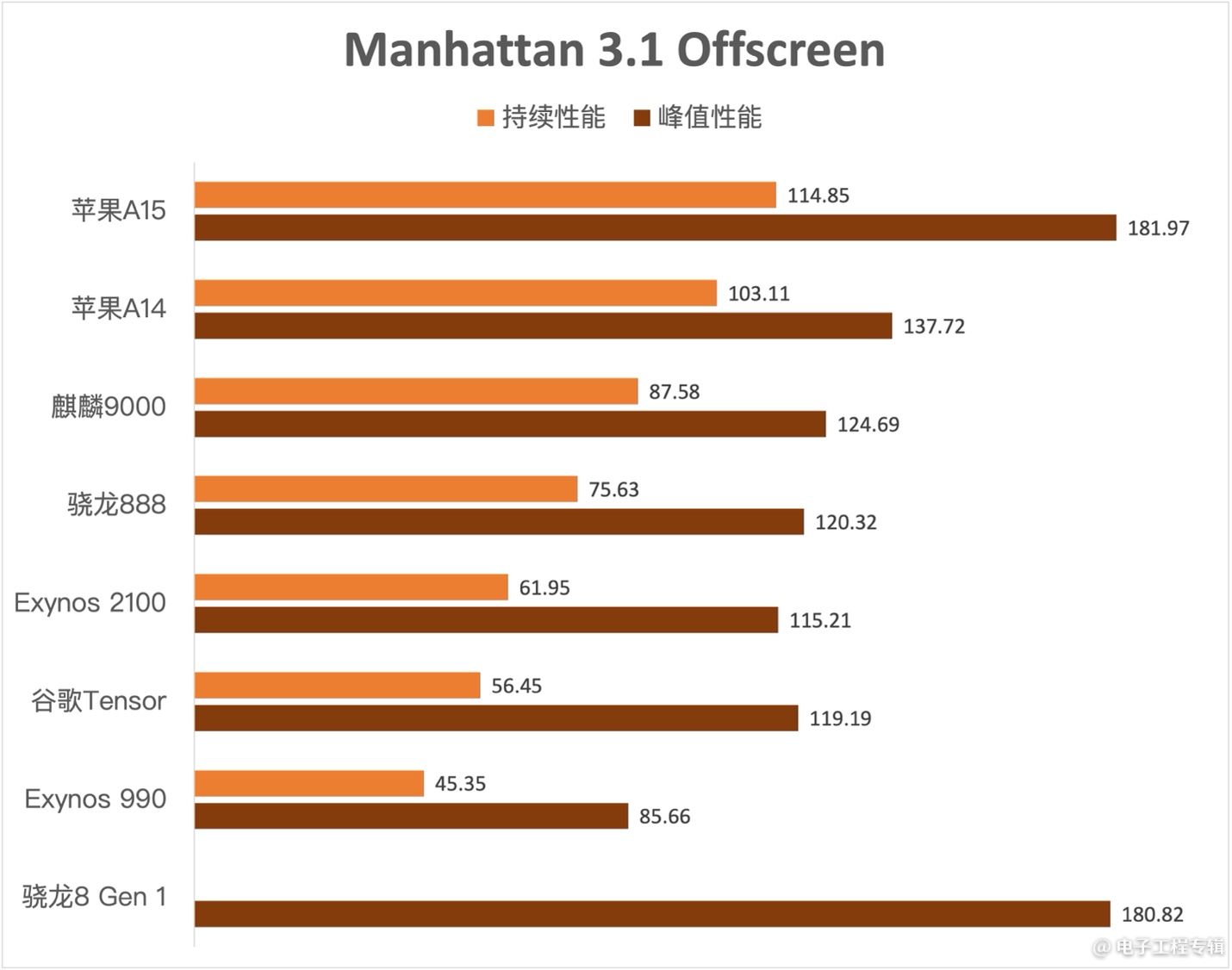
数据来源:AnandTech
如果单看性能的话,苹果的一骑绝尘是毋庸置疑的,无论是峰值性能还是持续性能都领先其他竞争对手一个身位。除了苹果之外,在GPU绝对性能上比较亮眼的应该是华为麒麟9000,在性能项目上能够完败骁龙888。
可见一方面Mali G78堆满24个核心是的的确确有用的;以及Arm这边的GPU在绝对性能方面真正意义上在这1-2年对止步不前的高通Adreno GPU构成了威胁——当然后文会提到,这也是要付出相当的代价的。而且本文没有尝试探讨面积效益:Arm Mali在这方面也是吃亏的。
这里相对匪夷所思的谷歌Tensor,GPU虽然也堆了20个核心的Mali G78,在峰值性能上的确和骁龙888互有胜负,但持续性能却一言难尽,到头来比规格更低的Exynos 2100(14核Mali G78)还不如。当然还是那句话,这与手机本身的系统设计乃至OEM厂商的软件都有很大的关系,不单是芯片的问题。
这两年Android阵营这边的芯片产品逐步落入峰值性能与持续性能严重不对等的怪圈。实际上苹果这边的峰值性能是实实在在有价值的,iOS对于GPU突发性能的日常操作利用率越来越高;而且苹果这几年也在刻意强调峰值的突发性能。但Android生态中,GPU峰值性能的实际价值暂时就没有那么大了——大概主要是有利于做营销宣传吧。
性能部分最后需要提的是,AnandTech测试骁龙8 Gen 1芯片的参考设计,发现其峰值性能几乎和苹果A15是一个水平。当然参考设计和最终量产的产品,在形态和系统设计上大约还将差异颇多。不过起码骁龙8 Gen 1手机来年的游戏体验是可以期待一下了。
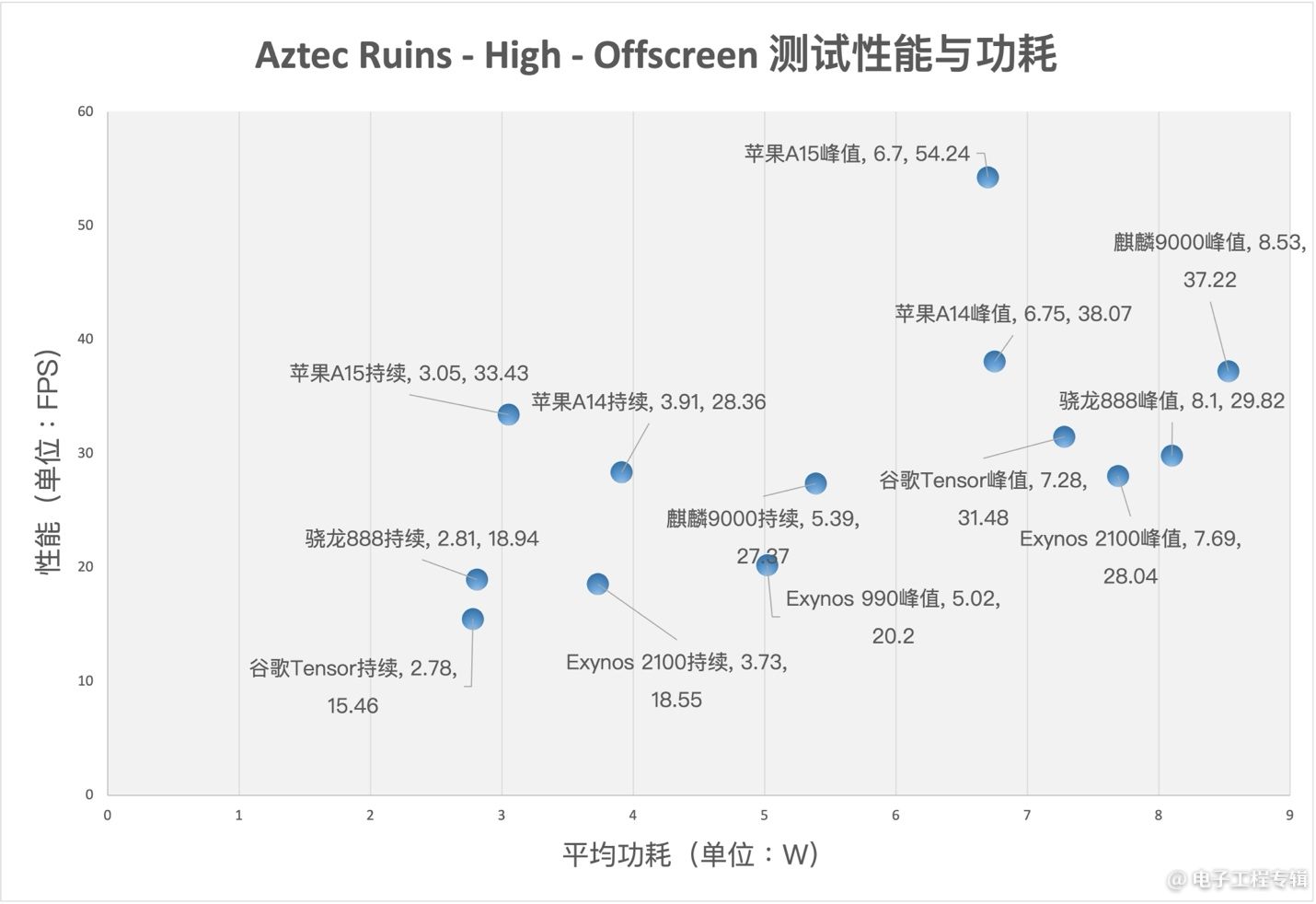

这两张表的纵轴表示跑分(越靠上越好,表中每个项目的第2个数字),横轴表示跑分对应的平均功耗(越靠左越好,表中每个项目的第1个数字);每个点表示的是处理器跑在峰值性能或持续性能下,其跑分与功耗对应的位置
到加入功耗考量的环节,苹果之外的其他芯片就多少都有些惨不忍睹了。这两张表将大部分芯片分成峰值性能和持续性能两个状态,并统计峰值性能下的平均功耗(单位W)和持续性能下的平均功耗。
虽然我们常说,瞬时功耗高不是太大的问题,只要效率高就行。眼见着现在所有手机芯片GPU的峰值功耗都比此前我们说功耗爆炸的苹果还高,跑出来的性能却一点也不美丽。
这里尤为值得点名批评的是谷歌Tensor。AnandTech在评测文章中提到,Tensor在跑Aztec Ruins高画质离屏渲染测试时,瞬时功耗可以超过9-10W。在这种功耗下很快就会因为发热被迫快速拉低功耗。所以Tensor的GPU规格虽然比Exynos 2100大不少,实际性能红利却远没有规格看起来的那么多。(当然,这口锅很大程度上也需要Pixel手机的系统设计来背)
骁龙888、Exynos 2100、麒麟9000也都没有好到哪里去,都是以远高于前代产品的功耗(普遍在8W附近,甚至更高),换来更多的性能。其数秒内的瞬时功耗都能飙到10W乃至更高,它们在峰值性能状态下的效率都比前代产品显著更差。

对于这两张表,各位可以用跑分÷功耗,得到一个可反映效率的值。GFXBench Aztec Ruins测试中,Exynos 2100和骁龙888在峰值性能下的效率极其不堪;而Manhattan 3.1测试,效谷歌Tensor、骁龙888、麒麟9000和Exynos 2100的糟糕程度都是不遑多让的。尤其Exynos 2100和麒麟9000两种性能状态下的效率都很不理想。
不过有个比较有趣的点值得一提,骁龙888持续性能下的效率很出色,和苹果A14是差不多的水平。与此同时,麒麟9000的GPU在Mate40 Pro手机的省电模式下,效率也不错,接近A14。当然这两者在此状态下的性能和A14就有较大差距了。但从这一点就不难发现,手机芯片厂这两年颇有刻意拉高规格和功耗的嫌疑,大约是都希望在性能上向苹果看齐。因此早就越过性能与功耗的甜蜜点,致效率十分低下。(另外,三星5LPE工艺实在是有严重的debuff)
有兴趣的同学可以自己去算一算这个除法等式,然后给效率排个先后,就会发现苹果的领先幅度是毁天灭地级的。A14的GPU在这两项测试里,即便是跑在峰值性能状态下,其效率也比其他绝大部分芯片持续性能状态下的效率高。而A15更是将这种差距拉到了另一个纪元。
只不过iPhone的GPU也并非完美,即便有着最好的性能和效率,iPhone手机的系统设计仍然限制了其性能发挥:包括PCB板上更密集的元件排布,以及SoC夹在双层PCB板中间的方案。iPhone 13 Pro因此在持续功耗方面有着更大的限制。

从已经公开的天玑9000和骁龙8 Gen 1的消息来看,我们认为天玑9000在GPU理论图形算力方面恐怕很难与苹果相较——即便联发科对Mali G710的实施方案再神乎其神,台积电N4工艺再省电,其规格都决定了这局依然没什么可比的。
骁龙8 Gen 1的GPU目前偷跑的性能成绩倒是十分亮眼——如前面图表中列出的,其峰值性能已经和苹果很接近。但从极客湾最近刚刚公布的测试来看,骁龙8 Gen 1在跑Aztec Ruins测试的时候,峰值功耗也突破了11W,远高于苹果A15。这个测试结果可能仍然有待商榷,后续有做观察的余地。
大概我们仍然可以说,这两年甚至在接下来至少一年时间里苹果A系列芯片的GPU还将在性能和功耗、效率方面独占鳌头。现阶段有机会挫败苹果的,大概只能等等看三星和AMD的合作了。
责编:Amy Wu
- Exynos2200被8G1吊打,反而是8+G1摸到了A15的屁股了
