
机器人技术这两年在各行各业的应用和发展是迅速的,对于普通人而言,在购物中心或餐厅看到机器人,好像越来越司空见惯了。许多酒店、医院、工厂对机器人的应用也日趋普遍。机器人是各学科、各类技术的集合,其自主化、智能化实现都并不容易。比如操控、自主导航就是很大的难题,仅依靠传感器技术的发展是不行的。
今年GTC报道中我们提到过,汽车大概可以认为是某种特殊的机器人。但两者又有差异,比如说汽车自动驾驶是遵循道路路径、路面和路侧标志的,而机器人的自主导航——如在工厂中的物流机器人——就这个层面的实现难度显然会更大,因为它们没有天然的固定路径。


我们自然能够想到的是利用AI技术来训练机器人,令其构建起自主导航和操纵的经验。但机器人的AI训练,不可能是在现实中让一大堆机器人真的跑在一个实体工厂里,并通过四处撞壁来习得经验。
前年的GTC China之上,英伟达发布了面向机器人的Isaac SDK。当时黄仁勋在演讲中提到Isaac是“用在非结构化环境中的导航和关节活动控制”的,Isaac“让机器人自我学习,模拟、训练”。
此前英伟达的宣传中提过Isaac包含4个模块,分别是Isaac Sim、Isaac Engine、Isaac GEMs,Isaac APPs。未知现在其抽象构成是否已经发生变化。我们着重想谈的是其中的Isaac Sim。这是个机器人仿真平台,可以进行环境和机器人的建模、算法的验证、强化学习、监督学习的模型训练等。
简单来说,Isaac Sim是为了让机器人在其“脑内”进行AI训练,搭建起虚拟的环境,并进行机器人建模。值得一提的是Isaac现在是Omniverse的一部分(有关什么是Omniverse可参见这里)。比如说在Omniverse中开发一个跑在工厂里的机器人,那么就在Omniverse中构建工厂场景;在场景搭建完成后,再对机器人做建模并放到Omniverse中。在虚拟的世界里就可以对机器人进行各种测试了,包括可以在这个虚拟世界中进行强化学习算法开发,还有目标检测之类的机器学习。

我们知道Omniverse对于现实世界的模拟是颇有心得的,包括物理引擎、图像渲染。这是机器人能够在Isaac Sim环境下进行各种学习和测试的基础。
不过一旦涉及到了AI,训练数据从哪里来、有没有好的数据就成为很大的问题。在这个问题上,英伟达选择的是数据生成+迁移学习的方式。针对数据生成,英伟达似乎从更早开始就在做研究,包括CVPR 2021之上都有研究成果的介绍,有兴趣的同学可以去搜搜看。
前不久的GTC上,英伟达又特别发布了Omniverse Replicator,这就是个合成数据生成引擎(synthetic-data-generation engine),其中之一就是面向Isaac Sim的(Isaac Sim Replicator)。
机器人的“脑内世界”
用合成数据来训练AI是如今挺热门的研究课题,因为合成数据生成是以模拟的方式来生成数据,减少了数据创建所需的成本和劳动。Omniverse Replicator就是能够产生物理模拟的合成数据的引擎,用于训练深度神经网络。
实际上GTC上发布了两个Omniverse Replicator的应用,分别面向DRIVE Sim(DRIVE Sim Replicator)和Isaac Sim,也就是汽车和机器人。英伟达表示,Omniverse Replicator能够让开发者创建AI模型,填补真实世界数据的空白,还能够以人无法做到的方式来标记地面真值(label the ground truth)。在虚拟世界中生成的数据能够覆盖大范围的各种场景,包括一些比较罕见和危险的情况——是在现实世界当中通常都难以察觉的。
这里“填补真实世界数据的空白”指的其实是真实世界数据收集的困难性。比如说位处气候炎热地带的开发者,若要模拟雪地的训练环境,那么对现实世界而言耗费的成本就会很高。那么用合成数据生成的方式,也就是用模拟世界生成的数据,就能显著降低成本,尤其是时间成本。
英伟达表示,Isaac Sim中的这些新功能使得工程师能够构建“生产级”的合成数据集。每次迭代的数据都是在模拟世界里生成的,也就加快了模型训练的速度。
尤其对于现在比较流行的“以数据为中心”的ML方法来说,开发模型其实就是不停迭代(iterate):工程师对完成训练的模型进行评估,并确定数据集的改进;然后生成新的数据集,再进行新的训练。如此迭代往复,直到模型性能达到要求。这其中数据的产生,自然是相当关键的组成部分。
除了数据生成本身的价值,合成数据也有让ML工程师做参数控制的余地——包括噪声、环境变量等因素,或者说工程师对数据有更高程度的掌控度,则开发时间自然可以被极大程度地缩短。以下这张图是在Isaac Sim中合成数据生成工作流的示例。

这些数据是怎么生成的?
针对Isaac Sim Replicator是怎么工作的,英伟达官方有给出一个AMR(自助移动机器人)避开叉车叉齿的示例。感兴趣的各位可以去看看Isaac Sim Data Replicator的这个功能概述视频,就是大致给出个概念,来说AMR如何避开叉车的。
避开叉车用传感器不就行了吗?工厂现有AMR会用平面LiDAR,这类传感器的确可以做对象测距。但这种平面LiDAR虽可检测叉车底盘,却检测不到叉齿(相比底盘通常更突出)。在这一例中,如果AMR能够知道:这是一辆叉车,也就能够避开叉车叉齿了。
一般数据生成的方式,都是在仿真中大量生成图片或CAD模型,再加入噪声和各种环境变量,以此来“复制目标域的内在分布”。英伟达介绍中提到,用Isaac Sim Data Replicator训练DNN的工作关键流程是这样的:
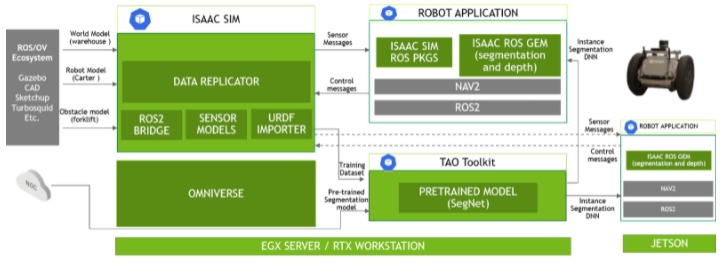
- 在 Omniverse 的 Isaac Sim 中建立仓库场景
- 在仓库中放置一个 AMR 并重新创建故障场景
- 获取叉车模型并使用 Isaac Sim 生成合成数据
- 使用合成数据,使用 TAO 工具套件训练现有的预训练模型
- 使用 DNN Inference Isaac ROS GEM 部署该模型
- 在模拟中测试 Isaac ROS GEM
- 最后一步:在 NVIDIA Jetson 平台上的机器人软件栈中部署 Isaac GEM
这里面我们比较关心的是1-3步,尤其是第3步。其过程至少包含了下面这些要素:



从用USD(不了解什么是USD点这里)来表达一辆叉车3D模型,到后续叉车本身的纹理随机、姿态随机、场景纹理随机、对象数量变化,包括还在场景中加入其他非叉车对象等等;最终让深度学习模型泛化对叉车的理解。各种环境变量,纹理、照明、姿态,主视角(机器人)的位置等等都可以配置。

除了Omniverse Replicator之外,针对将模型部署到机器人之上,英伟达还有更丰富的流程布局(如上图)。这从前面列举的Isaac Sim Data Replicator训练DNN的工作关键流程中也能看得出来。包括将合成数据,用TAO工具套件来训练预训练模型——有关TAO,我们此前的文章就已经有了介绍;以及将模型添加到Isaac ROS GEM中,实现AI感知;落到实处就是“在NVIDIA Jetson平台上的机器人软件栈中部署Isaac GEM”(GEM是机器人的算法功能模块)。
这套流程实际上是能够体现英伟达从软件到硬件的生态能力的,Omniverse Replicator只是其中的一个组成部分。或者说这里我们看到AMR训练避开叉车叉齿的全过程,也只是英伟达AI生态中的冰山一角。

这里既然提到了Jetson,可捎带一句前不久的GTC上,英伟达宣布推出Clara Holoscan——这是面向医疗设备的一款软件定义、可编程影像平台。黄仁勋在主题演讲中说Holoscan是英伟达的第三个机器人平台(另外两个是Isaac和Drive)。这一点在我们此前的GTC报道文章中就提到过。
随Holoscan而来的,英伟达同时宣布推出AGX Orin传感器处理机器人芯片。这颗芯片预计明年1月发售。而基于Orin芯片的Jetson AGX Orin乃是英伟达Jetson家族的新成员,用于取代此前的Jetson Xavier。芯片方面是安培架构GPU和Cortex-A78 CPU的升级,Int8算力达成200TOPS。Holoscan平台就是由Orin和ConnectX-7组成的。Jetson作为英伟达的边缘AI平台,也成为其在机器人方面发力的重要构成,或者机器人生态构建的布局。
我们从Holoscan的出现就不难发现,英伟达还在扩张其机器人生态的覆盖范围。想必将来Omniverse Replicator也会扩展到Isaac和DRIVE之外吧。
责编:Luffy Liu
