
前不久我们体验了Intel 12代酷睿桌面处理器。这代处理器的特点是CPU部分采用两种核心,P-core和E-core。这种设计在PC世界里很少见。
其中的E-core乃是“刷分神器”,尤其是在Cinebench这样的测试中。E-core作为占die面积显著更小的一种核心,也让今年Intel处理器的核心堆砌显得比以往方便得多。所以今年酷睿i9-12900K也很轻易地达成了16核心设计,隔壁AMD再也无法秒天秒地秒空气了。


2017-2018年,AMD通过Zen架构的推出,在PC处理器领域打了个翻身仗,让Intel这些年的日子越来越不好过。但我们此前的分析文章也不止一次地提到过,AMD Zen就核心架构层面也没什么了不得的,其核心层面的性能顶多也就是赶上了Intel。
AMD这两年让Intel真正不好过的是处理器的多核性能。说穿了就是AMD家PC处理器的核心数之多,能把Intel打得找不着北。当然就个人应用领域,很多CPU核心未必有太大实用价值,但跑分和媒体都喜欢嘛(误)。
这里就有个疑问,AMD给自家处理器堆了这么多核心,Intel为什么不也这么干呢?偏要等到今年出了混合架构,才开始通过E-core堆出更多核心?很多同学首先想到的,应该是Intel工艺暂时落后于台积电的事实。这的确是一个因素,更大线宽的工艺,堆起核心来自然要耗费更多的芯片面积——也就是成本;而且对功耗也相当的不利。
但实际上还有一些架构层面的原因,是相关于核心之间的连接方式的。
Intel的环形总线
Alder Lake架构分析文章提到过处理器内部的“Computer Fabric”是dual-ring双环设计(如下图),带宽是1000GB/s。这其实是当代PC处理器的常规设计。简单理解,就是将所有处理器核心挂在一个环上,当然这个环上还有一些别的模块(比如GPU、I/O)。核心之间的通讯就通过环形结构进行。
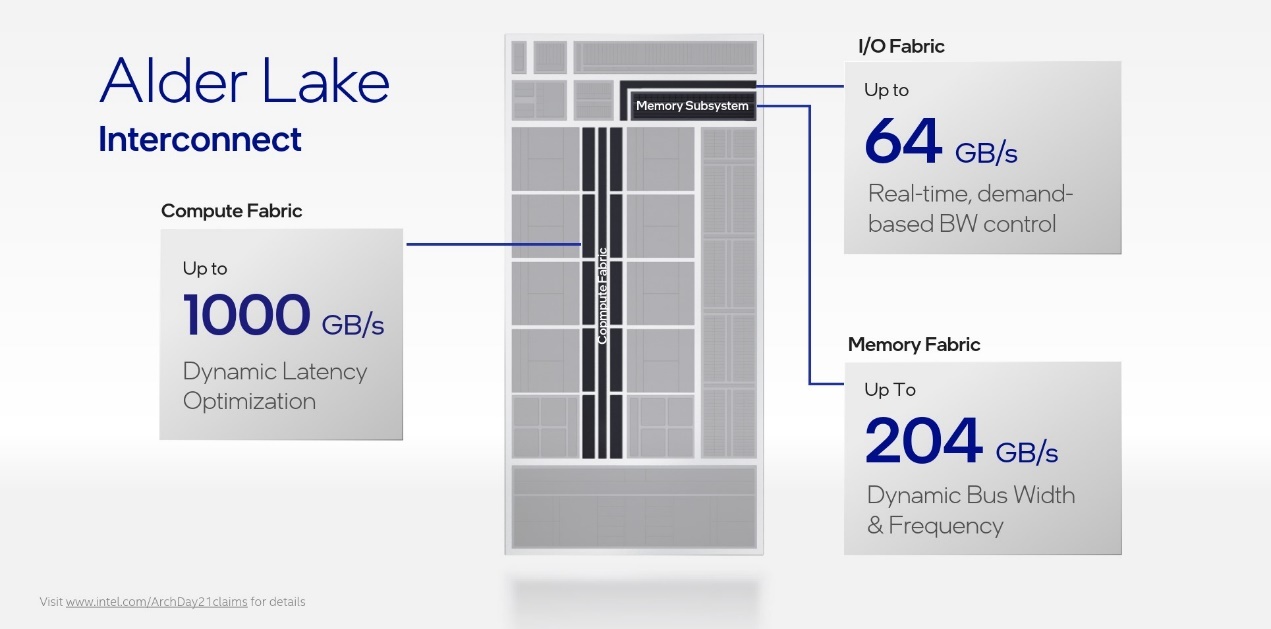
这种设计最早可以追溯到2008年Intel的Nehalem架构处理器(当年确立酷睿处理器地位,把AMD彻底甩在身后的一代架构)。
更早年die内的核心间连接方式不是这样的。如果只考虑CPU核心的话,两个核心直接连接即可;如果是3个核心,则两两互联,亦不是问题......不过此处还需要考虑到需要与核心产生连接的,远不只是处理器核心。
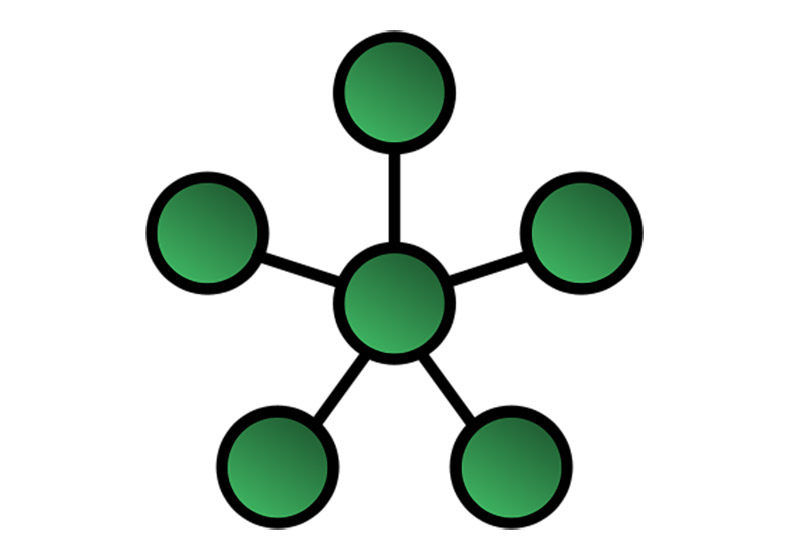
在只有1个核心的情况下,其他周边节点可以星型的方式,围绕核心做星型连接。双核大概可以采用双星结构。但随着核心数增加,这种连接关系就会显得越来越复杂。
在处理器一个die内的核心数达到4个的时候,核心之间的连接就会产生分歧了。以全连接的方式连接,则核心之间需要两两相连——听起来似乎也还好。而当核心数增加到6个的时候,全连接的复杂度显著增加。
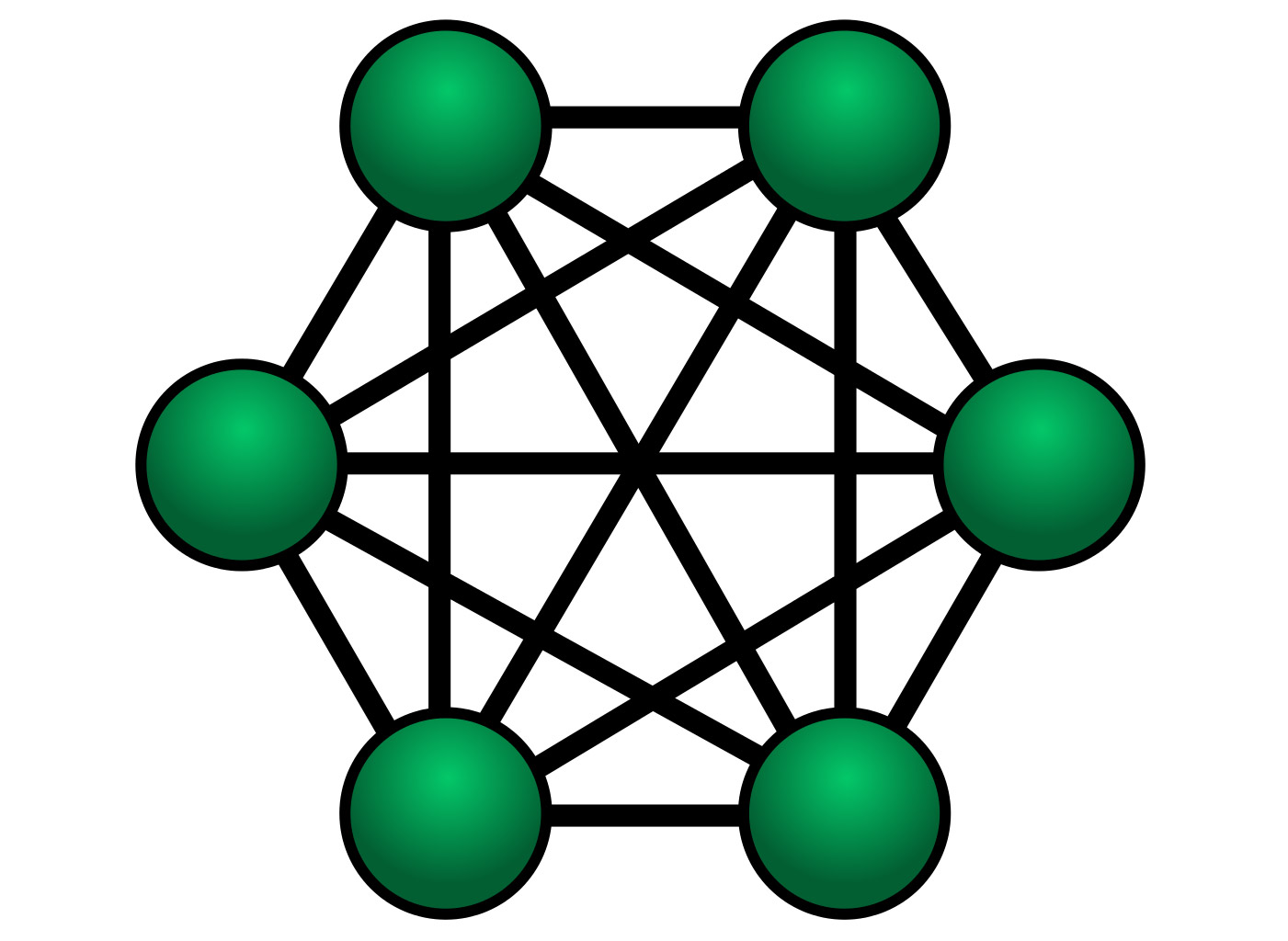
6核心全连接
这种全连接方案当然能够达成最高的互联性能,包括带宽和延迟。但全连接也意味着设计复杂度、成本和功耗的增加。这个时候环形总线就成为一个不错的选择(如下图),尤其这种方案对于增加核心数更友好——把模块加上去就好了。不同模块的互联起码是符合直觉的。
Intel的环形总线Ring Bus通常是双环,数据流向是两个方向。环形总线和全连接方案相比,每两个模块之间的平均通讯距离实际上是更长的,最长的时候可能需要经过半个环。这就产生了延迟、带宽方面的变数。
这种Ring Bus在实施复杂度、成本和功耗方面都达到了相对的平衡——尤其在核心数更多的情况下。如果4个模块做全连接,那么每个模块都要做3个连接,每两个模块之间的通讯长度是1跳。这4个模块若为双向环形通讯,则每个模块做2个连接,平均每两个模块之间的通讯长度是1.3跳。达到6个模块的时候,全连接每个模块就要做4个连接;环形连接时,每个模块依然是2个连接,平均通讯距离为1.8跳。
Ring Bus
如前文所述,在考虑当代PC CPU多核心(比如现在高端桌面处理器是8个核心),以及DRAM控制器、I/O、核显之类的构成时,全连接的复杂性将变得难以为继。环形总线至此都还是权衡利弊的方案。
但环形总线也不是万能的,当核心数进一步增加时,问题就会变得比较大了。在核心数增加到10个,甚至12个以后,ring也将变得很大,核心间的延迟将进一步增大;要喂给核心的数据带宽需求变大。
这其实也是Intel当代的酷睿处理器很难在核心上可与AMD Ryzen去比的重要原因。所以10代酷睿处理器最多塞了10个核心,而11代则只塞了8个核心(与工艺限制有很大关系)。单die之下,再塞核心一方面会让die size变得过大,影响良率和成本;另一方面核间通讯效率也会大幅下降。

12代酷睿i9-12900K die shot,注意看蓝色的8个P-core,和青色的8个E-core
所以12代酷睿是怎么做的呢?目前12代酷睿桌面处理器最高端的型号i9-12900K包含8个P-core与8个E-core。其中E-core的面积效益非常高,占die面积比P-core小多了。更重要的是,在Intel的设计中,每4个E-core构成一簇,在Ring Bus环形总线上才相当于一个stop。于是8个E-core,实际上总共只占了Ring Bus上的2个位置。加上Intel 7工艺的加持,12代酷睿达成了性能、成本和功耗的均衡。
这算是这一轮PC处理器核心大战中,Intel有喘息之机、扳回一城的重要战果。
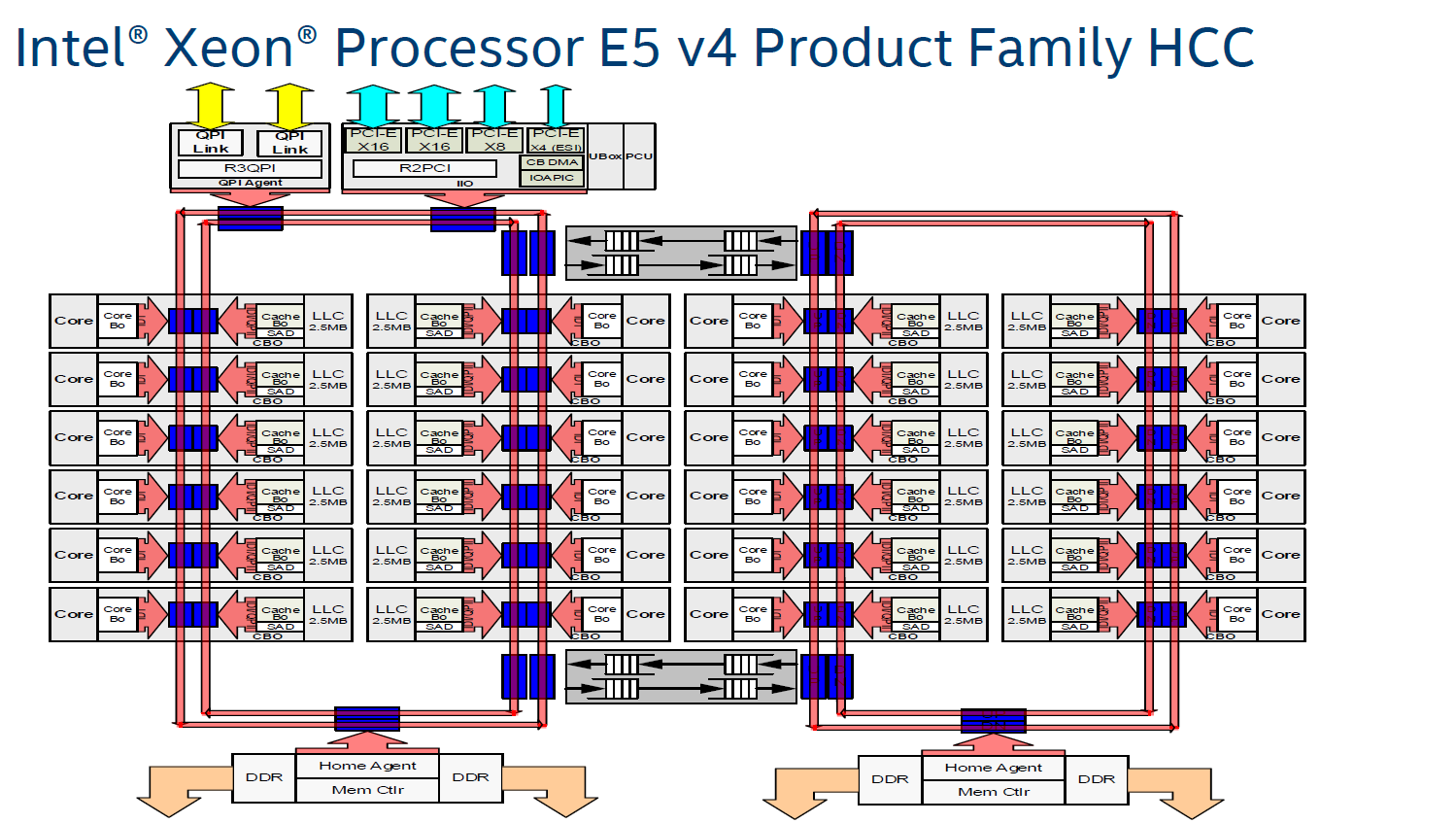
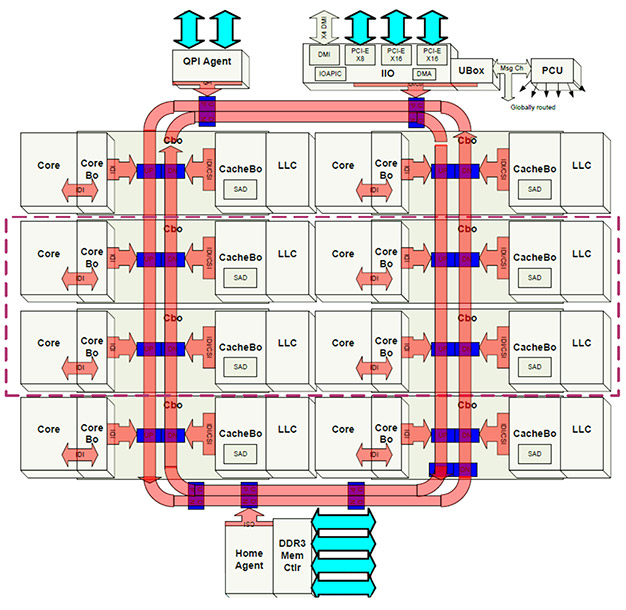
实际上,对于服务器CPU这类核心数明显又更多的处理器而言,Intel也尝试过用两个ring(两个双ring),然后把两个ring再连起来的方案。在至强处理器(Broadwell-EP)这一例中,每个Ring Bus都挂上了12个核心,当然还有外部存储、I/O相关的模块。左边这个ring上挂了17个节点。左右两个ring则用双向Pipe Line连接。
另外,针对多模块互联,Intel其实也尝试过其他的方案。通常是介于环形总线和全连接的方案,主要都是为了权衡功耗、性能和成本。但当核心数再行增加之时,又该怎么做呢?
mesh与crossbar方案
参考Arm面向服务器的Neoverse处理器IP:比如Neoverse N1,就核心微架构层面,它与手机上很多人熟知的Cortex A76是比较类似的,只是因为服务器处理器核心数可能会非常多(Arm这两代的最高配都预设了128个核心),自然不可能用环形或全连接方案。
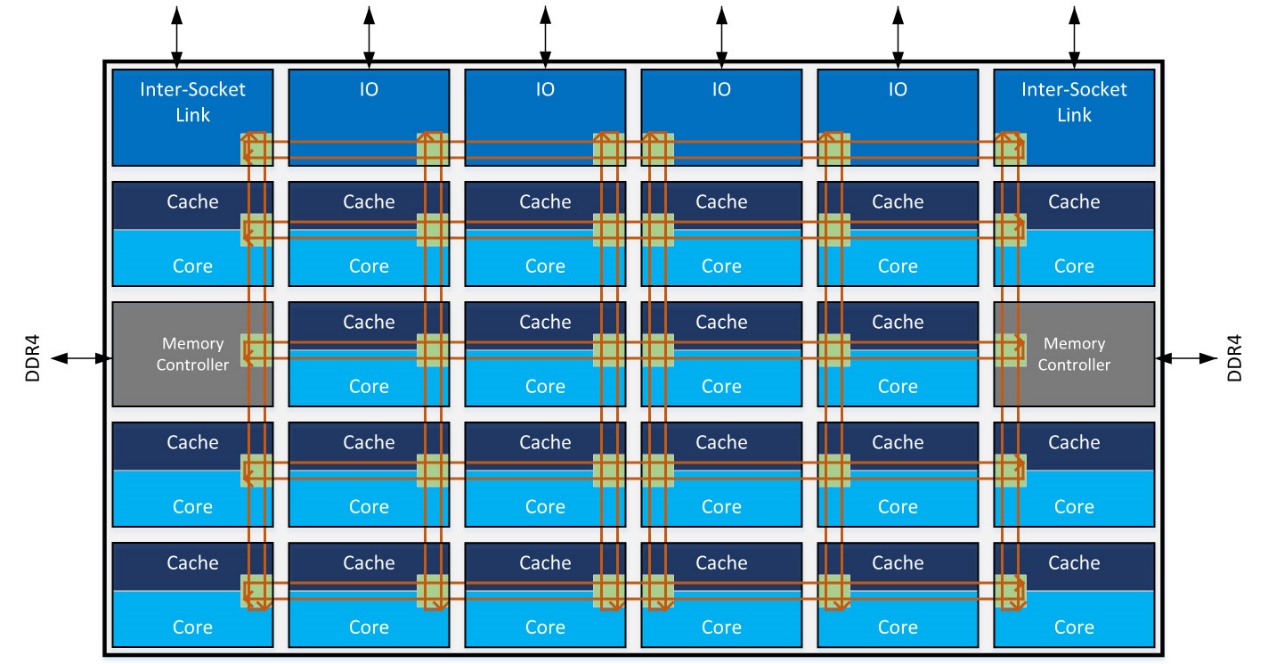
此前我们针对Neoverse N1、N2的解析文章都谈到过连接用到的mesh网络;当然x86现在的服务器处理器普遍也都是这么干的。在2D mesh网络连接下,大致连接方案如上图所示,就像围棋棋盘一样互联。
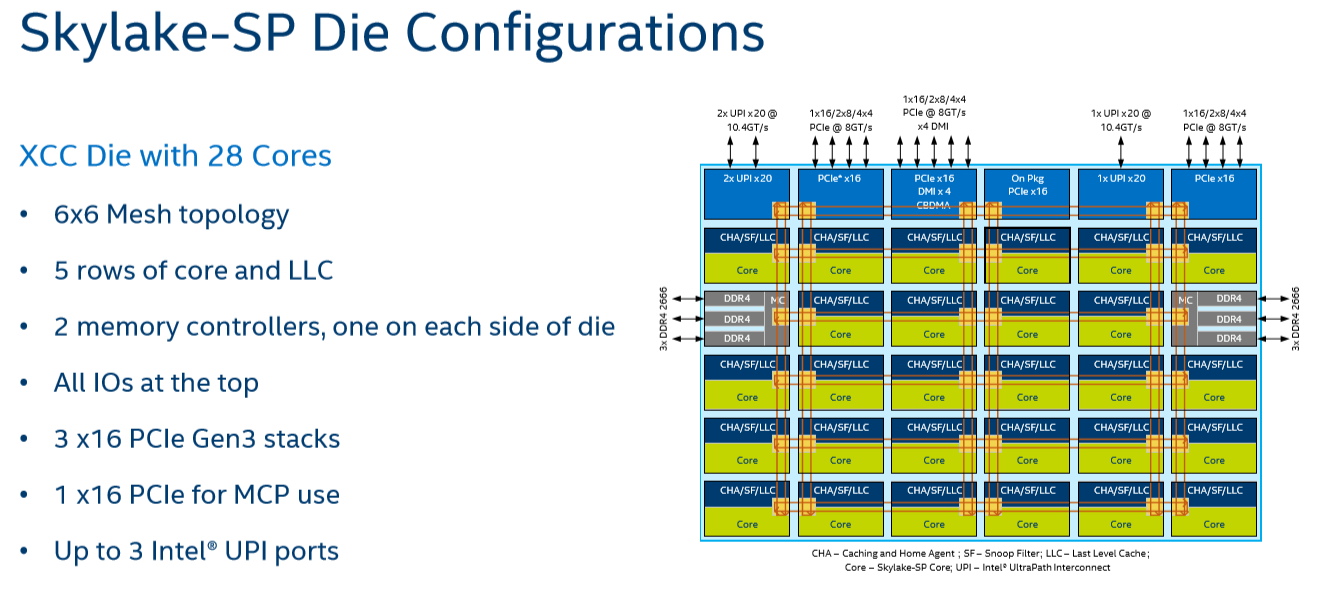
这种方案在不同节点之间的延迟上依然存在变数,对于某些较重的数据流事件而言,数据可能需要经过比较长的路径才能到达目的地。以Skylake-SP为例,当时mesh和L3 cache跑在1.8-2.4GHz的频率上,低于同期的ring运行频率(Boradwell-EP)。Mesh对于更多核心的支持本身也会增加延迟。比如说某个核心要访问临近的L3 cache,每1跳要多1个周期。最坏的情况是,从右上角的节点,获取左下角的节点数据,需要13个周期。
其实Skylake-EP问世之际采用mesh连接方案,虽然比此前的Broadwell-EP多连了几个核心,但平均延迟其实跟后者是差不多的。
不过这些都会随着核心数的进一步增加而显得没那么重要。Mesh连接的layout简单,而且灵活性、可扩展性很强——这是Ring Bus无能为力的,起码对于再增加核心数有着更高的适应性。
如果仔细对比:在处理器核心数再增多的情况下,采用两个ring,以及采用2D mesh网络相比,平均两个核心间的通讯,以及核心与DRAM、I/O的通讯会显著更优。前文中至强处理器那种两个ring的方案,尤其某个核心如果要跨越ring,去访问另一个ring上的内存控制器,则所需的周期开销会非常巨大。
另外,在2D mesh之外,现在探讨3D mesh的文章似乎也都很热门。即在chip-on-chip堆叠方案开始广泛采用之际,mesh网络在interposer硅中介层实施,也就能够进一步降低核心通讯的延迟。
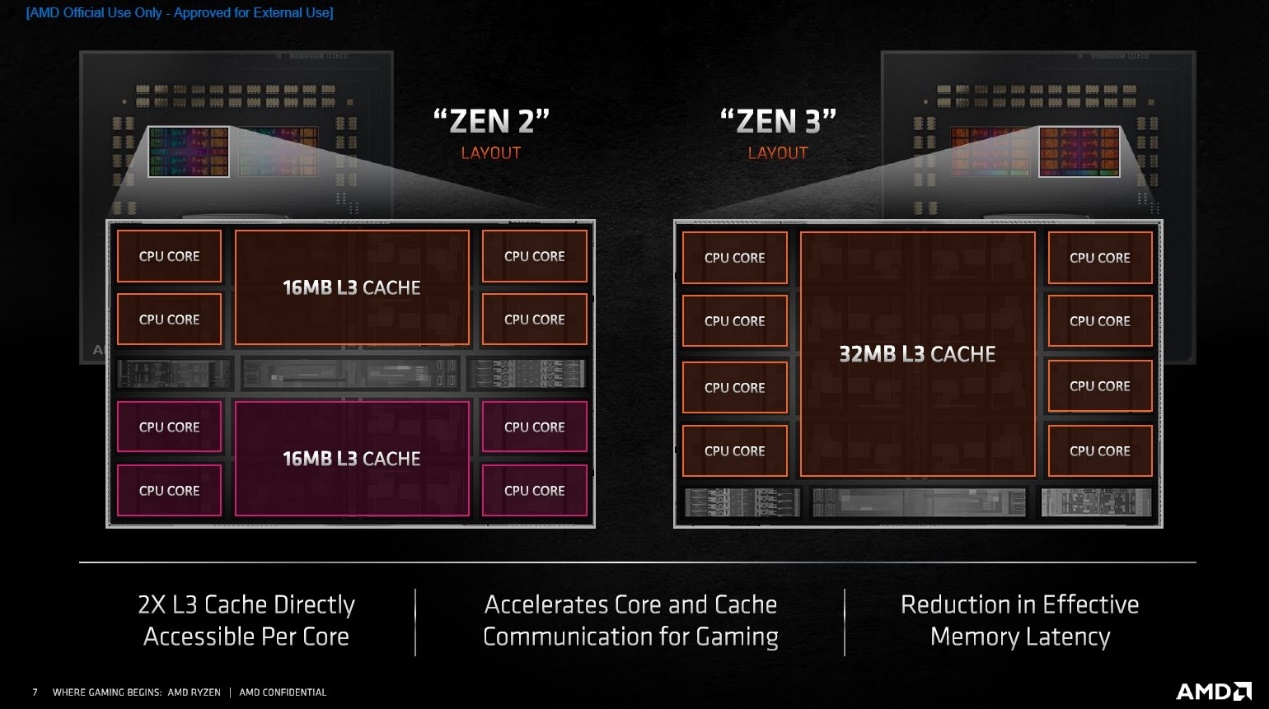
AMD Zen架构处理器的一个簇(CCX)
那么说回AMD,AMD在PC处理器上用的是mesh网络连接,所以堆核心才那么容易吗?并不是。AMD当代Zen架构处理器还是比较特殊的,我们在此前的文章里曾经介绍过。
从比较高的层面来看,AMD的PC处理器现在普遍在采用chiplet方案。也就是每个芯片是由好几片die(或chiplet)构成的。每个die上都有几个核心;然后通过一枚I/O die作为通讯中心,连接所有包含了处理器核心的die。
具体来看,Zen 2架构处理器,每4个核心组成一个簇(CCX),每2个簇组成一个die(CCD)。而两个或更多的die构成一颗完成的芯片(当然还要加一个负责通讯的I/O die)。到了现在的Zen 3,则每8个核心构成一个簇。
像AMD Ryzen R9(5950X)能堆出16个核心,这种基于chiplet的方案首先就是功不可没的。基于chiplet的方案,至少从工艺层面上就摆脱了核心数增多让die变得过大导致成本急剧增长的问题,因为把整个芯片切分成了很多的小die,那么在生产制造时也就可以增加良率、降低成本。这和Intel把那么多核心都塞到同一个die上的方案不一样。(虽然笔者认为,AMD的这种做法对PC行业本身是否真的有很好的正向价值,是值得商榷的)
当然,这只是制造层面堆核的基础。我们其实并不清楚AMD Zen架构处理器的核心之间究竟是如何通讯的。有可能每个簇(每8个核心)之间采用的是Ring Bus,此前AnandTech采访AMD问及其簇内部的8个核心是否是全连接的,AMD回答称并非如此,但比较接近。所以可能是某种介于环形和全连接的方案。

看看下面的I/O die
而die之间又是怎么连接的呢?从高层级来看,AMD现在的处理器的计算die之间当然需要经由I/O die来做通讯。而这个I/O die,在扮演的角色上其实更像是crossbar:就像一个路由器或者指挥中心一样,负责不同网络之间的通讯。
其实在更高层级上,物理外置的crossbar比较具有代表性的如英伟达的NVSwitch:将多GPU连在一起——可能层级有差异。不过crossbar内部总是采用某些连接方式,比如说mesh;从抽象维度来看,每个节点到crossbar都只需要1个连接,但其能够实现的带宽、效率仍然可能是可观的。
AMD Zen架构处理器的I/O die连接所有的计算die,这是个Ring Crossbar结构设计。AnandTech在探讨文章中提到,I/O die的这个环可以挂8个stop。在ring连接之外,某些stop之间也会有连接——所以不同节点之间的通讯延迟也存在差异,以及I/O die也并不是单纯的环形连接。似乎将计算die内互联,和die间互联考虑进来,这样的方案也还是比较复杂的。

其实AMD当前做多die封装的技术并不先进,未来基于硅中介的2.5D封装才是此间的趋势,虽然成本也会更高。这一点,此前谈台积电与Intel先进封装技术的文章都已经分析过。加上3D堆叠垂直封装,可能未来基于chiplet堆核心的空间还是很大的。
而且不仅是CPU,今年随同12代酷睿一同发布的、Intel面向数据中心市场的GPU Ponte Vecchio才是chiplet方案的集大成者吧。要看到Intel持续在PC CPU上堆料也不会遥远。虽然我们始终觉得,堆核心对个人用户而言存在更为严重的边际递减效应。核心数量大战未见得是好事。
- 作者不知道AMD Infinity fabric的情况下也可以写科普文?厉害了ee times china
