
英伟达每年GTC上都在说,针对相同的硬件,只需要升级软件就能获得性能方面2倍以上的提升——比如对科研人员而言,通过升级软件物理模拟(simulation)时间就能缩短一半。这是比半导体行业摩尔定律还要彪悍的存在。
这其中应当存在一个前置条件,就是是否很多科学计算库原本就是不完善、低效的。在英伟达涉足这些行业之后,各种库、编译器、中间层得到优化,硬件性能才得以充分挖掘。2倍甚至更多的性能提升也就不足为奇了。此前HPC领域有业内人士告诉我们,的确是这样。比如做计算化学的研究人员,不要期望他们能够精通底层优化。这样的前置条件,为英伟达扩展生态创造了大有潜力的发展环境。

但事实上,情况可能比我们想象得还要复杂。黄仁勋在这两天的GTC上提到,实现所谓科学计算“Million-X百万倍”性能飞跃的几个重要条件。除了英伟达的“加速计算”之外,另一个重要的推动力是AI——深度学习编写软件能够具备高度并行性,这就更有助于挖掘GPU这样的硬件算力了。
我们认为,这一畅想未来还能扩展到科学计算之外的领域。虽然带来的性能提升在各行各业或许无法达到“Million-X百万倍”的程度,软件上的效率优化也将会显而易见。黄仁勋在主题演讲中说:“我们拥有超过150个SDK,为游戏与设计、生命与地球科学、量子计算、AI、网络安全、5G和机器人等行业提供服务。”
今年GTC,英伟达又推了65个新的(或更新的)SDK。举个例子,设计自动化是现在英伟达也在涉足的领域:Synopsys、Cadence、Ansys、Dassault如今都是英伟达这方面的客户——主要是对散热、机械结构及针对RFI与信号完整性的3D EM的模拟。
说起来,英伟达通过这样的生态扩展,构造巨无霸式的生态帝国,主力都是软件能力;GPU硬件在此倒显得没那么重要了。这也是GPU能够对如雨后春笋般涌现AI芯片实现降维打击的基础。这更坐实了英伟达不是家芯片公司的事实......
本周的GTC大会,我们自己总结黄仁勋的主题演讲主要涵盖了几个方向:科学计算加速、AI、Omniverse、虚拟形象(avatar)、机器人/自动驾驶汽车。本文我们主要谈谈科学计算加速、AI,其他几个部分可点击这里查看。后续针对黄仁勋的采访,我们还将做一篇报道。
2.5亿倍的性能提升
CUDA生态是众所周知的,就如文首提到的——其中各种资源应当是现如今英伟达GPU生态的核心所在。其实我们始终认为,GPU作为如今加速计算的通用硬件,服务于各行各业,AI只是其中的一个分支。只是因为AI涉及到的产业如此庞大,致AI被单独划分出来。所以AI部分,后面的段落还会做进一步解释。
有关加速计算,这次黄仁勋主题演讲中的发布包括有:
● 发布3个新的加速库:ReOpt(针对如车辆路线安排、仓库拣选与包装的加速求解器)、cuNumeric(针对NumPy的插入式加速库)、cuQuantum(以及发布cuQuantum DGX设备,用于加速量子电路模拟——cuQuantum DGX设备明年Q1推出)
● 宣布推出Nvidia Modulus,这是个用于开发Physics-ML模型的框架,使用物理原理以及principled physics model的观测数据来训练Physics-ML模型。(这个好像应该放在AI里面,不过因为它与科学计算紧密相关,所以就放在这部分讨论了)
简单说一说:cuQuantum DGX是为造量子计算机存在的东西。据说对于量子傅里叶变换、Shore算法、谷歌Sycamore的计算,传统方案要几月才能完成,cuQuantum DGX只需要几天。而针对Phython NumPy的cuNumeric加速库,能够实现任务级并行、且乱序执行,还支持GPU扩展,扩展效率也不错。ReOpt则可用于路径规划,比如达美乐送披萨,最后一公里配送就能实现最优路径规划。
看不懂是啥不要紧,毕竟GPU加速涉足各行各业,唯有相应行业的人才会知道英伟达发布的某个组件究竟是做什么用的(而且我们也经常怀疑,黄仁勋在演讲中常提到很多自然科学相关知识,他自己真的理解吗?划掉)。这些都是所谓“百万倍性能提升”的组成部分——当然这里的百万倍性能提升特指科学计算领域。
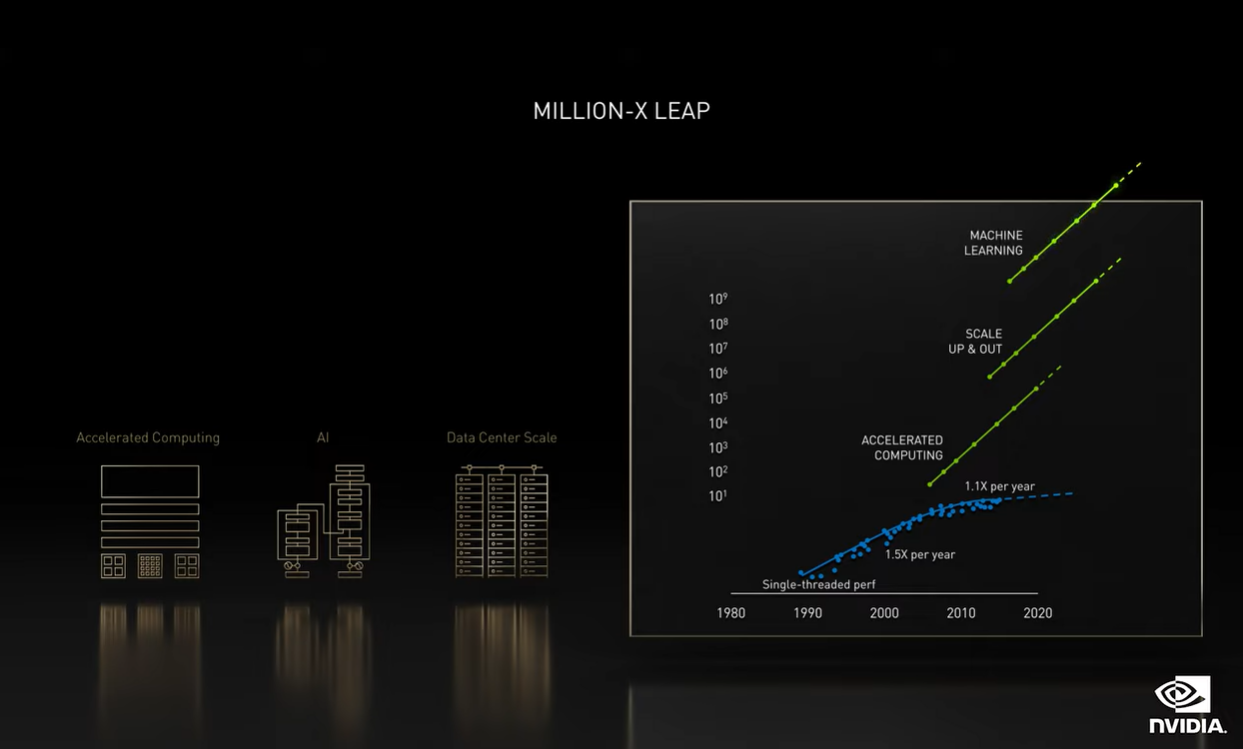
接下来就详细说说这次GTC上的一个大热门,“Million-X百万倍”性能飞跃——科学计算领域;它本质上也属于英伟达加速计算的组成部分。黄仁勋表示,实现科学计算百万倍性能提升,包含三个方面。
首先是加速计算,即上图中最下方的绿色线条(蓝色线条看起来或许是摩尔定律)。这其实是CUDA的基本实现。黄仁勋说:“加速计算正重塑从芯片和系统、加速库,到应用的全栈式计算,这会带给我们50倍的提升。”
第二,我们认为应该是数据中心的规模化扩张(图中的scale up & out,英伟达的官方翻译似乎有点问题)。这是实现AI的先决条件,也是改变编写软件范式的基础。
第三,就是AI。“从根本上改变了软件。深度学习编写的软件具有高度并行性,这是其更有助于GPU加速,并且可扩展到多GPU和多节点上。”如文首所述,这或许不仅是科学计算,而是全行业的发展趋势。
英伟达提供的数据是,如果扩展到DGX SuperPod这样的大型系统,则速度提高5000倍;而深度学习编写的AI软件,速度又会比人工编写的软件快1000-10000倍;那么加上前面的50倍,总共就是2.5亿倍的性能提升。
这虽然是很理想的一个预测,但大方向我们认为是相当正确的:即便2.5亿这个数字大概还可以再讨论讨论。而事实上HPC、科学计算领域有这样的性能需求,一点也不算贪婪。其一大价值就在于提高模拟/仿真性能。教AI模型学习物理,并做出符合物理定律的预测,也就让AI真正在模拟方面做出了贡献。

举两个例子。其一是药物研发中的“虚拟筛选(virtual screening)”。包括解码人类蛋白质、有效化合物与蛋白质结构相遇涉及到的分子模拟等过程。据说其中的某些过程,可以从原本需要3个月缩短到只需要3个小时。
黄仁勋有句话让人印象很深刻,“我们正在见证生物学革命的曙光。”此前生物学革命一直被很多人称作第四次科技革命。不过生物学的发展速度之缓慢,应该是很多人都了解的。或许AI真有这样的能力,实现某些尖端领域的快速突破。前提就是电子科技行业,“2.5亿倍”性能提升。
第二个例子是气候模拟与预测。目前人类没有能力预测几十年后的气候,因为算力限制,气候模拟的规模是现阶段电子科技无法想象的。长期气候预测需要对地球大气、海洋/水域、冰、土地和人类活动的物理特性及相互作用进行建模。而且需要1-10米的空间分辨率,加入大气云对太阳辐射反射回太空等的影响。
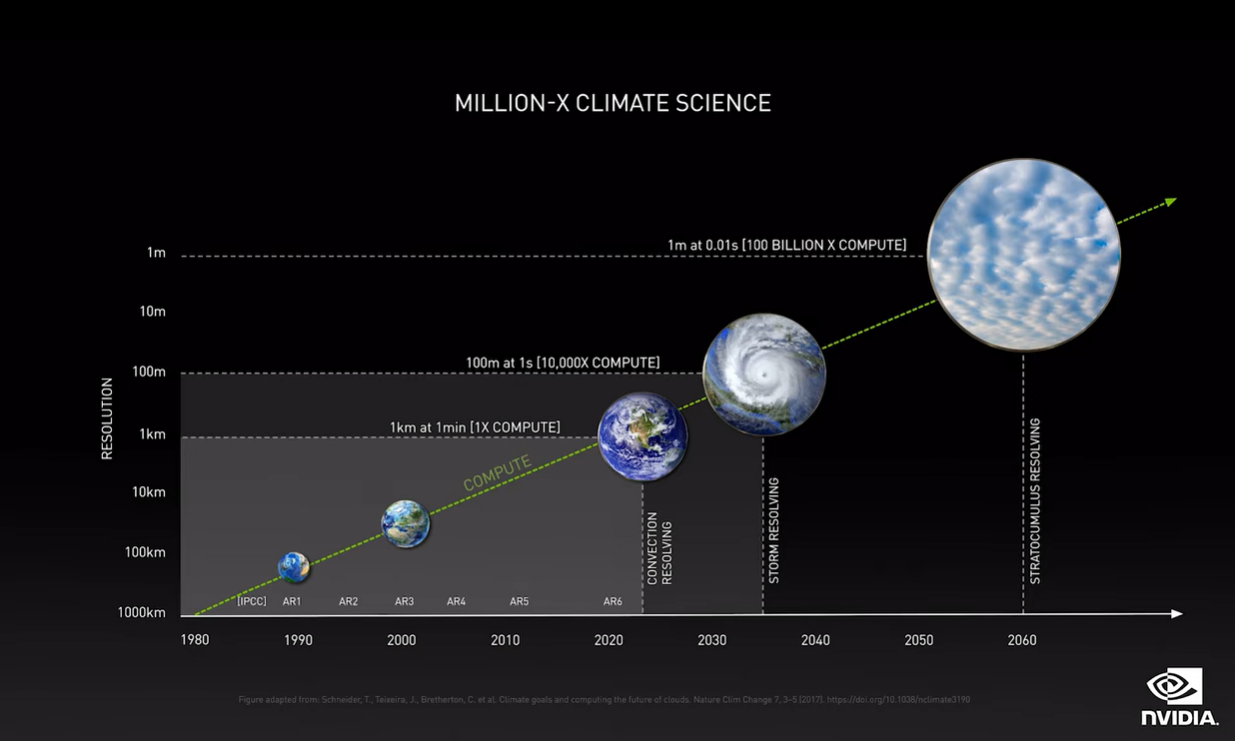
所以英伟达这次宣布推出Nvidia Modulus。这是个用于开发physics-ML模型的框架,可在多GPU、多节点上做训练。黄仁勋说,由此生成的模型,其物理仿真速度比模拟快1000-10万倍。用Modulus打造地球digital twin模型,就能解决气候科学的一些问题。
据说研究人员用ECMWF(欧洲中期天气预报中心)的ERA5大气数据去训练一个physics-ML模型,得到的模型能以30公里的空间分辨率来预测飓风的严重程度和路径。而且原本需要7天完成的预测,现在只需要1/4秒(?)。或许几年以后,Omniverse中的地球digital twin,加上一些Physics-ML模型,就能预测气候了。
这就是软件和AI的威力。
有关AI的一些新发布
AI始终是这两年英伟达发展的重头戏,毕竟现在谁家出个AI芯片都不忘在PPT上揶揄一下英伟达。这其实也从反面印证了,英伟达的GPU与AI生态对于一众AI芯片厂商而言,的确构成了白色恐怖。
本次GTC上,主要相关于AI的发布包括:
● 宣布与DGL(Deep Graph Library)社区合作,加速GNN(Graph Neural Network)处理——今年12月“提供抢先体验”;
● 宣布推出Nemo Megatron,这是个专门用于训练十亿、万亿量级参数LLM(large language model)模型的框架;
● 宣布TensorRT原生集成到TensorFlow和PyTorch中;(“1行代码,机器学习开发者就能获得3倍加速”)
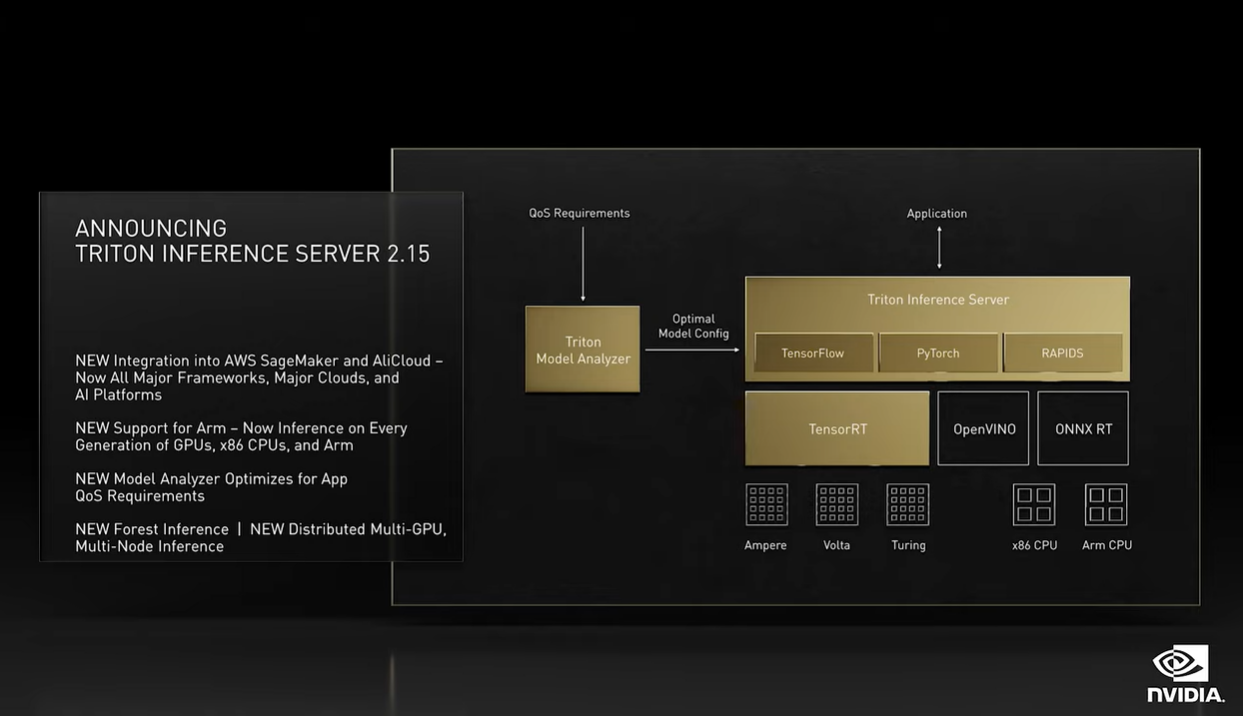
● 宣布Triton推理服务器能够同时支持深度学习、机器学习模型;Triton推理服务器2.15适用于所有推理工作负载:包括“对所有模型、各种框架、多查询类型的推理,机器学习和深度学习、面向所有平台、云、本地、边缘和嵌入式系统,多GPU、多节点,在CUDA、x86和Arm平台上”;
● 宣布LaunchPad,这是与Equinix合作的服务项目,在全球范围内面向企业数据中心“预安装和提供Nvidia AI”。目前覆盖地区暂不包括中国。

英伟达在AI方面的生态扩张,是此前我们花了很多笔墨去描摹的。上个月的《国际电子商情》封面故事《AI芯片竞争红海之下的生存之道》,我们还提到了英伟达对于各AI芯片公司造成的阴影。英伟达FY2022 Q1/Q2的营收较去年同期分别增长84%和68%,净利润增长109%和282%。
如今英伟达在GTC之上的AI相关发布,绝大部分都是生态完善和补全。说穿了就是持续扩大市场覆盖范围和优势。比如说GNN(Graph Neural Network)主要是学习关系(relationships)的一种神经网络,目前已经是金融服务、药物研发、数字生物学和网络安全的首选模型。
所以英伟达在这方面很自然而然地有了动作。“我们正与DGL社区合作,以加速GNN处理,就像我们对CNN、RNN和Transformer所作的一样。”DGL是用于在现有深度学习框架之上,实施GNN的一个phython库。黄仁勋列举PayPal(欺诈检测)、亚马逊(滥用与欺诈检测)、Pinterest(搜索与推荐)都已经从中获益。

另一个AI能力补全的例子:黄仁勋这次特别谈到了Transformer。搞AI的应该都知道Transformer的价值。黄仁勋提到训练LLM(大型语言模型)是耗时、耗力,而且需要“强大的信念和专业知识和优化堆栈”的过程。
所以英伟达这次发布了Nemo Megatron。这是个训练“拥有数十亿、数百亿参数的语音和语言模型框架”。英伟达给的数据是,在500节点Selene DGX SuperPOD上,11天完成GPT-3训练。
在推理(inference)方面,“GPT-3有1750亿参数,需要至少350GB内存;Megatron有5300亿参数,需要超过1TB内存。”所以英伟达推出分布式推理引擎Triton,可在多GPU、多节点间进行分布式处理。原本双Xeon Platinum CPU服务器上,Megatron 530B模型推理需要超过1分钟,据说现在将其分布部署在2个DGX系统中,推理时间缩短至半秒。
LLM的发展潜力还是相当之大,“为新语言和新的领域,定制LLM,可能是有史以来最大规模的超算应用。”像电子商务产品与服务推荐这种万亿市场价值的领域,显然是发展AI的必争之地。
事实上,AI领域中的推理部分越来越不再成为英伟达的主场——这个细分赛道将来极有可能被各路AI专用芯片占据。推理和训练,在生态要求上还是有着比较大的差异的。
这一次新的Triton及推理服务器被黄仁勋称为“推理工具至今最重大的一次发布”。“今天我们宣布,Triton推理服务器能对深度学习(DL)以及机器学习(ML)模型进行推理。”“我们将Nvidia GPU向经典机器学习推理的世界开放。”
“通过一个推理平台,Triton就能实现在CPU和GPU上做DL和ML的推理。”新版本的Triton推理服务器则是“对所有模型、各种框架、多查询类型的推理,机器学习和深度学习,面向所有平台、云、本地、边缘和嵌入式系统,多GPU、多节点,在CUDA、x86和Arm上。”似乎通用性,以及AI生态霸权,仍然是英伟达期望扩大这一市场的关键。
黄仁勋在此谈到英伟达的优势是“凭借我们的全栈优化,和丰富的生态系统……”“购买多年后,我们的芯片不断变得更快更好…”原汁原味的说辞,这些年老黄其实反复在说(还有“买得越多、省得越多”…)。
生态帝国的持续扩张
有关AI的部分,英伟达这次还着重谈到的UCF(Unified Computing Framwork,统一计算框架)。英伟达将其放在了“边缘AI”范畴之下。黄仁勋对边缘计算的定义:“边缘计算的统一概念,是需要处理一系列任务的组合。包括传感器、高速IO、数据处理、信号与物理处理(signal and physics processing)、AI推理和计算机图形等。”
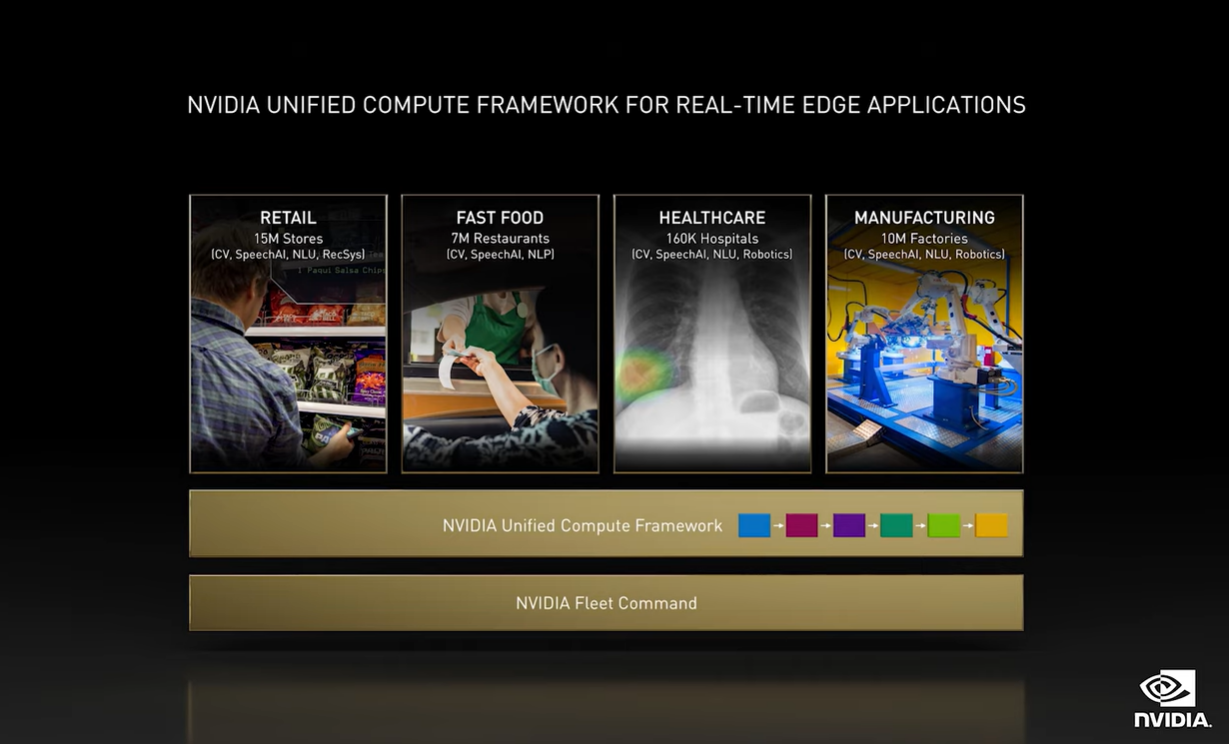
这个定义其实更多把边缘定在了机器人之类的应用上。UCF框架实际上是把专用加速器、CUDA GPU、Tensor Core AI、RTX图形处理、网络安全、高速IO等处理过程都串联起来,对容器、微服务进行编排。我们理解,这是对英伟达眼中“边缘AI”开发的全链条打通。比如通过UCF,可以比较简单地扩展对于摄像头、LiDAR、depth传感器、超声波、红外等的支持。
谈到边缘计算芯片,总也感觉这并非英伟达主场。但在AI生态上的呼风唤雨,仍然是英伟达在AI每个环节上都能说上几句话的关键。针对这一点,还是建议去看一看系列文章的另一篇《在元宇宙实现之前,有哪些工作要做?》,里面谈到了英伟达在边缘机器人方面的布局,“端到端机器学习循环”。
似乎我们已经不是第一次用“英伟达生态帝国”来形容其AI发展了,但这仍是这些年的事实。前一阵苹果发布M1 Pro/Max芯片版MacBook Pro,我们在讨论异构系统生态被苹果玩得风生水起。集成到SoC芯片上的GPU,搭配UMA,就能发挥那么强大的芯片性能。
但另一个问题随之而来,M1 Max上的GPU究竟能拿来做什么?这才是体现GPU生态价值的时候。这大概也是英伟达现阶段的主要价值所在吧。2.5亿倍的性能提升,也就是这个链条中的一个组成部分罢了。
有关本次GTC上其他几项重点,包括Omniverse、虚拟形象、机器人,请关注系列报道另一篇文章《在元宇宙实现之前,有哪些工作要做?》。

最后稍补充GTC上相关networking与cybersecurity的发布,因为不是本次我们期望报道的重点,所以仅在文末简单带过:
● 宣布推出 Nvidia Quantum-2平台,这是个400Gbps的InfiniBand平台,由Quantum-2交换机、ConnectX-7 NIC/BlueField-3 DPU,以及一套面向新架构的软件组成。其网络速度、交换容量与可扩展性,对于HPC系统而言很适用。其中ConnectX-7版本样品明年1月问世;BlueField-3样品明年5月问世;
● 宣布推出DOCA 1.2,主要是能够支持全新的网络安全功能。
此处有个亮点,Checkpoint、Fortinet、Palo Alto Networks等网络安全公司的NGFW防火墙服务预计都将基于BlueField做部署。这也算是英伟达生态扩展相当重要的里程碑了。当然,这是DPU生态组成部分。
责编:Luffy Liu

