
今年12代Intel酷睿桌面处理器(产品代号Alder Lake-S)宣传活动还是相当的盛大,除了10月28日全天的发布会之外,事实上在此之前的2天,面向媒体就已经有会前沟通会,以及演示活动了。
前两个月的Intel Architecture Day上,我们仔细分析了这代酷睿CPU处理器的两种核心架构,分别是代表性能的P-core(代号Golden Cove),以及代表效率的E-core(代号Gracemont)。此前的总结中我们就提到过,无论哪种核心,都称得上架构层面的大跨步。
其中P-core实现了相比上代(11代酷睿Cypress Cove核心)19%的IPC提升,比Skylake->Sunny Cove的提升还要大;而E-core虽然只是“效率核心”,但在单线程性能方面,同功耗下相比Skylake(10代酷睿)也有最多超过40%的性能提升,多线程最多有80%性能提升,功耗至多降低80%。


按照核心层面理论上的性能提升,要摆脱隔壁AMD的纠缠已经是小菜一碟。而且12代酷睿在绝对性能上应该是能够超过最近被吹得神乎其神的M1 Max的,虽然在功耗方面大概仍然会有一定的弱势。而Intel本身也对12代酷睿寄予了厚望,称其“重新定义x86架构的性能”,以及在宣传口号上提“异构强芯,一战封神”,并且把Alder Lake-S称作“世界上最出色的游戏处理器”。
在看本文之前,建议感兴趣的同学先去了解一下12代酷睿P-core与E-core的微架构分析——此前的这篇文章我们也谈到了对这种混合架构做调度的Intel Thread Director技术。本文从更系统的层面来谈谈12代Intel酷睿桌面处理器,以及我们在发布会上听到更多可在此给出的细节信息。
首发的几款Alder Lake-S新品
先来看看Intel本次首发的几款12代酷睿桌面处理器新品,具体如下图所示。包括了最高端8个P-core与8个E-core的酷睿i9-12900K(24线程);酷睿i7系列普遍是8个P-core加4个E-core(20线程);i5系列则为6个P-core加4个E-core(16线程)。

I/O的主要亮点包括对于DDR5(4800 MT/s)、PCIe Gen 5(16 lanes)的支持。还有相关睿频、缓存cache方面的信息此处也不再一一赘述,看图即可。值得一提的是,表格右边的功耗部分并未像往常一样,以TDP来标注。这将在后文中做解释。
Cache方面可做补充的是:Intel表示在混合架构之下,“对缓存进行了进一步加强。在增加P-core二级缓存与E-core每核二级缓存的情况下,我们同时在共享的L3智能缓存上也进行了增强和容量扩充。” L3 cache最高为30MB。
核显这次编号叫UHD Graphics 770,似乎相比去年的11代酷睿(Graphics 750)是有提升的,具体不知道提升了哪里。不过作为桌面处理器的核显,集成的Xe core核心数量应该会比较有限。
有关Alder Lake-S的其他信息还包括,采用Intel 7制造工艺(原10nm Enhanced SuperFin),LGA1700封装——也就意味着旧主板是不支持Alder Lake-S的。新主板搭配的是Intel 600系列芯片组。从主板厂在京东的销售信息来看,Z690芯片组的主板过几天才会上市。600系列芯片组的相关提升会在后文中详述。
有关E-core扮演角色的简单补充
此前虽然我们已经用了相当大的篇幅去探讨Alder Lake两种核心架构,以及配套混合架构的Intel Thread Director辅助调度技术。不过这次的发布会,Intel还是公布了一些新料。在谈具体的产品之前,与各位做简单分享。
首先是有关E-core在系统中的作用。鉴于隔壁Arm的宣传,我们习惯上把不同核心放在一起的这种架构称作“大小核”设计。所以大部分人对于Intel推混合架构中的E-core,是秉承其作为“小核心”的思路的。
E-core在整个系统中的确有提升效率的价值,比如在笔记本平台能够更大程度地节电。但就像此前架构分析文章中提到的,E-core在核心规模、宽度上远超Arm的小核心(如Cortex-A55),是个标准的乱序核。

而且这一代E-core(Gracemont)的单线程性能(SPECint)相比Skylake在同功耗下至多提升40%,多线程(4C4T)提升至多80%(同性能下,功耗降低80%)。当然这个对比是基于特定频率,而且并未涉及浮点性能。不过这也意味着12代酷睿即便是E-core,也在某种程度上比10代酷睿的“大核”性能更彪悍、更节能。
我们在这次活动上向Intel提了个问题,即P-core是支持超线程的。当某个任务有16个线程需要处理时,12代酷睿处理器会优先于将16个线程塞满8个P-core并启用超线程(8C16T),还是更倾向于8个线程给P-core,另外8个线程给E-core(16C16T)。
Intel院士Guy Therien在回答这个问题的时候特别提到,超线程通常能够带来30%的性能提升,但E-core却可获得80%的额外性能。“所以在填充核心的时候,首先会挑选P-core——因为其性能出色,随后就挑选E-core。在它们都被填满以后,才会考虑P-core的超线程。”
这个回答其实能够较大程度表明,E-core并非“小核”。Intel方面似乎一直在强调E-core对于多线程吞吐提升的价值。此前我们也说E-core以足够小的占die面积,实现了相对高效的多线程性能提升(四个E-core,面积差不多相当于一个P-core),绝对是Cinebench这类基准测试的刷分利器(妈妈再也不用担心隔壁chiplet-based堆核战术了)。
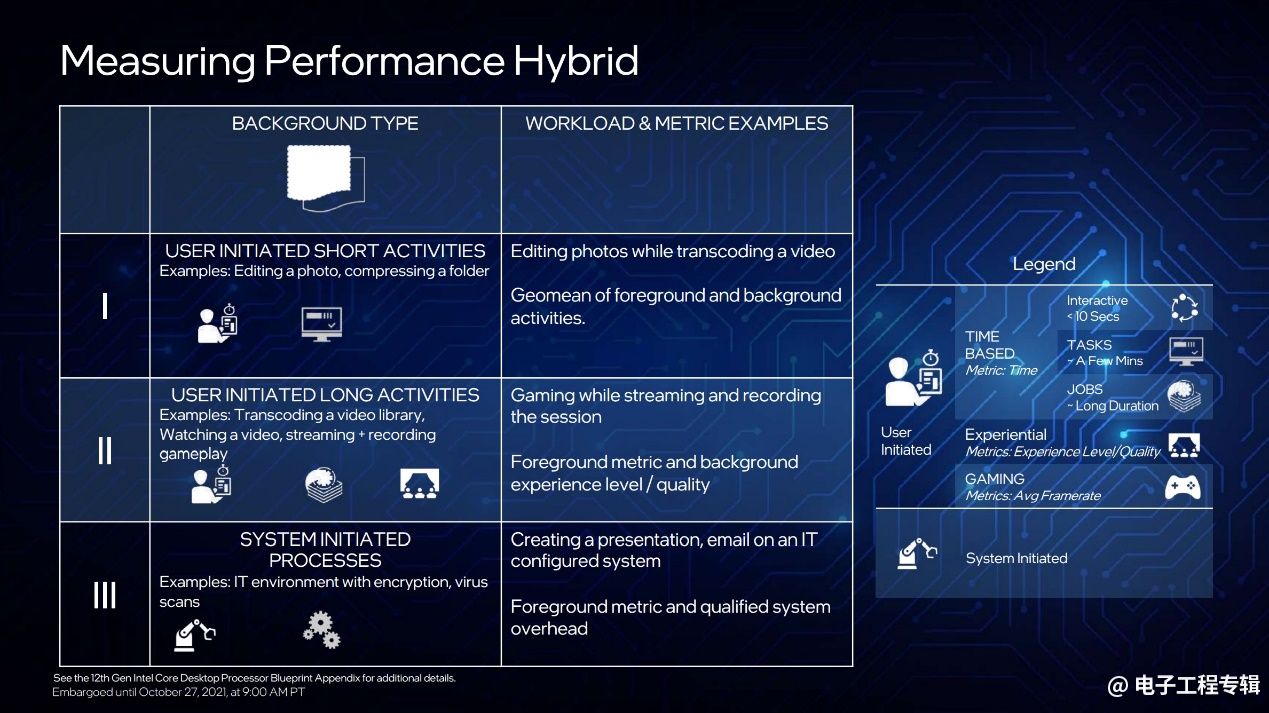
在demo演示中,Intel也分享了几个有趣的场景,包括一边玩游戏,一边在推流平台做游戏直播——则E-core将在其中发挥非常好的作用,游戏帧率相比以往会有个显著提升。演示中Intel用《骑马与砍杀》+在斗鱼平台推流——相比竞品(AMD Ryzen 5950X)的游戏帧率领先幅度可以达到40%左右;而在未开启E-core的情况下,领先幅度则在20%左右。
另外一个演示场景是,同时用Premiere和LightRoom——当后台做Premiere视频输出时,前台执行Lightroom照片转换工作,会有相当大幅度的速度领先。不过感觉大约很少会有人真的这么去用电脑吧。
Intel针对混合架构可实现性能提升的问题,预设了一些前后台或其他多任务工作场景,具体如上图所示。这其实也是桌面平台为何也用E-core的原因,毕竟它的确不是“小核心”。Intel这次在分享活动上说,一定要形容的话这俩应该是“大核”和“大大核”。
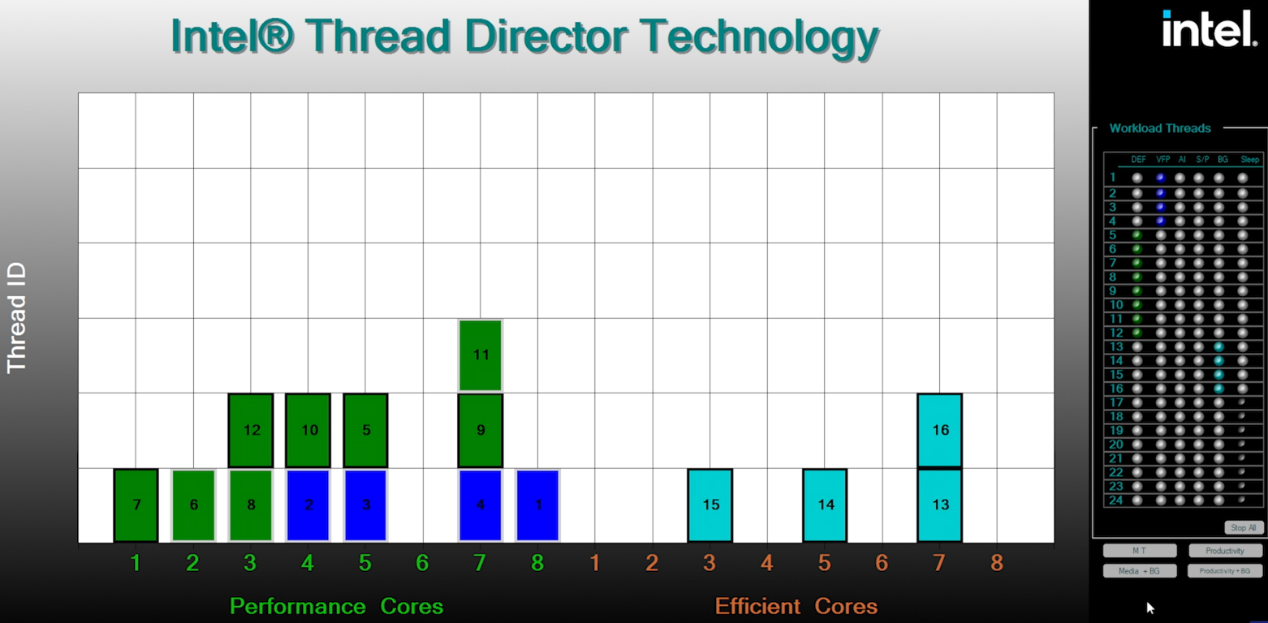
其实有关E-core、P-core以及超线程该怎么用的问题是相关于调度机制的。Intel Thread Director是Intel针对混合架构设计的一种线程调度辅助技术。因为不同核心构成同一个处理器,谁跑在P-core上、谁跑在E-core上,以及何时进行线程迁移,都是影响使用体验的关键。而Intel Thread Director在工作时可以给操作系统scheduler提供更细致的“hint”,帮助操作系统进行调度决策。
这也是Intel与微软Windows 11合作开发的技术,此前我们特别撰文谈了这项技术。其基本原理以及调度的一些典型场景,本文就不再细数了。
另一个值得一提的问题是这次的12代酷睿是不支持AVX-512与AMX(Advanced Matrix Extensions,一种AI加速单元)的。但实际上我们知道,应用于数据中心的Sapphire Rapids支持这两大特性。这表明这代P-core(Golden Cove)在设计上是有AVX-512与AMX硬件基础的。
而12代酷睿之所以不支持这两者,最大的原因应该是E-core不包含对AVX-512与AMX的硬件实现。基于一般情况下,同一颗CPU中,不同架构的核心需做到相同的指令支持这一点,12代酷睿处理器芯片也就不再支持AVX-512与AMX了。
所以我们问了Intel,未来是否有计划推出仅包含P-core(而不包含E-core)的PC处理器。Intel对此表示需要等待后续公布的消息。另外关于能否通过关闭E-core来开启P-core中的AVX-512和AMX特性的问题,Intel的回复是“不能”。
有关Alder Lake-S的性能提升
这代P-core(Golden Cove)相比11代酷睿核心(Cypress Cove)在IPC方面有19%的提升,这一点此前分析P-core架构的时候已经谈到过了。隔代19%的IPC提升还是相当耀眼:Golden Cove作为微架构基础,未来应该会在Intel后续的处理器产品中延续比较长的时间。这其实也是12代酷睿有革新意义的原因所在。
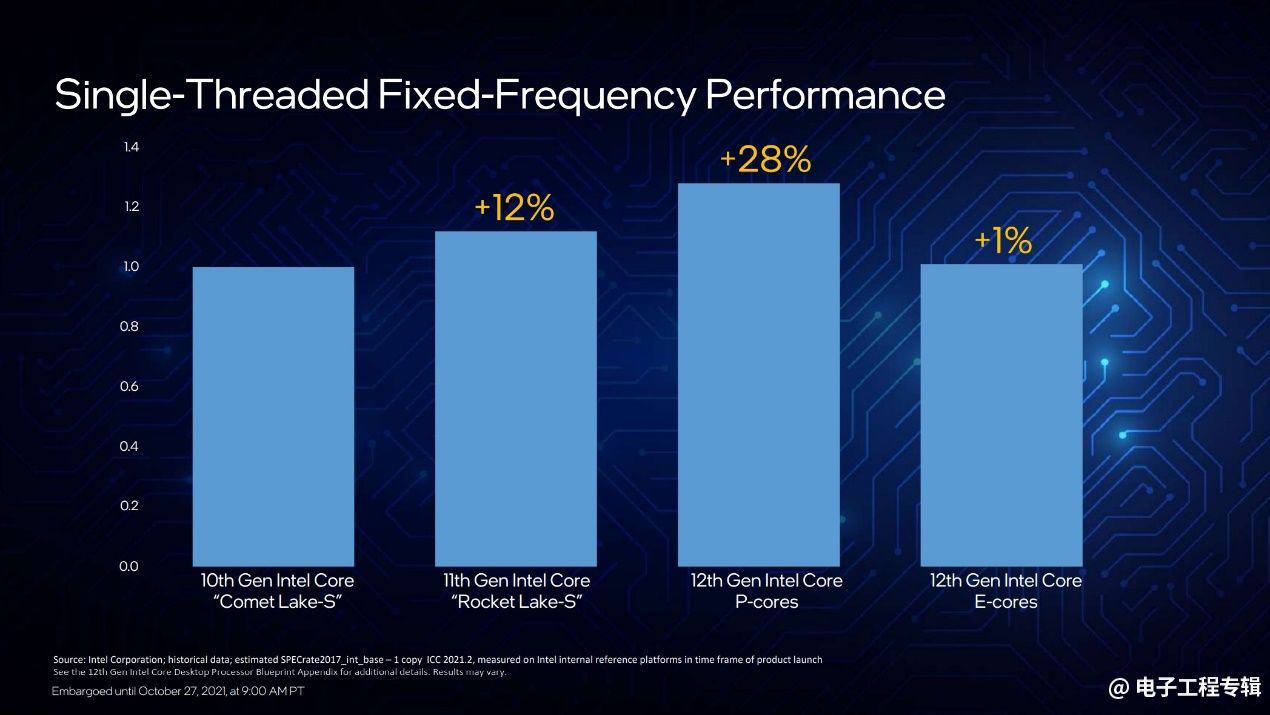
这次Intel也给出了更多的数据,上面这张图是以10代酷睿(Comet Lake-S,Skylake核心)为基准,在固定频率下,整数性能(SPECrate2017_int_base)的变化。12代酷睿的P-core(Golden Cove)较之有28%的提升。而尤为值得一提的是,E-core(Gracemont)也有1%的领先——这里还没有呈现功耗方面的优势。
这其实也能看出,近几代Intel产品在核心性能方面的显著变化。
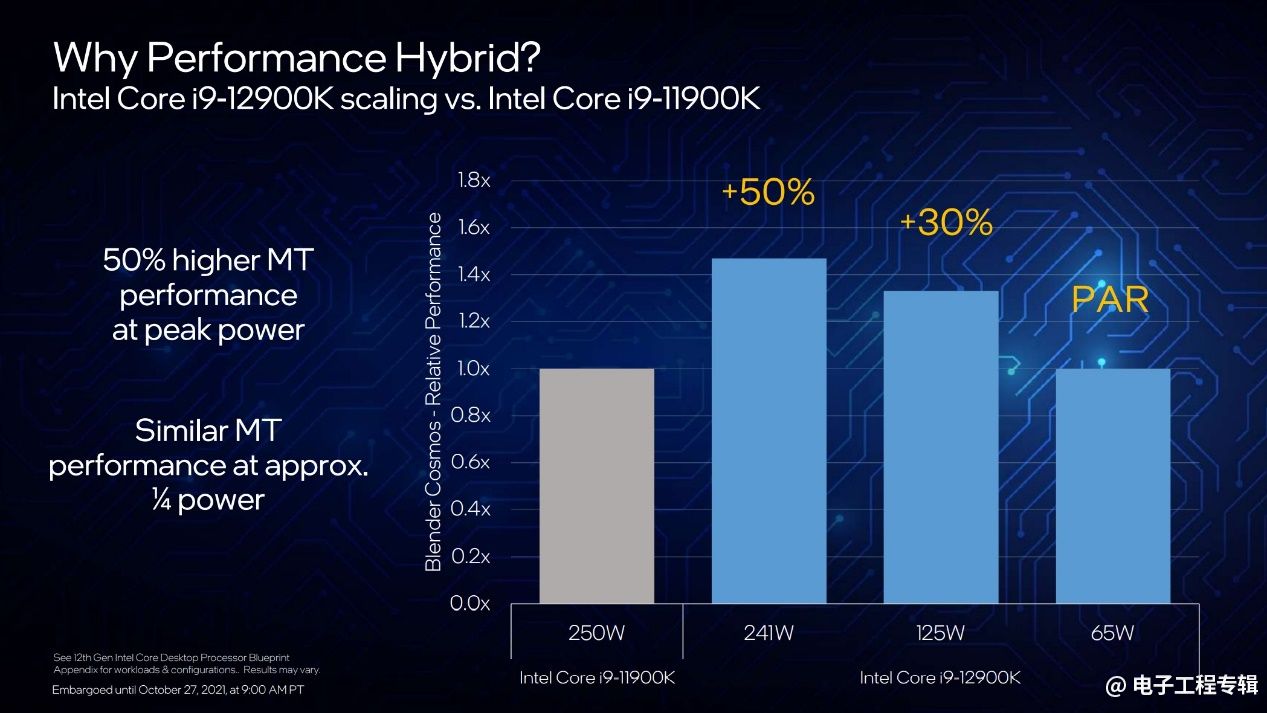
结合两种核心之后,上面这张图对比了酷睿i9-12900K与上一代的i9-11900K。以酷睿i9-11900K在250W峰值功耗下达成的性能为基准,i9-12900K在不同功耗下可实现的多线程性能成绩如上图所示。
这张图有两个亮点,其一是i9-11900K的峰值功耗241W下,相比上代达成50%的多线程性能提升。更重要的是,要达到上一代相同的性能水平,只需要65W的功耗,即上代1/4的功耗。这样一来,12代酷睿理应会有更多的机型设计自由度;而且也让我们更期待移动平台的12代酷睿产品。
尤为值得一提的是,在前文中新品规格表里,首次出现了“processor base power”和“maximum turbo power”这样的功耗词汇。从Intel的解释来看,基础功率(base power)是指PL1状态下的功耗;而最大睿频功率自然就是指PL2状态下的功耗了。

关注PC的同学应该很清楚,PL2是个短时睿频状态:处理器在该状态下,可维持很短的时间达成性能突发量;而PL1是相对稳定的长时睿频。这次最高配的酷睿i9定义最大睿频功耗为241W。
Intel表示,在散热理想的情况下,可设定PL1=PL2=241W。因为这次的芯片可以长期稳定工作在241W功率下。
系统性能,与上一代和对手的比较
以这种程度的核心性能提升,虽然在制造工艺上仍然会在短时间内落后于竞争对手,但AMD在微架构设计上,恐怕很难在接下来要发布的Zen 4上实现赶超。接下来谈谈系统性能,这应该才是更多人关心的问题。
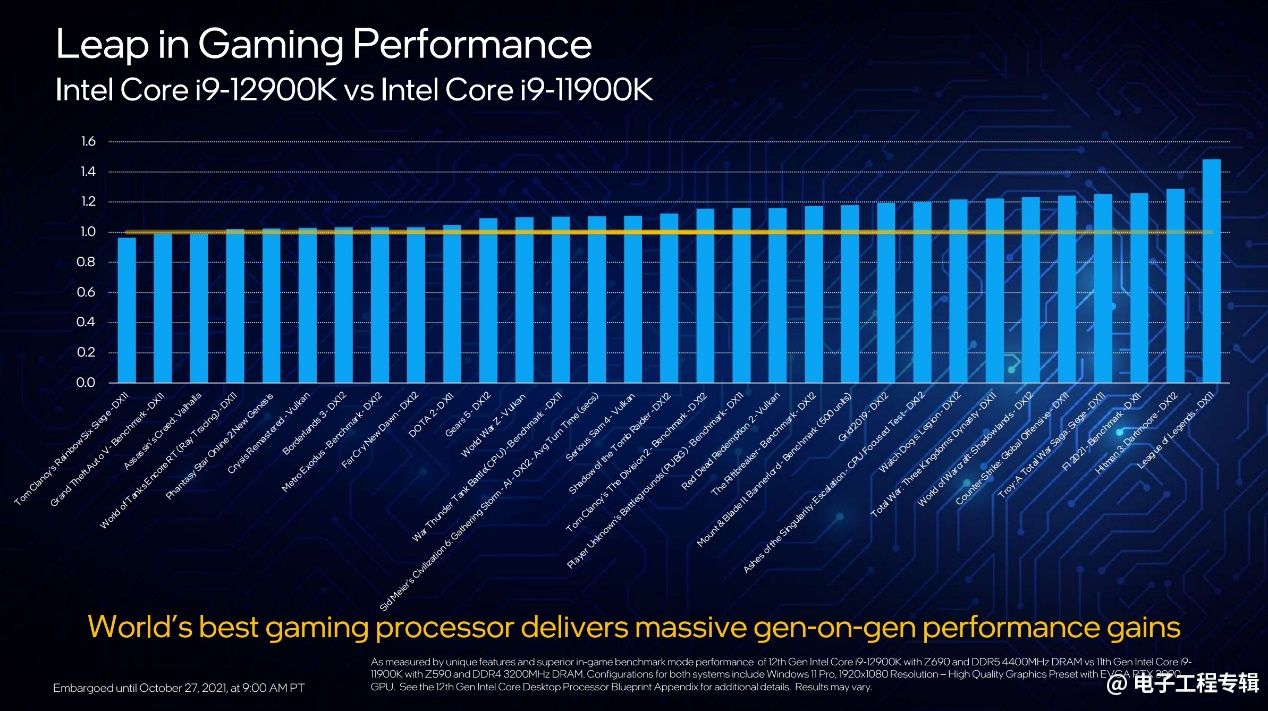
作为强调“游戏”的处理器,上面这张图是i9-12900K与上代i9-11900K在各类游戏上的性能比较(其他配置包括12代酷睿采用DDR5-4400内存,Geforce RTX 3090显卡)。Intel测的游戏还真是相当多,从《彩虹6号》到《英雄联盟》。
综合性能提升取几何平均值,则12代酷睿的性能提升幅度大约为13%(Intel提供的另一组数据是13-28%,可能测试环境和样本量有差异)。像《英雄联盟》这样的游戏,性能提升幅度大约有40%。
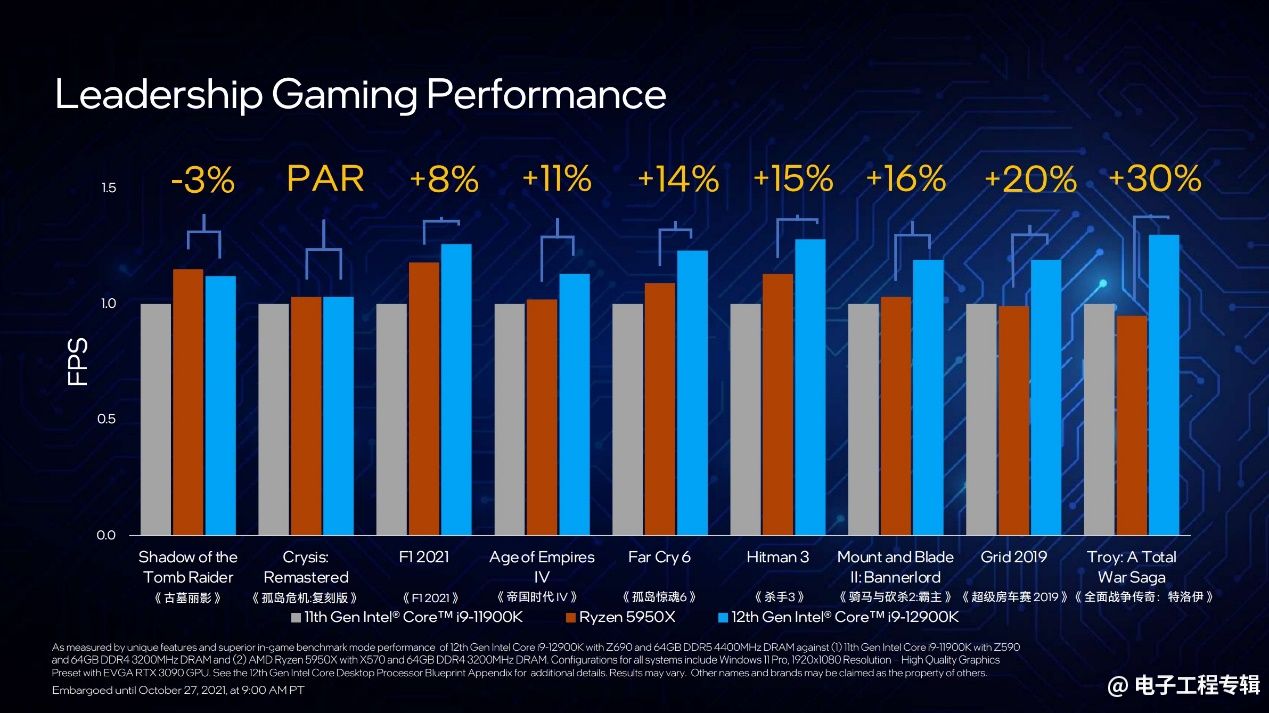
和对家的5950X比比(这次总算是比最顶尖的5950X了)。这张表中包括《古墓丽影》《孤岛危机》《F1赛车》等游戏。酷睿i9-12900K在大部分游戏中都比AMD的线程撕裂者彪悍。不过这一点应该是完全在意料之中的。只是这个对比其实并未发挥AMD使用自家GPU在系统架构层面优势,该对比同样基于英伟达RTX 3090。
另外AMD Ryzen 5000系列不支持DDR5,对此Intel表示12代酷睿也支持DDR4。“同样的,我们将30多款游戏在DDR4上做了详细评估,得到的结论还是相同的。DDR4之上的游戏性能同样高于竞品和11代酷睿产品。”

在昨天的体验活动中,Intel现场展示了自家产品与AMD在游戏过程中的实时帧率、功耗和温度方面的差异。在《超级赛车》这样的游戏里,能表现出相当大的性能差异;而且CPU温度也显著低于AMD的线程撕裂者。这算是真切地在新一代产品中扳回一城,即便Intel 7工艺接下来要迎战的是台积电N5。
有关散热的问题,Intel也在会上提到了一个细节。这代酷睿处理器的封装再度做了优化。此前我们就知道,Intel通过做薄die的部分,而做厚上方的IHS(Integrated Heat Spreader)散热器来提升散热效率。12代酷睿桌面处理器的IHS进一步做厚,将STIM(Solder Thermal Interface Material)钎焊散热材料做薄了,来进一步提升散热效率。
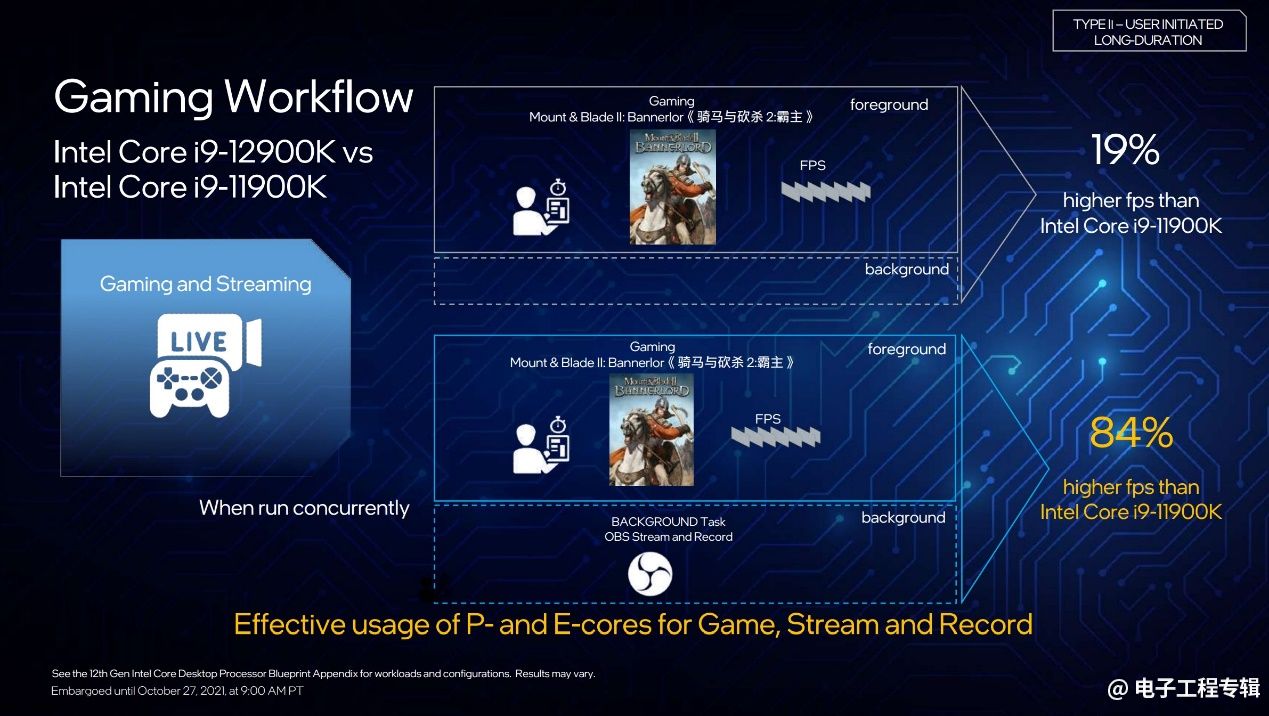
另外需要单独提一提混合架构中,E-core在游戏场景中可发挥的作用。前文已经提到,即一边玩《骑马与砍杀2:霸主》这款游戏,一边跑游戏的流播与录制(OBS)。酷睿i9-12900K的E-core能帮上很大的忙(主要是针对OBS的流播与录制任务),最终可让游戏帧率提升84%。如果没有E-core的话,那么相比前代的提升则在19%左右。
值得一提的是,Intel这次专门与游戏工作室合作的游戏包括《杀手3》《反恐精英:全球攻势》《骑马与砍杀2:霸主》《全面战争传奇:特洛伊》等。《骑马与砍杀》应该是这其中对多线程并行能力利用率比较高的游戏,所以能够表现出更大的性能优势。
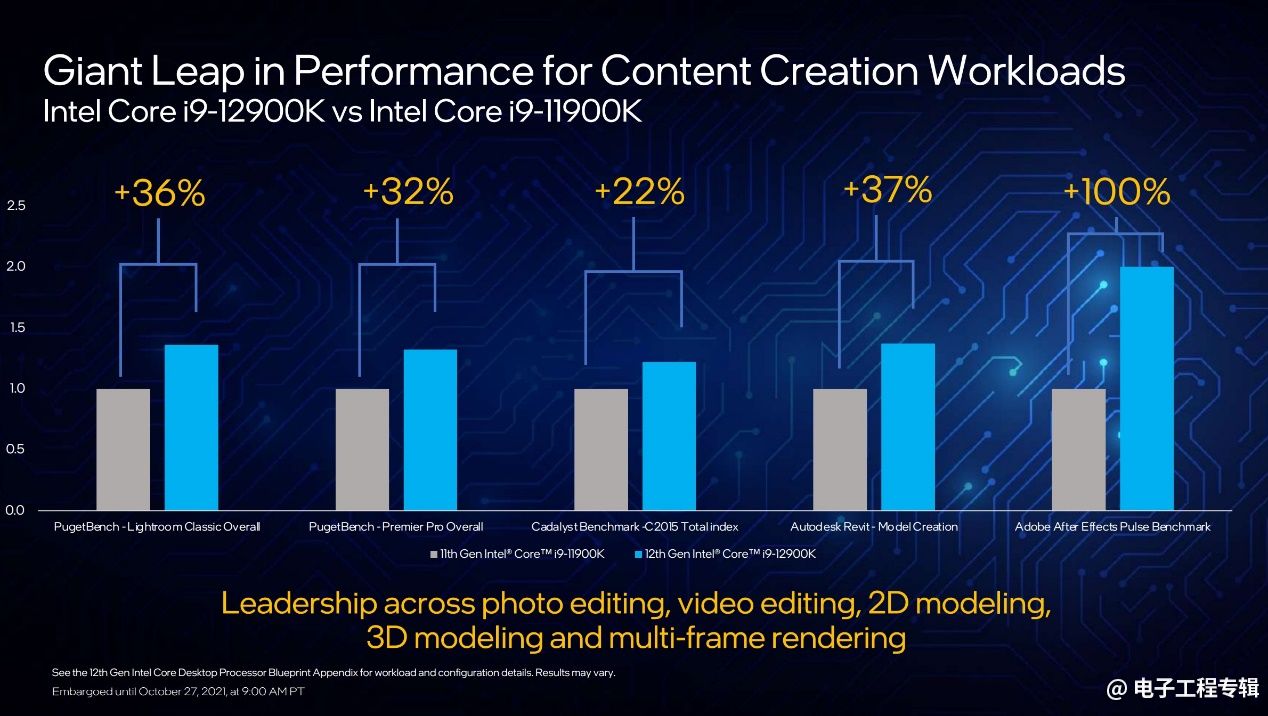
说完游戏,自然要说内容创作了。Adobe全家桶,包括Lightroom、Premiere、After Effects,以及其他各种工具,从照片、视频编辑,到2D、3D建模和多帧渲染等工作,12代酷睿相比前代的性能变化如上图。
这里After Effects Plus Benchmark能够充分利用并行计算资源来做视频处理,所以性能提升幅度达到了翻番的程度。E-core在这其中应当也起到了相当大的作用。这些内容创作工具中,Intel同样有生态合作方面的例子。这次Intel特别提到了VEGAS Pro——在程序上较早开始利用VNNI指令集。这种生态合作的工具,事实上总是能达成更高的硬件利用率。
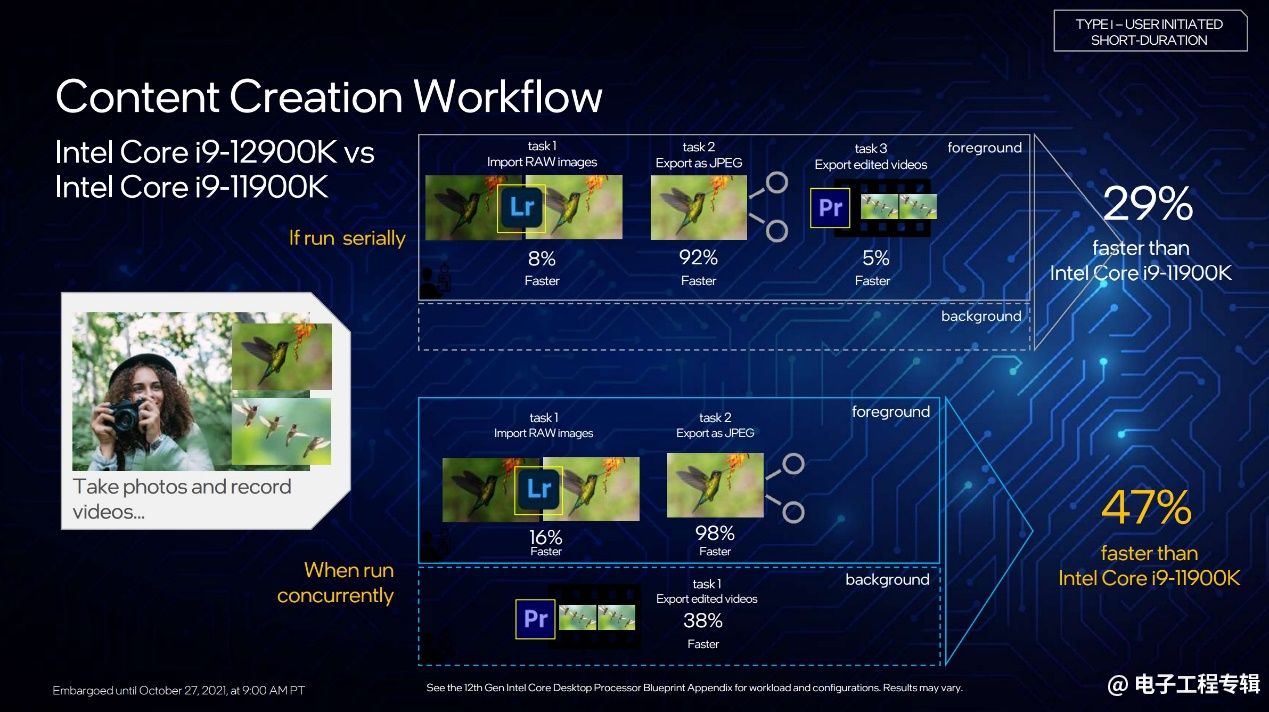
此处Intel为了表现其混合架构优势,列举的一个多任务工作场景是一边用Lightroom导出照片(RAW->JPG),一边用Premiere导出视频。在E-core参与工作的情况下,并行处理这两项工作,能够达成相比上一代47%的速度提升。
这一例中。“照片编辑是短期操作行为,会被拉到P-core去操作;而视频转码用Premiere会被移到后台。”是两种核心配合工作的典型场景。
前文我们已经提到,其实这样的工作场景还是挺少见的。不过或许的确有摄影师存在此种工作需求,一边剪片子、一边给照片调色——摄影师本人仿佛也是多核工作状态…
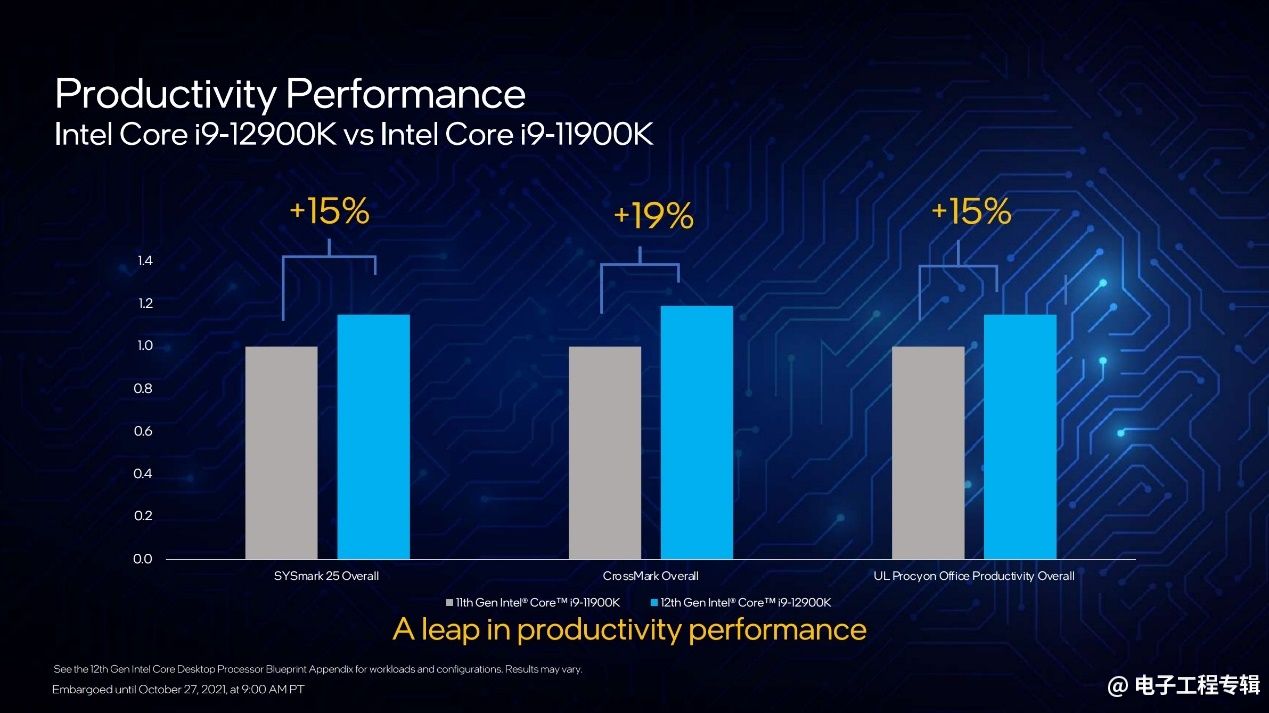
还有个生产力性能场景,包括一些办公工具的性能变化,i9-12900K相比上代产品的变化如上图所示。不过在多媒体内容创作以及生产力方面,Intel并未给出与AMD的对比数字。
600系列芯片组与超频
最后来说说搭配12代酷睿桌面处理器的Intel 600系列芯片组(PCH),以及处理器及周边的官方超频选择——这也是现在Intel发布会必提及的项目,毕竟很多会选购桌面CPU的同学都是发烧友爱好者。
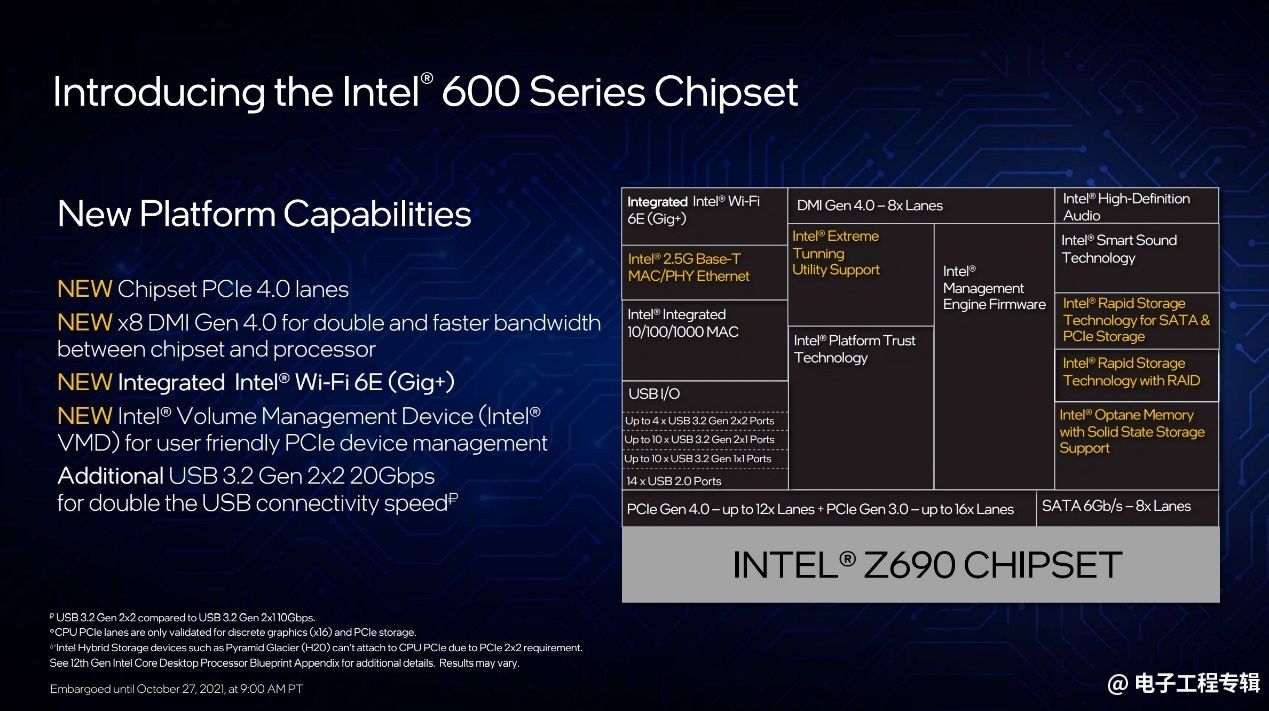
其实600系列芯片组能提的亮点不多,高端定位的Z690芯片组支持PCIe 4.0,“配合原有的PCIe 3.0,在芯片组上我们一共交付了28条PCIe连接接口,极大丰富了外设连接。”
这里有个亮点在于,芯片组与CPU连接的总线升级至x8 DMI Gen 4.0——虽然不知道具体规格,不过猜想应当与PCIe 4.0类似。外设拓宽,做芯片组与CPU连接带宽提升也是应该的。在这一点上,看未来12代酷睿移动版的配置应该会更有意义。
除此之外就是集成Wi-Fi 6E;以及“通过VMD(Volume Management Device)可以更好实现在PCIe下的设备管理,灵活进行设备组合管理”。
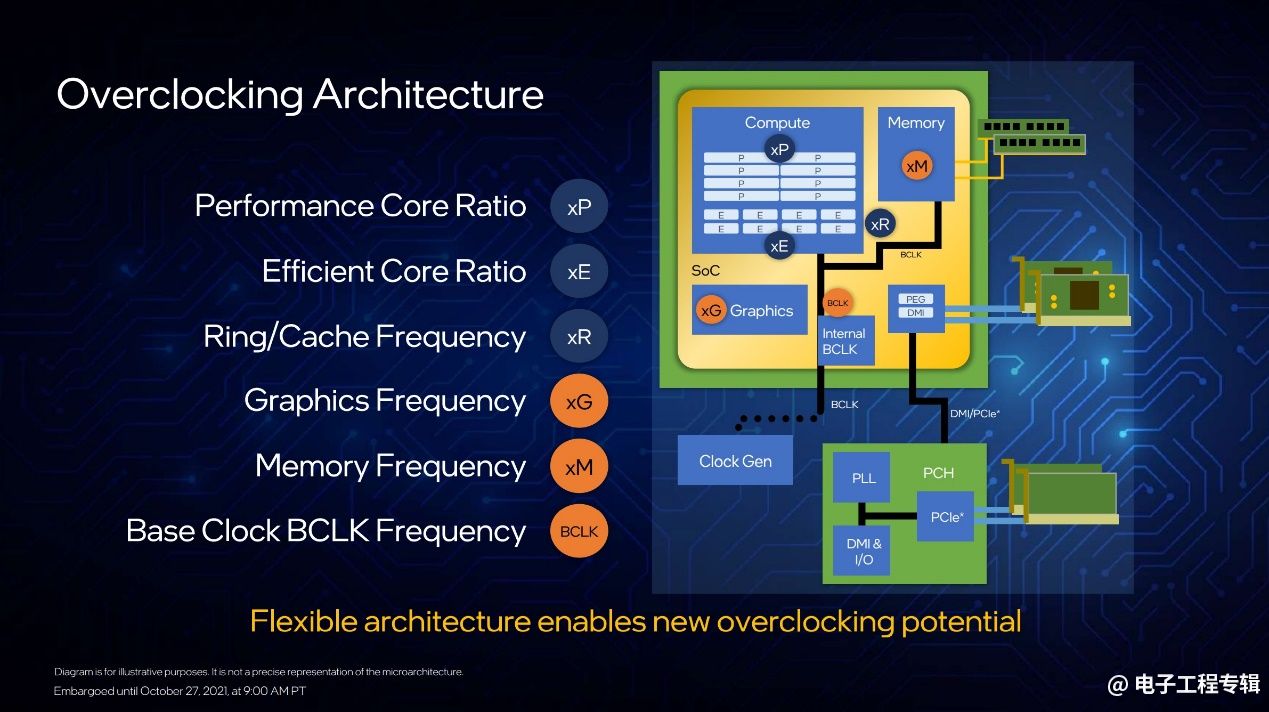
而在官方超频选择方面,对用户而言主要有几个新增的超频功能。其一是,E-core也可以超频,而且在XTU工具中可以针对单独的核心做超频设置。P-core与E-core倍频可分别做调整,Ring/Cache频率、核显频率等都可以做调整。


其二,配套DDR5,Intel推出了XMP 3.0。对于用户而言,XMP 3.0增加到了5个profile可选,有新的电压选项;其中有2个profile可以由用户手动修改一些时序特性——这一点在过去是没有的。PMIC如今是跟着DDR5走的,“DDR5电源管理IC目前有三个电压:VDD、VDDQ和VPP,这三个电压都以JEDEC与英特尔XMP做规范。”…“主板厂不需要去认不同厂商的产品,由Intel来做超频相关的电源IC规范。”

“我们提供这么多的频率、电压、timing…所需的位置会更大。以前是78bytes,现在是384bytes需求。”Intel方面表示,“这些XMP的规格与电源管理IC以及SPD的规格都有关联,互相做参考。这些规格让内存厂商做验证,然后将其验证结果交给Intel。Intel确认之后,将其列为Intel认可的DDR型号。”
XMP 3.0还是相当值得发烧友们去研究和把玩一番的。
在昨天的演示环节,Intel演示了用XTU工具,直接在操作系统中就可以进行内存超频的实时切换,从4800 MT/s超到5200,而不需要切到BIOS下去设置。

其三,内存超频部分这次Intel新推了一个Dynamic Memory Boost动态内存频率调整特性。可以根据当前负载自动进行内存频率的切换,即在可达到XMP设定“超频”频率的基础上,也能在不需要的时候回到默认频率。

最后就是XTU(Extreme Tuning Utility)这个官超工具的一些特性加强。在XTU 7.5版本中,除了前文提到的对不同核心做超频设置,对内存做XMP超频,Intel还特别强调了新增的Intel Speed Optimizer达成核心频率上的“一键超频”。按一个按钮,就能提升至优化过的更高的频率——真正的“官超”。

总结:Intel的关键一役
我们已经拿到了这次Intel新发布的酷睿i9-12900K与i5-12600K,后续将会从某些角度对这两颗芯片的性能和表现做个体验分享。
12代酷睿处理器(Alder Lake)对Intel而言是相当重要的产品。以此前的架构分析和这次官方公布的数据来看,秒杀AMD Zen 3乃至后续的Zen 4应该都不是大问题;而且已泄露的跑分也表明,其CPU部分的绝对性能是优于苹果M1 Max的——虽然因为制造工艺及运营模式的关系,在功耗表现上或许仍然不及。
混合架构,及作为未来酷睿产品架构升级基础的P-core(Golden Cove)都是Intel这两年的集大成之作。基于目前Arm阵营在高性能领域扩展的态势,以及AMD这两年的市场表现,Alder Lake无论对Intel,还是对x86阵营而言,都是异常关键的一役。这也让人更加期待后续要到来的Alder Lake移动版。
价格对应如下:
i9-12900K售价为589美元,国行预售价4999元;
i9-12900KF售价为564美元,国行预售价4699元;
i7-12700K售价为409美元,国行预售价3199元;
i7-12700KF售价为384美元,国行预售价2999元;
i5-12600K售价为289美元,国行预售价2299元;
i5-12600KF售价为264美元,国行预售价2099元。
这些产品目前已经接受预订,预计将在11月4日正式开售,明年年初还会有更多12代酷睿处理器型号问世。




位于华盛顿州的Alder Lake长这样


责编:Luffy Liu
- 不可能intel多核同功耗下能干过amd
