
最近联发科(MediaTek)召开了一场天玑旗舰技术媒体沟通会,联发科在这次活动上主要分享了5G、游戏、AI方面相关的技术进展,以及“天玑5G开放架构”。本文我们着重谈谈游戏、AI相关的技术,并顺带简单提一提“天玑5G开放架构”。有关5G技术的部分,电子工程专辑的其他同事将另外撰文,阅读请点击:《R16商用会给5G手机带来什么?联发科谈天玑旗舰技术之5G特性》。
联发科作为目前智能手机市场份额最大的SoC厂商,对游戏和AI技术的发展观察与决策,对于我们理解未来智能手机在这两个方面的市场走向,具有比较大的参考价值。而且联发科在沟通会上着重谈的一些技术,也的确是市场发展的主流——只不过从中,我们还能听到不少细节上的补充,便于我们更深入地理解智能手机技术。

本文篇幅较长,大方向分成三部分:游戏(第一、二、三段)、AI(第四段)、天玑5G开放架构(第五段),可根据读者的喜好选择性阅读。我们认为联发科这次的分享还是有不少干货的,值得一看。
对手游的一些观察
第一部分先来谈谈移动端游戏技术。联发科这次着重谈到了“移动游戏趋势”,这是个挺有意思的议题。从两个方面来谈。
首先是手游“内容生态”的变化。下面这张图左边部分展示了传统生态,联发科谈到一般一个新的渲染技术,要从行业标准化,到游戏内容生态落地在Android移动平台,需要经过GPU厂商开发支持、游戏引擎导入、APK内容商导入等——整个过程需要3-5年。
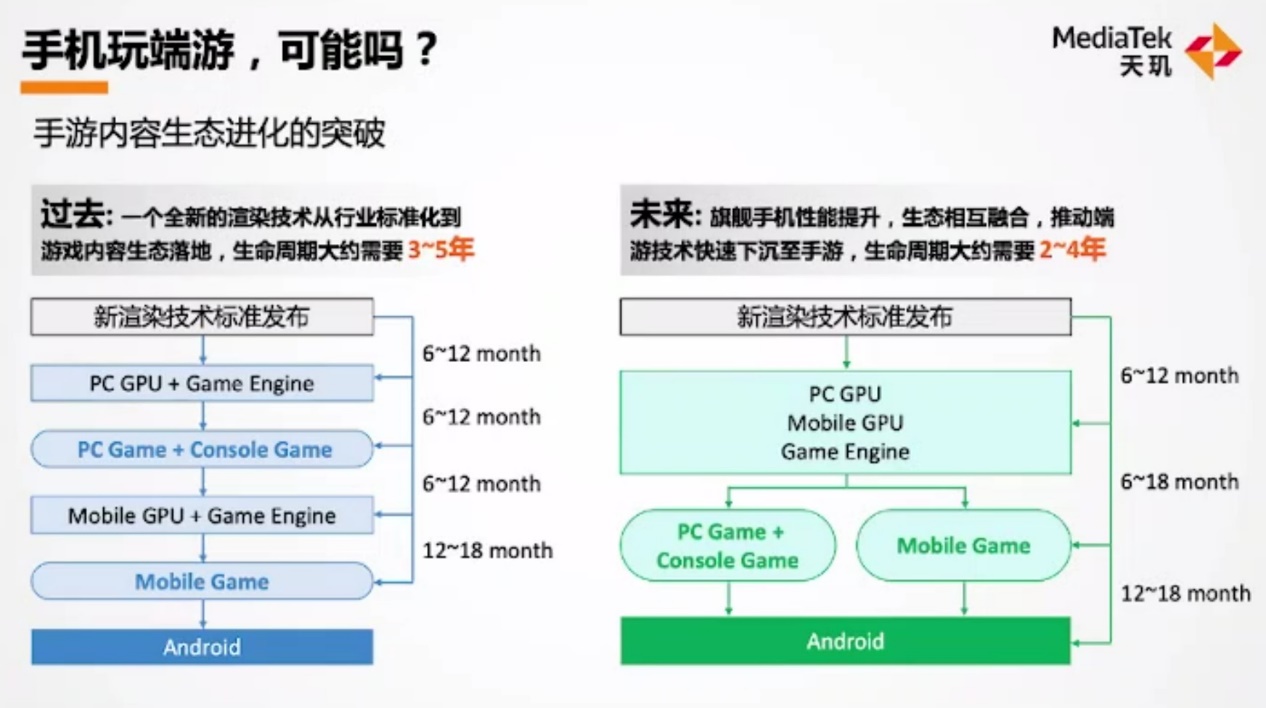
联发科认为,未来因为旗舰手机的性能提升——甚至提升到与轻量级笔记本接近的程度,所以手游开发者会更愿意尝试原本属于端游(PC游戏)的特效。也是因为性能方面的提升,游戏内容商的开发周期会由3-5年缩短至2-4年。
这其中的逻辑在于,通常新的渲染技术总是更早被PC或游戏主机享用,后续才下放到Android平台。而随着移动GPU性能提升,移动平台更具价值,自然减少了其中的下放时间。“性能问题解决了,芯片厂商能够提供更多的渲染技术给内容开发者。”
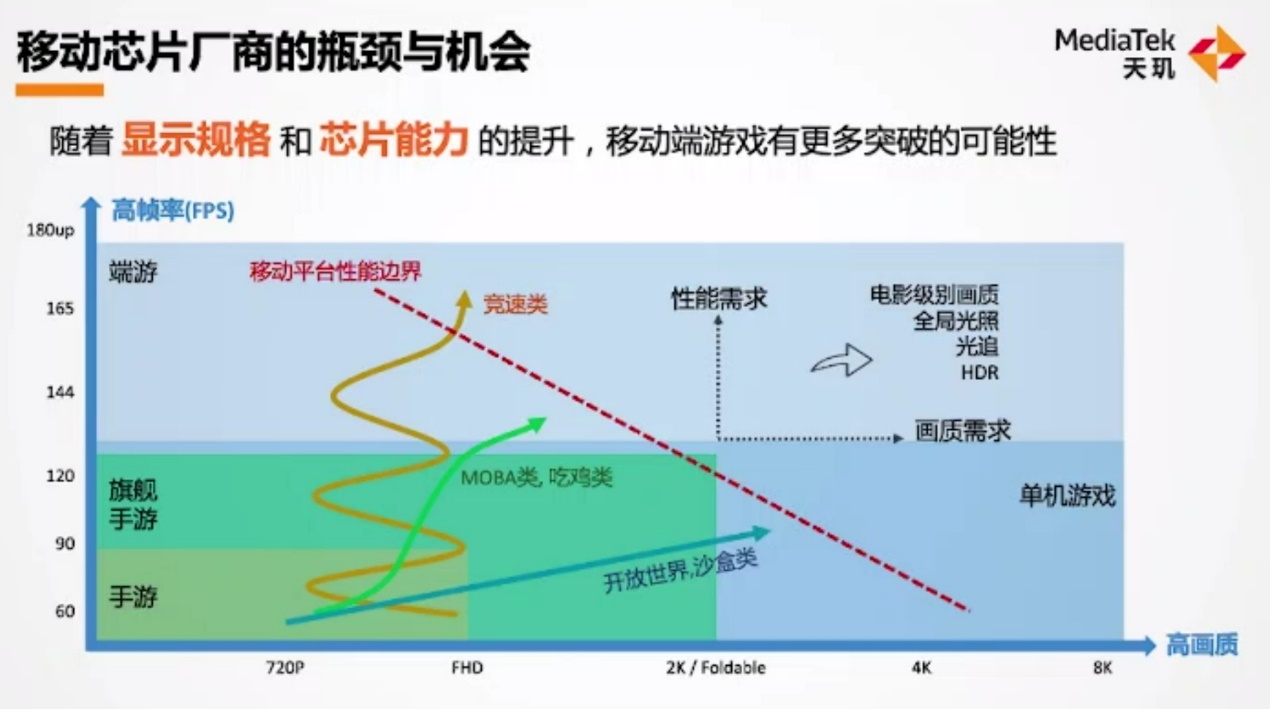
其次是对现有手游市场的观察,能看出手游某种程度在向端游靠拢。上面这张图横轴代表游戏分辨率,纵轴代表游戏帧率。不同色块自然就可以用来表示不同性能需求定位的游戏了——这个维度分类,从大方向来看有一定价值——虽然游戏帧率和分辨率,并不能完全代表其硬件性能需求。
从游戏硬件平台的角度来看:联发科认为,手游目前主流的规格是1080p 90fps,旗舰手游则在2K 120fps的程度。脱离手游范畴,在真正的游戏市场,某些单机游戏可达成8K 120fps的规格。端游的情况则可能很复杂,英伟达的高端GPU最高可实现某些游戏8K 180fps的规格(不知道说的是哪些游戏,似乎当代消费级GPU要带动8K分辨率的3A游戏,仍然相当罕见)。
从游戏类型来看:竞速类(如赛车、跑酷)手游,为了追求流畅度,往往着重在刷新率、帧率,相对在分辨率方面会有所妥协——这张图中竞技类游戏的发展曲线了震荡螺旋上升的,大约是画质与帧率间寻求平衡的缓慢提升过程。
MOBA和吃鸡类手游,则是随着手机平台支持的刷新率,去逐渐开放更高的帧率支持。这类游戏在每代游戏版本迭代过程中,在画质层面会增加更多特性,如HDR、UltraHDR显示支持等,而非单纯的分辨率提升。
还有一类即开放世界类(以《原神》《天涯明月刀》等为代表),以大地图、无边界场景为主要呈现方式。这类游戏追求更高的画质细节,如草地、树丛、水流等高精度的画面内容。由于其贪婪的性能需求,其帧率提升速度是显著更为缓慢的。
“不同内容需求,驱动我们硬件厂商要将性能边界线往右移动。”联发科表示,“芯片厂商需要布局更高刷新率、高画质需求和性能边界线。令其越来越往端游技术贴近,布局更多端游的渲染技术。”这一点实际上与前面提到新的渲染技术从端游下放到移动平台速度显著缩短,是相吻合的。
即将应用于手游的几项技术
那么基于对手游的观察和理解,以及当前游戏行业的主流技术发展(也包括Vulkan的普及,提供端游、手游跨平台兼容的可行性),联发科预期旗舰手机有3大技术需求:光线追踪、超分辨率与全局光照。对游戏比较关注的同学,对前两者应该不会陌生,此前我们在谈游戏行业的技术发展时,也将光线追踪和超分辨率作为主流游戏技术热点看待。这三者“是用来承接端游下沉到手游的基础部件”,联发科表示。
光线追踪这两年在PC平台是比较火的,连刚刚发布的《仙剑奇侠传7》也增加了光追特性;AMD比英伟达晚了一步增加对光追的硬件支持。而移动平台更早做光线追踪的是Imagination,Arm Mali在这方面事实上并未快速跟进——只不过Imagination的移动光追技术暂时也还未见于手机端普及——这显然是因为光追对硬件资源、功耗有着明显更贪婪的需求,此前我们也在好几篇文章中重点解析过光追技术。
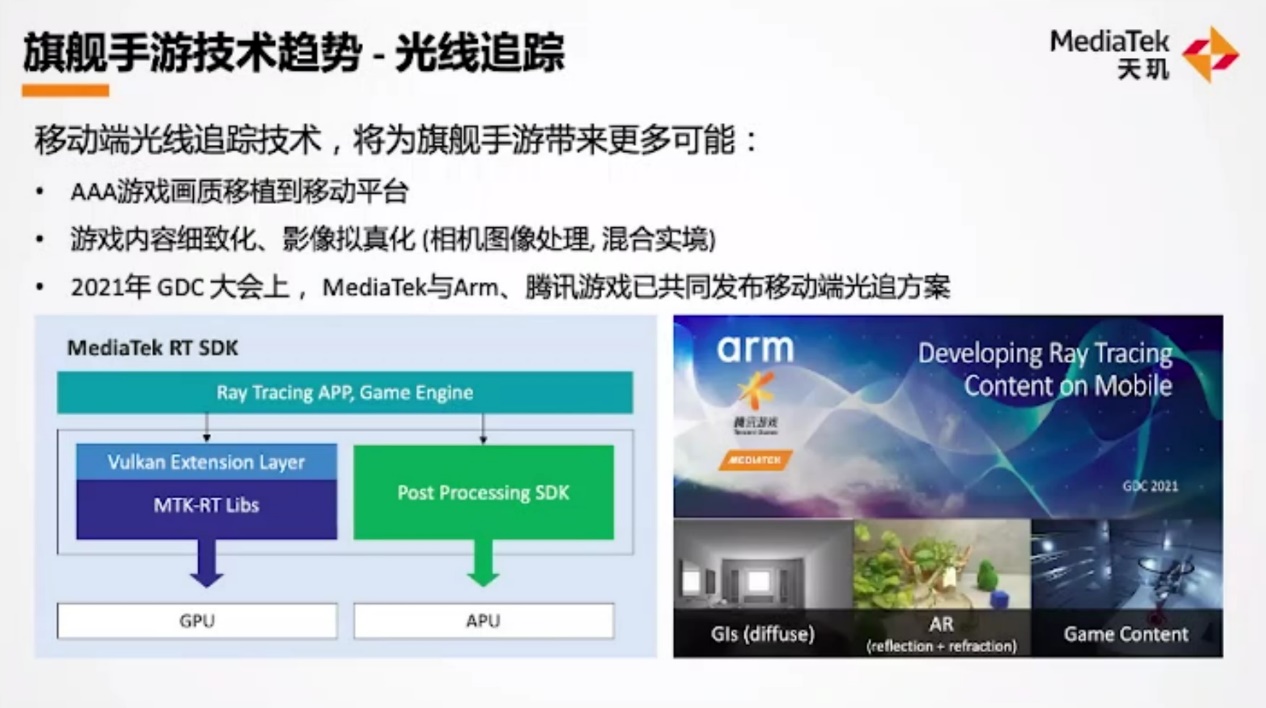
联发科表示,在移动平台实现光追并不是简单做端游技术的下放。毕竟“PC是DirectX渲染线程为主”,所以“要将端游光追应用到手游上,需要对移动端游戏引擎做改造,光追方案对手游开发者才能真正做到可用”。联发科表示,去年年初就已经在和腾讯引擎团队合作,在手机游戏上引入光追。Imagination此前在接受我们采访时认为,光追在手机端的普及可能要到2023-2024年左右;但看联发科的姿态,恐怕不需要等这么久。
“我们主要是针对游戏引擎端去优化渲染管线,希望为内容开发者提供更容易导入的开发环境和游戏引擎的支持。”“另一个方向,我们针对光追和AI运算,定义新的渲染方式,将光追扩展到AR、相机影像应用上。”“2021年GDC大会上,联发科与Arm、腾讯游戏共同发布了移动端光追方案。这会是未来主流移动光追的方案。”联发科在采访阶段确认,“接下来的确会有一些腾讯系(的游戏)合作工作会开始尝试导入;对于其他生态系,我们也正在推广中。”虽然并未明确具体时间,但对手游玩家而言的确是个福音。
另一个比较重要的问题是,光线追踪对硬件资源会提出更高的要求。光追在端游市场尚且都并未完全普及,移动端的功耗与性能限制又如何承载光线追踪呢?对此联发科提到:“我们和腾讯引擎部门共同开发这套框架。这和端游是不同的,端游的光追是对整个游戏画面做渲染,性能要求高。但其实整个画面不一定都要应用光追特性,移动端就是针对局部区域或者局部对象导入特定光源需求,实现手游场景中的局部光追。这是我们认为,移动端主流的光追方案。”
虽然联发科并未谈到GPU层面的光追硬件实现(这一点或许可以等未来的Mali IP架构揭晓去进一步了解),但必定也是增加专门的固定加速模块——英伟达、AMD、Imagination也都是这么做的。联发科针对这部分谈到移动GPU光追是分阶段与Arm合作的,即虽然现有的Mali GPU尚未增加光追单元,但其实这两代就已经在为光追做准备,包括“渲染指令运算、缓存机制,现在是融入在了IP里面的”。这个过程并不是一蹴而就的。

其次是超分辨率——这也是当前我们所知,AI技术在游戏领域应用的重点。英伟达DLSS与AMD FSR都属于游戏超分技术(虽然AMD FSR事实上并未应用AI),也就是通过算法将低分辨率的游戏画面upscale为高分辨率——upscale后的高分辨率画质,与以原高分辨率渲染得到的画质很接近。这么做能够有效节约硬件资源,以更低的成本来提升游戏帧率和体验。DLSS技术在游戏市场上成功就很能说明问题了。
“我们也认同游戏市场有这样的需求。我们未来会布局游戏超分,在移动平台端的完整方案。目标上和英伟达一致,满足游戏开发者在性能和画质上的要求,芯片平台的性能、功耗也达到整体平衡。”
联发科在接受我们的采访时提到,“我们第一代游戏超分的规划方案,希望是结合GPU+APU的异构方案。在移动平台端,我们希望让GPU专心做渲染,APU则可以offload一部分超分的系统需求。”“这是我们第一代会推出的方案趋势。”听起来和英伟达的方案理念是类似的。虽然联发科也并未透露超分应用于手游的具体时间。

第三就是全局光照了。这一点玩《原神》这类游戏的同学应该会有比较深刻的体会。“开放世界游戏对移动端平台会有不可控变因,存在许多场景与角色间的互动。场景中的光源,动态光源需求会很多。角色人物一动,场景内的光源就需要重新计算。”
“加上户外游戏场景会有一些持续的变化。比如黄昏、黑夜、清晨,都有不同的阴影、光线的变化,就需要更细致的光照计算。”这的确是当今开放世界游戏场景动态变化的特点。另外还有“场景对象与面数大幅增加”这样的客观事实。
“基于这些开放世界游戏的需求,我们认为需要全局光照的优化方案。”延迟渲染(Deferred Shading)成为联发科眼中的必要手段。“延迟渲染改变传统计算流程,使用额外中介buffers减少光照计算,支持10倍数量的动态光源交互,节省20%带宽,是落地到移动端的关键技术。”事实上,TBDR也一直是移动端为减少外部存储访问,规避移动平台有限的带宽和功耗资源,有别于PC平台的重要方案。这里的“中介buffers”应该也就是指片内cache了。
联发科也在采访阶段解释了这些internel buffer是当做“整个光照内容的暂存,避免运算过程中有额外存取memory的动作。”“与此同时,整个光照过程中的公式会改变,基于计算机图形的一些基本结构去修改。”联发科还透露说,“下一代旗舰平台就可以支持实时的全局光照技术。”说明这项技术的普及已经很快了。
从系统角度做考量的HyperEngine
除了对手游市场的观察,以及对未来手游技术的展望,联发科当然也着重提到了此前在手机SoC上实践的一些技术。“了解用户体验需求后,将其转化为技术指标。”包括前文提到的高帧率、高画质,还有低延迟需求对芯片与外围器件提出的技术指标。芯片厂商、终端厂商、游戏开发者都需要为这些指标做出对应的变化。英伟达现在也一直在走这样的路子。
“对芯片厂商而言,我们要提供先进工艺技术、最新运算架构、系统缓存这样的架构革新,用于支撑游戏基础性能功耗的基础部件。”“游戏终端厂商则需要在系统上布局新的器件需求,如高刷屏、大电池、大存储、触控等周边。”“而内容开发者需要在手机平台上扩展游戏特效,也包括游戏性能优化等。”这些是针对不同层级的技术特性的单点构建。
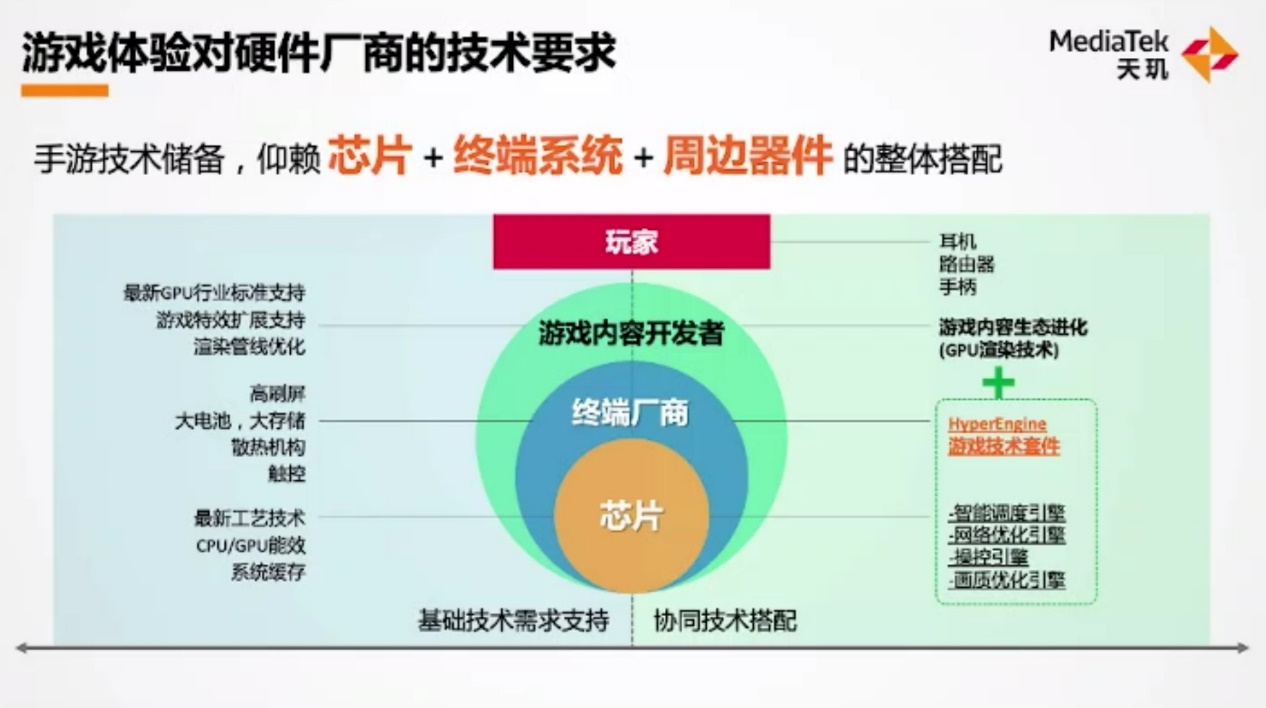
“联发科在思考将不同层次的技术串联起来,让硬件部分不只是在堆料,而要发挥整个平台的综合效应。”这也就引入了联发科此前就在大力推广的HyperEngine游戏套件。
前年联发科发布Helio G90的时候,我们就介绍过同期推出着重提升游戏体验的HyperEngine游戏技术套件。HyperEngine包含了智能负载调控引擎(Resource Management Engine)、画质优化引擎(Picture Quality Engine)、操控优化引擎(Rapid Response Engine),以及网络优化引擎(Networking Engine)。
不同引擎的提出其实就是满足不同层级的技术要求,搭建一个完整的方案。不过当时的HyperEngine乃是1.0版本,联发科在本次沟通会上说当时的1.0版本建立了一个框架。HyperEngine 1.0主要优化的是游戏网络延迟、触控延迟,有兴趣的同学可以去回顾一下当时我们撰写的文章。

后续几年,HyperEngine也有了对应的升级。2020年以iQOO Z1为代表的机型,所用的HyperEngine 2.0着力在网络优化引擎上,包括所谓的“电梯模式”“高铁模式”——针对特定场景实现的网络稳定性优化;还有在家用环境下,不同无线网络——如蓝牙可能与 WiFi 产生干扰,影响游戏网络的稳定性,HyperEngine 2.0着力于解决此类问题。
今年联发科HyperEngine 3.0重点在推出了温控稳帧算法;以及尝试做芯片和其他外设的协同方案。比如芯片与蓝牙耳机的协同,尝试尽可能实现蓝牙耳机的低延迟体验。其他主要技术着力点可以在上图中看到。
比较值得一提的是,联发科特别提到HyperEngine 1.0-3.0各代持续演进的“来电不断网”方案——这项技术要解决的是玩游戏过程中,来电造成的卡顿和断网。这两代似乎主要是增加了5G NSA与SA相关的来电不断网支持——据说这是联发科的独家方案,在实现上比iPhone还要早。联发科并未就这项技术做详述阐述,未来我们或可做进一步的深入探讨。
至于图中的HyperEngine 5.0,联发科表示“拭目以待”,预计将在明年推向市场。
手机AI芯片算力,怎样才算有价值?
说完游戏,再来谈谈手机上的AI技术。联发科包括天玑系列在内的手机SoC,之上的AI专核被称为“APU”——其本质与NPU、AI Engine、Neural Engine是一样的。有关AI在移动设备上的价值此前我们谈得太多了,这里就不多花笔墨去谈了。

联发科对于旗舰设备AI关键场景的设定包括三个方面,分别是Multimedia AI——也就包含了拍照、视频录制这些场景——这其实也是手机AI现阶段绝对的主场,是计算机视觉、计算摄影的发展和演进。比如说夜拍、人像模式等,还有类似直播实时换脸、美颜等feature。
Game AI——主要是指在游戏上应用AI,着力于提供高清稳帧的游戏体验。这两年通过AI来提升GPU效率的技术我们也听过不少了,再加上前文提到很快就会到来的手游超分技术——又是AI在游戏方面应用的重要组成部分。
Social AI——这一点联发科称其为“高清流畅收视体验”,针对的应该是Display部分。一个比较典型的例子是直播或线上会议。高分辨率的视频直播,对带宽、服务器硬件资源都有要求。在带宽和服务器资源并不理想的情况下,以低分辨率传输,到本地通过AI技术来upscale分辨率,也就事实上从系统上降低了系统消耗。这一点很类似于此前我们提到英伟达的Maxine SDK。不过Display AI应该也不仅限于此。
这三个组成部分,其实都要求生态构建能力。以联发科对自身的角色定位,他们极有可能会与合作伙伴一起来推具体的AI实现。联发科自家AI生态中的Neuropilot SDK,事实上已经增加了相关的不少基础实现,比如人脸侦测、HDR影像、SDR-to-HDR显示技术,都是对AI的典型应用——天玑1200芯片就有配套的实现。
单纯从AI硬件的角度来说,我们知道APU这类AI专核本质上是能够进行大规模并行乘加运算的电路。CPU、GPU之类的处理器也能执行AI运算,但效率会比APU差很多。当然相对的,它们的通用性(可编程性、灵活性)也因此有较大差异,APU更多的被称为“专用处理器”,自然不及CPU、GPU那样通用和灵活。
联发科将APU比作货车,而CPU是电动车,GPU是汽车。电动车灵活性最高,可穿梭在大街小巷,但其载货量是有限的;货车虽然灵活性不佳,但货运量是最大的。这是AI这种特定的运算会用APU进行的原因,因为效率最高。
如果将司机比作是功耗,在只有一个司机的情况下(类比1W功耗墙),即便有很多辆货车(很多APU运算资源),司机每次也只能开一辆车。功耗超了就会有更多的发热问题,并影响到移动设备的续航。“再大的算力,超过功耗要求也就无从发挥了。”这是AI计算的其中一个限制。

另一个限制则在于有效算力:“运送的包裹是不规则的,没有做很好的排列”,如上图中右下角的九宫格所示,“明明有9格空间,但只有6个空间在运算,另外3个是浪费的,只有66%的效率。”“这就是有效算力的概念。”“良好的资料排程,能够发挥每个运算单元的效率,有效算力很重要。”
基于这两个限制,联发科提出了“每瓦有效算力”的概念。我们认为,这的确是个更具参考价值的值,毕竟市面上的硬件厂商普遍在宣传的都是理论上的总算力,未曾考虑功耗效率,以及有效算力的问题。当然联发科提“每瓦有效算力”应该也与其天玑系列SoC芯片APU标称的理论峰值算力数据并不算高有关。
前文提到的Multimedia AI、Game AI、Social AI,在联发科看来都对每瓦有效AI算力很看重。这几个特性都要求持续的AI算力,比如玩游戏、看直播都会持续几十分钟,那么让APU在有限的功耗下发挥最高性能,就非常重要。
事实上,联发科提“每瓦AI有效算力”的概念,更多的价值应该是体现在联发科的Neuropilot SDK上的。面向开发者的中间层写得好、效率高,自然就有更高的有效算力。这方面联发科似乎是相当自信的。事实上,联发科APU经常在AI Benchmark排行榜上拔得头筹主要靠的就是“有效算力”,而不是标称理论峰值性能。
“凭借我们的优化,我们对各模型的掌握度,让有效算力能够充分发挥,经过良好的资料排程,发挥最好的性能。”我们认为,每瓦AI有效算力是个挺不错的倡导。不过这一点依靠的应该主要就是软件方面的能力,就如同英伟达每年对各类库、工具的更新,能够在相同硬件基础上实现翻倍的性能提升,是一样的道理。
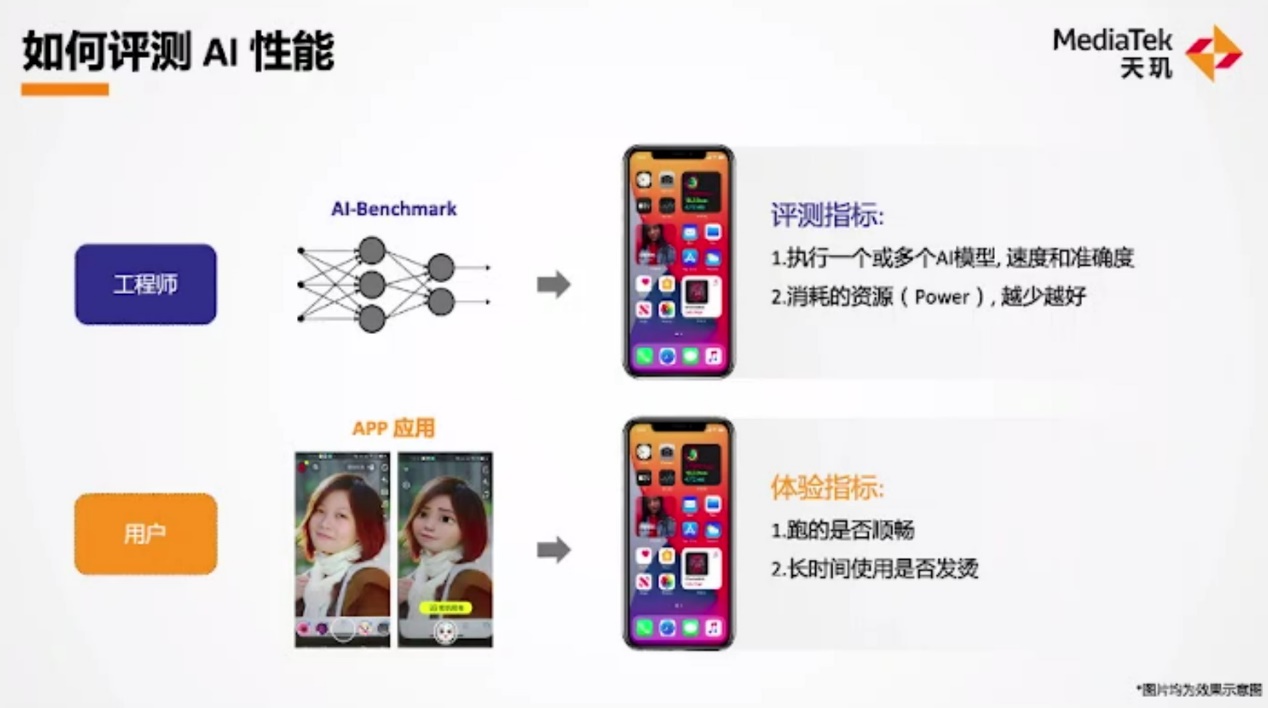
联发科随之提出“如何评测AI性能”。一般我们说评价端侧AI芯片inferencing的能力,无非就是令其跑一个模型,依据精度和性能来排名。不过联发科认为,一个典型的应用往往不是1个模型的问题,比如拍照需要对人脸做侦测,需要做语义分割,还有美颜等。这些模型跑起来效率和准确度如何是很重要的。另外就是消耗的资源,越少越好。
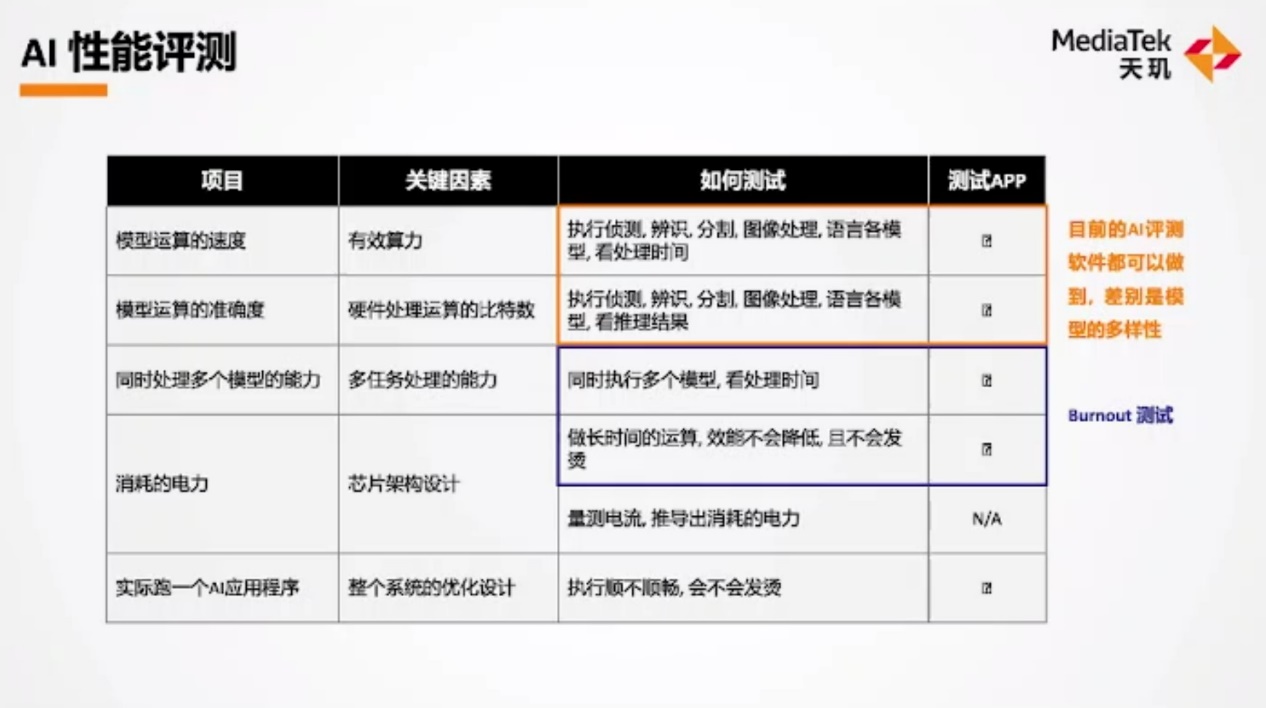
反映到用户体验层面,都是特定的AI功能跑的是否顺畅,长时间使用是否会让手机发烫。总结为更细致的分项,则具体如上图所示。包括模型运算速度、准确度,同时处理多个模型的能力、功耗情况,以及实际跑AI应用的表现如何。在此联发科特别提到,AI Benchmark测试的模型多样性比较充足;而用AI Burnout进行基准测试,能够更好地反映上述特性中同时处理多个模型的能力,以及功耗、温控表现。
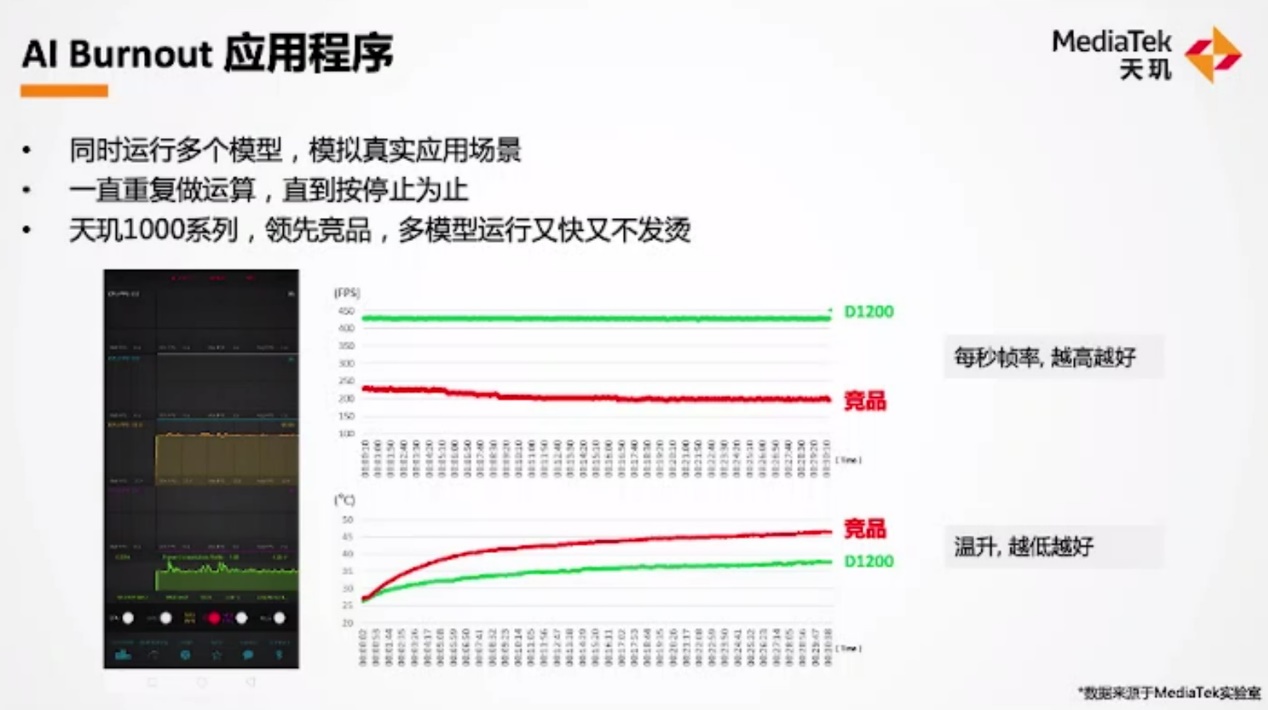
联发科表示,AI Burnout有测试模拟一个应用跑6个AI模型,而且可以长时间地去跑,考验持续性能。联发科认为这样的测试更能反映直播、游戏等AI应用场景的实际表现,因为它们有多模型,以及算力长时间的持续要求。
当然了,很大一部分原因必然是天玑1000系列SoC在AI Burnout中的跑分成绩很好看(这一点可能还需要考虑不同测试工具对于各家芯片厂商AI生态的支持情况)。不过AI Burnout式的测试,或许的确很有手机AI实际应用场景的参考价值,起码比AI理论峰值算力有价值很多。
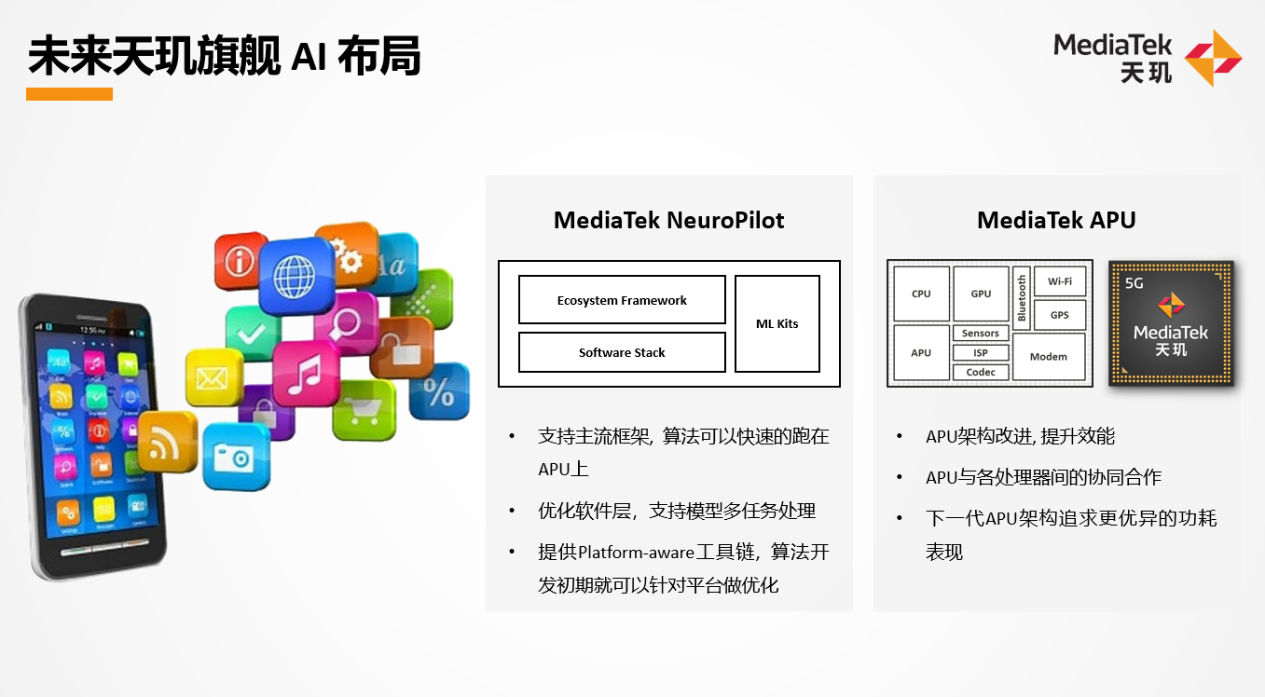
而联发科着力的,总结一句话还是NeuroPilot生态,与APU硬件本身的结合。联发科在对上面这张图做讲解的时候,比较有趣的一点是谈到“下一代APU架构追求更优异的功耗表现”时说:下一世代的架构,“比如存算一体、neuromorphic,可以实现效能10倍以上的提升”。不过联发科并没有再提更多。存算一体、神经拟态是更未来的发展思路了,不知道联发科是不是真的会在近未来去做这些架构的芯片。
为终端厂商开放更自由的能力
这是个很有意思的时代,即手机各方面的技术都是在趋同的,但无论是芯片厂商、终端厂商还是再下一级的开发者,还是锲而不舍地追求“差异化”。那么其上游企业自然会想办法去满足他们的差异化诉求,比如Arm在IP授权模式上就有各种定制化的探索(比如早年Arm的BoC授权),为的是让手机SoC厂商有更大的余地去做基于Arm IP的差异化。
芯片厂商也在提供面向终端厂商的定制方案,比如今年OnePlus Nord 2所用的芯片叫天玑1200-AI,vivo X70/X70 Pro则采用天玑1200-vivo,小米11T采用天玑1200-ULTRA。这些是天玑5G开放架构提供的选择,这里的尾缀是“终端厂商与联发科深度协同合作的平台”,且未来还会有更多类似这样的尾缀合作在全球落地。
天玑5G开放架构并非本文要谈的重点。最后这部分就对此做个简单的分享。联发科的设想是将自家软件、硬件引擎开放给客户。举个例子,比如对于联发科的AI-display能力而言,在显示链路上要增加AI节点,让显示链路穿过AI——使用APU。那么联发科将“显示链路硬件介面(interface)开放”给终端厂商。
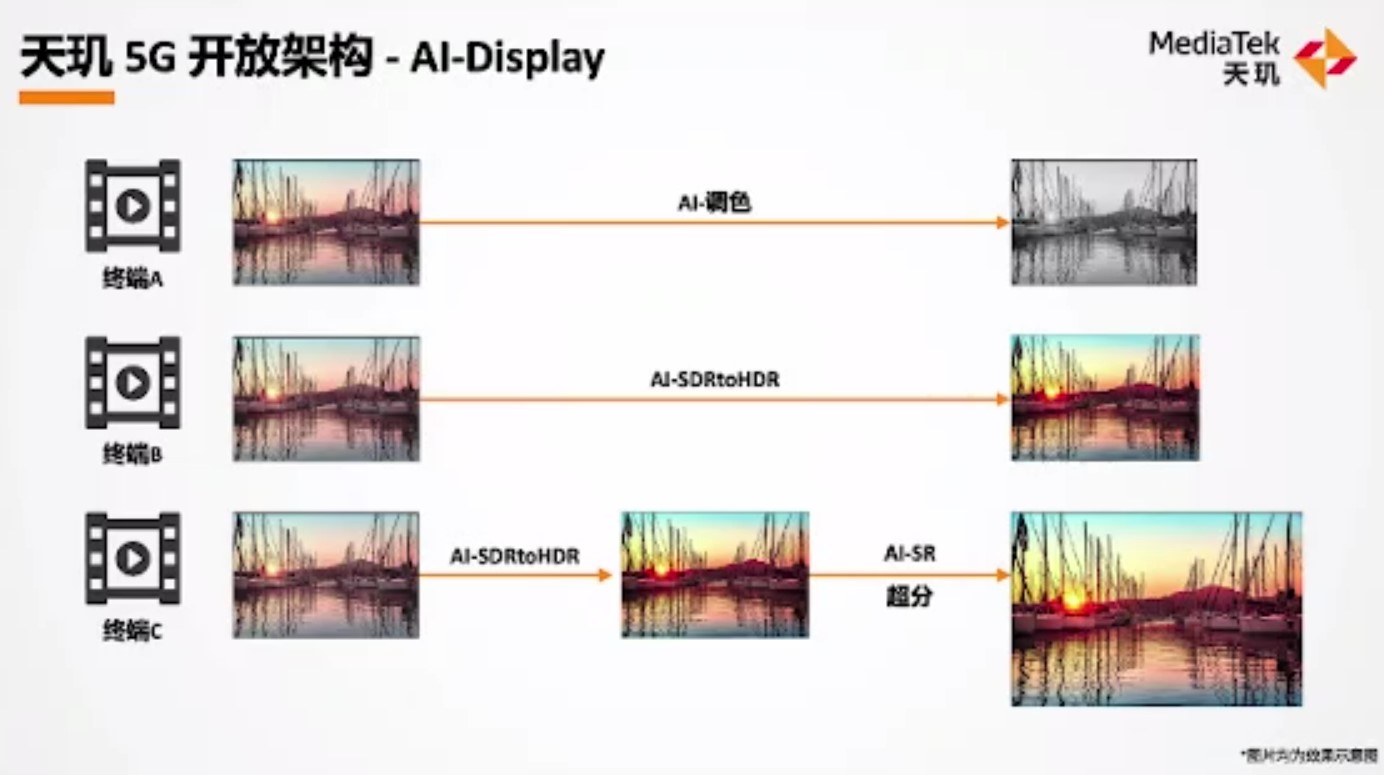
比如针对同一个场景:落日画面的视频播放。客户A期望将颜色逐渐调暗;而客户B则想要通过AI节点(APU),将SDR的画面转为HDR;客户C则希望在此基础上,再加一次超分算法,将其显示在大的画面上。那么这些不同的终端客户都能藉由天玑5G开放架构,来实现不同的选择。这其中的重点在于提供给客户的“介面”,虽然我们仍然不是很清楚这个“介面”究竟处在整个系统中的哪个层级。
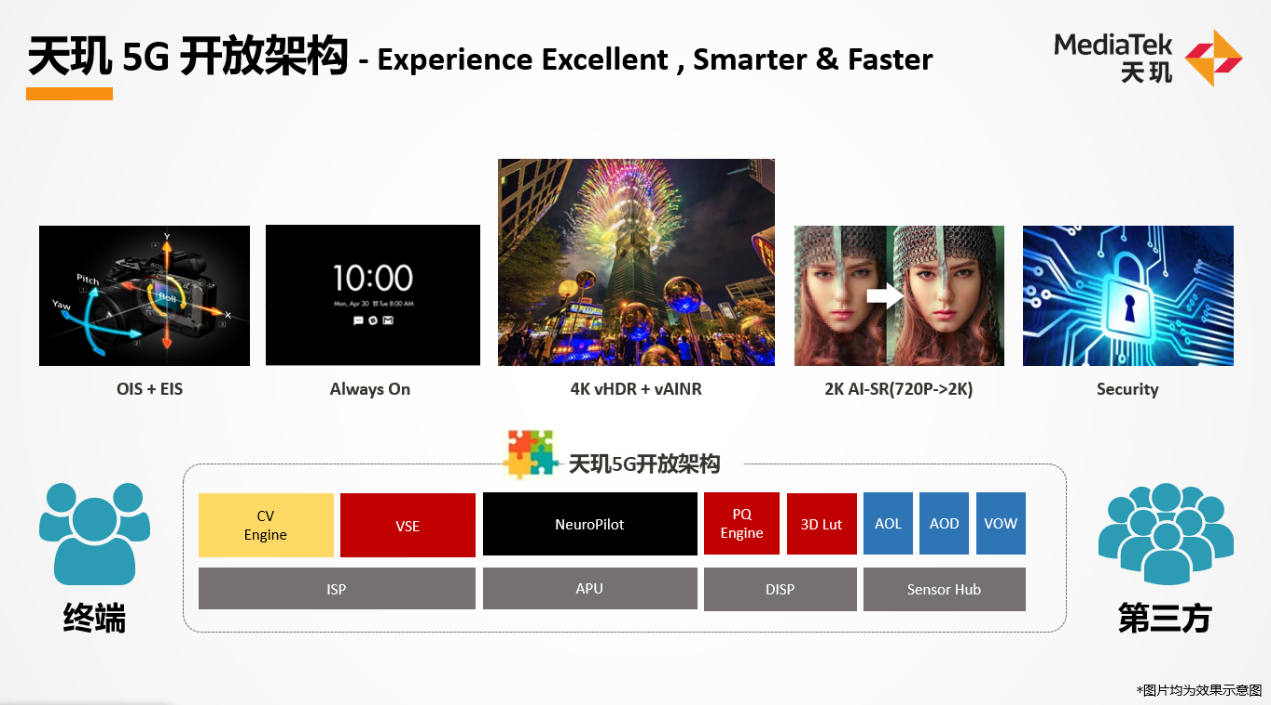
据说在天玑5G开放架构之下,联发科与终端客户的沟通时间提早了很多,即在对应的介面之下,联发科需要做到怎样的参数,包括时延、功耗等。在介面之下进行调校,而在介面之上由客户开发功能。且除了AI-display以外,在安全、游戏等方面都有开放的目标。而且联发科也与三方合作,让三方来提供更多算法和功能,那么终端客户在不做自研的情况下也能有更多的选择。
联发科在答记者问时提到,介面之下仍是通用硬件,“我们提供链路上的接入点,提供更大的弹性”。联发科举例说,“以前联发科针对某个功能提供的链路可能是ABCD,四个模块、四个硬件固定的,客户可以调参数。而在客户提出定制化需求后,或许C的位置开放部分代码,客户可以排在C里面去改一些效果,或者插一些东西进去。在天玑5G开放架构之下,我们开放ABCD四个模块,客户可以用BCAD的方法做排列,甚至可以做AABBC,或者把C换成客户自己的C。”
与此同时,除了在AI方面的开放,后续还会有Connectivity、互联等层面的开放。据说此前联发科有尝试过针对蓝牙提供介面,但发现客户需要很多时间和精力去开发,所以“后续开放架构中,我们会把客户合作的层级或者软件层级往上拉”。有关天玑5G开放架构其实还有技术层面的深入探讨余地,受限于篇幅,未来我们或可再与联发科做交流,这也是个很有趣的议题。
责编:Luffy Liu

