
仅仅使用语音来控制机器的能力已经成为许多商用和消费系统的流行功能了。但是语音控制的问题在于设备必须始终处于监听状态,这意味着必须随时为其供电。不过,更多的新选择正不断涌现,有助于设计人员为其音控设计降低使用功耗。
要让机器对口语指令做出适当响应,是一项巨大的处理挑战。系统必须先有麦克风来拾取声音、数字器将声音转换成处理器可以运作的形式,然后进行大量的数字信号处理,才能从声音中提取语音信息。所涉及的处理量将取决于需要辨识的指令字符数量。词汇量有限的系统可以使用如图1所示的结构进行本地处理,以进行单词检索,而需要自然语音理解的系统则可使用云端运算资源,进行更多的处理。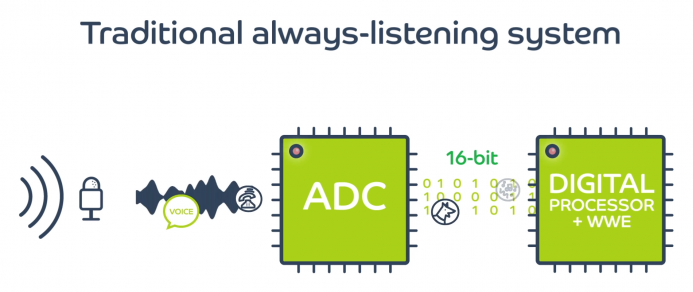
图1:典型的语音控制系统必须不断地处理声音,以寻找指令字词。(图片来源:Aspinity)

遗憾的是,大多数的时间并不会有任何的语音指令,浪费了处理和所消耗的功率。如果要求用户先按下按键等动作以启动语音处理,则可以避免这种浪费。但是,如果仅透过语音唤醒以启动系统,则必须始终撷取并处理声音,以免错过任何指令。这使得以电池供电的应用备受关注,因为语音处理的“常时监听”(always on )本质,可能会消耗大量电池。
为了减少浪费力气以及节省功率的考虑,语音处理系统通常会使用“唤醒”词来启动。这种方法所需的功率较小,因为在大多数情况下,语音处理只需要能够辨识某个特定单词,而不是全部功能的词汇。因此,系统可以在监听唤醒词的同时,执行较简单、功耗更少的处理算法,从而暂停整个语音处理工作,直到检索到唤醒词为止。
业界在追寻这种方法时,已经投入大量精力来开发仅需要最小功率的唤醒单词引擎。通常,这些引擎只能辨别几个单词,从而让用户选择可能的唤醒选项。然而,有些引擎能够辨别足够多的单词,以提供有限形式的语音控制,从而提供多个指令。但是,对于更复杂的语音控制,唤醒词引擎的目的只是为了及时启动一些更强大、更耗电的处理功能,以接收并诠释伴随唤醒词而来的语音指令。
这些唤醒词引擎正在不断发展中。例如,最近市场上推出将Retune的VoiceSpot关键词检测算法与CEVA的低功耗数字信号处理(DSP)系列相结合的配对方案。该组合可以执行波束成形和声学回声消除,以便在出现噪声时提高单词辨识以及唤醒词辨识的可靠性。该算法的总内存占用量低于80KB,适用于诸如耳塞、智慧手表和运动相机等更小的电池供电应用。
最近还有另一个方案采用Cyberon的CSpotter算法,搭配瑞萨电子(Renesas Electronics)的RA6系列微控制器(MCU)。该算法使用基于音素(phoneme)的建模,支持30多种语言。它可以作为唤醒词引擎或使用多种不同的指令集,提供本地语音控制。该处理器为数字麦克风提供I2S接口,从而无需使用模拟数字转换器(ADC)。
这两种方法尽管已尽能地减少语音识别任务了,但仍必须依靠数字信号处理来进行唤醒词辨识。这为“常时监听”的电源需求设置了下限,因而在电池供电的应用中可能仍然很麻烦。事实上,还有另一种技术可以为“常时监听”的唤醒词辨识节省更多功率。
模拟机器学习(machine learning)技术是关键。Aspinity为此开发了“可重配置模拟模块化处理器”(RAMP)芯片,首先将声音辨识为语音,然后再尝试确定语音是否提到唤醒词。RAMP芯片赋予系统的功能是在执行任何语音处理之前,先确定所检测到的声音实际上是语音。如图2所示,当没有任何人在说话时,这种预先确定声音是否是语音的功能,让唤醒词引擎能够持续休眠状态。
图2:RAMP芯片由于能先确定某个声音是语音再进行处理,让语音处理过程得以安全地略过其他声音类型。(图片来源:Aspinity)
该芯片使用模拟神经网络来实现这一目标,该模拟神经网络经过训练可以区别人类的语音以及其他声音,然后向语音处理系统发送启动信号,以确定语音是否在说某个唤醒词。为了确保语音处理具有完整的语音工作模式,芯片将会在快取开始之前缓冲500毫秒(msec)的撷取声音。当芯片辨识到声音为语音时,就会将传入的声音(从开始传送数据之前)引导至语音处理系统以进行解释。
这种方法仅在RAMP芯片持续供电时才能维持语音控制系统。每当没有人在讲话时,语音处理硬件(包括唤醒词引擎)就可能保持休眠状态。在大多数情况下,没有语音的时段表示系统运行的大部份时间。相较于唤醒字检测所需的典型数十毫安(mA)电流,RAMP芯片和主机MCU仅需要约25uA的电流。因此,相较于“常时监听”的唤醒字检测,忽略静音和非语音的能力可以节省大量功率。
在语音控制中,这种降低功率的创新很可能继续发展,从而将语音启动操作的潜力从线性供电到电池供电设计,一路扩展到实际应用。无论透过语音控制特定设备是不是个好主意,也无论其电源如何,它都已经成为一种实用的选择了。
责编:Luffy Liu