
“摩尔定律”估计是行业内被提及频率最高的词之一了,又是这两年的热门话题。从不同市场参与者的角度,大家对于摩尔定律是否放缓或停滞是各有说辞的。比如尖端工艺foundry厂,普遍会说摩尔定律还能延续很久,不信看我们的roadmap;比如AI芯片厂商倾向于说,摩尔定律放缓是事实,我们需要架构革新;学界则说,材料革命必将来临......
这两年我们探讨有关摩尔定律的话题也不少,包括算力需求依然强劲,但半导体器件尺寸微缩速度却实实在在放缓了,该怎么办的各类文章。本文再从相对实际的角度来谈谈,摩尔定律放缓的各种外在表现;也算是从更全面的角度来理解摩尔定律的放缓。

系统地谈摩尔定律停滞的paper非常多,包括前年我们写的《深度学习的兴起,是通用计算的挽歌?》较多参考了MIT的那篇paper(The Decline of Computers as a General Purpose Technology: Why Deep Learning and the End of Moore’s Law are Fragmenting Computing)。
美国CSET(Center for Security and Emerging Technology)去年4月写过一篇paper,题为AI Chips: What They Are and Why They Matter*,阐述摩尔定律放缓的思路和MIT那篇大同小异。不过在细节上作了更大程度的完善。本文我们参考其中提供的一些数据,有兴趣的读者可参考文末的reference做进一步的深入理解。
从AI芯片成本,来看摩尔定律的放缓
这些paper有个非常大的共同点,即本身是探讨AI芯片,前面却会花很大篇幅去谈摩尔定律放缓的事实。在大规模数据并行计算方面,AI芯片效率和算力上,甚至能够达到CPU这种通用芯片的1000倍。要是换算成摩尔定律,则CPU需要26年时间才能达成这种程度的提升。
虽然总感觉这种说法相当的流氓,通用芯片和专用芯片无论如何都不该这么比,但这表达的是行业的整体转向。因为AI芯片实实在在的部分抢占了原属于CPU的市场份额,无论AI芯片形态是GPU、FPGA还是ASIC。CPU在未来甚至有被各类专用芯片边缘化的可能性——这一点在《深度学习的兴起,是通用计算的挽歌?》一文中已经有比较详细的阐述。
本文不会着重去谈AI芯片,但即便是AI芯片,其效率也和制造工艺关系甚大。传统认知中,ASIC类别的芯片由于市场更窄,所以考虑到成本摊薄的问题,ASIC芯片总是更倾向于采用更旧的工艺,而不是尖端工艺。但AI芯片如今市场非常大,有相当规模的ASIC AI加速芯片也都开始用7nm这样的尖端工艺,或次尖端工艺;而相对通用的数据中心GPU采用尖端工艺则是必然。

抛开AI技术本身的高速发展,包括各种模型、算法和库优化方案造成的性能和效率提升,AI芯片在制造工艺层面也受制于器件尺寸微缩,或其他先进制造封装技术。所以我们首先来谈谈,摩尔定律是如何影响AI芯片的——这也是个很有意思的话题。
AI芯片选择何种工艺还是颇有讲究的。AI芯片的总“成本”需要考虑到后续的运营成本,比如说用旧工艺,则大规模AI计算(如数据中心training)的电力开销和效率会显著更低,甚至这种运营成本会远高于芯片制造成本。这些也需要考虑到AI芯片的成本中去。这就涉及到成本效益计算了。
具体应该计量的“生产成本”包括了制造成本——fab工厂、设备架构消耗、材料、人力、R&D投入、利润;设计成本——fabless企业需要投入的;此外还有ATP(封装测试,assemble, test, package)成本。所以这里定义生产成本包括foundry厂制造成本、芯片设计成本以及ATP成本。另外还需要考虑到芯片的运营成本,主要是能耗成本。

该对比基于相同晶体管数量,以Nvidia P100 GPU服务器级别芯片为参考;对于一些更老的工艺,也需要考虑到reticle limit,所以老工艺实现同等晶体管数量,会换算成多颗chip构成一个系统;注意这个对比可能并未考虑其他层面的AI优化技术和系统互联折损
从CSET这份paper构建的模型来看,在不到2年的时间里,尖端工艺AI芯片(7nm/5nm)的运营成本,就会超过其生产成本。而旧工艺AI芯片(90nm/65nm)的运营成本在此期间可能达到生产成本的3-4倍之多。上面这张图是将一颗芯片的运营时常拉长到3年(也就是芯片用上3年),则在不同工艺之下的AI芯片,所需支出的能耗成本逐年增加。
这张图表达的一个重要信息在于,同时计算生产和运营成本,尖端工艺AI芯片的成本效益会比旧工艺AI芯片,高出至多33倍。
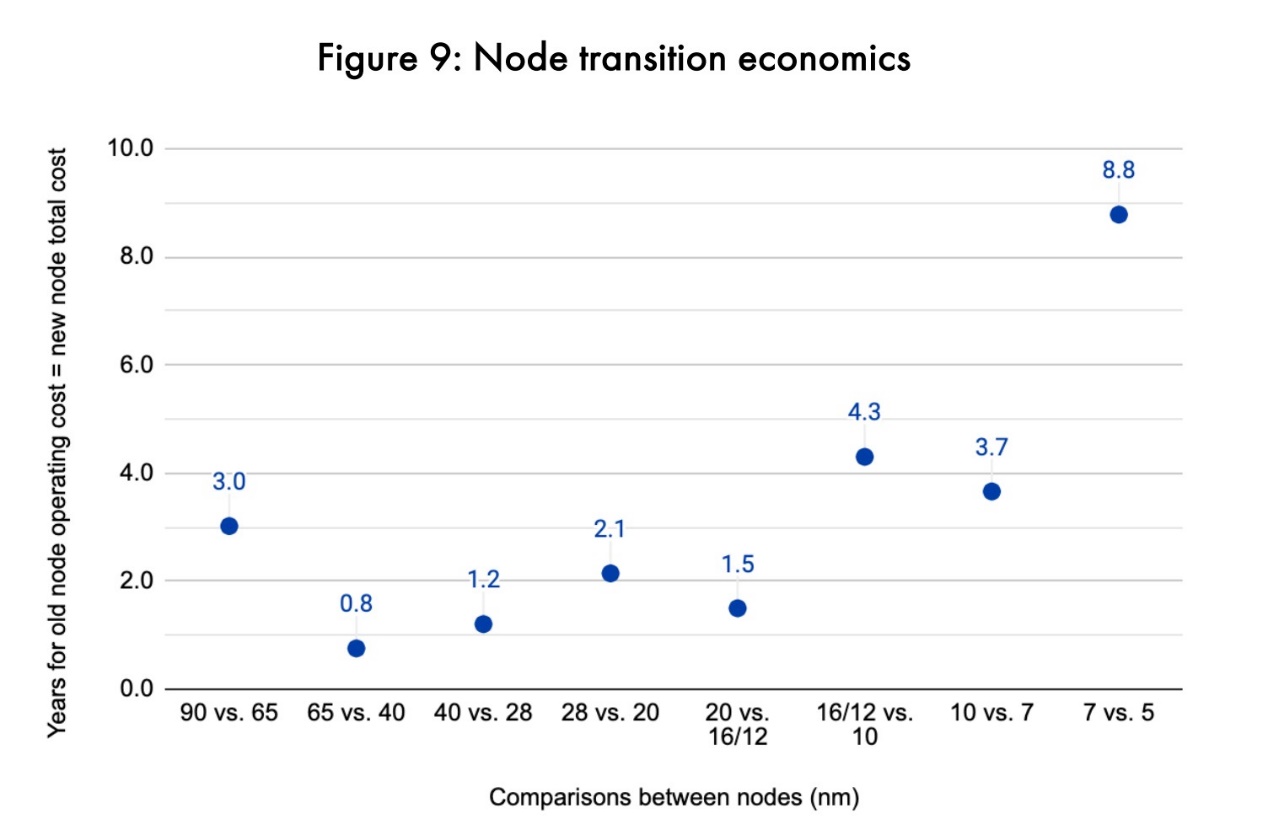
这里随即得出更有趣的一些结论,也就是在运营时间达到多久以后,新旧工艺之间谁才更划算的问题。上面这张图作了这方面的表达。比如说90nm工艺和65nm工艺相比,运营时间以3年为界限,低于3年的情况下90nm造AI芯片更划算;如果芯片要用3年以上,则65nm更划算。
这其中可表现出摩尔定律放缓的一点在于,在7nm vs 5nm这一代,运营时间临界值显著增加。对于一颗5nm工艺的AI芯片而言,运营该芯片8.8年所需的成本,加上生产成本,可达成与7nm芯片相同的生产+运营成本。也就是说,在运营不足8.8年的情况下,以7nm工艺来造芯片更划算;而达到8.8年以上,5nm工艺更划算。
事实上,企业更新服务器芯片的常规周期是3年或以上,和如今工艺新节点迭代周期差不多——理论上,每次有新工艺出现,服务器芯片就可以做一次同步更新。但在5nm这一代,企业对这代工艺的采用,恐怕需要更久时间才能达到成本效益。
这是摩尔定律对AI芯片达成直观影响的重要体现。当然还是需要强调,该模型构建是CSET做的——它可能没有考虑到器件微缩之外的其他技术因素。不过我们认为,大方向的确如此;或者这个结论至少可表达摩尔定律的显著放缓。这个思路还是挺有意思。

摩尔定律放缓的一些实际数字
摩尔定律从上世纪60年代提出,假设到如今是满速运转没停过、没放缓的,那么现在芯片上单位面积内应有的晶体管数量,应该比现在实际的量多出15倍。这个结论来自Communications of the ACM杂志2019年2月的一篇paper (A New Golden Age for Computer Architecture)。
从可追溯的数字来看,1978-1986年CPU每年速度提升22%,主要是基于时钟频率提升(frequency scaling);1986-2003年,CPU速度每年提升52%,主要是得益于频率提升,以及设计优化——尤其是并行计算;2003-2011年,每年速度提升23%,这一阶段频率提升是放缓的,但多核设计依然实现了更高的并行度。而2011-2015,CPU并行计算再次发力,也才促成了12%的每年速度提升。
从能效的角度来看,2000年之前CPU最高达成每1.57年整体效率的翻倍提升;但自从摩尔定律放缓,以及晶体管功耗红利的持续下降,这个速度放慢到了2.6年。这些数字基本也算是共识了。一个更直观的状况在于,Intel的32nm与22nm工艺都是在前代工艺的2年后更新的,与摩尔定律基本保持一致;但22nm与14nm,中间隔了3年;14nm和10nm迭代之间,中间隔了4年。
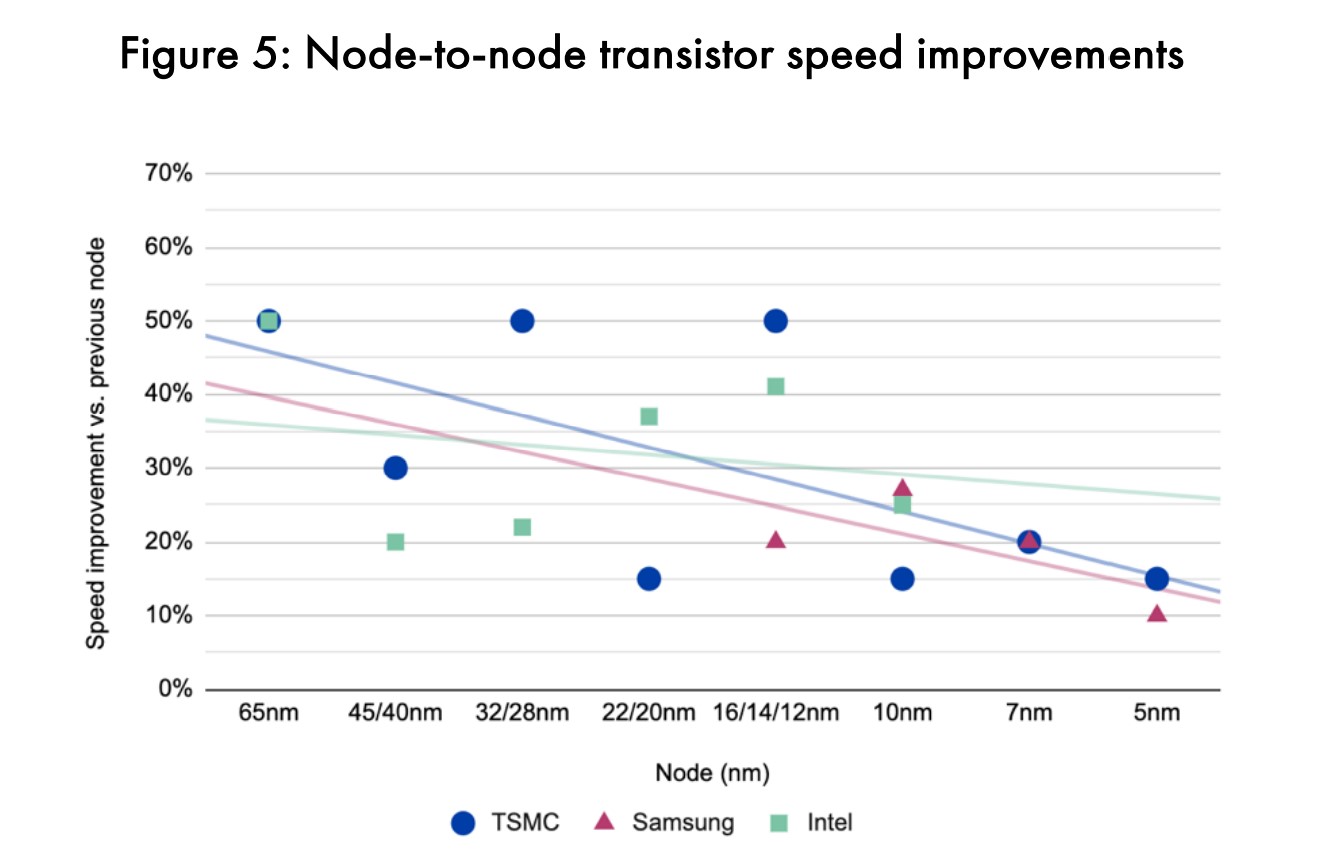
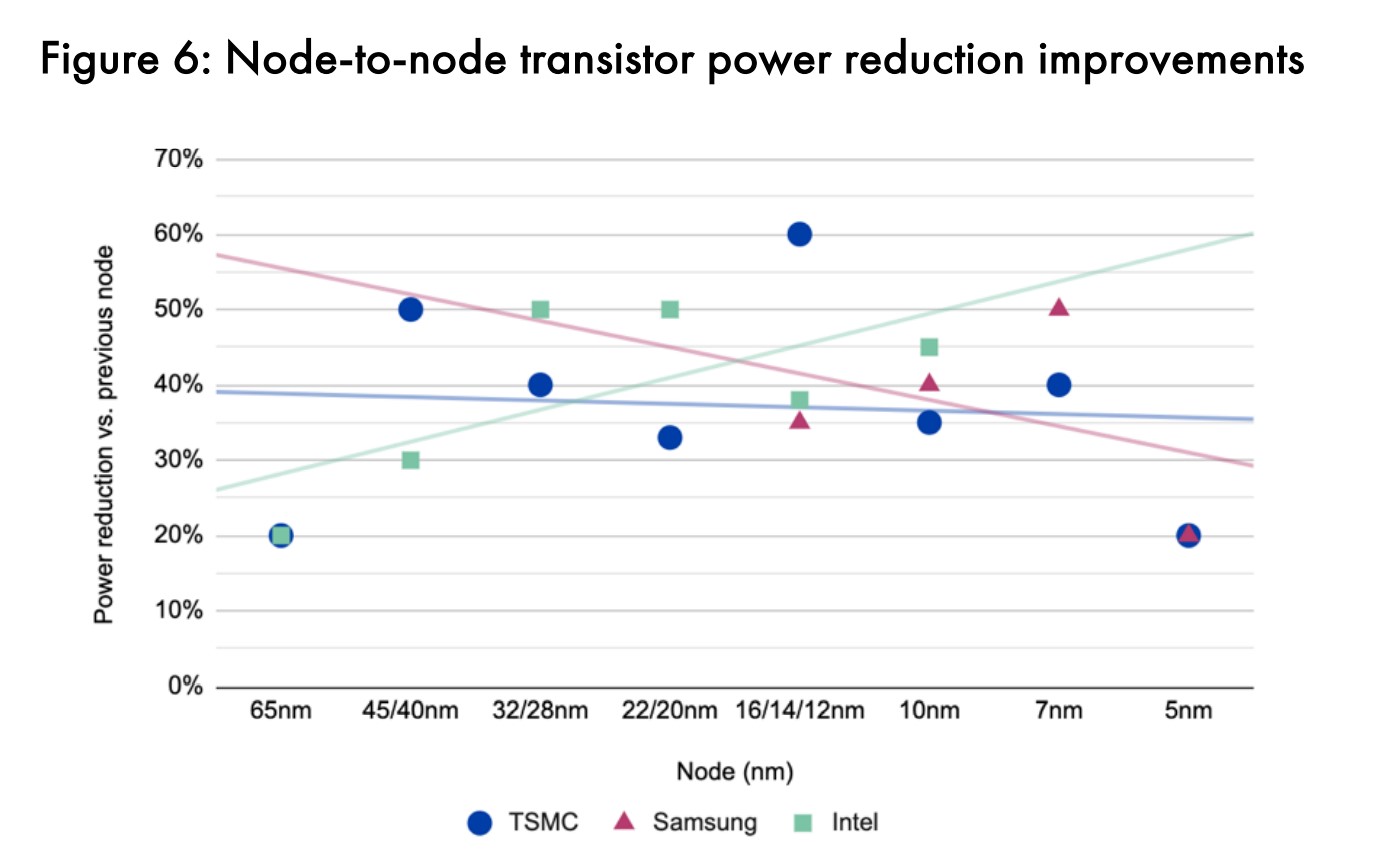
而且在器件尺寸微缩的同时,功耗表现和性能的提升未能保持同步。2004年前后,65nm节点实现晶体管密度提升之际,功耗降低和速度提升是相对更加迟缓的。上面这两张图展示的是从90nm到5nm发展期间,台积电、三星与Intel各代工艺节点之间的晶体管开关速度(frequency scaling)和功耗变化(相比上一代的变化百分比)。
台积电可能是颇具代表性的,即从拟合的趋势线来看,符合我们对摩尔定律放缓的认知,一路在速度提升、功耗降低方面变慢或趋于平坦;Intel的情况是性能提升亦在放缓,但与此同时确保更好的功耗表现。(这些数字主要是基于台积电、三星和Intel在发布会上公开的信息)
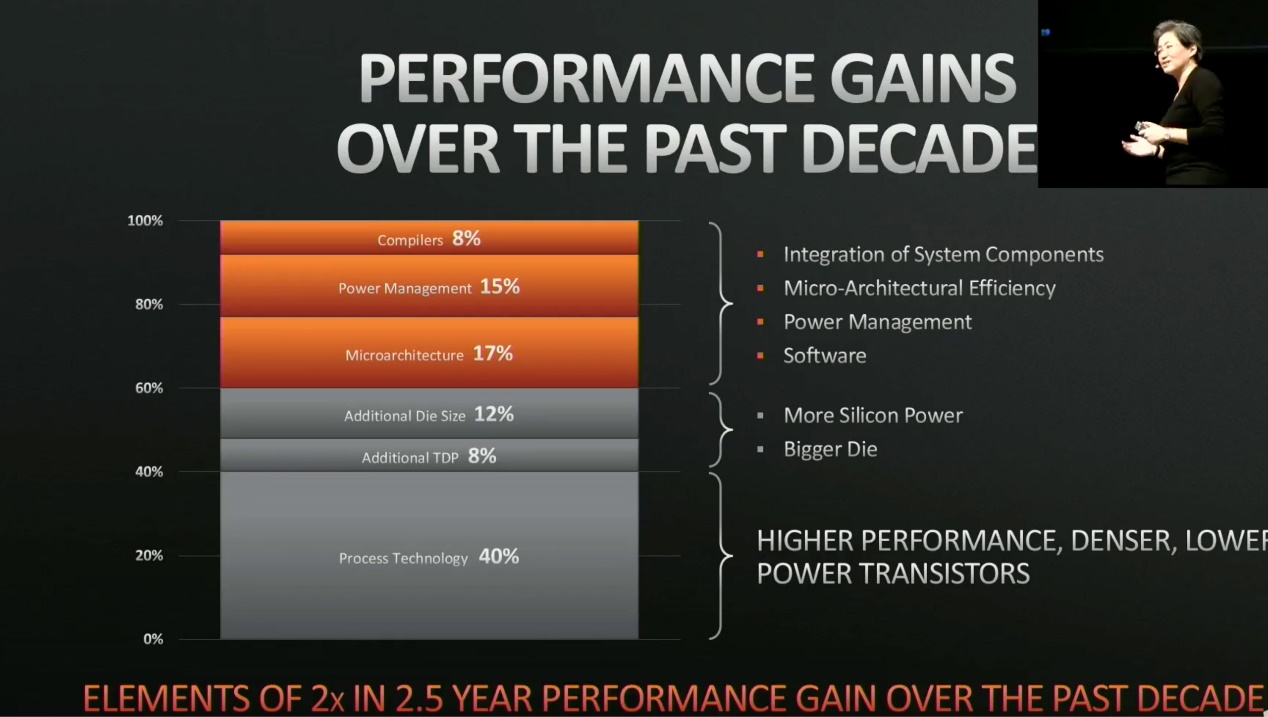
其实将这些数据与处理器这些年的性能提升与功耗降低作比较,就会发现晶体管层面的创新,对于处理器过去15年的效率和性能提升,还是扮演了最重要的角色的。此前AMD在HotChips上也明确过,即过去10年间,造成处理器性能提升的主要因素中,占比最大的就是工艺技术的进步。它比编译器、微架构、电源管理等方面的贡献都要大得多。
不过有个通用处理器性能与效率提升放缓的事实值得一提:抛开一些增加专用固定电路的方案不谈(比如说给CPU加入AI指令支持等),为通用处理器增加更多的晶体管能够带来的性能提升变得越来越有限。这主要是因为能够从并行计算获得的速度提升,这些年受到边际递减效应的影响。
并行度本身是受限于串行计算的时间占比的(比如线程间的计算结果有关联性,则无法实现并行计算)。某个算法中即便仅有1%的部分需要串行计算,那么处理器能耗也将有45%的浪费(因为此时处理器运算单元的闲置率很高)。
而实际上大部分应用所需的串行计算占比还不止这些,则浪费也就更大。处理器架构拓宽、核心数增加、晶体管增加,很大程度都是增加并行度。其中的边际递减效应是存在的。这也是通用处理器在摩尔定律持续之际的尴尬所在。
工艺迭代的技术难度与成本飙升
有关制造工艺技术提升越来越难,无论是材料、制造还是各不同角度,这已是共识。也是因为技术挑战的存在,导致尖端工艺更新越来越难。Intel 10nm以及Intel 7工艺的难产都与此有莫大关联,更不用提GlobalFoundries很早就退出了7nm工艺技术的竞争。
早前《深度学习的兴起,是通用计算的挽歌?》一文已经相对详细地探讨了,工艺迭代在成本方面的飙升。即当前的普遍认知在于,单纯就尖端工艺的建厂成本之高,及每次迭代带来成本的急剧攀升,可能已经超过了半导体行业本身的年复合增长率。
在这样的大背景之下,唯有通过减缓工艺迭代的节奏,以及提升foundry销售服务的价格,并且还要侵吞更多属于竞争对手的市场,才有生机可言。AI Chips: What They Are and Why They Matter这篇paper给出的数字是,如今半导体生产设备年增长率11%,平均每颗芯片设计成本增长24%,比半导体市场7%的增长率还要高。
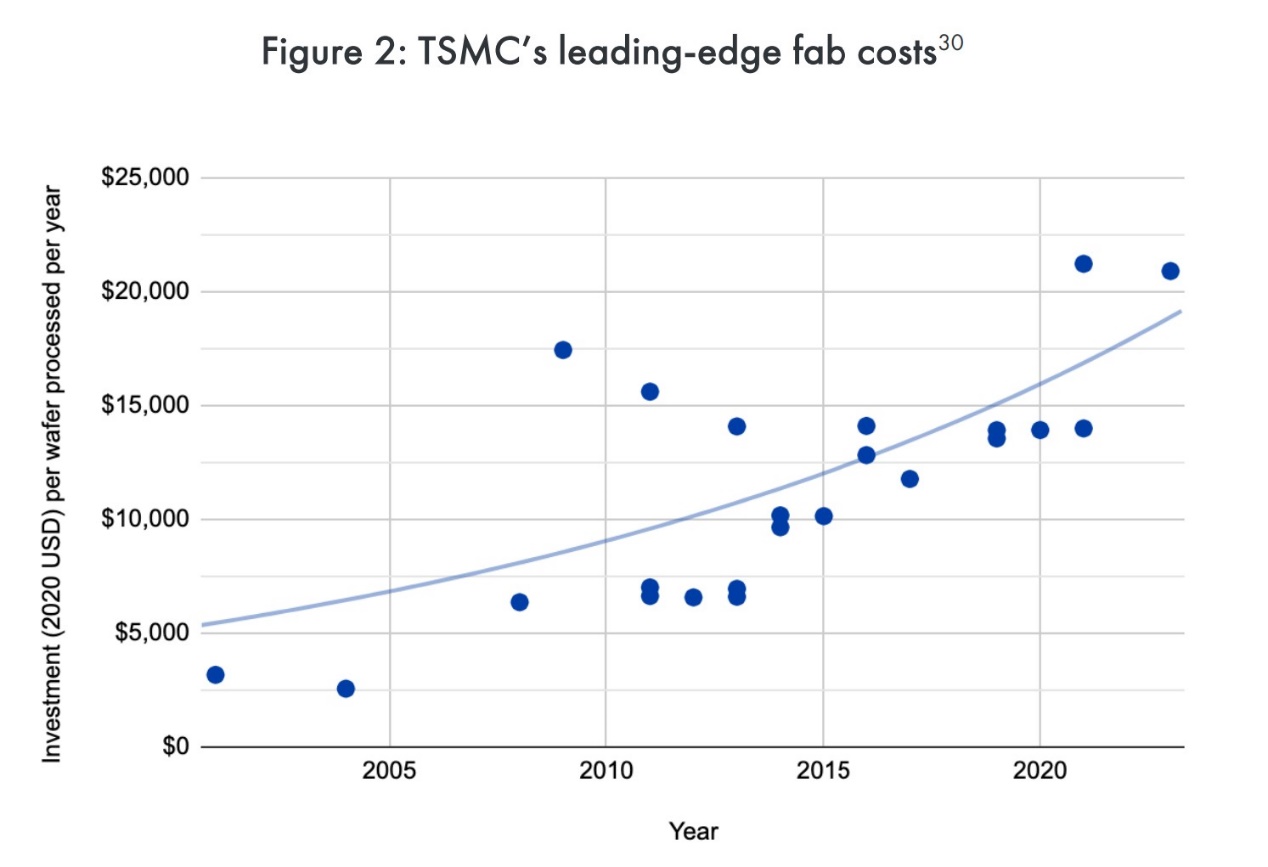
这个数字比MIT给的还要悲观。无论谁家数字更准确,尖端工艺投入成本的增加是不争的事实。在半导体制造设备中最为昂贵和复杂的组成部分,尖端工艺lithography工具,1979年每台45万美金;2019年是1.23亿美金。
所以其实这么多年来,参与尖端工艺研发生产的芯片制造商,和lithography设备企业数量都是在逐年下降的。(90nm以后,除了ASML之外,尼康成为唯二的参与者;到5nm也就只剩ASML)
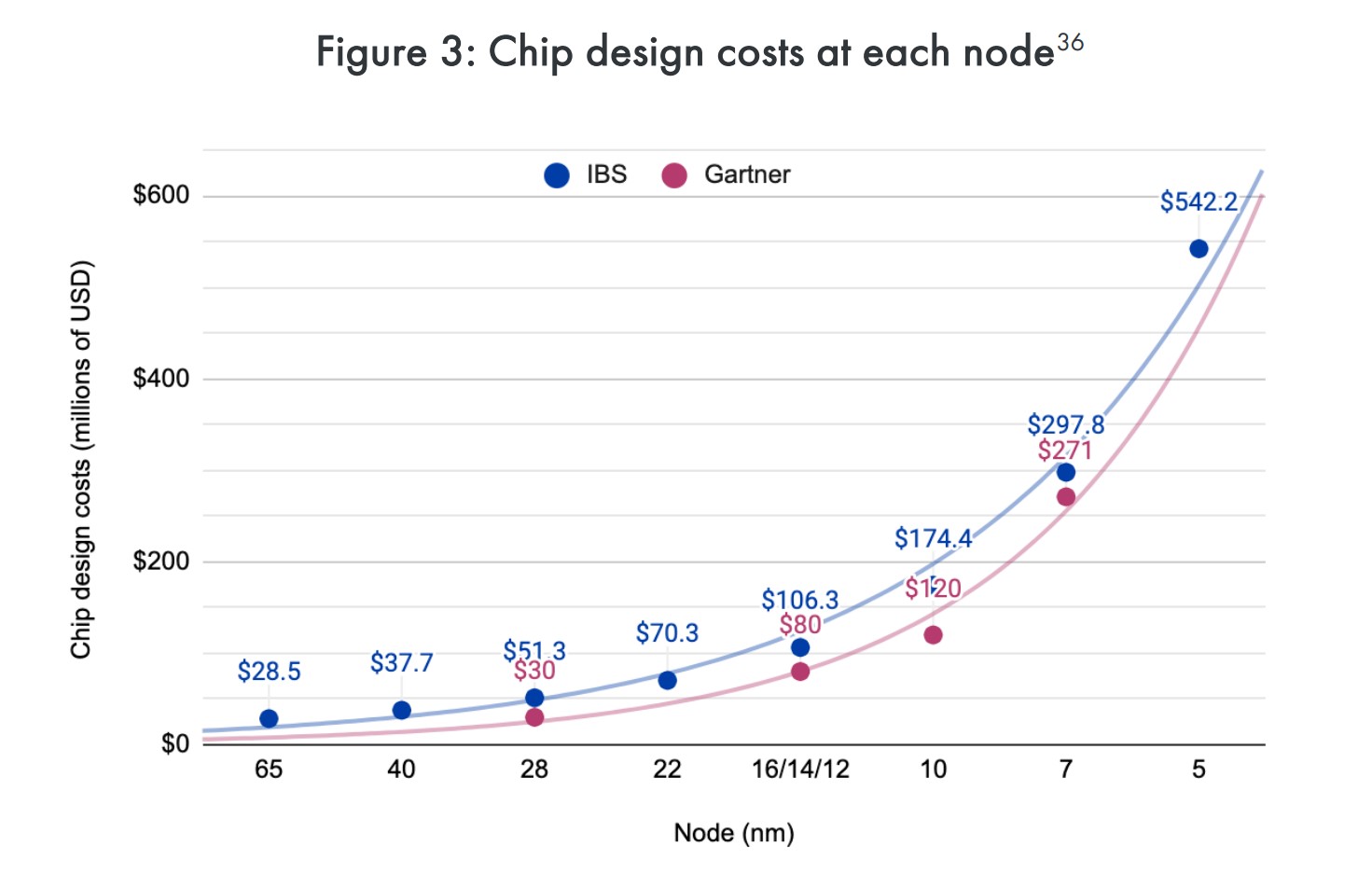
上面这张图是不同工艺节点,带来芯片设计成本的提升,分别来自IBS(International Business Strategies)和Gartner,数据量级和趋势都是一致的。设计成本提升,除了复杂度提升和时间成本增加,半导体行业用人成本也在显著增加。据说2015年和1971年相比,人力研究投入增加18倍,每年提升7%。
以每一个晶体管的设计与制造成本为指标,来衡量工艺节点迭代是否保持经济效益,听起来是比较靠谱的。2018年有篇题为Measuring Moore’s Law: Evidence from Price, Cost, and Quality Indexes的内容做过这方面的考量,即历史上曾有一段时间,这个指标每年下降20-30%——也就是工艺迭代带来了更高的经济效益。但部分分析师认为,自28nm以后,该趋势便不复存在。

期望这些数据能够给读者更多的思考。最后我们给出一些摩尔定律停滞和放缓的“解决方案”文章,虽然这不是本文要谈的重点,来自不同层级的市场角色或技术。比如晶体管结构革命;比如如今谈得很多的more than Moore,先进封装技术;还有EDA厂商在提从系统层面来实现性能与能效整体提升的;
以及AI芯片及更多专用架构芯片的问世,大幅提升不同应用场景处理效率的方案;还有对冯诺依曼体系革命的存内计算等等新技术……都可能成为半导体行业续命的存在,附在本文的最后。通过微信阅读本文的同学可在电子工程专辑主站查看以下内容:
- 异构集成、器件结构、先进封装等综合解决方案;还有存内计算、神经拟态计算;
- 架构革命:软件定义芯片;
Reference:
* Saif M. Khan and Alexander Mann, "AI Chips: What They Are and Why They Matter" (Center for Security and Emerging Technology, April 2020), cset.georgetown.edu/research/ai-chips-what-they-are-and-why-they-matter/. https://doi.org/10.51593/20190014
责编:Luffy Liu
- 讲得有点意思

