
本文的上篇大致解释了苹果M1实现的“统一内存架构(Unified Memory Architecture,UMA)”实际上并没有什么稀奇,AMD在十多年前就在APU产品上做这一理念更全面的实践了。
只不过AMD未能将APU with HSA的生态做起来,因为APU的理念是让GPU和CPU集成到一起,并同时处理日常工作,尤其是在CPU的矢量及其他大规模并行计算算力不足时,集成在同一片SoC上的GPU能立马顶上——这个思路固然是好,但也要求开发生态的配合,CPU不会无缘无故就将工作分给GPU去完成。
如上篇所述,AMD高估了自己的生态话语权,除了游戏主机这个主场,PC领域APU完全体的HSA联盟和生态未能如预期般强盛起来。如今应用于PC的APU更像是单纯将CPU、GPU放在同一颗die上的普通处理器,HSA开发生态已经处在了荒废状态;而且AMD的APU产品如今集成的GPU核显,在性能上也未能如十多年前APU刚诞生之时预期的那样,显著优于竞争对手;AMD处理器的UMA也就随之成为历史了…吗?


苹果虽然晚于其他市场竞争者很久才入世,在发布M1之时才提出了UMA统一内存架构,但凭借其在生态构建方面的独特话语权,却在CPU+GPU+其他加速器的异构计算方面,有着无与伦比的优势。不过有关桌面处理器异构集成、UMA的故事并未就此结束。本文的下篇,我们来补充谈谈各路竞争对手在UMA实现上的努力。建议在阅读下篇之前,首先看一看本文的上篇——以便理清异构集成、HSA、hUMA、UMA等词汇表达的涵义差别。
Intel家上古时期的UMA
以“统一内存”这个说辞来做市场宣传的,其实远不只是AMD、苹果——毕竟异构集成是市场发展的总体趋势,市场的主要参与者普遍都能看到UMA这样的技术红利。比如英伟达也在大约6、7年前就提到了Unified Memory,虽然在实现方法和阶段上,大家都是有差别的(比如是否真正实现了共同内存地址,还是部分实现,抑或对上层隐藏了更多复杂的实现细节)。
在下文谈UMA之前,我们首先来回顾一下苹果的UMA究竟是怎么回事。为普罗大众所知的是,苹果M1实现的UMA,主要是让RAM内存面向CPU、GPU时,采用统一可访问的内存池。因为传统方案的CPU和GPU即便放在同一颗SoC上,且访问相同的物理内存,但由于它们对内存的不同访问习惯及数据结构,所以CPU和GPU针对内存的存取空间是分开的,需要在内存的不同空间之间来回复制数据。M1则不需要执行这种数据复制操作。
但苹果在其M1芯片的UMA实现上语焉不详,其新闻稿中只提到了两句:“M1采用统一内存架构(UMA)......”“这让SoC上所有的技术组成部分,不需要在多个内存池之间进行复制操作,就能访问相同的数据,进一步提升了性能和效率。”
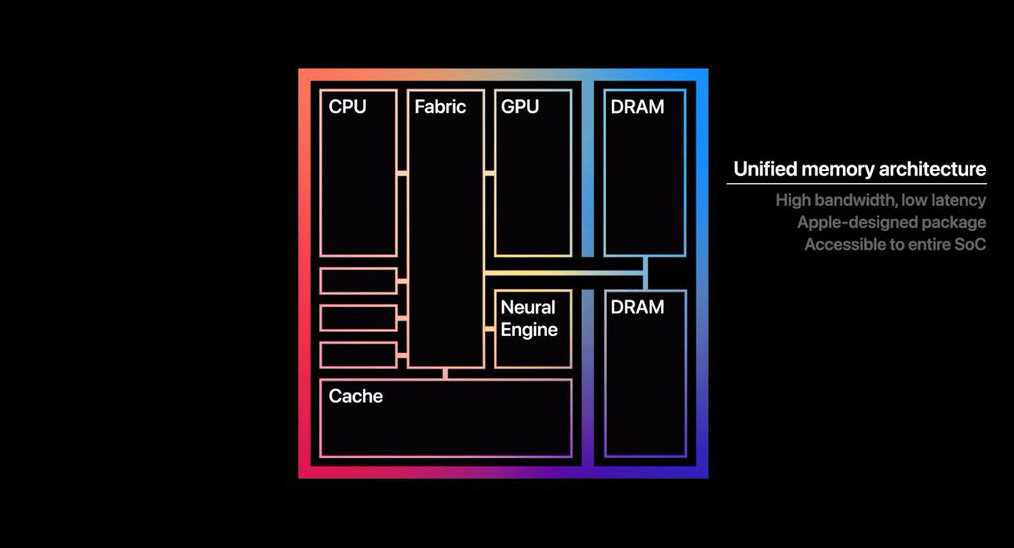
其实“访问相同的数据”这一点,在硬件层面以及中间层实现方式上是多种多样的,且历史悠久。这句话约等于什么也没说。至于“不需要”“进行复制操作”,这一点也不稀罕,后文会提到。在此,苹果也并没有说清楚他们定义中的UMA究竟是什么概念,尤其硬件层面究竟要走到哪一步。
从苹果公布的这张图来观察,其实也看不出什么花样来。CPU、GPU、Cache(应该是SLC)、NPU都连接到Fabric上,两片DRAM亦如是。这种方案算不算得上高端呢?我们来看看别家是怎么做的。
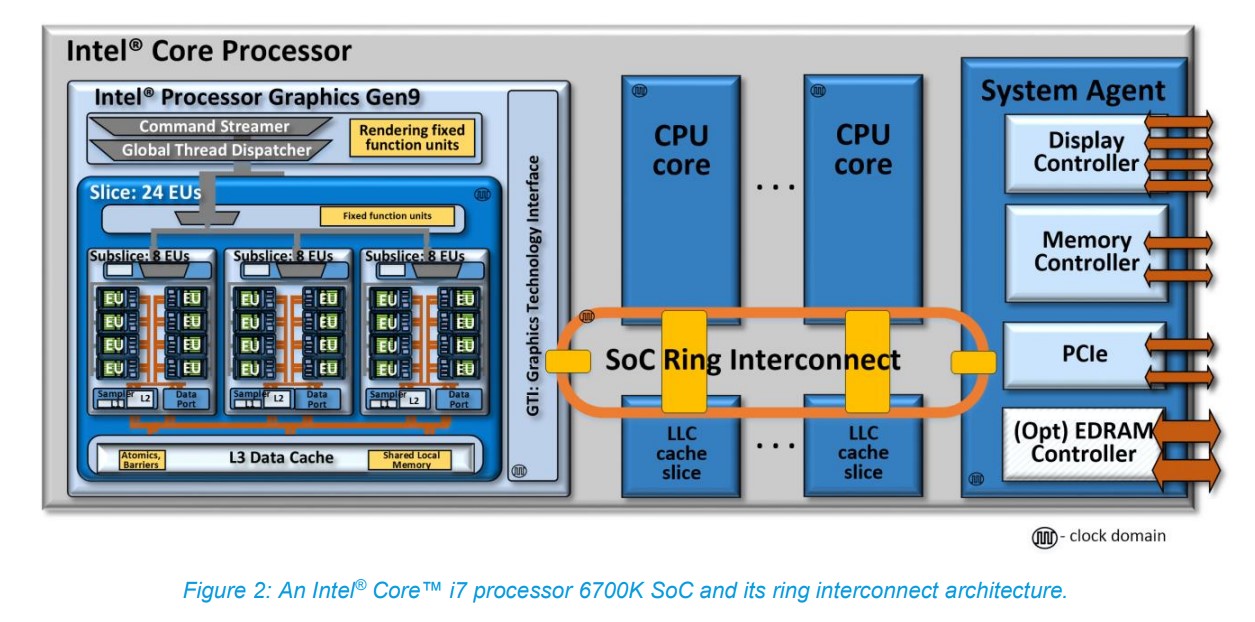
上面这张图是Intel第六代酷睿处理器(Skylake,2015年)i7-6700K的ring互联架构。这一代的酷睿处理器集成了Intel Gen9核显(上图中的左边部分)。从这张图就能看出来,CPU核心、LLC(last level cache)、GPU,还有System Agent之间有个片上总线,叫SoC Ring Interconnect,而且每个连接对象都有这个专门的本地接口。
这里的SoC Ring Interconnect是个双向ring环——对Intel处理器熟悉的同学对此应该也不会陌生。GPU在这个层面,就像是CPU的某个核心一样,也处在互联ring的一个agent环节上。右边这一侧的System Agent包含了DRAM内存管理单元、显示控制器、其他芯片外的I/O控制器等。
内存控制器自然就要通往内存了。Intel在Gen9的计算架构介绍中特别提到了。“所有来自或者去往CPU核心,以及来自或者去往Intel GPU的(片外)系统内存数据交换事务,都经由这条互联ring实施,通过System Agent以及统一DRAM内存控制器。”
仔细想一想这种结构,再回看苹果M1的那张图,是否感觉双方的差别并不大(只不过那会儿还没有NPU这种东西)?另外尤为值得一提的是,Gen9这张互联架构图中可见,LLC cache也作为单独的agent节点连在ring上。Intel在文档中提到:“该LLC也与GPU共享。对于CPU核心与GPU而言,LLC着力于降低访问系统DRAM的延迟,提供更高的有效带宽。”
也就是说,从很多年前开始,Intel处理器内部的核显其实是连片内的LLC cache都是可以访问的,和CPU核心算是平起平坐。这里面当然有更复杂的一些访问机制,包括存储一致性、分层级的存储访问问题,以及到系统内存如何实现CPU与GPU的“统一访问”等。这其中似乎关系到很多奇技淫巧,对于“统一存储访问”的定义可能不是本文上篇提到的“共同地址空间”这么简单。
事实上我们也并不清楚苹果在M1芯片上究竟是怎么来定义和实施“统一内存架构UMA”的。但我们起码也知道了,UMA这个东西是大家都在做的。不光是AMD、Intel,其实还有Arm(所以苹果以前的芯片有没有在做呢?)。虽然可能大家对于UMA的实现方法和效率都存在差异。
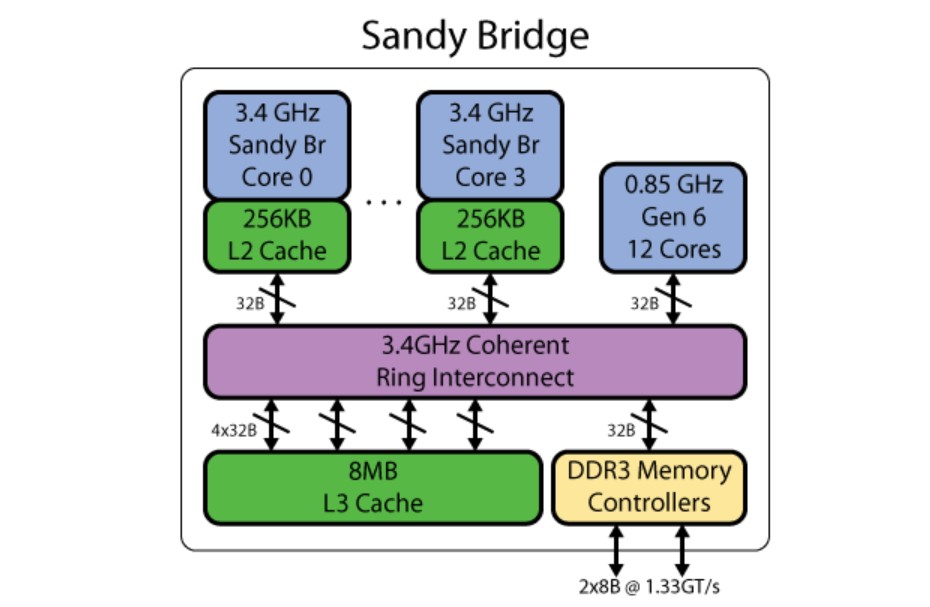
可能有同学会好奇,Intel最早是从什么时候开始搞类似的方案的?我们简单查了一下:从维基百科的记录来看,Intel是从Gen5开始将主板上的“集显”,移往处理器SoC内部成为“核显”的(Arrandale/Clarkdale,2010年)。不过Gen5时代的内部互联架构已经不大可考,但我们找到了前人总结的Gen6核显(Sandy Bridge,2011年)互联架构,如上图所示。
大体上看起来是不是还是那个味儿?或许Intel和AMD对于广义上UMA的实现差不多是同期。这一刻是否感觉苹果M1的UMA也没什么大不了?虽然还是那句话,我们不清楚苹果究竟是怎么去实施UMA的,或者从过去的A系列芯片到如今的M1,期间是否经历了什么。
以另一种方式延续的HSA
回到AMD本身,上篇我们提到了AMD的HSA生态实现是分阶段、分步骤的——虽然现在PC领域的HAS生态和工具似乎已经“停更”了,不过在这其中我们关注的UMA统一内存架构/访问的问题,AMD从2012年以来的更新节奏还是比较清晰的。
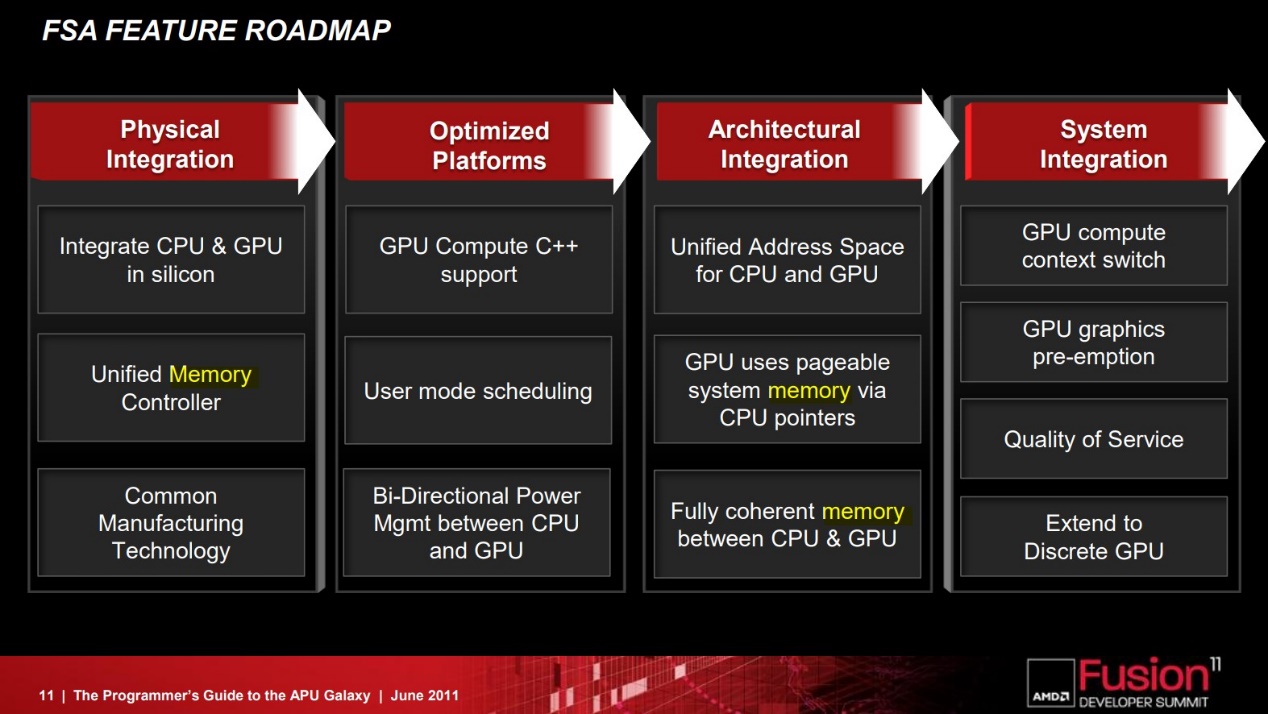
这是AMD当年给出的APU HSA特性更新,在上篇中我们也已经谈到了其中相关UMA的一些实现。从2012年GPU能够通过HSA MMU访问整个系统内存,到后来CPU的MMU和GPU的IOMMU共享相同地址空间,指针能够在CPU和GPU之间传递,实现所谓的“zero-copy”零拷贝,这跟苹果所说不就是同一回事吗?
与此同时,2014年的APU也有了CPU和GPU之间的完全一致存储——这和前文提到Intel片内共享LLC的方案异曲同工,虽然实现上差别似乎不小;还有GPU能够使用页交换的虚拟内存——上篇中已经提到了这一点。
不过AMD在2011年就发布文章提过APU对开发者而言的zero-copy。AMD APP SDK 2.5引入zero copy传输路径,在实现上似乎是在可访问的GPU内存区创建一个内存buffer,将其映射到CPU,CPU和GPU从逻辑上实现对这部分buffer的传输控制。其更底层的实现不得而知。不过极有可能,AMD对于“zero-copy”的实现在2011年之后,芯片设计或者说硬件层面又有新的变化——毕竟UMA的实现这么多年都有各层面的进步。
而2013年OpenCL 2.0带来了shared virtual memory特性,其中第一项就是共享虚拟地址空间。Intel当时还特别在宣传中提到这项特性需要专门的硬件一致性支持,例如其当时的Gen8 GPU。多提一嘴,从当年Llano系统架构分析来看,它在CPU与GPU的一致性存储实现上可能比Intel还稍稍晚了一点。不过这种差距最晚于2014年补上,实现方式和Intel差别较大——此处或许还有许多问题值得商榷,因为时间有限,我们也没有再深入研究。
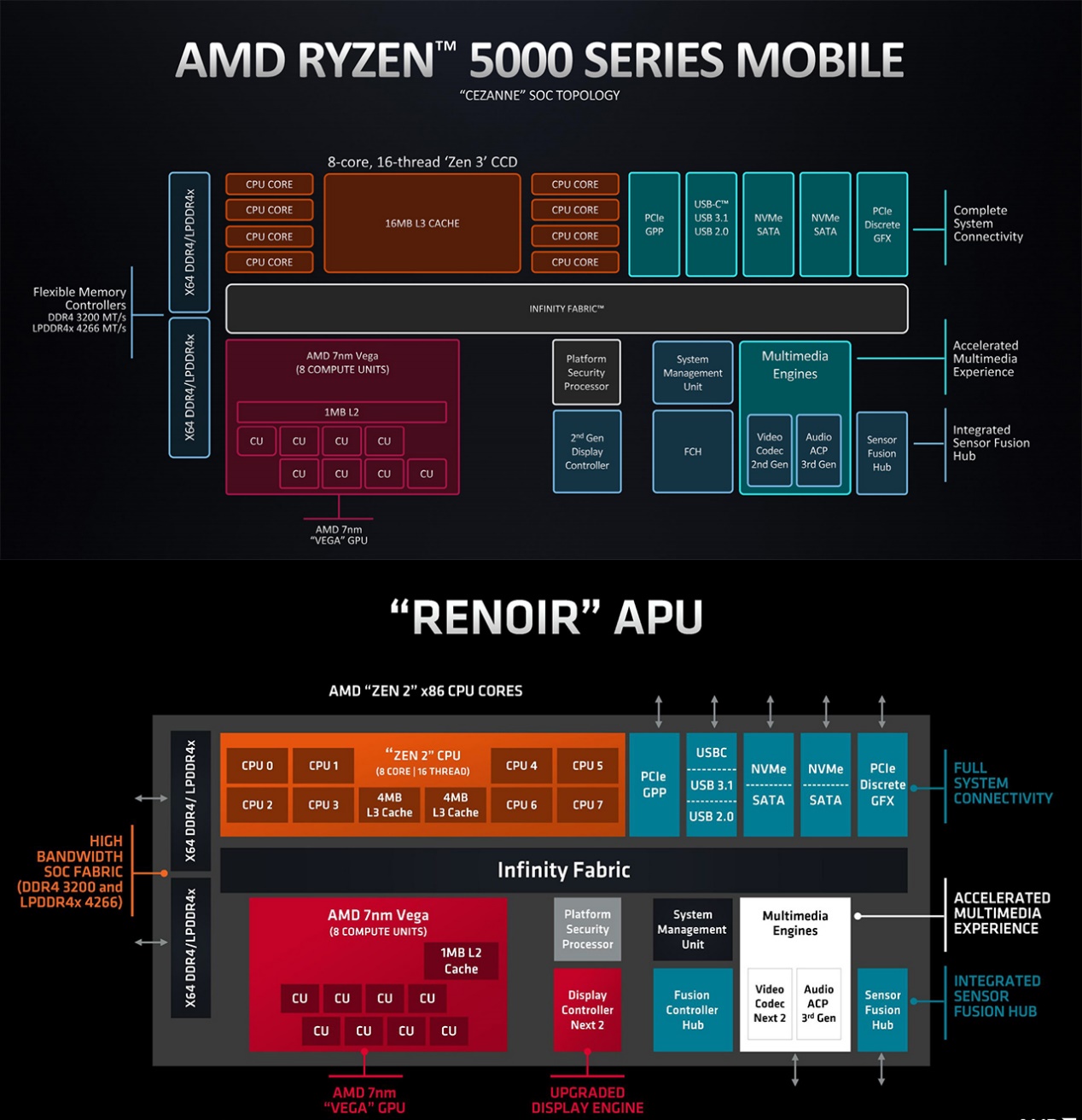
从时代的发展,以及当代AMD处理器架构图来看,大概能发现两件事。其一是,桌面端APU核显,和笔记本移动端的核显,从构成和互联方式上也都没什么太大分别——这或许能够一定程度表明,“APU”如今也就剩个名字了,或者也可以说现在的移动处理器普遍也都发展成了APU那样。
另一点是UMA就处理器层面的实现,是个极其稀松平常的事情——看上图中的Infinity Fabric,再回顾下苹果M1的那张架构图,都是这么串联的。UMA不是苹果一家在做,而是大家都在搞;只是或许每家每户的实现方式是不大一样的,在程度和效率上我们也无从得知谁高谁低。
如AMD如今的处理器这样,也是一堆东西都挂在Infinity Fabric互联上,包括CPU、GPU、内存控制器等。与Intel和苹果的区别,大概就是LLC(或system level cache)并不共享;当然更多实现细节,我们是无从得知的。
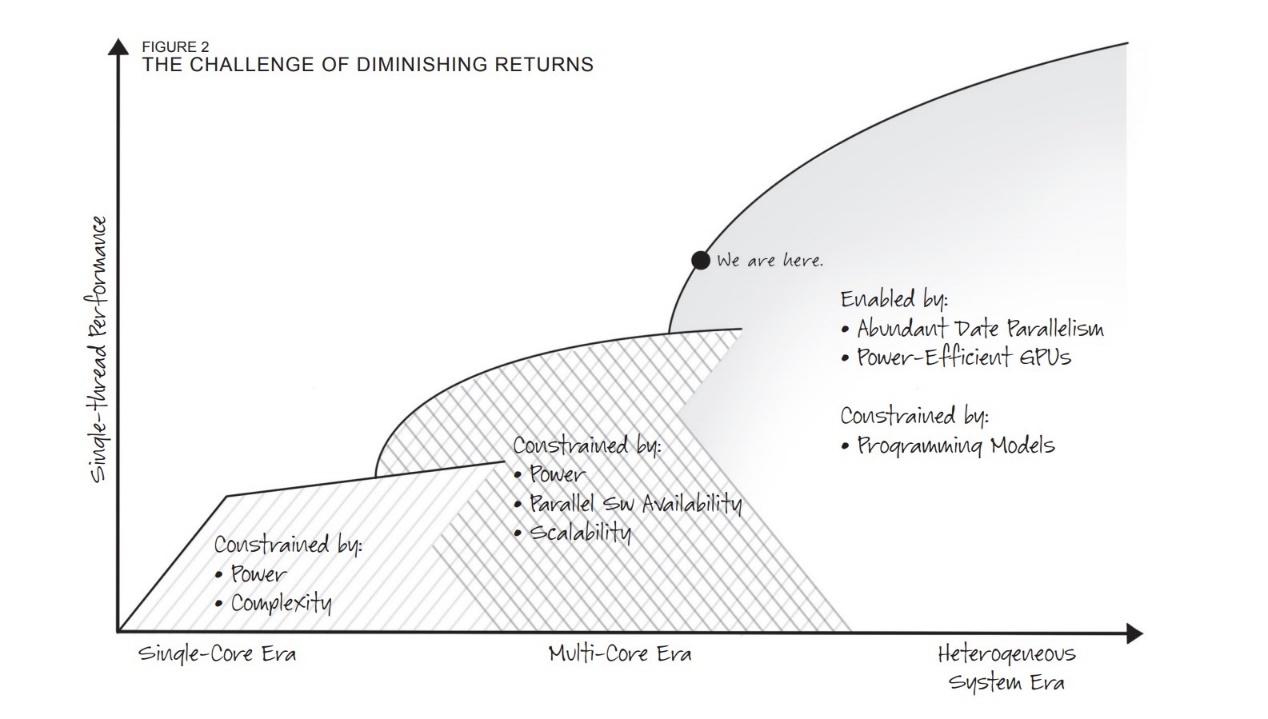
如上篇所说,从HSA最初的设定来看,AMD的APU with HSA理想和生态终未能实现。这个时代若说算力,即便只是图形计算,也得依靠独立显卡和大容量的显存,APU with HSA又怎么谈得上第三阶段的性能飞跃(上篇提到的前两个阶段分别是单核时代、多核时代)?
不过UMA的实施和现状,其实都表明HSA的故事还在延续,即便UMA也只是HSA生态中的一环;即便这可能不单是AMD的HSA生态促成的。只不过时代发展至今,即便UMA的硬件实现如此稀松平常,x86开发生态对于UMA的接受度仍然并不算高(此处仍能体现出苹果的生态优势)。
但AMD有一点没有料错,就是异构计算时代的到来,是算力的又一次飞跃。即便这个时代不叫HSA,或者与AMD牵头建立的HSA Foundation联盟关系不大,异构计算的发展却也从不曾停歇。比如Intel的XPU和oneAPI,比如Arm的Total Solution,比如安谋科技的超域架构,还有英伟达的CUDA;只不过不是以AMD期望的方式那样发展罢了——AMD自己现在不也有其他的异构计算发展方向吗?HSA正以各种方式延续着。
责编:Luffy Liu
