
Intel的10nm工艺现在改名叫Intel 7了,原7nm改名叫Intel 4,后续工艺节点分别叫做Intel 3、Intel 20A、Intel 18A,这是Intel未来5年内的半导体制造工艺节点新规划,Intel还宣布2025年要重现昔日荣光(technology leadership by 2025,主要是从每瓦性能的角度)。
这则消息当然引发了不少吐槽,工艺节点的名字怎么说改就改了?这篇文章就来说道说道最近的Intel Accelerated活动中,Intel放出的有关其制造工艺的新技术,以及对未来的展望,看看Intel的工艺改名计划究竟靠不靠谱。


事实上,在Intel CEO Pat Gelsinger上任以来,Intel的市场活动也愈发频繁了,这在我们看来是个积极的信号——毕竟现如今Intel在制造工艺上落后于竞争对手,牵动着Intel整个公司的发展脉络。包括此前Intel宣布IDM 2.0计划,其中有两个对Intel而言颇具变革性的事件:Intel的部分芯片会外包给其他foundry厂制造(如台积电),以及Intel的foundry厂也要开始接外部的单子了(也就是所谓的IFS服务)。
Intel这两天放出的消息包括:亚马逊和高通会成为IFS的首批客户——这是个大新闻,虽然我们不清楚亚马逊和高通会把具体什么样的芯片交给Intel去造。
除此之外,就是Intel原本的工艺节点名字作了改动,当然并不像文首说得这么简单;还有未来5年内一些大方向的技术路线,比如说2024年的20A工艺要开始采用RibbonFET晶体管了(也就是Gate All Around FET)、新增一种PowerVia技术;封装工艺方面,EMIB要迭代换bump间距更校的版本,而Foveros则将更新第三代的Foveros Omni,以及第四代的Foveros Direct。
我们来逐项简单看看,这些工艺技术能不能让Intel在2025年重现昔日荣光。注意本文的最后两部分为选读内容,感兴趣的读者可选择性阅读。
Intel工艺节点改名,是不是噱头?
我们多次撰文重申过,如今foundry厂所谓的“几nm”工艺,事实上并不存在现实意义——比如市场上采用7nm或5nm工艺制造的芯片,其晶体管器件并不存在任何一个围度的物理尺寸是7nm或5nm。如今的工艺节点名称,只是个称谓,已经不具备数据上的指导意义。(节点数字的历史意义,可参见《7nm究竟是指晶体管的哪部分?14nm是7nm的四倍?》)
而且不同的foundry厂,对某一个工艺节点的定义还差别巨大,比如台积电5nm和三星5nm,根本就不是同一个东西——不仅体现在器件尺寸、密度方面的差异很大,还体现在台积电5nm是相对7nm的完整迭代,而三星5nm则只是其7nm的同代加强。
这就造成了事实上“几nm”这个称谓,不再具有不同厂商之间做对比的可行性。如果用“冒进”和“保守”来形容foundry厂的节点名称特点,无疑三星是最为冒进的,而Intel则是最保守的。此前我们撰文探讨过Intel的+/++/+++命名法,或许以三星的标准来看,Intel的14nm+++工艺,完全可以命名为12nm,甚至10nm。
这导致,Intel的工艺看起来一直在原地踏步,一个加号跟着一个加号;而别家的工艺则可能在此期间“看起来”已经更新了两代。现在foundry厂的制造工艺节点命名已经彻底放飞自我了,尤其是三星。

单纯从晶体管密度(对应工艺的最高密度单元)角度来看,Intel 10nm工艺的晶体管密度为100.76 MTr/mm²(百万晶体管/平方毫米);而三星7nm工艺(7LPP)晶体管密度为95.08 MTr/mm²(Wikichip估算的数据)。虽然高密度单元的晶体管密度,并不能简单说明工艺节点的性能表现,但这两个数字对比大致上可以体现这两家foundry厂在工艺节点命名上的偏向性。
事实上,从Intel的规划来看其原本的7nm工艺,在晶体管密度上比台积电5nm也要高出一截,预期理论性能也会高于后者,但Intel 7nm的延期也是众所周知的了。
更夸张的还可以体现在后续工艺节点上,早前Intel规划中的7nm节点晶体管密度预计会超过200 MTr/mm²;而三星4nm(4LPE)工艺晶体管密度也才137 MTr/mm²(Wikichip估算的数据)。从晶体管密度这个角度来看,和三星一比,Intel把原本的10nm Enhanced SuperFin改名为Intel 7,将原本的7nm改名为Intel 4是不是显得相当合情合理?虽然仍需重申,晶体管密度值(尤其特指HD单元)并不能作为某代工艺节点实际表现的唯一参考。
基于此,Intel期望将自家的工艺节点命名方法,与行业的普遍做法(其实也就是台积电和三星的做法)“对齐”,彻底舍弃+++式命名方法,力争向三星看齐(误)……
目前依然落后的事实,与5年计划
我们甚至认为,市场宣传上Intel早就该这么做了。不过这种工艺节点改名策略,对其客户(无论是芯片设计厂商,还有更下游的PC OEM厂商)而言,并不存在太大影响,毕竟工艺节点并不会因为名称变化而让制造技术发生实质性变化。但这种改名策略,对于技术爱好者、行业分析师,以及公司股票而言可能都有更积极的价值。
Intel这次的工艺改名计划整体上还是没有表现得十分激进,至少和三星比是如此(误)。所以虽然改了名字,但也没有改变Intel制造工艺技术现阶段落后于竞争对手的事实。我们来看看这次究竟是怎么改名的。

(1)首先是10nm SuperFin(10SF)工艺节点名称不变,毕竟采用10SF工艺的产品已经大规模上市了,主要包括11代酷睿Tiger Lake。再改名的话容易引起混乱。这两年Intel在10nm工艺上始终处于难产状态,随Tiger Lake-H45的发布,10nm的良率和产能应当都已经完全跟上。Intel也确认10nm晶圆产量目前已高于14nm晶圆。10SF工艺相比初代10nm工艺的改进,此前我们撰文详述过。
(2)就AMD和Intel的x86处理器来看,Intel实际上未能达成在10SF工艺上相比台积电7nm工艺的绝对领先,尤其是较低性能区间的功耗表现上。那么改进版的10nm Enhanced SuperFin(10ESF,也就是10nm++)计划中应该是强于竞品7nm的,所以10ESF更名为Intel 7。
所以Intel 7理论上当算是10nm工艺的同代改良。今年年底预计我们就能见到采用Intel 7工艺的产品,包括12代酷睿Alder Lake,还有明年初的至强Sapphire Rapids,这才叫通过改名瞬间实现7nm量产……据说Intel 7的确带来了一些尺寸上的变化,在能耗控制、供电、金属堆栈方面均有变化,具体情况未知。Intel宣称Intel 7相比10SF实现了10-15%的每瓦性能提升,而且强调“这等同于完整节点迭代带来的性能提升”。
(3)其次是原本的7nm更名为Intel 4,计划2022年下半年量产——也就是此前Intel CEO宣布已经在今年Q2达成tape-in的节点,14代酷睿Meteor Lake、至强Granite Rapids会采用Intel 4工艺。计划中这也是Intel首个将要采用EUV极紫外光技术的工艺(Wikichip的数据是会有至多12层采用EUV),主要是在BEOL;Intel 4预计相比Intel 7可达成20%的每瓦性能提升。

(4)Intel 3节点理论上应该是此前的原7nm+工艺,相比Intel 4预计实现18%的每瓦性能提升。具体工艺上会有个晶体管更密集的HP(高性能)标准单元库;缩减via电阻;用到更多的EUV层。Intel 3量产时间定在2023年下半年。
其实从Intel 4和Intel 3这两代节点的规划时间来看,虽然工艺节点名称下探到了数字3,但时间还是比台积电和三星规划中的3nm更晚,虽然可能双方无法直接对比。所以到这个阶段,改名也并未改变工艺落后的事实。
值得一提的是Intel 3工艺节点仍会继续沿用FinFET晶体管。这样一来,在3nm节点上,仅有三星选择了转向GAAFET结构晶体管(台积电称其为GAAFET,三星称其为MCBFET)。不过此前我们在4nm解读文章中也提到了三星4nm会成为一个新的完整迭代节点,三星4nm规划上不再作为7nm的同代改良节点。
(5)而Intel转向GAAFET结构晶体管预计要等到2024年上半年的Intel 20A。这个节点名字比较奇特,单位A不再是纳米,而是“埃(angstrom)”,1纳米=10埃。果然foundry厂对工艺节点命名都逐渐我行我素了,不知道台积电和三星会不会跟进。Intel把自家的Gate-All-Around FET晶体管称作“RibbonFET”。随Intel 20A一同到来的,还有PowerVia技术。有关RibbonFET和PowerVia,后文会提到。
单纯从转向GAAFET的速度来看,Intel 20A在时间节点上会比台积电和三星至少晚1年(台积电2nm)。不过到这时,可能很难再预期评价这几家foundry厂彼时的能力。三星虽然更早转向GAAFET,但我们对其3nm工艺是不乐观的——虽然三星3GAA工艺PDK前年就进入了Alpha阶段,宣称3GAA工艺量产是明年。
但从三星在IEDM上更新的数字来看,其3nm工艺的性能和功耗表现提升实在称不上亮眼(相比7nm有10-15%性能提升,25-30%功耗降低),相比三星2019年最初给出的数字也更保守了。加上三星目前对待4nm的态度发生变化,不负责任地猜测三星3nm工艺有可能会不及预期(时间和表现两方面)。
而台积电这边在3nm节点上,此前相当自信地表示,FinFET仍有余地实现较大程度的性能与功耗表现提升。N3虽然仍采用FinFET,却能够实现相比N5大约50%的性能提升、30%的功耗缩减。后续N2节点转向GAAFET的技术细节目前未知。从已知信息看来,台积电在2nm时代仍将有显著优势,不过这话可能说得有点远了。
值得一提的是,Intel 3、Intel 20A工艺均面向芯片设计客户开放,也就是Intel IDM 2.0计划中的IFS服务。

(6)最后是Intel规划中要重回领导者地位的Intel 18A,预计2025年(下半年?)量产。Intel有信心在这一代产品上重回“领导者”地位,似乎是基于Intel届时会采用ASML最新的high-NA(高数值孔径)EUV设备,Intel宣称会成为业界首个拿到这种设备的企业。恰巧我们最近拜访了ASML China位于上海的办公室,ASML也提到越大的NA,就能实现更高的微影分辨率。
NA数值孔径的概念和摄影镜头中的光圈(入瞳径)比较类似,简单理解它决定了EUV光束宽度。越宽的光束,打到晶圆上、强度越甚(可能也相关更大的衍射角)。AnandTech给出的数据提到,目前EUV系统的NA值是0.33,而新系统会达到NA 0.55。Intel或许就有机会抢占这一高地,毕竟Intel入局EUV应该是三大主要市场参与者中最晚的。
Intel如果真的想要在未来5年内重回昔日领导者地位,恐怕需要严格按照这份计划表来执行,甚至某些情况下需要超额达成目标才有机会。以行业与Intel此前公布计划表的常规来看,大家普遍很难按时达成目标,所以这份时间表执行起来大概还存在诸多变数,也包括台积电和三星。
有关RibbonFET晶体管、PowerVia技术(选读)
有关Intel制造工艺节点改名和5年规划的梗概,就谈到这里;虽然其中变数甚多,但对于提振Intel及其生态的信心应该是很有价值的。以下内容谈谈Intel Accelerated活动中强调的几个重点技术,作为本文的选读内容。包括Intel 20A工艺要引进的GAAFET晶体管——名为RibbonFET,和一同出现的PowerVia技术;以及Intel对于EMIB和Foveros的2.5D/3D封装工艺更新。
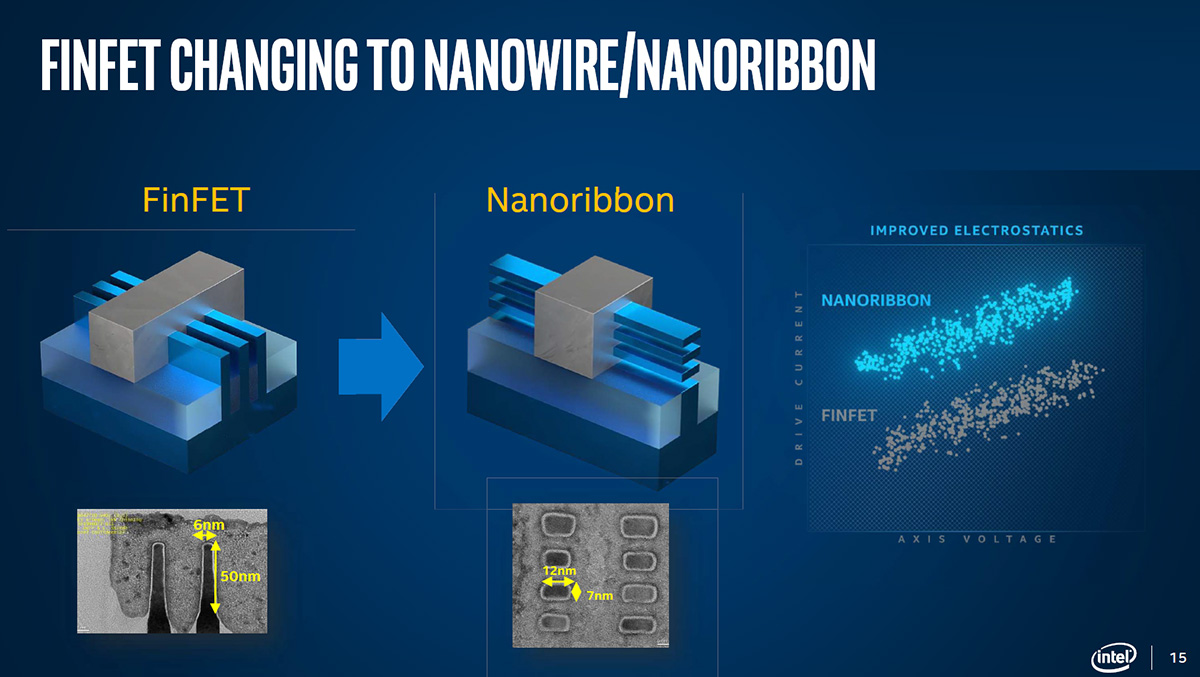
对Gate-All-Around场效应晶体管有过了解的同学,对其结构应该也不会陌生了。GAAFET被认为是FinFET之后,器件尺寸进一步微缩之时,将会采用的一种新型晶体管结构。Intel的这张图很好地解读了GAAFET和FinFET的结构差异。Intel把自家的GAAFET称作RobbinFET。
左边的FinFET是Intel早在22nm时期就引入的一种Tri-Gate晶体管器件,有3个fin。其实FinFET相比更早期的平面晶体管结构,凸起的fin很好地增加了它与gate之间的接触面积——在晶体管尺寸微缩的同时,又能增加驱动电流。而3个fin,则进一步增加了总的驱动电流,实现性能的提升。

在器件进一步微缩的过程里,GAAFET结构变化也是为了达成这种目的,看起来就像是以前的fin转了个方向。Intel展示的PMOS和NMOS器件都是4-stack nanoribbon设计,可能是研究权衡下的结果。
除了RibbonFET之外,2024年将要到来的Intel 20A工艺另一个比较重要的技术叫PowerVia。比较传统的芯片制造,是先从晶体管层和M0层开始,再往上会叠十几、二十层金属层。金属层通常逐层尺寸变大,这些金属层用于芯片不同区域、晶体管之间的连线;最顶层用于外部连接。一般上方的这些连线遍布着供电网络和信号通路。
PowerVia就不是这么干的——这种技术会把所有供电网络全部都移到晶体管另一侧(back-side power delivery),令供电网络放在晶体管底下。Intel表示,传统的互联技术,供电和信号线路混杂,对性能和功耗都会有影响。传统方案在设计上需要确保没有信号干扰——供电线路就是信号通路的干扰;互联信号通路本身也会对供电电阻产生影响。所以把双方移到晶体管两侧也就解决了问题。
如此一来,供电网络就能直接连接晶体管,而不需要通过上方的互联堆栈;而信号互联又能更密集,信号传输效率、包括延迟表现也就有了提升;电力互联部分电阻也减少。最终实现性能、功耗、面积的同时优化。

PowerVia应该是行业内对于back-side power delivery技术比较早的践行了,虽然也要等到2024年的Intel 20A。而且这种技术本身也存在很多挑战,比如说在这种技术下,晶体管是夹在两者中间的——以前传统制造方案,虽然制造的时候晶体管在底层,但封装时通常以倒装的方式进行,最终晶体管实际上位于最顶层——而现在夹在中间,则散热问题需要考虑。
还有其他各种工序、制造难度增加之类的问题。这类技术的开发在业内已经持续多年了,相关paper也时有发布,其现存的技术挑战依然不少。Intel表示在PowerVia技术上研究良久,现有成果也令其有信心将其应用于大规模量产。
EMIB与Foveros封装技术更新(选读)
Intel EMIB和Foveros作为2.5D/3D封装时代的技术,我们在此前的文章中已经有过介绍了。它们都是把多颗die/chiplet,连接起来的封装技术。其中EMIB(Embedded Multi-Die Interconnect Bridge),和直接通过封装基板走线、以及藉由interposer硅中介来实现chiplet的互联(典型如台积电CoWoS)这两种方案都不同,如下图第三种方案。
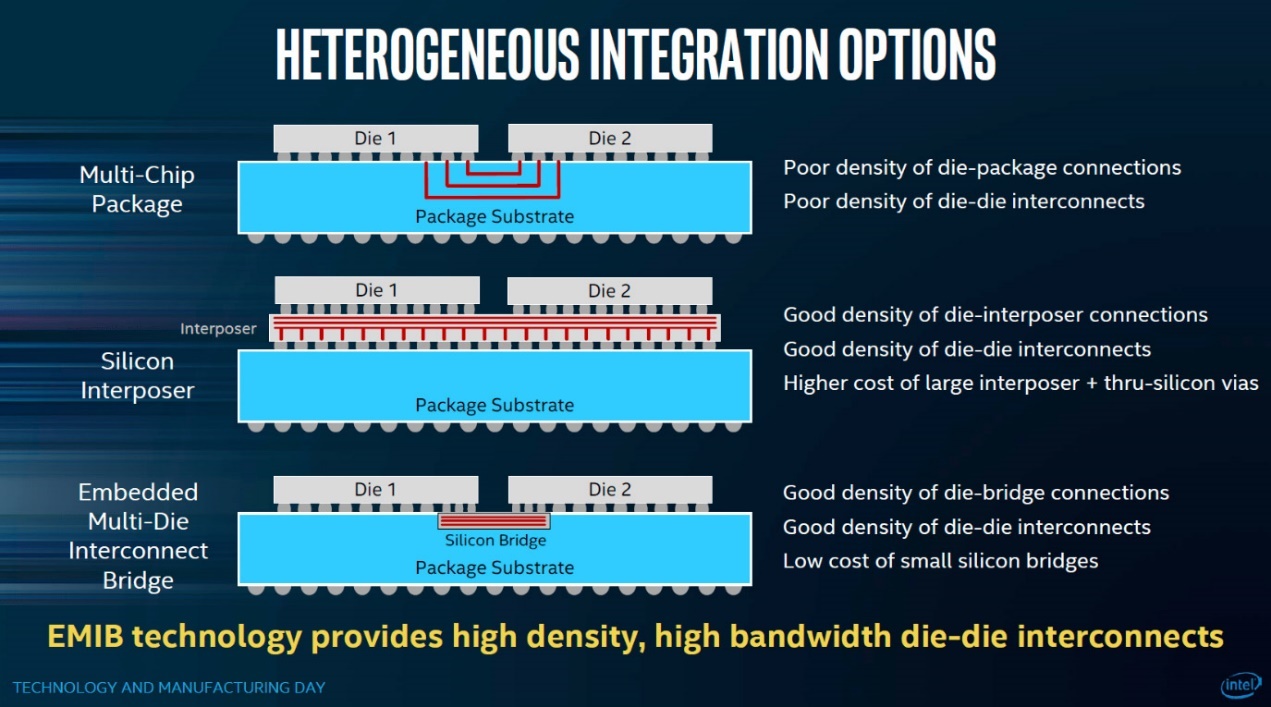
EMIB通过所谓的silicon bridge——将其直接嵌入到封装基板,以较低成本(相比硅中介)实现chiplet之间相对比较高效的互联。有关EMIB,本文不再多做介绍,Intel对EMIB的宣传也不是一天两天了,也有类似Kaby Lake G这种比较知名的产品问世(就是Intel CPU+AMD GPU核显的那款神奇处理器芯片)。
这项封装技术未来还会应用于包括至强Sapphire Rapids、14代酷睿Meteor Lake以及数据中心GPU产品之上——EMIB的大规模应用,预计也会让Intel处理器堆CPU核心不再像现在这么难。
不过Intel这次提到,EMIB的bump间距未来会进一步缩减。Chiplet连接到silicon bridge的时候,是通过bump连接的,bump间距缩减也就实现了更高的连接密度、更大的带宽、更小的bridge尺寸。2017年的初代EMIB技术bump间距为55μm,下一代会缩减至45μm,第三代则进一步缩减至小于40μm。

至于Foveros 3D封装,Intel此前小规模生产的酷睿Lakefield芯片就是典型,是一种将不同的chiplet/die垂直堆叠起来的技术。此前Lakefield芯片,主要是base die和compute die两层的Foveros 3D堆叠。其中base die采用22FFL工艺制造,这层die包括了I/O、安全相关的组成部分;而上层的compute die则主要有CPU、GPU核心之类的计算组成部分,采用10nm工艺制造。
Foveros、EMIB是可以一起用的,Intel规划中的Meteor Lake、Ponte Vecchio GPU也都会用上Foveros技术——不过相比初代Foveros,迭代的Foveros也有一些改进。据说Meteor Lake要用的二代Foveros(与Intel 4工艺同期),会把bump间距缩减至36μm,实现相比初代Foveros翻倍的连接密度。
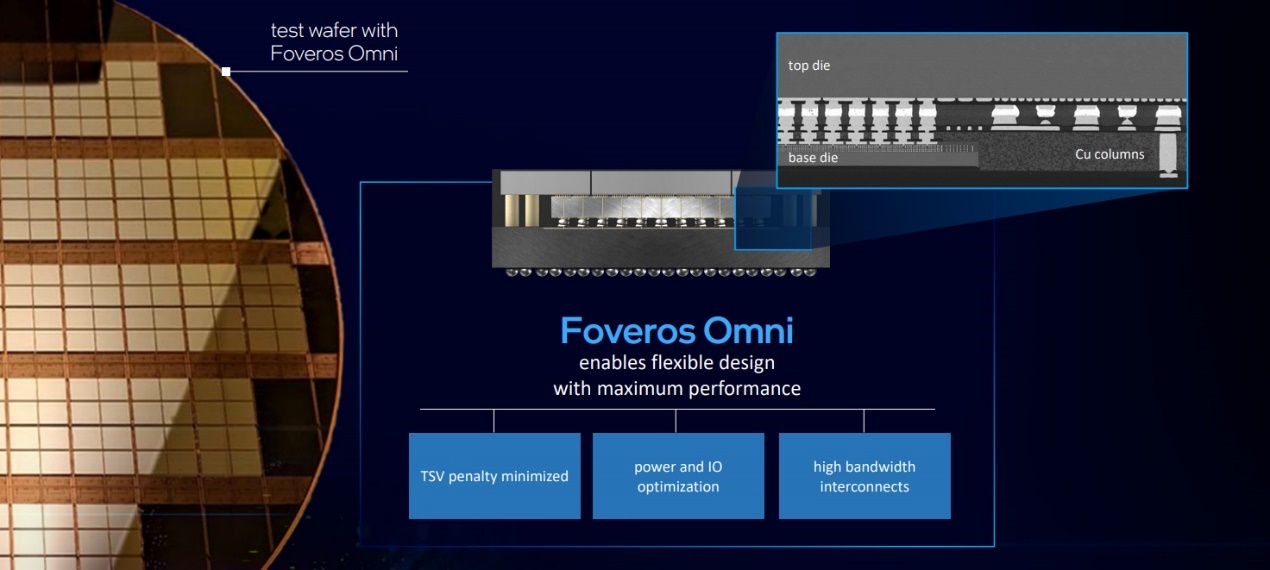
看起来封装技术的互联尺寸缩减现下也正如火如荼的进行中。这次Intel主要更新的是Foveros Omni(双向互联,Omni-Directional Interconnect)和Foveros Direct。
其中Foveros Omni技术更新(第三代Foveros)上,是对于上层die而言,可以铜柱(Cu column)的方式直接为上层提供电力和信号,对于减少TSV(硅通孔)带来的效率损失、提升信号完整性都有价值。(在初代Foveros的堆叠方案中,上层die的供电需要藉由TSV从底层封装、贯穿下层base die、再抵达上层,TSV供电对本地数据通路存在干扰)
另外这种技术在设计上,允许下层die比上层die尺寸更小,上层、下层die也都可以有多个,可以体现出更灵活的设计和制造方案(不同die也因此可以采用不同的工艺制造)。
把供电部分都移到底层base die外部,其实本身也有助于bump密度提升。预计Foveros Omni的bump间距为25μm,密度相比上代提升50%。Foveros Omni预计量产是在2023年。
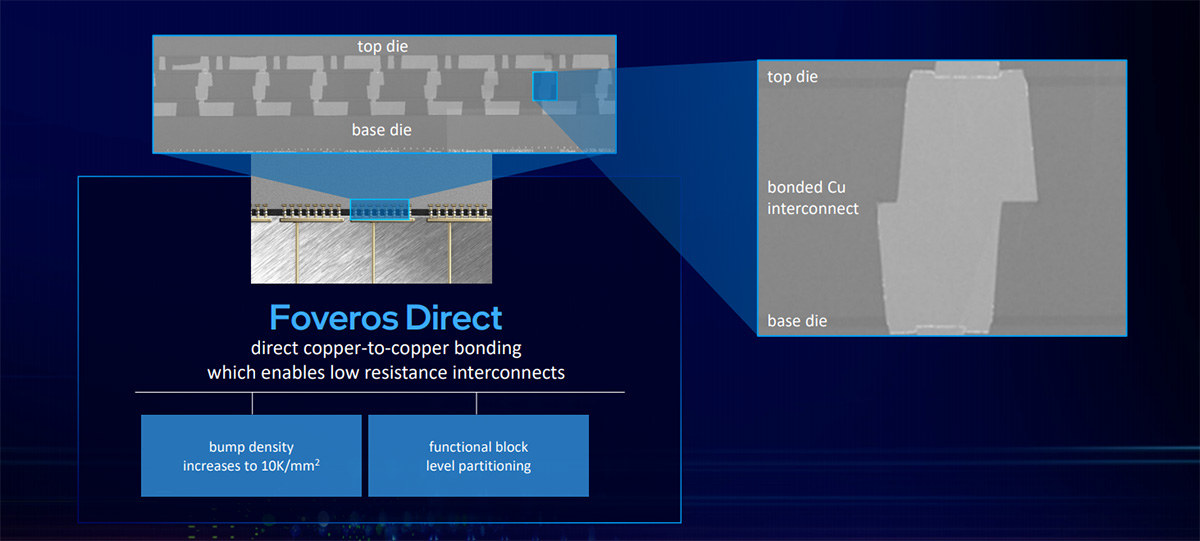
不过我们从AMD前不久宣布在Zen 3处理器上应用的3D V-Cache看来,台积电CoW采用hybrid bonding方案,其bonding间距在量级上是显著优于Foveros的。Intel这次更新的Foveros Direct(第四代Foveros)似乎就是一种hybrid bonding(混合键合)实施方案,采用直接的铜-铜键合,而不再是microbump键合连接(带锡焊帽的铜柱,尺寸相对更难做小,也存在电力传输损失)。同类技术台积电也一直在积极研究。
Intel表示Foveros Direct实现die-to-die连接的键合间距≤10μm,相比Foveros Omni有着6倍的密度提升(>10000 wires/mm²)。且全铜连接方案也意味着更低的电阻和功耗。此外,Foveros Direct可以与Omni配合使用——比如两层die堆叠连接主要采用Foveros Direct,而上层die的电力连接则延伸到下层base die外部采用Foveros Omni方案。
Foveros Direct实现量产也是2023年。感觉从EMIB、Foveros技术更新来看,Intel与台积电的较量也正很大程度在2.5D/3D封装技术上展开。

最后总结一下本文内容。(1)Intel将5年内的制造工艺作了全线的改名处理,与业界常规工艺节点命名方案实现“接轨”;(2)Intel计划在2025年重获昔日荣光(表现在每瓦性能维度上);(3)2024年的Intel 20A工艺节点之上,Intel将采用RibbonFET晶体管结构,以及PowerVia技术;(4)未来几年内,除了工艺节点跟进,EMIB与Foveros封装技术也将相应获得更新。
那我们就拭目以待Intel的5年计划能否顺利执行,并达成Intel所愿。其实从大方向来看,此前Intel原7nm工艺宣布再度延后之前,Intel也曾在公开场合提到过制造工艺暂时落后于竞争对手,并将在5nm时代回到原有的领导者位置。考虑Intel 20A变动很大,技术积累也非一朝一夕,此番5年计划决心似乎也不是近期才有的。
责编:Luffy Liu
- 掩耳盗铃,缘木求鱼,刻舟求剑,南辕北辙,其实都是一个意思:自欺欺人
- 英特尔:台积电不守武德,耗子尾汁~
