
机器学习(ML)系统性能测试基准MLPerf的幕后推手、产业联盟MLCommons近日发表了专为TinyML系统设计的新性能指针,同时也公布了第一次使用该MLPerf Tiny指针进行的推论系统跑分结果。
MLPerf已经为高性能运算(HPC)系统、数据中心以及行动装置等级的系统提供性能测试基准,新的TinyML系统性能基准,则是专为那些在资源极度受限环境中执行机器学习工作负载的设备所设计。MLCommons执行总监David Kanter表示,现在MLPerf基准可涵盖微瓦(microwatts)到千瓩(megawatts)等级的机器学习系统。
他指出:“如果你检视一些我们的训练以及HPC性能测试基准,HPC基准可在全球最大超级计算机上的1万6,000个节点上执行;在Tiny基准方面,则是关于我们如何量测那些最小、最低功耗的设备(参考下图)。”

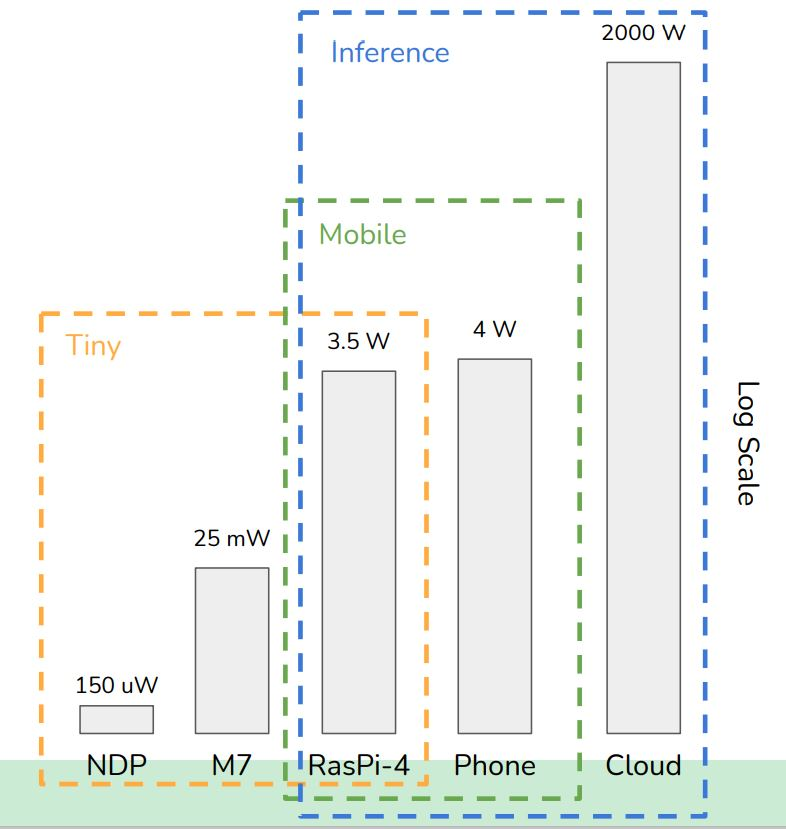
MLPerf性能测试基准的涵盖范围从TinyML装置到大型数据中心设备。
(图片来源:MLCommons)
通常TinyML系统意味着以嵌入式微控制器/处理器在传感器节点执行传感器数据推论的系统,可能是来自麦克风、摄影机等感测装置的数据。一个这种等级的典型神经网络装置可能数据量只有100kB或更少,而且受限于电池电量。
尽管TinyML并没有明确的定义,该名词通常是指以微控制器为基础的系统;MLPerf已经将之延伸了一点点,因此也涵盖包括Raspberry Pi在内的系统。MLPerf Tiny推论性能测试基准工作小组主席、美国哈佛大学(Harvard University)教授Vijay Janapa Reddi则表示,开发这个领域的性能测试基准是一项挑战。
“任何推论系统都有复杂的堆栈,但在TinyML,所有的东西都是与传感器数据──音频、视觉、惯性量测单元(IMU)──有关,生态系统特别复杂;”Janapa Reddi表示:“在嵌入式领域特别具挑战性,是因为大多数的硬件有其客制化工具链…这使得性能基准检验极具挑战。我们必须从头特制很多基础架构,那不是能轻易从MLPerf推论性能基准借用的。”
他补充指出,有鉴于该堆栈的所有部分都有广泛的创新,要定义一个固定的性能测试基准以有效展现那些硬件、软件、工具以及算法的创新,在TinyML领域是特别大的挑战。
工作负载选择
MLPerf工作小组是与嵌入式微处理器性能测试基准联盟(Embedded Microprocessor Benchmark Consortium,EEMBC)合作开发TinyML的性能测试基准,利用了EEMBC的测试工具(EnergyRunner框架),MLPerf工作小组则是定义工作负载、规则以及性能测试基准。
与其他的MLPerf性能测试基准一样,各组织能提交执行一个或多个不同工作负载的硬件与软件系统跑分结果,但TinyML性能基准要支持多样性的应用案例,让系统可选择工作负载来呈现常见的应用会特别困难。为此,MLPerf Tiny推论工作小组将之缩小为四种工作负载:
- 关键词识别(Keyword spotting)──利用Google的语音指令数据集(Speech Commands Dataset),以DS-CNN模型进行有限词汇的语音识别。
- 异常侦测(Anomaly detection)──利用机器以Deep Autoencoder模型运作ToyADMOS声音数据集,进行音频时间序列异常侦测。
- 视觉唤醒词(Visual wake words)──这是一个两类别影像分类的工作负载,影像被区分为“人”或“非人”,利用MobileNetV1 0.25X模型执行视觉唤醒词数据集(Visual Wake Words Dataset )。
- 影像分类(Image classification)──以ResNet-8模型进行CIFAR10数据集的多类别(10类)影像分类。
如同其他MLPerf性能测试基准,MLPerf Tiny推论基准也有“封闭”与“开放”两种赛程(division),以尝试提供相似系统的可比性,还有展示创新方法的灵活性;此外,也让提交者展示其附加价值,无论他们要聚焦在堆栈的哪一个部份。由MLPerf工作小组定案的性能指针是既定预测准确度下的延迟性,以及既定预测准确度下的功耗。
该基准的延迟性分数是必选项,功耗量测则是可选的。但因为TinyML系统通常会在功耗与性能之间有谨慎的平衡折衷,我们是否真的能在不同时看到两种指标的情况下,得到一个清晰的系统性能评分结果?
对此,MLCommons的Kanter表示:“我们把这个版本的测试基准叫做0.5版,有部份原因是因为这是我们第一次的MLPerf Tiny推论跑分结果。取得结果、订定规则以及打造性能测试基准套件实际上是非常重要的任务,而在其上产生功耗/能耗结果又添加了一层复杂性…”
“我坚信要先学爬、再学会走路,然后才能跑,要让事情开始、动起来,然后再优化、或者添加一些额外的能耗/功耗量测复杂性;”他接着指出:“我想,在我们下一轮的跑分结果中,应该会看到更多能耗量测。”
Janapa Reddi也同意以上观点,补充指出该TinyML测试基准将会随着产业进展更进一步提供清晰度;“这是一个还在萌芽的领域,正尝试找到立足点。我们可以等个三年让它成熟,因为在不同地方都会有大量的TOPS以及每瓦TOPS数字;然后我们可以尝试进行某种程度的标准化,或者从一开始就与产业界合作,协助他们设定一个合理的方向…”
他表示:“对我来说,这与确切的数字或系统无关,更多是关于为这个社群提供清晰度与能见度,让他们能加速进展。”
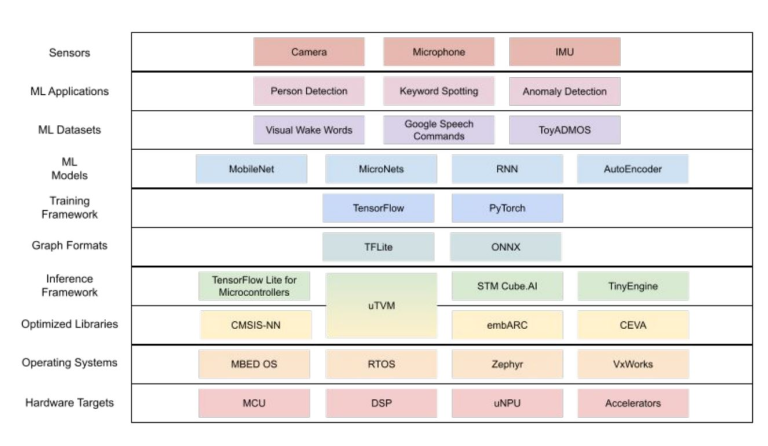
TinyML系统的技术堆栈相当复杂。
(图片来源:MLCommons)
TinyML领域厂商情况与数据中心系统业者迥异,有更多新创公司以及中小型企业。MLPerf的TinyML工作小组共同主席Colby Banbury表示,他们也将这个特性纳入了考虑;“我们在设计测试基准的一开始就想到这个,因此特别着重参考实例并尝试构建出来。我认为其重要性程度在先前几代的MLPerf推论基准中不一定存在,因为没有那么多需求。”
由工作小组提供的参考实例是一组所有工作负载都是在意法半导体(ST) Nucleo-L4R5ZI开发板上执行的延迟性与功耗跑分;选择该开发板是因为其开放平台、广泛可取得性以及成本可负担性。该开发板采用STM32 Arm Cortex-M4微控制器,如果有需要,完整的实例能提供未来提交者使用,作为他们自己的系统的起跑点。
Banbury举例指出,理论上,一家软件供货商能采用该参考实例堆栈,更换为他们自己特定的零组件并相当容易地执行。
第一轮跑分结果
MLPerf Tiny推论性能测试基准的第一轮跑分结果,在封闭赛程中有4套系统提交分数(包括参考系统),开放赛程则是有一套系统提交份数。在封闭赛程中,美国软件开发商Latent AI提供了执行在Raspberry Pi的两套纯软件解决方案,该公司不挑硬件的Latent AI Efficient Inference Platform (LEIP)软件开发工具包能用以优化运算、能耗与内存效率。
Latent AI提交的4种工作负载延迟性分数都分别以FP32与INT8精度模型来跑分,执行关键词识别工作负载的延迟性结果为0.39 ms (FP32模型)或0.42 ms (INT8模型),而参考系统的结果是181.92 ms。中国的一家研究机构鹏城实验室(Peng Cheng Laboratory)所提交的系统,是将4种工作负载的跑分作为其TinyML应用自制RISC-V微控制器组件的概念验证,该系统的关键词识别执行结果为325.63 ms,参考实例则为181.92 ms。
另一家美国业者Syntiant所提交的系统是唯一使用了硬件加速器的,在执行关键词识别任务的延迟为5.95 ms (参考实例系统的延迟为181.92 ms)。该公司的NDP120系统单芯片就是为了关键词识别所设计,采用Arm Cortex-M0处理器CPU核心,加上Syntiant的Core 2加速器。
在开放赛程只有hls4ml一个提交系统;hls4ml实际上是一个神经网络最佳化工作流程,是为了欧洲核子研究组织(CERN)的大型强子对撞机(Large Hadron Collider)所开发,现在则是由一个科研社群Fast Machine Learning for Science负责开发。hls4ml优化模型以双核心的Arm Cortex-A9处理器以及Xilinx FPGA加速器执行,在影像分类工作负载的延迟为7.9 ms,准确度77%;同样的系统执行异常侦测工作负载的延迟为0.096 ms,准确度82%。
除了参考实例,MLCommons公布的第一轮TinyML系统性能测试不包含能耗表现,完整的跑分结果请参考此连结。
(参考原文:MLPerf Launches TinyML Benchmark for Smallest AI Systems,by Sally Ward-Foxton)
编译:Judith Cheng
责编:Luffy Liu
