
EE Times刚刚公布今年的Silicon 100榜单中,中国企业增加了不少,有9家是首次入选该榜单的。其中有一家是致力于AI芯片研发的瀚博半导体:这家公司今年4月份刚刚完成了5亿元人民币的A+轮融资,自天使轮至今身价看涨。这和AI技术和行业本身的火热应当也有很大的关系。
此前EE Times美国采访瀚博半导体CEO钱军时,钱军就曾提到瀚博半导体的首款AI推理(inference)芯片产品已经成功流片,产品面向的市场包括云、企业数据中心、边缘应用,应用方向主要是计算机视觉(CV)和视频处理应用,也适用于自然语言处理(NLP)。当时钱军还表示,瀚博半导体的产品要覆盖15W-150W功耗、不同需求的应用场景。


瀚博半导体创始人兼CEO钱军,与发布的SV102芯片
昨天瀚博半导体在上海的WAIC(世界人工智能大会)发布了SV100系列芯片(SV102),和对应的VA1通用推理加速卡。SV102的定位是面向云端的通用AI推理芯片,VA1自然就是基于这颗芯片的更完整的板卡解决方案了。
从SV102芯片的发布,我们或许也可以管中窥豹地看看AI推理芯片市场的现状和潜力。
SV102芯片与VA1加速卡
先来谈谈瀚博发布的芯片和板卡产品。这次发布会上,瀚博半导体几乎没有透露相关其AI推理芯片的技术细节,所以我们也只能从外部来看看其性能表现如何,以及瀚博半导体在大方向上都做了些什么。
SV102应该是瀚博SV100系列的首款芯片,其特点主要在高推理性能(单芯片INT8峰值算力200TOPS,也支持FP16/BF16数据类型)、低延时(据说是“不到GPU的5%”);并强调内置的“高密度视频解码”,视频解码性能64+路1080p支持(解码格式支持H.264、H.265、AVS2);另外包括“用户场景通用性高”以及“软件易用”。

对应的VA1加速卡尺寸为单宽半高半长;通过PCIe Gen4 x16连接主机;内存32GB(具体规格未知);被动散热;TDP功耗75W——这个功耗不需要额外供电。更多规格如上图所示。
与GPU的性能/性价比对比
AI芯片产品照例要对比英伟达GPU——毕竟这类DSA(domain-specific architecture)架构方向的AI芯片,在特定应用具备了相比GPU明显更优的性能和效率。瀚博半导体CTO张磊将VA1与英伟达A10和T4作了性能、性价比方面的比较。
英伟达A10是基于Ampere架构GA102核心的GPU。这张卡的GPU除了常规的图形计算部分和Tensor Core张量核心之外,还额外配了72个RT Core光追核心;数据类型支持涵盖了INT4、INT8、FP16、BF16、TF32、FP32,标称INT8算力250TOPS;所配内存为24GB GDDR6。其标定的最大TDP是150W,且形态是全高全长。从这里其实也能看出GPU和DSA架构AI芯片之间的差异。
另外对比的英伟达T4是Turing架构的卡,算略有年头了。瀚博选这张卡做对比,应该是基于其TDP 70W,及半高半长的尺寸与瀚博VA1相似这一点。不过T4在规格上和VA1还是有较大差别的,T4内存大小为16GB GDDR6,系统接口是x16 PCIe Gen3;从标称INT8 130TOPS的算力来看,都和VA1差着量级。

瀚博半导体创始人兼CTO张磊
对比的项目是CV和NLP两个方向上、比较有代表性的ResNet-50和BERT模型INT8推理最高吞吐。这张图的对比没有标出具体值。张磊解释说,在ResNet-50模型INT8推理吞吐(FPS)表现上,VA1是英伟达A10的2倍,是英伟达T4的2.5倍以上。这个比较结果是基于将英伟达A10的功耗也控制在75W的程度上;张磊谈到,如果英伟达A10功耗满载,“我们的芯片也是超过A10的”。
BERT模型的情况也差不多,在大家都控制在TDP 75W的情况下,VA1的吞吐(SPS,Sentences Per Second)大约是A10的2倍,是T4的2倍以上。另外针对INT8,张磊表示:“英伟达T4和A10也只用INT8做推理benchmark,一些头部客户都用INT8。”
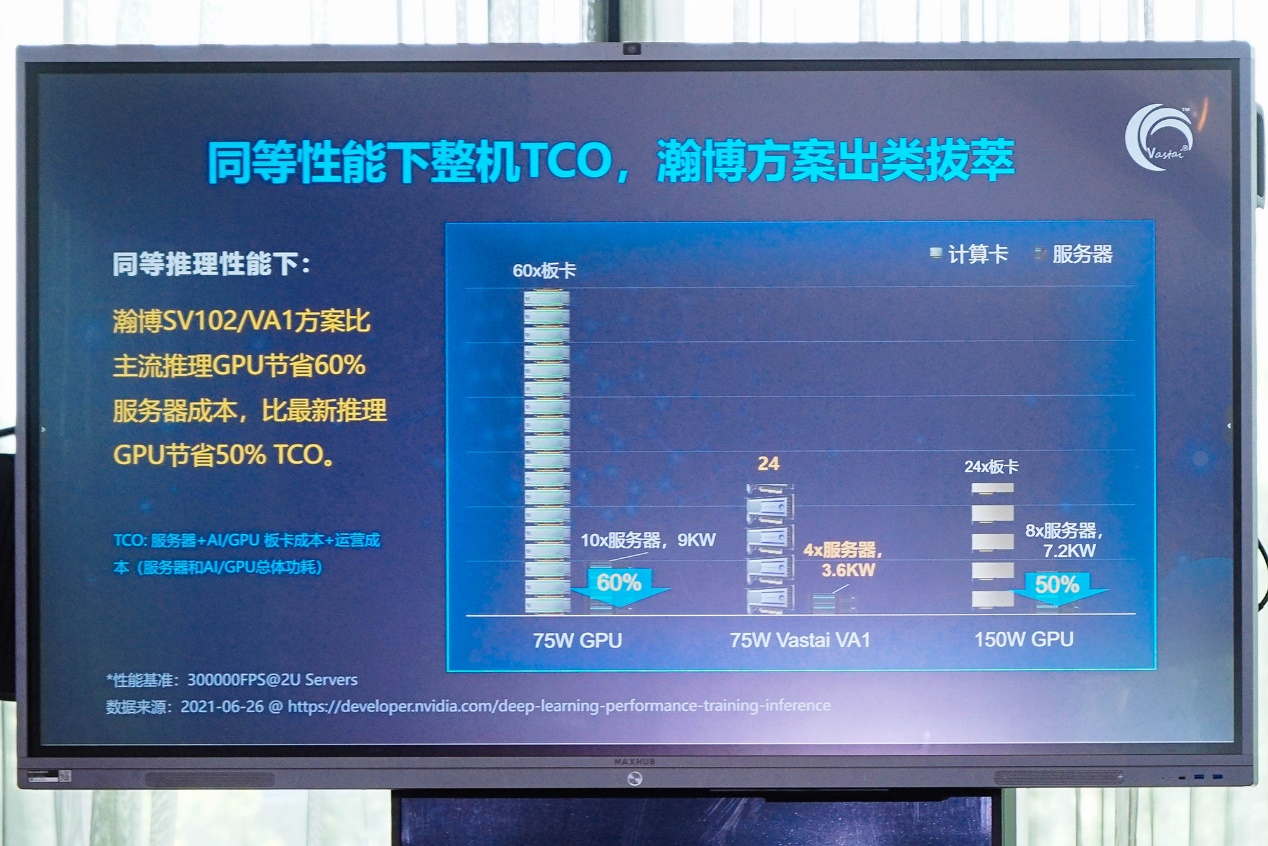
随后对比的是Performance/TCO。TCO是指总拥有成本,包含服务器+AI/GPU板卡成本+运营成本,Performance/TCO也是AI芯片厂商很喜欢提的一个指标,基本可以理解为性价比——此前我们提过,尤其对于搞训练AI芯片的厂商而言,对比英伟达的GPU时可能还需要做开发成本的考量。
这里的对比对象依然是瀚博VA1(中间列)、英伟达T4(左边列)、A10(右边列)。这项对比,基于“假设VA1和T4是一样的售价”。“2U服务器可以放6-8张半高半长75W板卡,假设每个服务器放6张T4板卡,那么60张T4就需要放在10个2U服务器里。2U服务器可以放2-3张A10板卡,假设放3张,那么4个2U服务器里可以放24张A10板卡。”张磊说。瀚博VA1也堆24张,由于半高半长的特性所以只需要4个2U服务器。
之所以这样堆硬件,是为了尽可能达成相似的性能水准。基于前文中ResNet-50和BERT推理性能数据,瀚博VA1(75W)与满载的英伟达A10(150W)性能相似,而瀚博VA1的性能是英伟达T4的2.5倍。
“同等推理性能下,瀚博SV102/VA1方案比主流推理GPU节省60%服务器成本,比最新推理GPU节省50% TCO。”这对客户而言应该还是具备了充分吸引力的。张磊提到:“客户会看TCO,我们的性能有很大的优势,对客户来说是巨大的TCO节省,唯有如此,客户才愿意用一小部分成本做迁移。如果没有2-3倍的节省,如果我们的TCO和GPU竞品一样,客户不会愿意做迁移。这才能助推我们产品在云端推理的快速落地。”
值得一提的是,在对话中钱军和张磊都提到,SV100系列在某些特定场景下的性能优势可以扩展到10倍。不过他们并没有明确提到究竟是哪些应用场景——可能包括了SV100本身在视频编解码方面的优势。
强调视频解码性能
硬件部分另外尤其值得一提的,也是SV102/VA1相比其他AI推理芯片的主要优势项,在于“内置”的视频解码特性;应该是指SV102芯片内部有专门的硬件视频解码单元。这一点实际也进一步明确了SV102/VA1的应用方向。钱军在会上反复强调,做AI推理芯片就要明确客户需求,产品要“与客户的需求匹配”,“最最重要的是要从客户的需求出发,构架要匹配”。
他在答记者问阶段提到了合作伙伴之一的快手。“瀚博是比较低调务实的一家公司,我们不会去做没有客户的芯片。我们花了两年半的时间打造SV100,就是为了做一个可以商业化落地的产品。包括快手在内的所有互联网公司都会是SV100系列产品的目标客户。”

瀚博对SV102/VA1的形容为“高密度视频处理场景”。的确大部分云端推理AI芯片都不会集成视频解码单元,张磊举例说:“我们的友商选择用多个150W全高全长的GPU来做视频解码。有趣的是,云端AI芯片本来应该是用来取代GPU的,但因为AI芯片里面没有内置解码器,高密度的解码又只能用GPU来做。所以友商用多个GPU来做64路视频解码,而我们用一个SV102就行了。”
如前文提到的,2U服务器可以装下6张VA1板卡,可实现384+路1080p视频解码;如果用GPU的话,2U服务器以两卡一组的方式只能做到64路视频解码。从更高集成度的角度,这是成本节约的一个重要体现。比较有趣的是,在AI芯片内集成视频解码单元,本身就是个偏domain-specific的行为了——这种策略在效率上一定比偏通用的方案更强。看起来即便大家都是DSA的AI推理芯片,在这里也有了谁“更DSA”的区别。
这一点还是可以体现“与客户需求匹配”这个重要原则,也可能是未来更多芯片产品面向不同领域的发展方向。
软件与生态
前面我们没怎么提软件:像GPU这种最早是纯ASIC形态的芯片,到后期发展出CUDA,并逐步走向通用,对软件人才的需求是海量的,包括各种中间件、库。传说当代GPU公司是每1个硬件工程师搭配10个软件工程师,英伟达现在也常年宣称自己不是一家芯片公司。
对于瀚博半导体这种创办没几年的企业而言,短时间内就把软件生态做得风生水起还是相当有难度的。英伟达AI王国的建立可不是一朝一夕的。张磊大致谈到了瀚博的VastStream AI软件平台。“视频编解码我们有media acceleration library。我们也有自己的AI compiler,compiler上面能够支持AI Basic算法,也可以做Extended Operator算子扩张。用GPU做完模型训练之后,不管是TensorFlow、PyTorch还是Caffe,我们的AI compiler针对已经训练好的模型,产生我们的ISA,让下面的硬件跑起来。”

张磊表示:“迁移过程是非常低成本的。”“从AI模型的支持角度来看,我们也是非常全面的,包括计算机视觉、视频处理、自然语言处理、搜索和推荐的各种模型。SV102是通用的云端推理芯片,所以也支持算子自定义和扩张。”
落地到服务器的适配规划方面,“我们现在在向联想、浪潮、H3C、超微一类的服务器在做适配。”操作系统方面,“我们支持CentOS、Ubuntu、Red Hat和麒麟。”
整个生态的搭建还需要慢慢积累。钱军谈到,“软件生态要一点点建立。我们现在主打产品,我们也有时间一边建立生态、一边卖我们的产品。刚才也谈到了整个软件stack,除了我们的AI引擎,我们还有视频、CV引擎。在互联网端侧,我们的AI引擎会推得快一些,视频稍微晚一点——计算机视觉方面要把视频引擎优化好。我们目前在大力招软件方面的人才,软件团队未来会有3倍、5倍的扩张。”
“将来我们会发布15W、150W的产品。我们的芯片是scalable的。软件团队会也会在基础软件共同平台上,搭出不同的解决方案。”钱军说。这些规划实质上才是瀚博半导体的AI芯片实现通用的基础。
AI推理芯片的未来
钱军说:“现在我们整合国内外多家头部互联网公司合作。其实很多公司和我们的合作已经有段时间了,正在等着测试我们的产品。”“预计我们的产品会在2021年Q4开始量产。”从瀚博列出的时间表来看,SV100系列芯片测试成功是在今年6月。据说SV100的测试过程非常顺利,“开始测试以后8分钟就全部点亮,我们让PCIe Gen 4工作,低于40小时的时间里所有功能模块基础测试就提前完成。”
瀚博这家公司虽然是新创,似乎在前两年就有半定制7nm芯片的经验。而且钱军和张磊这两名创始人此前都有国际芯片大厂的高层工作经历。钱军此前在AMD负责GPU和AI服务器芯片设计和生产;而张磊早在2013年就已经是AMD Fellow,负责AI、深度学习、视频编解码和视频处理领域。钱军说,此前还在AMD的时候,“beat Nvidia就是我每天的工作”。
所以创办瀚博半导体,并以抢占英伟达GPU市场为目标,大概也只是早前工作的延续。不过为何特意选择AI推理这个赛道,瀚博有一个完整的逻辑:打造更偏专用的AI推理芯片,是因为这个市场的潜力仍然相当之大。
钱军表示:“HPC超算+科学计算,AI训练、推理,这三个细分赛道,他们对于算力、精度、能耗比等方面的要求是不同的,其市场大小、生态也都不一样。” 若以GPU来做AI推理,则以英伟达在软件生态上的完善程度,恐怕现下已经难以逾越。所以要在AI推理这条赛道上超越英伟达,选择DSA架构来做AI推理芯片成为瀚博的必然选择。

瀚博半导体创始人兼CTO张磊,VA1加速卡
瀚博确定从AI推理方面突破,是“因为GPU在推理侧并不是最好的架构”。与此同时,“随着AI训练逐渐走向成熟、AI应用逐渐落地,推理市场规模超过了训练市场。2021年推理市场就已经大于训练市场了,未来市场差距还会越来越大。”有预测数据提到2025年90%的算力都会用于推理。这是瀚博看到的未来市场机遇。
“在推理侧,我们的方案会远远优于GPU;推理侧的生态也更容易突破。”而SV100更偏向视频应用,则在于“计算机视觉占了AI市场的大半壁江山,视频流占到整体数据流的70%——这个百分比还会越来越高,数据基础也会越来越大,要面对视频相关的数据绝对是海量的。”
这个商业逻辑看起来还是相当完整。随瀚博芯片产品很快就要量产(及未来覆盖更多场景的AI推理芯片问世),以及软件生态的持续完善,验证这个逻辑已近在咫尺。在AI市场走向完善之路的过程中,瀚博这家企业出现与AI推理芯片的诞生,可能会成为相当重要的一步。
责编:Luffy Liu
