
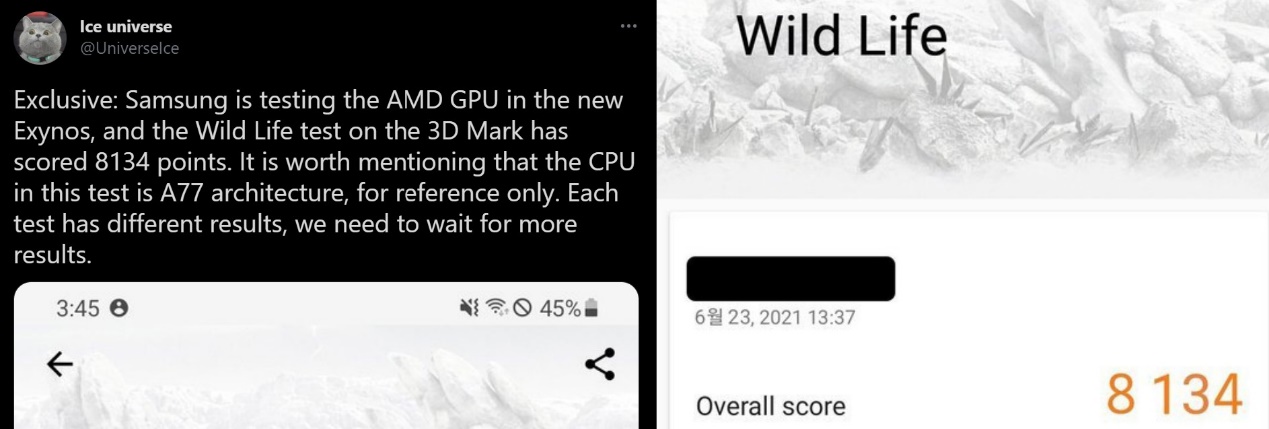
前不久的一则新闻,曝光了三星即将推出的Exynos芯片的图形性能。这颗应用于未来三星手机的SoC芯片,据说其3DMark Wild Life跑分达到了8134分。这个性能成绩比高通骁龙888的Adreno 660高出大约50%。至于和苹果A14比,我们手头没有可现测的设备,有媒体提到8134这个得分和iPhone 12 Pro Max相似,也有媒体提到iPhone略胜或iPhone在这项测试中无法达到8000分。
无论如何,这应该是三星Exynos芯片首次在GPU绝对性能上大幅领先高通,且与苹果差不多。如果消息可靠,那么这也意味着三星的新一代Exynos芯片在手机平台上基本可以碾压其他竞争对手(麒麟9000满血的Mali G78MP24这个项目的得分大概是6000分出头)。

这也并不奇怪,前年AMD和三星共同宣布多年战略合作,以及今年年初三星宣布下一代旗舰Exynos芯片会搭载AMD最新的RDNA架构GPU,到上个月的Computex大会上AMD宣布RDNA 2会出现在高性能手机市场上——“我们很高兴宣布我们即将把定制图形IP带到三星下一代旗舰SoC上,且将支持光线追踪和VRS(可变速率着色)”。
预计明年的三星旗舰手机(Galaxy S22)上就会看到AMD的GPU。这还是AMD的GPU首次以很明确的方式出现在手机平台上——当然,这得抛开当年高通从ATI(AMD)手中接过Imageon移动GPU业务,成就现在的高通Adreno GPU这件事。AMD对于手机GPU的影响还真是深远和有趣。这颗AMD GPU在手机上出现之前,我们来发(sui)散(bian)地谈谈AMD GPU应用于手机平台的可行性,毕竟AMD此前都只有桌面平台高性能GPU的经验;也当是对AMD GPU当代产品的技术科普。
有关三星与AMD的合作方式
2019年,三星与AMD明确“多年战略合作”之时,双方的合作就显得相当有趣。三星获得的是AMD的图形IP授权——就像Arm此前把Mali GPU授权给三星、华为、联发科那样,AMD并不负责制造GPU。
与此同时,2019年签署的协议已经明确,只允许三星在“与AMD不发生竞争关系的领域”使用AMD GPU IP,比如说手机、平板等。这基本上意味着三星授权得到的IP,并不会出现在PC这样的平台上——这对高通而言可能是个好消息,毕竟高通骁龙SoC已经开始广泛应用于笔记本平台了,而三星与AMD的合作可能很难对高通产生什么正面冲击(虽然高通可能还需要考虑联发科与英伟达的合作问题)。

另外一点值得探讨的是,双方的合作究竟是以何种方式展开的。一方面AMD和Arm还是不同的:AMD虽然也有IP授权业务(属于这家公司的Enterprise, Embedded and Semi-Custom业务),但这不是AMD的主营方向,更少见GPU IP直接授权。AMD与客户合作更在意、在行的其实是半定制(semi-custom),比如索尼PS、微软Xbox游戏机之上的处理器就属于AMD的半定制业务。AMD今年Q1财报还特别提到,其半定制产品销量巨幅提升。
另外,三星SLSI此前似乎早就对Mali GPU不满意了,曾立志自主研发GPU(此前称为SGPU计划)。虽然三星的CPU/GPU自主研发计划都受挫了,但研发的“遗产”应当还是有的,而且此前也有多年搞Arm Mali移动GPU的经验。加上AMD其实并没有造手机GPU的经验,双方的这次合作很可能会是相互促进做更有效的定制的方案,而不是像Arm那样做简单的IP整套授权——此前的模式下,三星的发挥余地也相当有限。
虽然AMD在2019年发布RDNA初代架构时,就强调了其可扩展性,不过真的要让RDNA适用于手机这样的低功耗设备恐怕也没有那么简单。
AMD的RDNA架构GPU
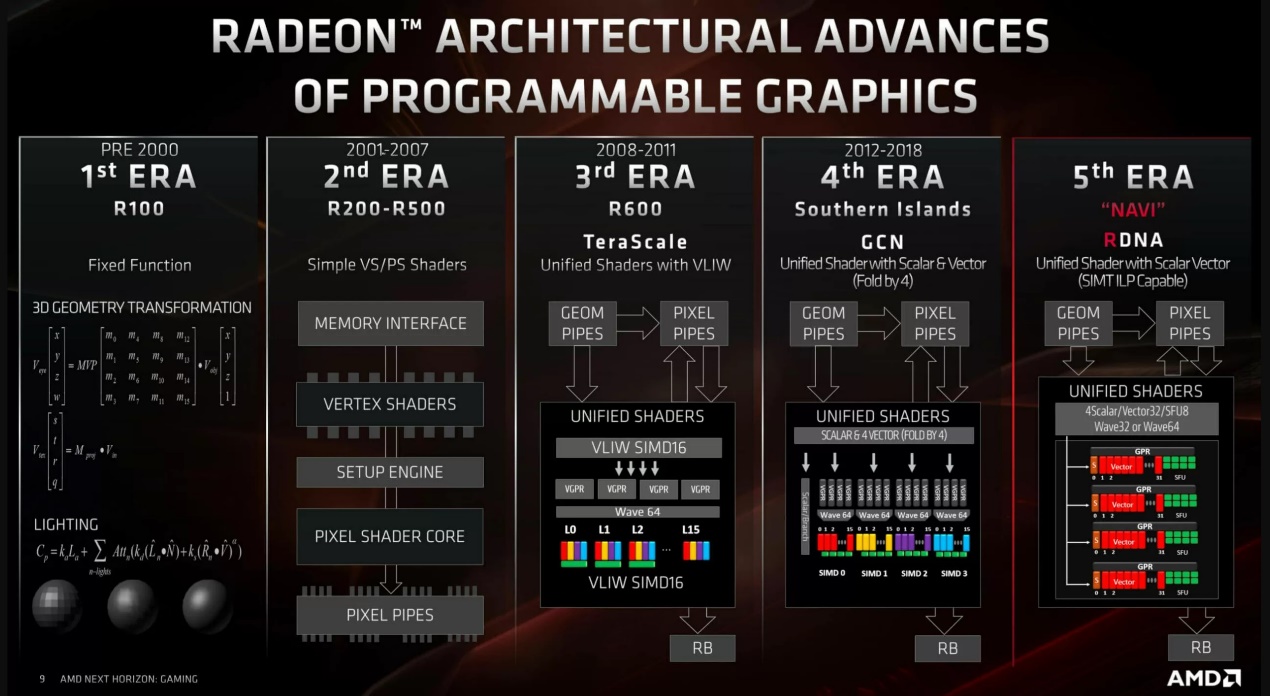
Lisa Su在Computex上明确,三星的下一代Exynos会采用RDNA 2架构的GPU。在AMD的路线图上,RDNA是GCN(Graphics Core Next)的迭代架构(GPU微架构与指令集)。2019年7月发布的Radeon RX 5000系列GPU(代号Navi)是应用RDNA初代最早的产品。当初AMD在发布RDNA时似乎就提到了,其适用范围包括智能手机、笔记本,以及超级计算机,可扩展性实现全场景覆盖。
RDNA二代产品Radeon RX 6000系列是去年年末问世的。我们来简单看看所谓的RDNA架构,到底是什么,以及将其应用于手机平台的可行性。
RDNA相比GCN一个比较大的变化就是wave32。GCN架构之时,shader编译器创建的wavefront宽度是64,而RDNA架构的并行宽度收窄到了32线程。wavefront是线程分组的一个名词,比如每32个执行单元分成一组来跑同一指令,意即一个wavefront宽度为32线程。不过不同的厂商对线程分组的称谓不同,AMD称其为wavefront,而英伟达称其为warp。wavefront可认为是GPU的最基本可调度单元,亦有说法是“代码的最小可执行单元”,“在所有线程中,同时执行同一指令”,“SIMD过程中数据处理的最小单位”。
以前AMD GPU的wavefront普遍是64,也就是每64条线程分组并行(不过GCN事实上是16-wide SIMD,所以wavefront要以16通道分组作4周期来执行)。RDNA架构将其收窄为32(wave32)有三方面的考量。
其一是当代GPU编程代码已经不只是一系列简单指令了,会有更多的循环、分支。比如在代码有分支的情况下,更宽的线程分组会造成资源利用率的低下——一般一个wavefront一直在执行相同的指令,如果出现分支就会出现divergence,wavefront中的更多核心会闲置。而更窄的分组并行宽度,在遭遇循环和分支时,相比以前就能提升效率。
而且更窄的wavefront本身对于数据访问占用更少资源、完成更快,比如使用一半的寄存器——在更快速完成工作之后,寄存器更快地释放出来,也就达成了更高的资源利用率。
其次,wave32是将任务切分成更小的数据流,事实上可达成更好的并行度,提升性能和效率。针对更窄的wavefront,本文就不再展开了。

RDNA相比GCN其他改进还包括,单周期发射4条指令到每一组SIMD——GCN每4个周期发射1个指令的wavefront,而RDNA则是每个周期就能发射32线程wavefront,给执行单元。RDNA的另外一个主要改进是引入了所谓的Workgroup Processor(WGP)。WGP就是以前的CU(compute unit),即shader内部的基本构成单元。每个WGP包含2个CU,单WGP可实现更大的算力和内存带宽,这一点下文还会谈到。
RDNA2应用于手机的可行性
RDNA2则是RDNA的迭代架构,是在去年年末发布的。此前AMD曾经提到过,RDNA2相比RDNA实现了54%的每瓦性能提升,也就是更高的能效——这可能是RDNA2可应用于低功耗产品的基础。事实上RDNA2并没有换用更新的制造工艺,单靠架构改进实现54%每瓦性能提升感觉也是很厉害。另外RDNA2也提升了频率和IPC,且在特性上开始支持硬件加速的实时光线追踪、Infinity Cache、mesh shader、sampler feedback和VRS(可变速率着色)——也就是对DirectX 12 Ultimate的支持。
不过RDNA2这55%的效率提升,真的是为手机准备的吗?其实简单看一看AMD公开有关RDNA2的更新就会发现,应用于桌面的RDNA2 GPU所实现的“54%每瓦性能提升”,和手机可能关系并没有那么大。首先RDNA2的核心架构相比RDNA并没有什么大变化。不过RDNA2在电源管理方面的确下了不少功夫,包括更加精细化的时钟门控策略;而且重新搞了CU的数据路径——也就是降低数据移动的功耗开销,减少传输能量开销。
另外AMD在幻灯片上还提到了比较激进的“aggressive pipeline rebalancing”,不过具体不知道是怎么个rebalance法。这几项改进固然很有价值。
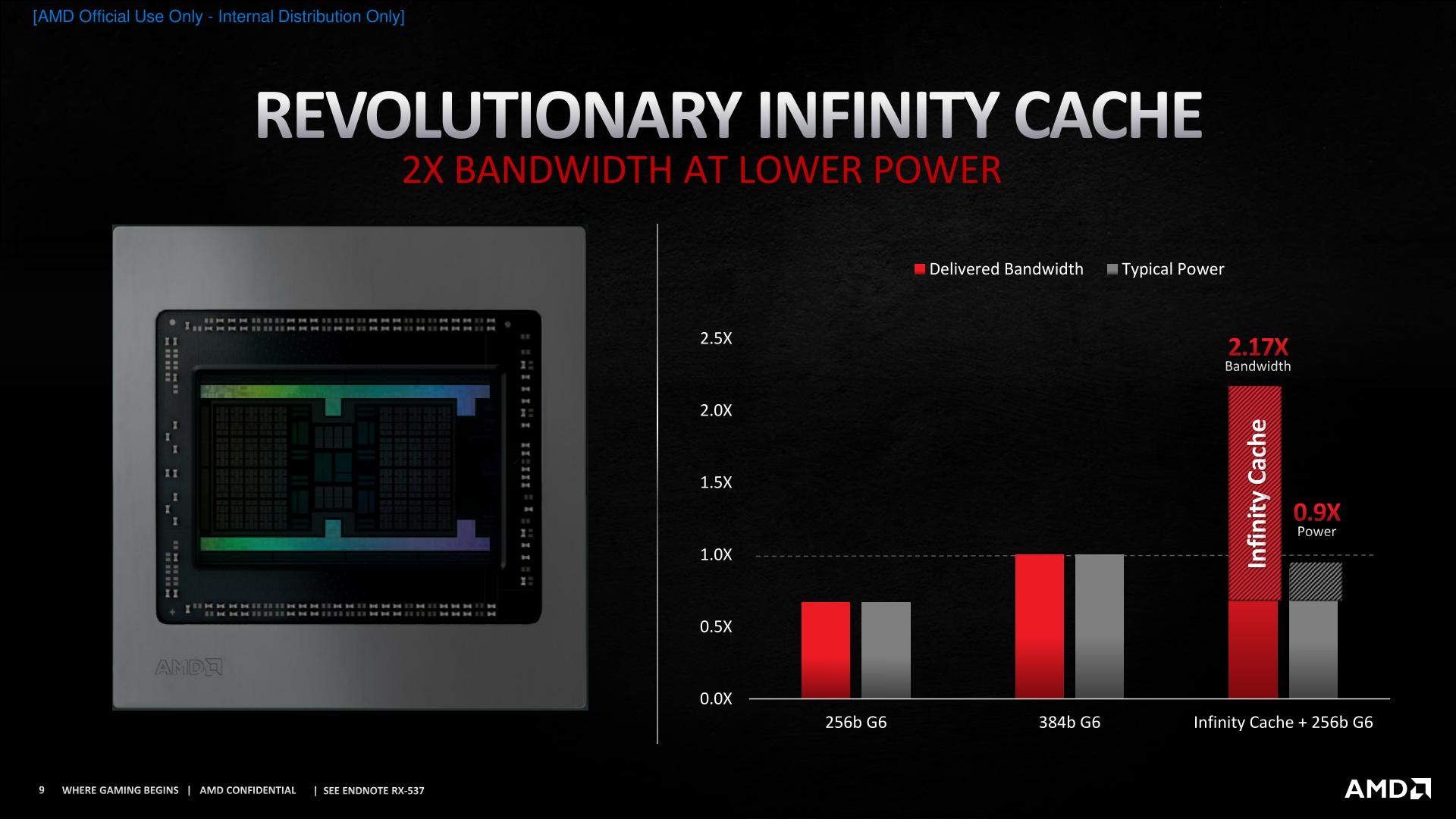
不过在功耗降低的问题上,这代架构比较大的一个变化应该是引入了Infinity Cache。Infinity Cache是GPU的片内cache。从AMD的说法来看,它很像CPU上的L3 cache,作为与显存之间的缓冲地带——感觉这两年AMD特别喜欢在cache上动心思(比如前不久才宣布的Zen 3处理器上3D堆叠L3 cache)。AMD方面表示,因为Infinity Cache的存在,也就完全不需要显存位宽做到384bit(此处应该是在嘲笑英伟达),峰值带宽超2倍,功耗却只要90%。
这招固然有效,但要应用到手机上恐怕难度很大。Navi 21核心配的Infinity Cache是128MB SRAM,要耗费的晶体管是巨量的——这一项能效上的巨大改进很难用于手机SoC。在我们看来,Infinity Cache的加入极有可能是RDNA2在PC平台实现54%每瓦性能提升的最关键要素。

那么RDNA本身的弹性化规模扩展特性呢?我们来看看RDNA的核心情况。前文已经提到,RDNA的每个Workgroup Processor包含2个CU(Compute Unit)。AMD日常在宣传中会提GPU上有多少个CU单元,这一代架构上的CU是成对出现的——每两个CU(也就是每一个WGP)作为GPU的基本计算构建模块存在,这也是相比GCN架构一个比较大的变化。
RDNA的CU构成大致如上图所示(上面一个CU,下面另一个CU)。在这样一个Dual Compute Unit中,一共有4组SIMD(Steam Processors,SP),每个SIMD包含32个ALU(算数逻辑单元)。这两个CU之间会共享一些资源,比如各种cache、纹理过滤单元、纹理映射单元等。
到具体的GPU产品上,举例说面向笔记本的Radeon RX 6600M采用了28个这样的CU;面向桌面PC的6700XT内包含了40个CU,而更高端的6900XT则有80个CU(519mm² die size,超过260亿晶体管)。
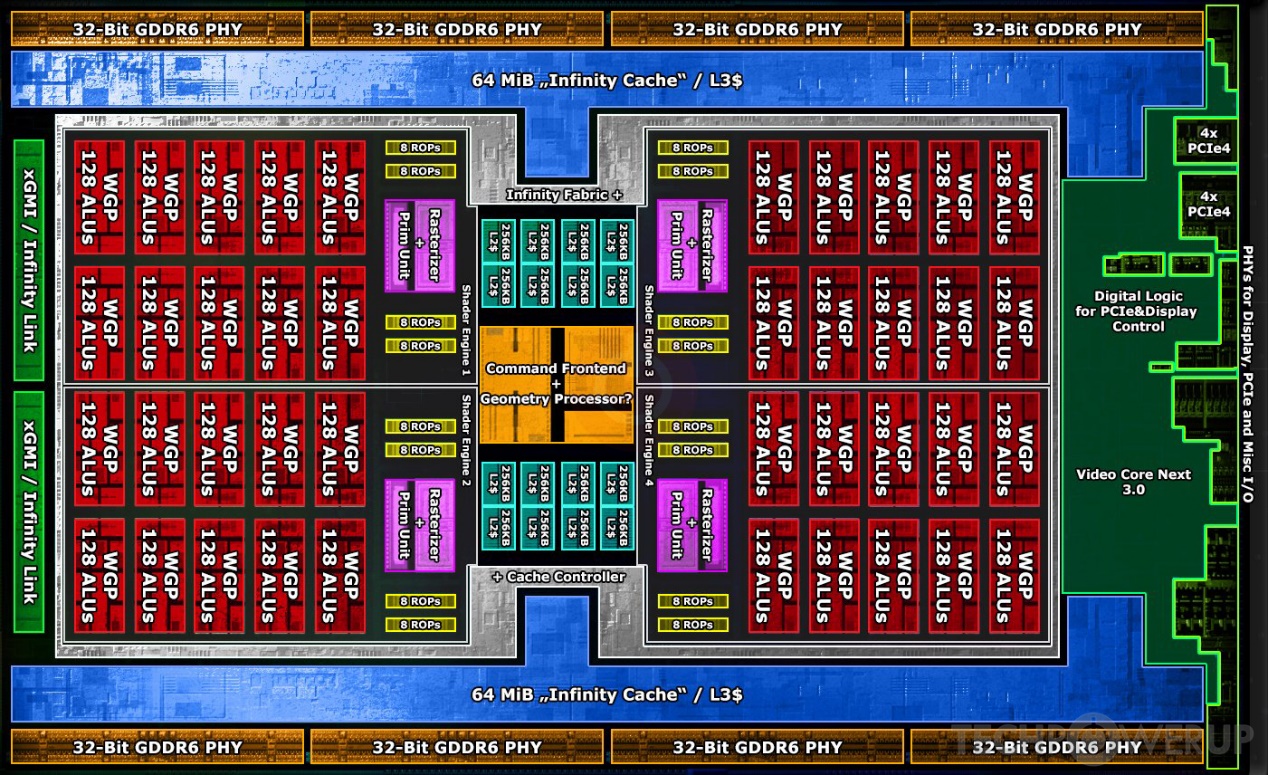
上面这张结构图展示的是6900XT的Navi 21核心,每20个CU(10个WGP)构成一个Shader Engine;每个Shader Engine除了CU之外,还有一些共享的硬件单元,如光栅单元,相关深度、stencil、alpha测试、像素blending等的渲染后端(RDNA 2事实上在这部分也有的提升)等。在Shader Engine之间当然也需要一些公共单元,如L2 cache、几核引擎等,这里不再赘述。从这里不难看出,在这个层级的抽象中,CU属于AMD GPU的最小单位——两个CU组成WGP,多个WGP组成Shader Engine,多个Shader Engine组成GPU。
上面这些是面向PC有高图形算力需求的GPU产品,这种规模当然不可能应用到手机上。有兴趣的同学可以去看看我们此前对Imagination PowerVR处理器近代架构的详述——PowerVR目前主要是面向手机这样的移动产品的,以此可以看看手机和桌面端的GPU在硬件规模上有着怎样的差距。
上述三款不同规格的AMD GPU,其TDP功耗设定分别在100W(6600M)、230W(6700XT)、300W(6900XT)。手机SoC的功耗吃不消这么大的数量级,此前华为麒麟9000在跑一些高负载的游戏测试时,能达到10W的整机峰值功耗,我们就已经认为相当惊人了。

不过既然CU可以弹性扩展,那么如果我们(不负责任地)推算一下,不考虑显存、GPU核心频率、CU本身规模缩放、渲染其他阶段功耗之类的问题,那么用TDP功耗来除以CU数量,则每个CU被“分配”到4-6W的功耗。
虽然这个计算方法很不靠谱,不过似乎如果不做CU本身规模的缩放,手机上大概能塞进RDNA 2架构的一个完整的WGP(Workgroup Processor),或者说Dual Compute Unit(即2个CU)。不过手机端的GPU频率也不可能达到2GHz这样的频率(比如Adreno 660的shader频率最高可能在800MHz左右),而且手机GPU没有专用的显存,CU规模、渲染管线也都可能调整,产品问世前的变数还很大。
一些猜测和疑问
另外一个众所周知的事实是,像手机这样对功耗、带宽都格外敏感的设备,不大可能用桌面端那种大手大脚作数据存取操作的传统IMR(Immediate Mode Rendering)立即渲染结构。对于桌面级GPU而言,传统IMR是以整个帧为单位做绘制的,在像素着色(pixel shading)阶段,因为有大量像素要处理(相比顶点要多很多),依赖外部存储的读写操作会比较频繁。
所以手机或移动GPU最早改进采用TBR(Tile-Based Rendering)架构,就是所谓的分块渲染。就是将整个屏幕显示分成若干区域,每个区域都是一个tile;GPU可以一个tile一个tile地渲染的。GPU再配个片上cache,就能显著减少读写外部存储的时间。Arm Mali、高通Adreno、苹果GPU等普遍在用TBR渲染结构。

不过极有可能2014年英伟达Maxwell也开始采用基于tile的光栅化和分组(binning)操作;2017年AMD在vega上开始作这种应用(Draw Stream Binning Rasterizer),想必带宽的节约也是颇有经验的。与此同时,苹果、Imagination(Arm也有可能)普遍在用一种名为TBDR(Tile-Based Deferred Rendering)渲染结构,以“进一步”的“延后”,更早地搞清楚画面中哪些部分被前景遮挡,真正避免画面的overdraw,也就不需要处理被完全遮挡的几何体,更大程度地节省带宽和资源。
这些可能都是AMD需要针对移动平台考虑的问题,虽说AMD极可能在这方面已经具备了经验。就像前文提到的,三星Exynos要应用的RDNA2,是否还是完整形态的RDNA2或者只是规模弹性缩减,或要在核心规模上做大改?这些都是比较有趣的问题。
此外,Lisa Su在Computex上提到未来的三星SoC会携光线追踪和VRS(可变速率着色)登场。VRS其实没什么大不了,高通Adreno 660也已经实现了VRS——这项技术本来就在致力于优化硬件资源利用率。(Arm此前也预告过正在搞VRS和光追,不过不知道何时搞出来)

至于光线追踪,此前我们曾撰文特别解析过这种技术,它要实现的是更真实和符合直觉的画面光照效果。这项技术的力推者其实是英伟达,Imagination在移动端也在推——不过Imagination这两年所推IP的实际应用可能算不上成功。
光线追踪目前是对硬件资源有贪婪需求的技术,桌面端的推广都尚且未全面铺开。AMD也是在RDNA2上才开干光线追踪的。一般光线追踪需要额外的专用硬件单元来做加速,比如英伟达的RT cores。
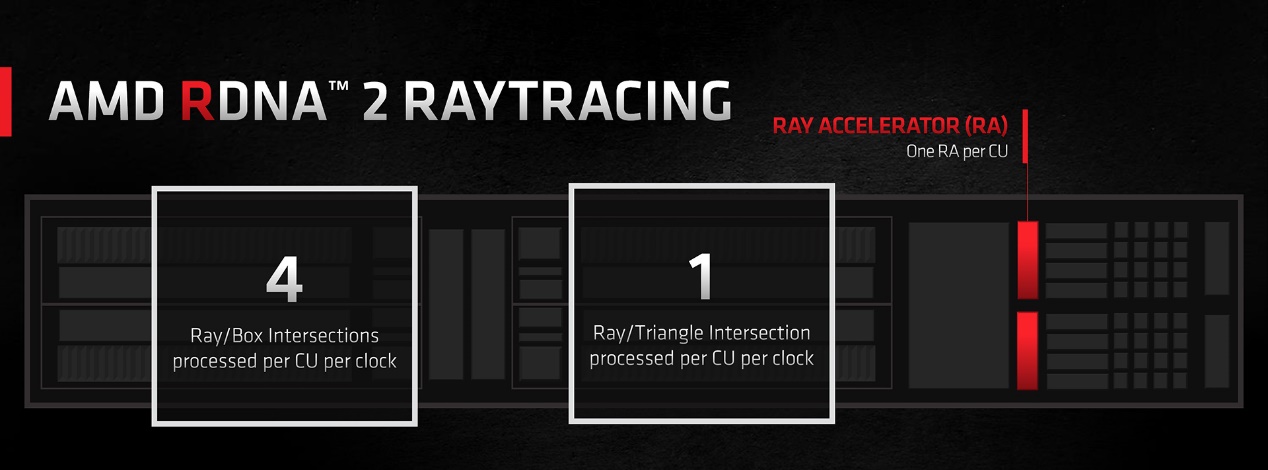
AMD这一代的GPU的确也加入了一个所谓的ray accelerator(光线加速器),每个CU中都有一个ray accelerator——这个硬件是用于检测BVH包围盒中的光线与图元相交,另外用shader来做BVH遍历并对场景做着色。像BVH遍历这种负载,算是存储敏感型任务,所以Infinity Cache在此也能发挥作用。
只不过AMD似乎并未交代过ray accelerator硬件的具体规格和构成,起码Radeon RX 6000系列GPU的光追性能,和英伟达GeForce RTX 3000系列还是有差距的。
于移动端而言,思路应该也会比较类似,Imagination此前介绍移动端应用光线追踪的方案,也是加专用的光追单元。只不过移动端的光追必然在规模和效果上,无法与PC平台相提并论。明年要问世的Exynos芯片,可能会是最早应用光追技术的手机芯片。
与苹果比起来怎么样?
要说和苹果比起来如何,如文首所述已曝光的3DMark Wild Life跑分8134分估计和iPhone 12 Pro Max的A14是比较接近(略胜或略差)。不过Twitter上的爆料者表示,这个跑分是基于Cortex-A77 CPU核心的,仅供参考。也就是说明年新推的Exynos芯片,预计这个项目的跑分还会更高。只不过苹果今年要推的A15,GPU性能还会有提升,所以鹿死谁手还得牵出来溜溜。
而且跨平台跑分这种东西看看就好,更何况还是小道消息,也无人知晓其跑分环境如何。而且像苹果A系列这样的高性能芯片,虽然有不错的突发性能,但从历史来看,它在手机上的持续性能也实在不怎么样;另外也需要考虑功耗的问题。AMD在手机上做GPU也逃不脱功耗与发热这样的基本命题。
 Lisa Su的大钻戒
Lisa Su的大钻戒
不过我们仍然很乐意看到,手机芯片市场出现可与苹果一较高下的新品,针对泛活市场,并促使其他竞争对手的和共同努力是有价值的,让高通、联发科这些市场竞争者都感受到压力,那么AMD GPU出现在三星手机上也就值得鼓励了。
责编:Luffy Liu
