
这两年我们参加了不少大学生电子竞赛之类的比赛。这些比赛的板子赞助商越来越倾向于提供带AI加速单元的开发板,高校之类的主办方本身也鼓励学生在竞赛作品中尽可能地融入AI技术,甚至将其作为一个硬性规定加入到比赛规则里,比如去年底我们参加的全国大学生电子设计竞赛,瑞萨作为赞助商,提供的板子就是加入了AI图像处理加速单元的产品——而且比赛中着意于突出这项特性本身。
这和AIoT或者说边缘AI的大趋势是有很大关系的。这类学生竞赛对AI技术,尤其是计算机视觉技术的融入,一定程度表明现在采用AI技术的开发门槛并不高,或者说以计算机视觉应用为代表的AI技术在走向成熟。
对于嵌入式应用、DIY爱好者、研究人员而言,现在要在产品或作品中融入AI技术,已经变得越来越容易。毕竟人脸检测、对象存在检测、人头计数以及各种计算机视觉相关的应用很热门,而且颇有稀松平常之势。现成的传感器、处理器算力支持,乃至算法支持的软件和库都愈发完善。
甚至主要占据云上AI市场的英伟达,在2019年GTC大会上都推出了价格99美元的Jetson Nano开发者套装——看起来其实不怎么像我们理解中英伟达的风格。这类型的产品对于AI相关的算法研究、做AI原型产品测试之类的都有价值。

而且在去年10月份,老黄又发挥生(jīng)态(zhàn)建(dāo)设(fǎ)的特色,推出一款2GB RAM的Jetson Nano开发套装,59美元的价格,即更低门槛就能上手AI(和CUDA)。英伟达自己在Jetson Nano产品的宣传上,分别用了“AI for Everyone”(4G版)和“Discover AI”(2G版)两个宣传语。
这个产品线尤其在边缘AI、AIoT方面具备了代表性,借此我们也能谈谈,嵌入式设计普遍开始融入AI技术的趋势,以及这个趋势的两个组成部分:性能与生态。
当AI技术入侵嵌入式设计
面向研究人员、开发者、技术爱好者、学生等的同类开发板,市场上比较知名的自然就是树莓派了,不过要单纯依赖树莓派的硬件资源做AI开发和研究还是不大靠谱的,同类的产品包括香蕉派、Nano Pi之类。毕竟通用处理器做AI计算还是效率太低,尤其是做实时的ML应用。很早以前我们就提过,从大趋势来看,无论是嵌入式领域,还是其他各种端侧(或边缘侧)设备,AI计算已经成为通用计算、图形计算之外,越来越重要的第三种能力。
所以类似英伟达Jetson Nano开发者套装这样的产品就问世了。一些面向特定领域的芯片和开发板产品,其实有不少也加入了AI专核。比如说前文提到的瑞萨RZ/A2M开发板,带DRP(动态可配置处理器)加速单元——虽然其面向的市场可能更具针对性——这类产品在工业领域就很常见。

更通用一些的开发板,有些即便没有AI专核,也有通过支持Tengine获得计算效率提升的——一款轻量级的模块化神经网络inference引擎,如瑞芯微RK3399开发板(ROCK960);进阶款的RK3399 Pro则加入了专门的NPU;还有比如晶晨A311D开发板,A311D芯片本身也集成了专门的NPU;下文还会看到谷歌edge TPU和Intel Myriad X......
Jetson Nano与这些产品的不同之处,主要还是延续了英伟达用GPU来做AI计算的传统(而且上面这些板子还真是一点也不便宜),这是英伟达与这些产品在思路上的差异。不过包括2GB版在内的Jetson Nano,在小身板下就支持CUDA,还是令人感觉相当不可思议(淘宝现在的价格似乎在430元左右)。
谈谈边缘计算的AI性能
Jetson Nano 2G开发板的主要配置包括,CPU部分是4颗1.43GHz的Arm Cortex-A57核心,GPU则为128个CUDA核的Nvidia Maxwell(Geforce 10系列Pascal架构的前一代),半精度浮点性能472GFlops,对比Myriad X之类更专用的VPU及上述NPU还是不及的。不过对比CPU仍然强了无数倍,而且英伟达那套令人难以望其项背的AI开发生态,也能某种程度无视竞品在纯硬件性能上的领先,下文在谈生态时还将提到这一点。
从这个配置不难看出,Nano在英伟达的Jetson家族产品线上就是更专注于低功耗、低成本的IoT,且主要定位于inference,虽然从英伟达的介绍来看似乎也能用于AI training。
这块板子的其他配置还包括2GB 64-bit LPDDR4,带宽25.6GB/s;视频编码最高支持4k30,4路1080p30,视频解码最高4k60,8路1080p30;1个MIPI CSI-2摄像头接口(支持Raspberry Pi摄像头模块、Intel Real-sense以及不少包括IMX219 CIS的摄像头模块),还有USB、HDMI、千兆网口、无线适配器、microSD插槽(作为本地存储)等,其他I/O相关的配置就不赘述了。99美元4G内存版的Jetson Nano开发板除了内存更大以外,在I/O资源上也会更丰富一些(包括要额外接无线网卡的M.2接口)。
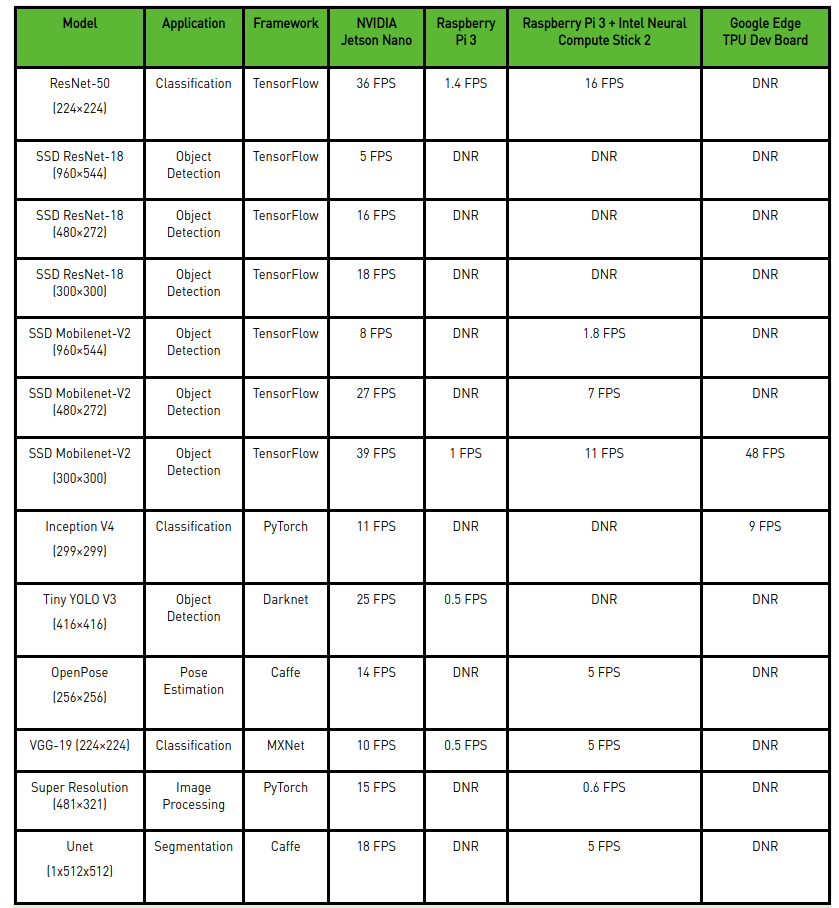
英伟达自己有专门列一张表格,对比的是应用视频流的不同模型下,Jetson Nano、Raspberry Pi 3、Raspberry Pi 3 + Intel Neural Compute Stick 2(集成的就是Myriad X)、谷歌Edge TPU开发板几款产品的实时inference性能差异(batch size 1,精度FP16),如上图所示(注意:这个对比的是4GB版的Jetson Nano)。
事实上,相较Raspberry Pi的碾压优势,以及相比TPU略弱的性能表现,是意料之中的——这本身就是通用和专用之间的差别(对比Myriad X的领先,可能是生态方面的能力体现)。不过这张表中有不少项目“DNR”是指did not run,可能是因为有限的内存容量、不支持网络层或者其他软硬件限制,所以跑不起来的。这部分英伟达想传达的,应该是GPU的通用性会明显更好。
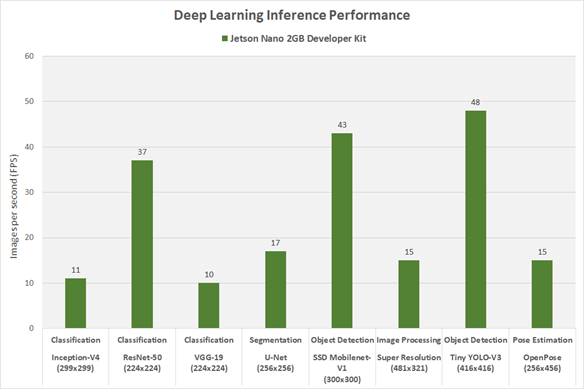
2GB版的Jetson Nano,在主流模型下的性能表现则如下图:
当AI开始谈生态
谈到通用性,也就不得不说英伟达在AI领域已经几乎没有敌手的生态建设进度。英伟达此前不止一次地提到过,AI计算科学发展迅速,研究人员在相当迅速地发明新型神经网络架构,AI研究人员或从业者在项目中使用各种各样的AI模型。“所以对于学习和构建AI项目而言,理想的平台应该是能够跑各种AI模型、具备足够的弹性,同时又能提供足够的性能,来构建有意义的交互式AI体验。”
主流ML框架,包括TesnorFlow、PyTorch、Caffe、Keras等就不多提了,上面的那张表给出流行的DNN模型,Jetson Nano都提供了支持。包括相对完整的框架支持、内存容量、统一内存子系统,还有各种软件支持,是实现通用性的基础。而且不只是DNN inferencing,Jetson Nano的CUDA架构可用来做更大范围的计算机视觉、DSP,包括各种算法和操作。
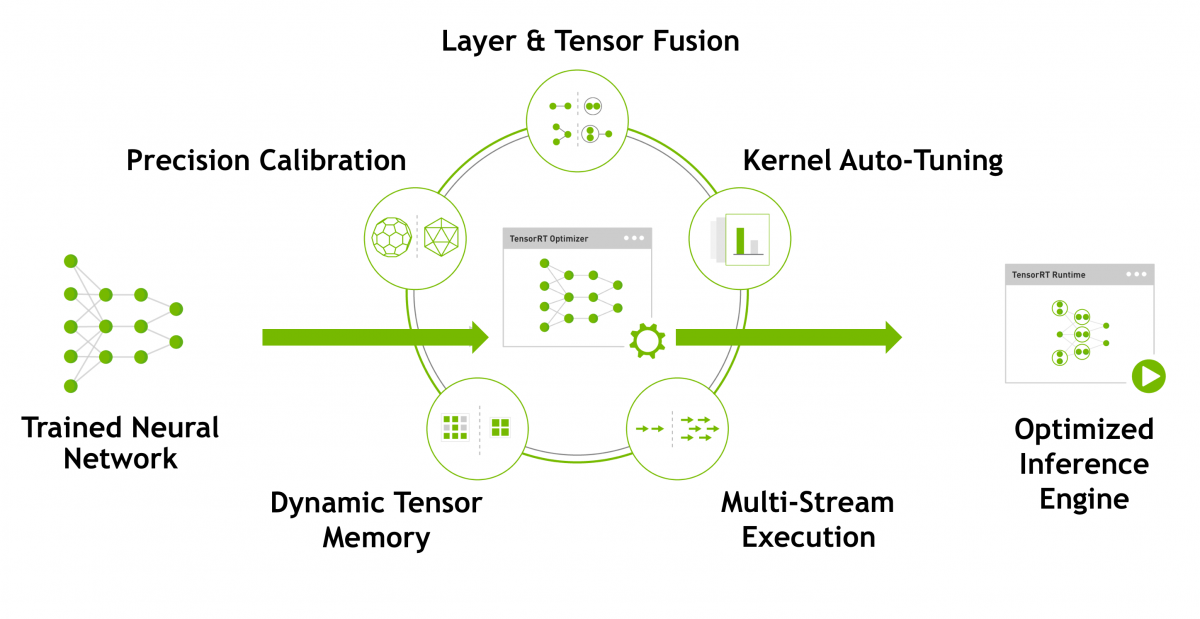
尤为值得一提的是,上面这些模型在Jetson Nano上执行用上了TensorRT。对英伟达AI生态熟悉的同学应该知道,TensorRT是英伟达推的一个中间件,输入模型后,CUDA GPU藉由TensorRT就能生成优化过后的模型运行时,是英伟达实现AI计算性能优化的重要组成部分。
TesnorRT作为一种软件,是前面的例子中实现更高帧率,达成更高计算效率的重要组成部分。有研究人员测试过不用TensorRT优化,在Jetson Nano 2G上直接编译一个版本的Caffe模型,虽然问题也不大,不过经过TensorRT加速的版本在效率上会有相当大的提升。
由TensorRT可引出的,一方面是英伟达每年在讲自己不是或不只是一家芯片公司,另一方面这也是Jetson Nano生态资源有英伟达做靠山的管中一窥。
简单来说,Jetson全系列所有硬件平台对各种软件工具和SDK的通用:Jetson Nano开发套装软件部分是JetPack SDK,包括Ubuntu操作系统,还有构建端到端AI应用的各种库,比如说用于计算机视觉和图像处理的OpenCV和VisionWorks;加速AI inferencing的CUDA、cuDNN、TensorRT,还有各种库。英伟达此前在营销上,把各种软件加速库称作CUDA-X软件栈(不过今年好像没怎么提这个词)。
这其中比较典型,可列举的与Jetson Nano强相关的,包括了针对智能视频流分析的Nvidia DeepStream,针对医疗成像、基因和病人监护的Clara,以及用于机器人的Isaac等。更现成的资源还有一大堆英伟达储备的预训练模型,通过transfering learning迁移学习做定制化的模型调整后,应用于Jetson Nano做inference,也属于这个生态中的重要组成部分。
这些我们在过去谈Nvidia生态的文章中多少都有介绍过。感觉谈到这里,其他板子从“AI生态”层面就弱了一截,更具效率的偏ASIC的AI专用处理器,好像这会儿也就不是个事儿。
举几个例子说说
我们浏览了英伟达官方写的Jetson Nano开发指南,包括环境搭建、现成库的简单使用等;发现Jetson Nano的主要应用,应该是对象检测、图像分类、语义分割,还有语音处理之类的,再具体些则可能包括了NVR网络视频录像机、自动驾驶小车、智能音箱、门禁系统、SLAM机器人,以及与智慧交通、智慧城市相关的各种嵌入式的AIoT应用。

要形象地表现这类开发,我们来简单地举一些例子,同类板子在很多特性实现上也有类似的过程,不过Jetson Nano有更广泛的生态。环境搭建的准备工作就不提了,给microSD卡写入image还是比较简单的过程。将microSD卡插入Jetson Nano(4GB/2GB)卡槽,接上电源、鼠标、键盘、显示器,就能开始用了。操作系统是Ubuntu 18.04 L4T,2GB版为了减少系统占用,桌面预设为轻量级的LXDE。用来学习、开发Python、OpenCV和AI深度学习、ROS自动控制等应用都是可行的。
给Jetson Nano安装摄像头,包括前文提到的CSI接口的,也可以是USB接口的。JetPack有内置OpenCV开发环境,配合CSI摄像头可以从摄像头输入,来实现一些基础的机器视觉应用;包括对输入图像尺寸做放大插值、旋转等;更高级的比如说追踪画面中特定颜色的对象、边缘检测、人脸追踪/眼睛追踪。
 来源:NVIDIA英伟达企业解决方案
来源:NVIDIA英伟达企业解决方案
以边缘检测为例,执行过程大致上是首先将画面转为HSV灰度图像;然后对HSV灰度图进行高斯模糊处理——这一步是为了对画面进行降噪;最后为图像找出边缘线条。整个过程调用几个函数即可,如上图所示。执行过程与结果大致如下:

这是比较常见的机器视觉应用。再来看看真正利用了AI的应用,利用OpenCV库和Python3开发环境来实现人脸识别,公司打卡、点名系统之类的就需要此类功能。利用face_recognition这个Python人脸识别库就能搞定,这是基于dlib机器学习开源算法库实现的,函数调用比较简单。
这个库的face_locations方法就能找到图像中人脸的位置,藉由OpenCV将框画到原图上并显示结果。代码如下图所示,这个例子是对图片中的人脸进行定位,套个while循环就能读取视频了。

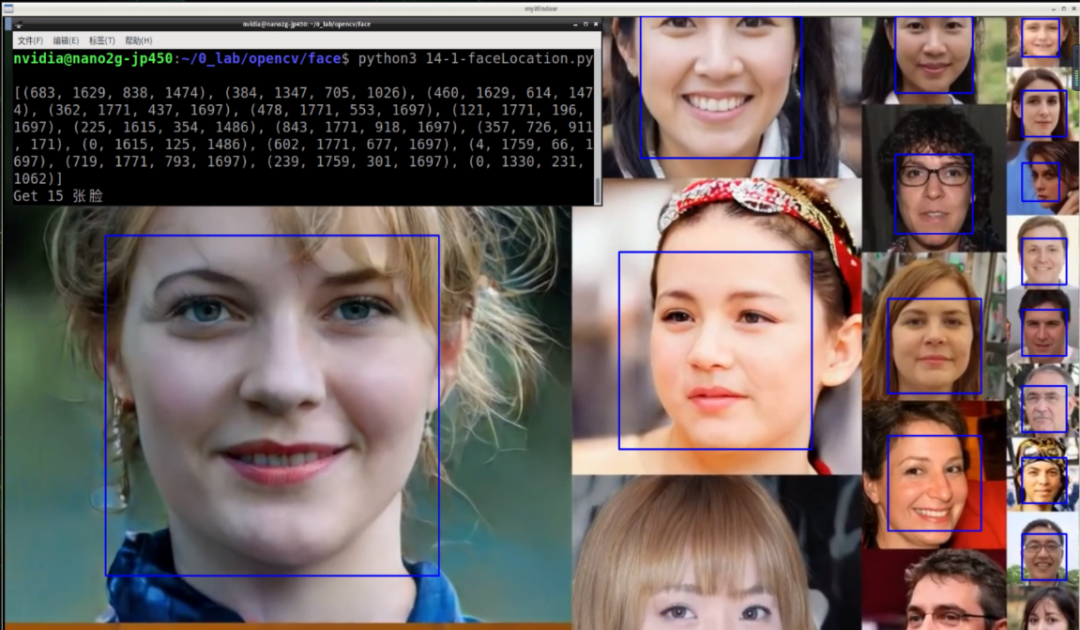
在人脸定位后,还需要与人脸特征库进行比对,完成身份识别这里不再展开,有兴趣的同学可以去看英伟达官微针对Jetson Nano 2G的系列文章更新。就这个上手AI开发的过程,还是相当轻盈和方便。
值得一提的是,若要体现性能和生态方面的优越性,实际上JetPack安装好以后,就能找到一些CUDA sample。这些示例包括了海洋模拟实验oceanFFT、烟雾粒子模拟smokeParticles(256x256烟雾粒子运动变化,有光影变化)、nbody粒子碰撞模拟等。
对比执行过程可以用单纯用CPU,或者藉由GPU并行能力做加速,就能感受到性能上的显著差异。这些CUDA示例本身应该是最能体现Jetson Nano在性能和生态上的价值的。

尤为值得一提的是,英伟达针对Jetson产品线和作为体验AI的构成,特别做了个Hello AI World,也算是AI生态的一部分,宣称开发者只需要在几个小时内,就能感受各种深度学习inference demo,在Jetson Nano上搭配JetPack SDK、TensorRT等,用预训练的模型,跑实时的图像分类和对象检测等功能。(而且英伟达的开发者blog也列举了用Jetson Nano来跑完整的训练框架,用Transfer Learning来重新训练模型,感觉也算是个用途吧,估计所需时间不会很短……)
Hello AI World应该算是个教程,主要是相关计算机视觉、摄像头的应用,相关图像分类、对象检测、语义分割等,还有Deep Learning Nodes for ROS这类将识别、检测等特性与ROS(Robot Operating System)做融合,达成机器人系统和平台的开源项目。其实Hello AI World本身就能表明,英伟达在生态布局上的全面性。

最后可以谈谈英伟达软件能力或者说AI生态能力的一个具体体现:英伟达官微曾经给出过10行python代码,如上图,“实现对90种类别的深度学习物体检测识别”。似乎以Jetson Nano 2G的硬件资源,即便是很优秀的YOLOv4或者SSD-Mobilenet算法,跑起来也只能达到4-6FPS的性能。
但在JetPack生态下执行这段python,系统会为模型生成对应的TensorRT加速引擎。这里代码第一行是导入工具库模块,尔后建立input和output对象;第四行是导入“深度学习推理应用”的模块,然后用detectNet()建立net对象,处理后面的“物理检测推理识别”任务。
While循环里,第七行是读取一帧图像,第八行代码就把图像中满足阈值的对象检测出来了。而且因为TensorRT的存在,这行代码在实现上,性能可提升不少,初学者不需要面对调用TensorRT的问题。第九行的方法,是针对画面中检测到的对象,把包括框、类别名称、置信度等数据叠加到图像上。在英伟达的底层实现上,把原本4-6FPS的性能提升到10+FPS。这个例子我们感觉还是颇具代表性的。
本文以Jetson Nano 2G为例,简单谈了谈嵌入式开发板加上AI能力之后,要把开发友好性做好,性能和生态都是必不可少的。硬件性能是基础保障——更多的嵌入式板子开始带AI算力加成是趋势;而现有的开发生态,则已经有以英伟达为代表的厂商,极大降低了开发难度,起码降低了初学者的上手难度,并实现了性能效率上的显著优化。(也算是从侧面印证了,英伟达可能是一家软件公司…)
责编:Luffy Liu

