
前不久我们介绍了Arm在数据中心市场的部署,主要谈到了Arm Neoverse产品线——即在Cortex之外的另一条面向服务器和基础设施设备的核心IP。包括初代发布即收获不错市场反响的Neoverse N1核心IP,亚马逊Graviton2、Ampere Altra都是应用了这一IP的产品。
除了N1之外,Arm此前还预告了今年即将推出的Neoverse N2和Neoverse V1。在上篇中,我们大致谈到Neoverse N1属于Cortex A76的变体,而今年推向市场的Neoverse V1则可类比基于Cortex X1的核心;N2则是个新架构,包括基于Armv9指令集,规划上全面采用5nm工艺等。


Arm前几天召开了一场发布会,详述Neoverse N2与V1这两个架构的情况,也分享了Neoverse系列IP目前的市场表现——尤其谈到Graviton2被亚马逊应用到了更多实例中,这些实例的增量远超x86产品。有关Arm面向基础设施的市场规划,可参见上篇内容,此处不再赘述;本文着重谈一谈N2和V1这两个微架构。
“应用于所有基础设施”的野心
我们知道,Neoverse N1的价值主要体现在相比x86产品更出色的Performance/TCO,也就是性能与TCO(总拥有成本)之比。亚马逊开发自家的Graviton,很大程度上也是基于节省成本的考量:这其中包括了Arm处理器在能效方面拥有更大的优势,能耗相关的成本投入上也有不错的红利。
但至少在Neoverse N1之时,如上篇提到的,其每核性能表现实则是不及同时代的x86竞品的。不过Arm一直在提“用内核来代替SMT”,并且强调单线程(整数)性能,以及“Arm合作伙伴提供比传统线程更完整的内核”,或者“用内核代替SMT线程”,尤其云环境负载更需要专属的核心——很显然这是在说x86阵营的同时多线程(比如Intel的超线程)在服务器市场并无太大价值。
无论这样的说法是否公平,在单线程性能表现(以及每瓦性能),乃至每核心一个线程的性能表现上,这次的Neoverse N2/V1都可能已经有了与传统x86处理器一较高下的资本。
单线程性能的持续提升实则也是Arm得以在服务器、基础设施市场站稳脚跟的关键。Arm基础设施事业部高级副总裁兼总经理Chris Bergey表示,在Neoverse时代之前,Arm面向基础设施的内核是基于Cortex-A72的,“它具有出色的能效比,而且媲美竞争对手的线程所提供的单核性能表现”,“但有些基础设施细分市场还希望能进一步提高性能,并在大规模使用时保证性能表现。”
“于是就有了现在的Neoverse N1内核与CMN-600 Mesh网络,将线程性能扩展到非常高的内核数量,这也使得Neoverse更加适合云服务。”Bergey说,“在AWS Graviton2和Ampere Altra这样的芯片上,几乎所有工作负载都能为用户带来高出40%的性价比。”
在Arm看来,通过这次新发布的Neoverse V1和N2,“我们将带领大家进入这个新时代。我们想要改变业界对部署基础设施的看法。大家不需要在性能和能效之间做选择,我们希望大家能够二者兼得。”这话的魄力还是相当之大。
“我们相信,我们的单核性能将能胜出传统架构。当Arm合作伙伴提供比传统线程(指SMT方案)更完整的内核时,哪一种解决方案能为最终用户提供更好的性能和价值,已经毋庸置疑。这种说法发主要针对的是云服务,但考虑到Arm的性能和能效,这种说法也适用于所有基础设施市场,从HPC、云到边缘。”Bergey表示,“Arm Neoverse应用于所有基础设施应用市场的时代已经到来了,现在正式启动。”可见Arm对Neoverse V1/N2给予了多大的厚望。
Neoverse V1与N2的性能与能效变化
在面向国内的线上发布会上,Arm提到的有关Neoverse V1/N2的微架构改进细节并不多,主体上是以分享案例和谈性能提升为主的。那我们就先来看看这两个新架构在性能和能效上的变化,包括相比前代产品(N1)和竞品(x86)。
在此前的发布会上,Arm就提到过Neoverse V1将实现50%的IPC(每周期执行执行数)提升,对比对象是N1。50% IPC提升在这个时代听起来是比较恐怖的数字,不过其实仔细想一想,Neoverse N1是基于Cortex A76的,而Neoverse V1在核心微架构层面与Cortex X1相似。这其中差了2-3个代际,50%的IPC提升也就显得顺理成章了。而且Neoverse V1和Cortex X1一样,都是在PPA指针方面更偏向性能,并一定程度牺牲成本、功耗为代价的微架构,V1原本就代表了彪悍的性能之路(应用定位上也偏HPC)。
值得一提的是,50%性能提升这个数字是个中值,即在不同的应用场景,可实现的IPC提升是不同的。比如能够充分利用SVE的工作负载,最高能够获得100-125%的IPC提升。
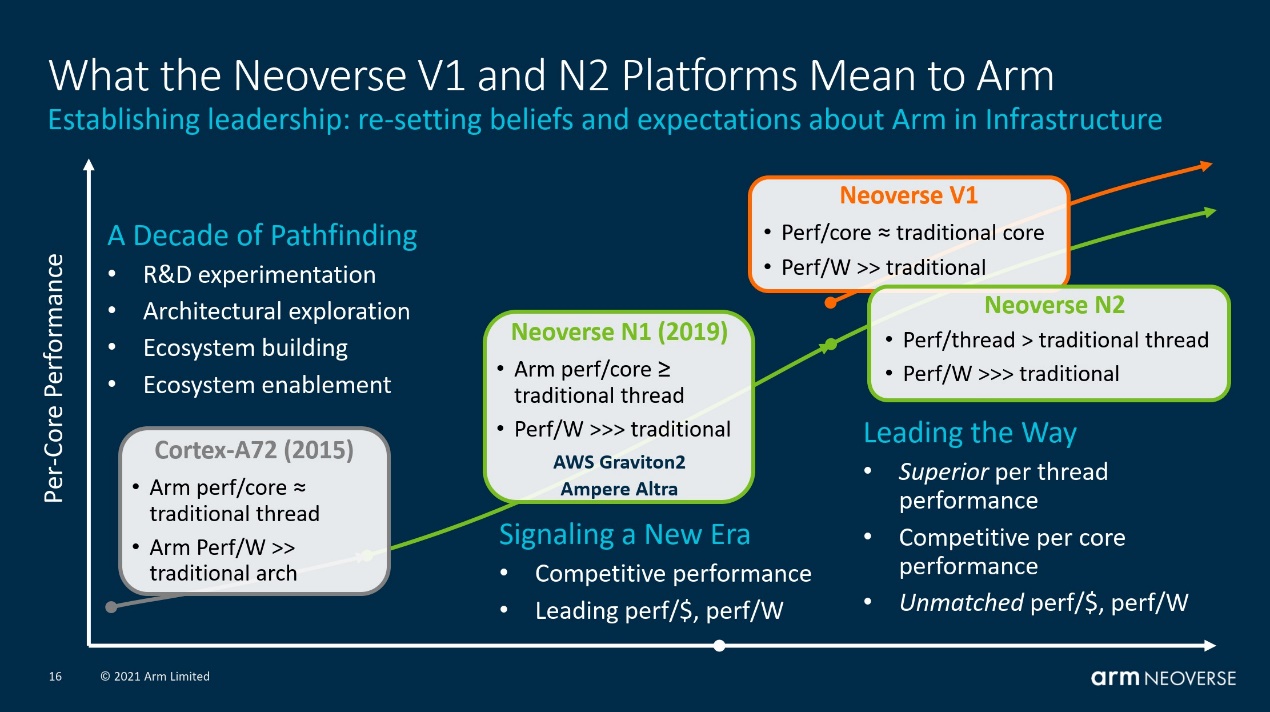
虽然在国内的发布会上Arm并没有提,但国外媒体给出的PPT上可见,Arm给出能效方面的数字为Neoverse V1是N1的70%-100%,核心面积是N1的1.7倍。意即功耗和面积产生了不对等的增加,这是符合预期的,因为如前所述V1部分牺牲了功耗和成本,换取性能的进一步提升。这里1.7倍的面积变化,也能看出在推升性能上,要付出的代价的确不小。如此,V1核心频率应当不会比N1更高。虽然即便是这样,包括面积效益、能耗比方面还是会显著优于x86。
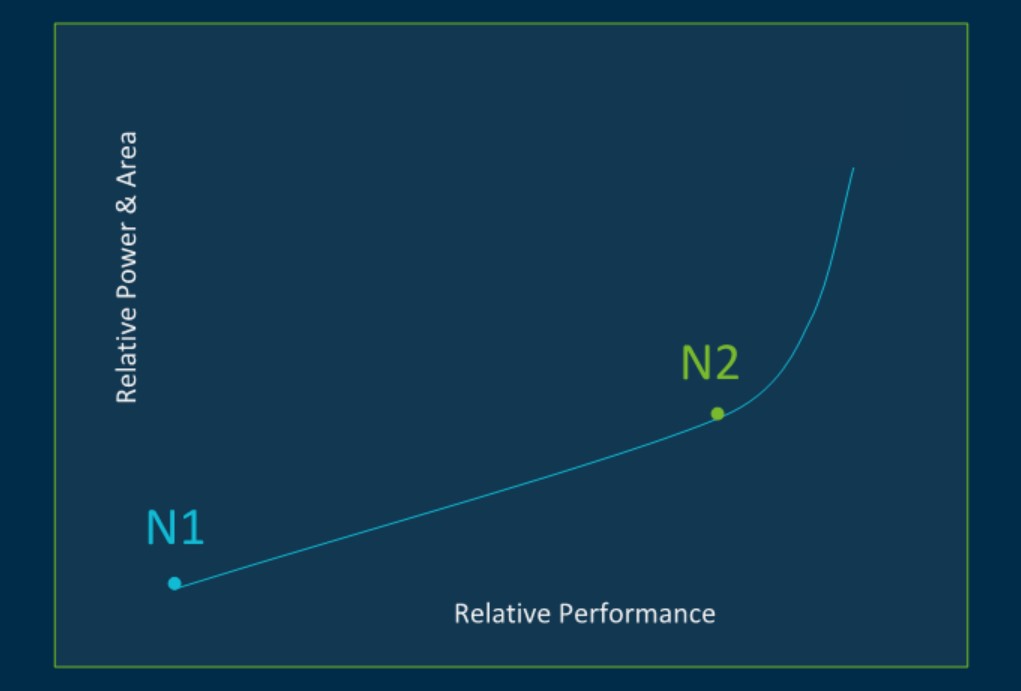
而在Neoverse N2这边,在相同工艺和配置下,N2相比N1也有着40%的IPC提升;面积多出1.3倍;功耗则会高出大约1.45倍——表明N2和N1的能效基本相似,略有下降。在Arm所画的相对性能与功耗曲线图上,以N1为参考,N2的性能提升,伴随的是功耗方面的线性提升——或者说N2在设计上,是性能与功耗线性提升的临界点,再往后,功耗就开始蹿升了。所以N2在Arm眼中仍是兼顾了PPA的核心,这一点与V1就很不一样。
Arm有特别提到在性能提升的基础上,5nm工艺实现的Neoverse N2核心在功耗与面积上,可与7nm的N1持平。这是个相当乐观的估计,不知未来N2具体实施方案能不能达到这个程度。

上面这张图是Arm给出的不同规格的Neoverse核心,与竞品的比较。横轴表示单个socket插槽的整数性能表现,纵轴表示单线程整数性能。很显然,其中写着“Traditional”的竞品就是指Intel和AMD去年与今年的服务器CPU。
“这些是Arm基于,我们认为具有市场代表性的内部参考系统,所做的预测。” Bergey说。
在纵轴单线程整数性能上,前文就提到了Arm基本无视了x86阵营的SMT设计(Arm此处列出的是竞品单核SMT之时,每线程的性能表现)。这对Intel/AMD而言其实是不大公平的。如果以一个核心一个线程来算,如此前文章中提到的,N1目前的产品相对落后于Intel Xeon和AMD Epyc。Neoverse V1对x86前代产品的超越应该是个必然,但论单核单线程性能,应该还有商榷的余地。
比如图中的Traditional 2021(40C/80T)指的应该是Intel Xeon 8380(Ice Lake-SP)。从SPEC2017 Rate-1单线程性能测试来看,Ampere Altra Q80-33的Neoverse N1核心实际上还是会略弱于Ice Lake-SP的(虽然有能效上的优势)——所以还是需要看具体的实施方案。不过可能的确如Arm所述,在很多基础设施环境(比如云),Arm的这种“更完整的内核”可表现出更大的价值。
而在横轴单socket插槽性能方面,多核心的优势自然更能淋漓尽致地体现出来。只是像图中128c/128t这样的设计,最终还是要看具体芯片的实施方案(比如N1虽然也规划了128核,但目前最高核心数的Ampere Altra处理器采用了80核心的设计;以及PPA权衡是否真能达到Arm的预期)。
即便下半年服务器处理器市场还会有Sapphire Rapids这样的劲敌出现,不过从Arm对Neoverse V1和N2的预期来看,Neoverse如今在服务器市场,战力又比去年增长了一大截,起码在性能方面也已经可以与对手叫板了,更不必说能效和性价比固有的优势。
Neoverse V1:更宽的架构
接下来就谈谈这两个新IP的微架构变化。有关这部分,Arm在国内的发布会上谈的不多,所以内容主要来自国外同期报道的一些汇总。另外Arm透露的有关Neoverse N2的内容也很少,这可能是因为N2这种新架构的详情,等着将来新一代Cortex产品问世时再揭晓。
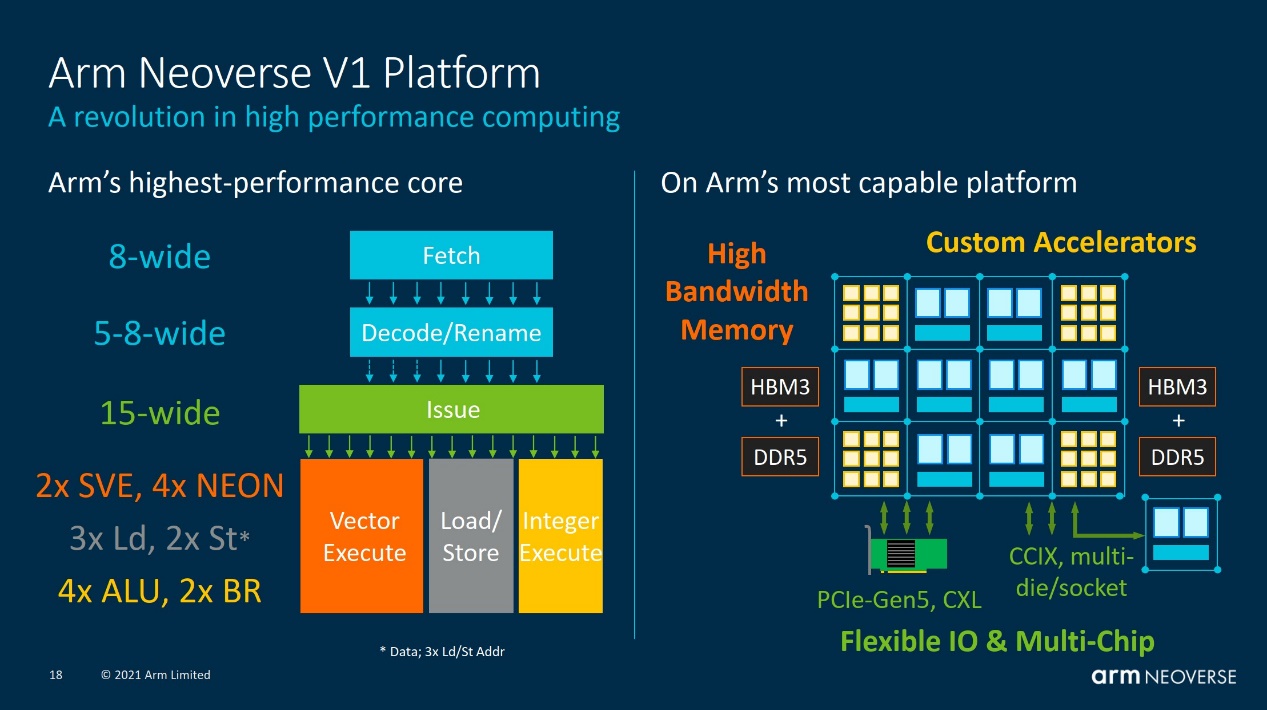
对Neoverse V1而言,如前文所述,这是个与Cortex X1有着诸多相似之处的核心,如上图所示的CPU管线:包括取指带宽加倍,更大的L2 BTB(8K entries),L0 BTB(96 entries),去掉了L1 BTB。另外和Cortex X1一样,引入了Mop cache(缓存最多3K解码指令),Mop分发带宽8-wide,指令解码宽度5-wide;OoO乱序窗口尺寸翻倍,ROB增加到256 entries;后端增加超标量整数执行带宽,分支执行端口翻倍,新增一个复杂ALU;存储子系统部分,同样增加了load/store单元数量。
缓存结构上,L2 cache在1MB容量下缩减1个周期,bank数翻倍提升访问并行度;SLC延迟大幅缩减。新一代prefetcher,能够发现针对存储的任意访问模式,以对后续相同模式的迭代做出识别和数据预取。为减少L2到SLC的流量采用一种新型的动态预取行为。

而Neoverse V1上比较重大的一些改进,包括Neoverse V1是Arm旗下首个支持SVE的微架构。SVE即Scalable Vector Extension,此前一直被认为是Neon的下一代扩展。Neon本身是一种SIMD(单指令多数据)。Neon一直使用固定长度的数据格式,早前128bit的计算宽度也适中。不过固定长度计算方式限制了其扩展并行计算能力。所以SVE作为当年Armv8.2-A的可选扩展就出现了。
SVE实现了128-2048bit可变矢量长度。这对软件而言是很有价值的,相同的代码就能跑在不同的目标产品上了。早前固定矢量长度计算方式,比如从128bit迁往256bit,就需要软件做重新设计和编译,才能应用这种更宽的执行能力。所以Arm的PPT针对SVE的描绘是:write once, compile once, deploy forever…
此前富士通的A64FX就率先用上了512bit SVE。而Neoverse V1则采用2条256bit宽度SVE管线,向后兼容128bit NEON/FP操作——也就是可作为4x128bit管线来用。除了这种可变长度的特性之外,还有不少特性,以此让编译器生成更优质的自动矢量化代码。
“Arm现有的SIMD指令集NEON难以对某些代码进行矢量化处理,例如这里的HACC示例。”Bergey解释道,“而SVE可以直接取用相同的代码,并很好地对其进行自动矢量化。相比于NEON,可提升将近3.5倍的处理速度(是指Neoverse N2)。”“在V1上加倍SVE矢量宽度,对应处理速度也就几乎提升了一倍。”也就是上图呈现的6.9倍。
SVE的引入对于重矢量计算负载的HPC而言,Neoverse V1/N2都会有相当大的提升。
与此同时,Neoverse V1也引入了对于BFloat16、Int8数据格式的支持,相比N1即加强了ML表现——Arm的数字是机器学习4倍性能提升。
Neoverse N2:应用Armv9与SVE2的新架构
有关Neoverse N2的介绍,Arm透露的信息不多。从N2基于Armv9指令集就能看出,这是个面向未来,且晚于V1的设计。如前文所述,N2是尽可能在提升40% IPC的基础上,藉由5nm的工艺红利与微架构的改进,将功耗维持在于N1相同水平线上的核心IP。
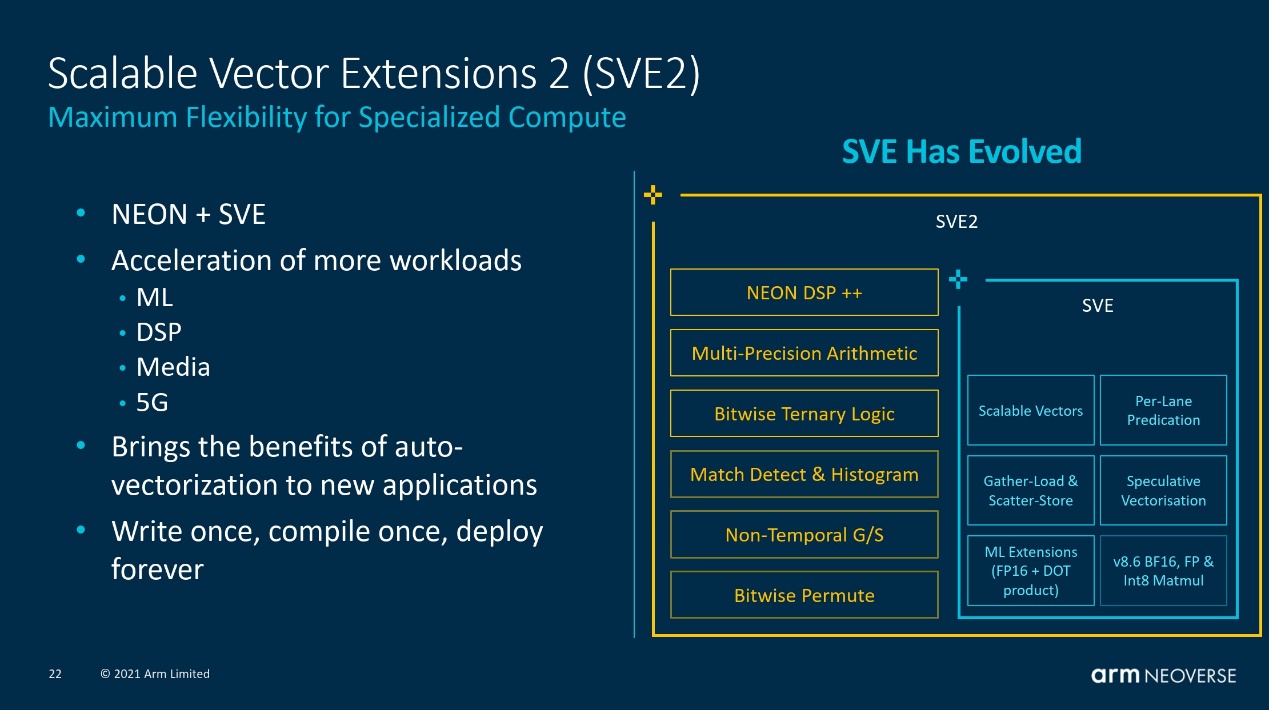
SVE2是Armv9引入的新特性,SVE2也就是第二代SVE。Neoverse N2应用了SVE2,虽然其管线宽度只有V1的一半(2x 128bit)。Arm官方介绍中提到,SVE2在数据级并行(DLP)覆盖到了更多的功能域。SVE主要针对HPC、ML应用设计;而SVE2则将范围扩展到更多的数据处理领域。
“SVE2把我们讨论的与SVE相关的性能、编程简易性及可移植性等优势,应用到更广的领域和场景。” Bergey在发布会上说,“SVE意在加速HPC,而SVE2则将其扩展到了ML、DSP、多媒体和5G等应用场景。”这符合Arm将Neoverse扩展到更多基础设施设备上的意愿。
在针对Neoverse N2的宣传中,Arm给的数据中也包含5G边缘上“1.2倍的DPDK L3数据包处理”,“在云端提升1.3倍的Nginx表现”等。
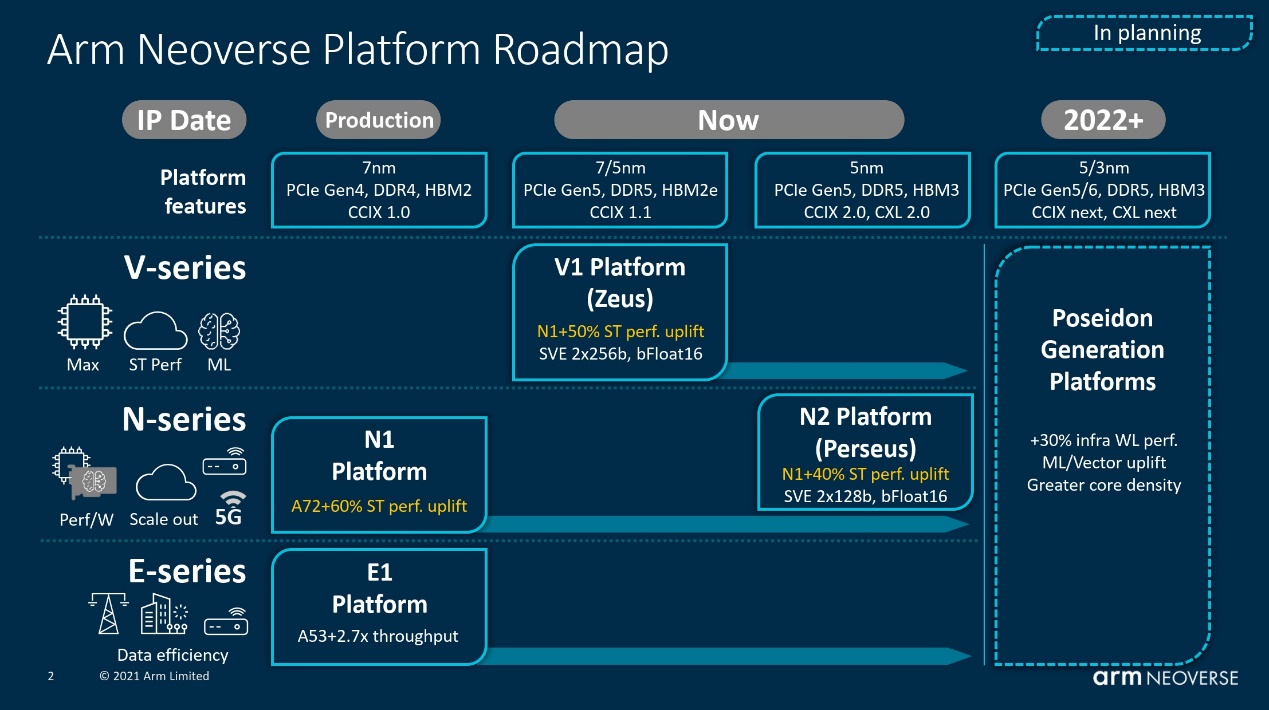
从Arm的路线图可知,N2产品的问世将晚于V1。N2本质上是V1的一个超集,只不过在具体规格上更加保守,毕竟V系列是真正面向高性能、HPC的;N系列则在基础设施方面具备了更广的通用性。
CMN-700 mesh互联:CCIX升级,新增CXL支持
上篇Neoverse N1文章也大致谈到了核心及更高层级的一些互联方案,上代产品的核心互联用的是CMN-600——这是Arm于2016年发布的SoC互联IP。随同Neoverse V1/N2核心一同到来的,是新版的CMN-700。
Mesh网络连接大量核心,实际上也是这类面向服务器的IP根本上有别于Cortex系列的一部分。有关CMN如何连接核心,上篇中已经有了一些简单介绍。
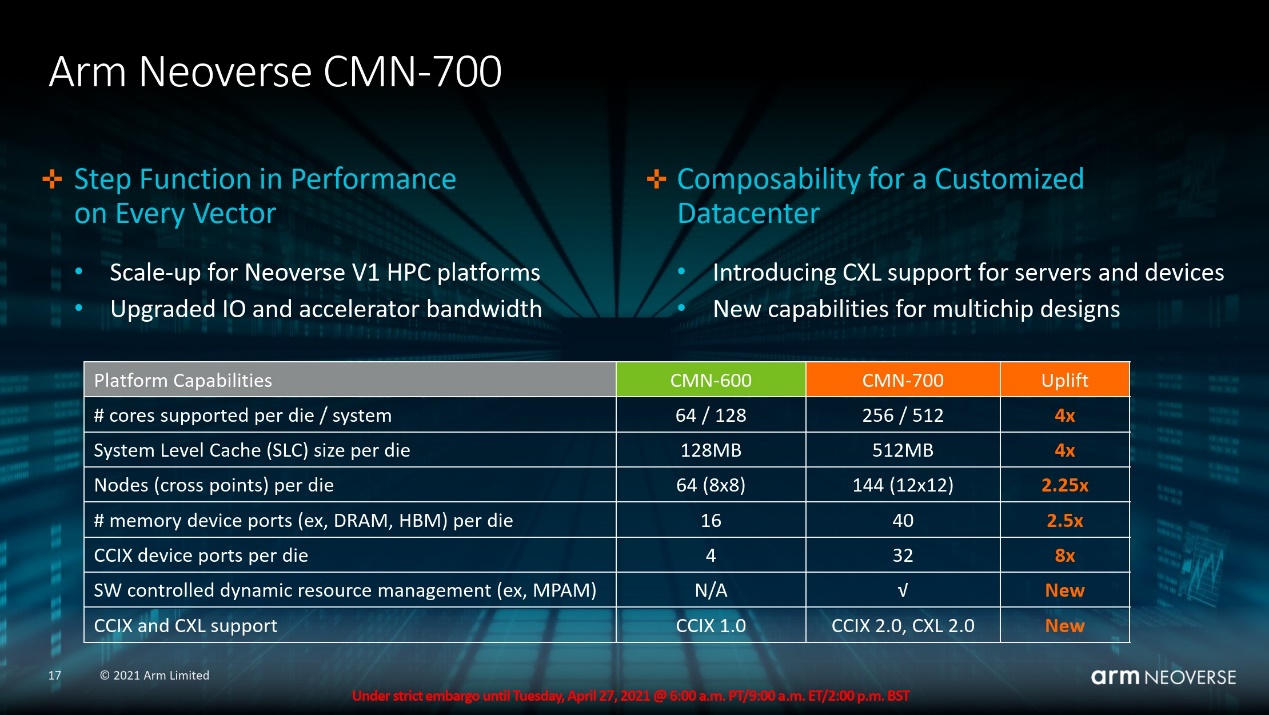
“Arm CMN-700 Mesh互联技术是构建基于V1和N2高性能SoC的关键要素。”“CMN-600为可扩展、高内核数、高性能SoC奠定了基础。CMN-700是基于这个成功的基础打造的,并在每个规格上都做了提升,从内核的数量、缓存的大小,到附加内存和IO设备的数量和类型。”
从上面这张规格表可见,CMN-700 mesh网络的交叉节点数量增加,单die之上的核心数也对应增加,从此前的64个增加到最多256个(上代N1扩展到更高核心似乎是通过DSU实现的)。每颗die最大的SLC可以达到512MB,每个节点4MB。
不过SLC在具体实施中会遇到一些实际问题,比如说Ampere Altra作为一款80核处理器,实际只配了32MB SLC,和Arm的目标配置相去甚远。外媒Anandtech对此的分析是,mesh网络中Home Node节点(带Snoop Filter的SLC缓存模块,snoop filter cache是一种特殊的缓存,存储索引信息,主要用于减少因缓存一致性所需的cache tag查询)的snoop filter缓存占用的面积比较大,所以实际的缓存大小设计也可能因此受限。
另外mesh上的最大内存控制器端口数量由16增加到40个;CCIX端口由原先的4个增多到32个——这对那些较多chiplet设计的芯片而言会有价值。
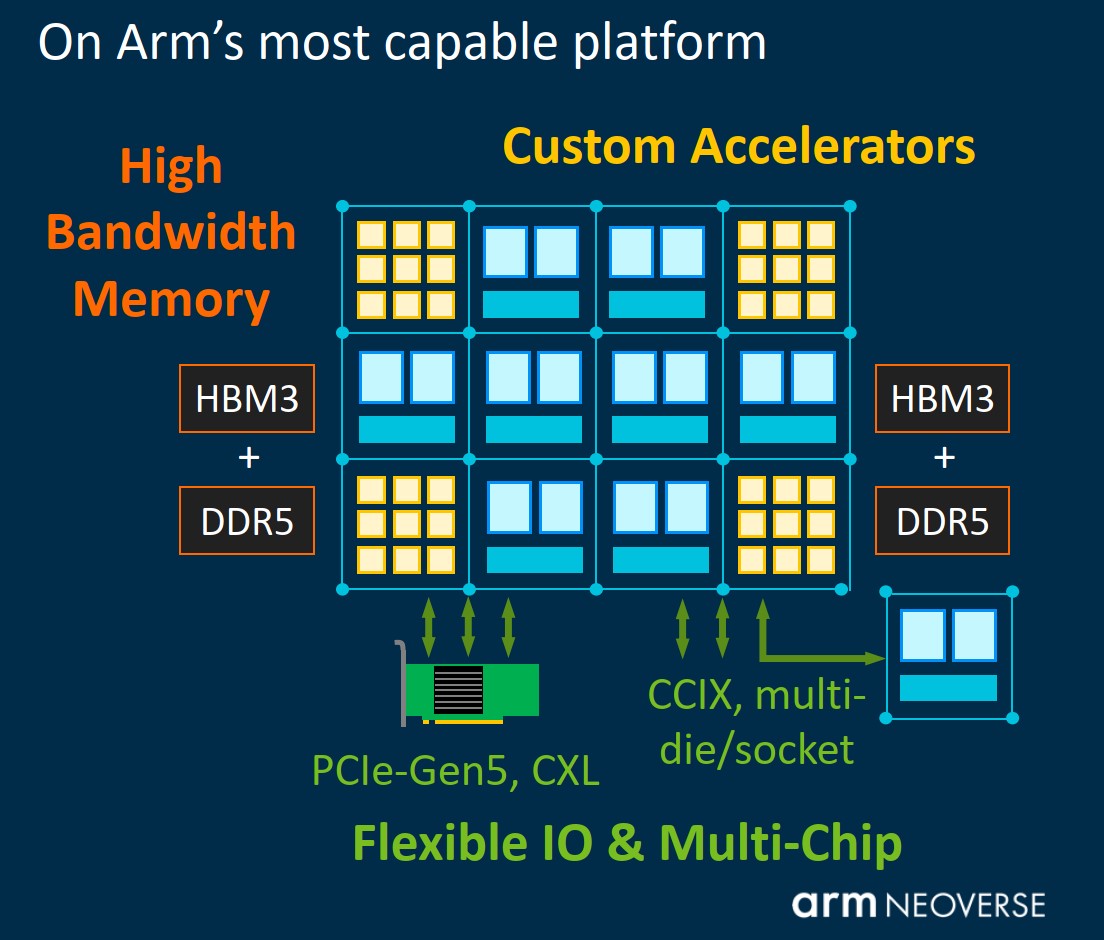
“对于基于V1的HPC平台而言,支持高带宽DDR5和HBM内存系统至关重要,CMN-700就实现了这一点。” Bergey表示。Arm的PPT就明确提到了对DDR5+HBM的混合支持。更高的mesh频率、节点之间mesh通道拓宽,则实现了互联带宽的提升。
针对CCIX的支持,这次升级到了CCIX 2.0。这在多die、多socket设计上,对Arm而言是比较重要的更新。上一代Ampere Altra在双socket配置上就表现得比较低效,相比竞争对手有差距。CCIX 2.0着力在缓解这方面的问题,当然具体的还是要看最终成效。
“CMN-700一个关注重点,就是对多芯片功能的助益,以便为数据中心资源池化的增长提供更多的定制选项。” Bergey说。针对多芯方案,Arm在CMN-700方案上的一些改进,包括跨双芯片做Home Node节点一致性;还可通过一个中央I/O hub实现更大的弹性(如异构chiplet)——为此Arm引入了一种Super Home Node,作为中央一致性节点,内部有SLC、snoop filter。
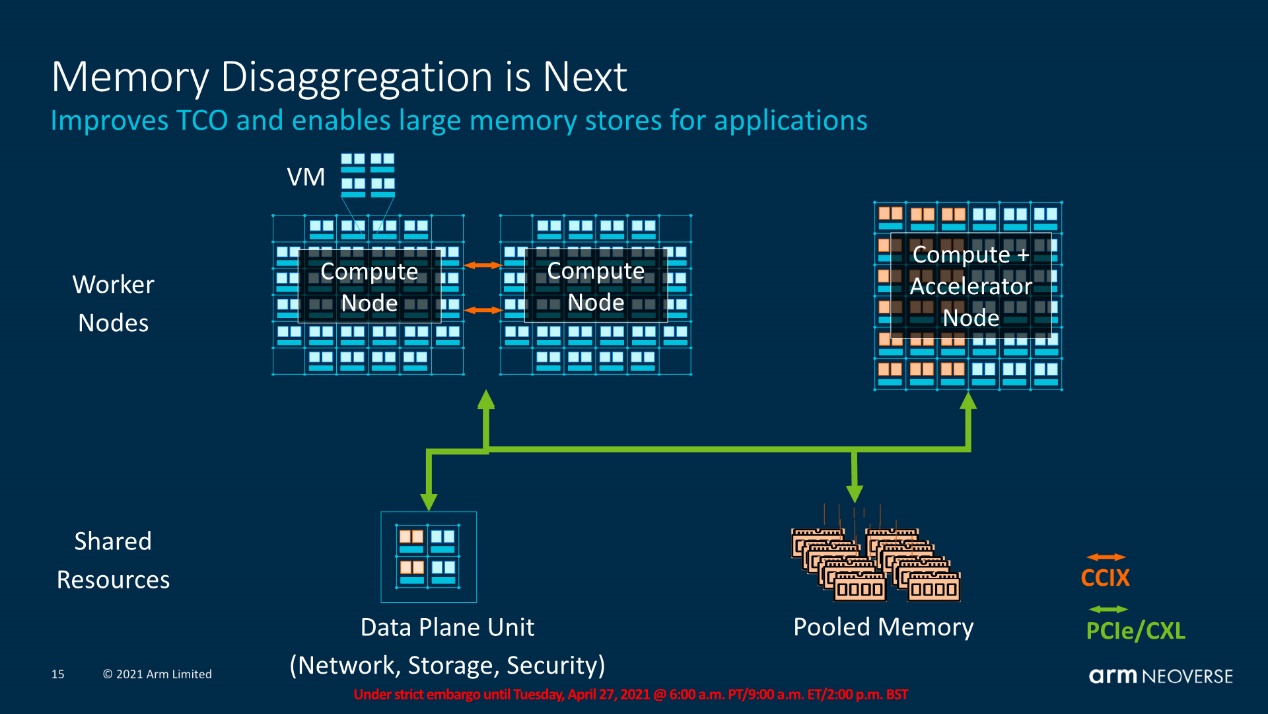
而这次新增支持的CXL,原本是Intel在力推的一种高速互联。Arm是在2019年加入CXL联盟的。CXL着力于解决不同处理器、设备之间的通讯和缓存一致性问题(比如CPU、GPU、FPGA加速卡各自的内存就是割裂的)。
藉由CXL,CPU和其他加速器之间可实现低延迟的缓存一致性(和相同的存储语义)。从Arm的PPT来看,多设备(包括CPU与加速器等)、池化内存资源之间的互联用CXL/PCIe;而CPU本身的多die(chiplet)与多socket之间则用CCIX;这是个相对更完整的方案——这些对于Arm的客户构建更多样化的弹性设计是相当有价值的。
快速发育中的市场
Neoverse V1/N2同时作为“平台”,不仅有核心IP方面的方案,另外也有面向系统的方案,如电源管理。Arm这次有更细粒度的电源管理机制(MPMM),对于核心内资源更合理的分配都更有价值;有像Cbusy这样的机制,可基于反馈的方式,进行CPU核心与mesh互联的交互,CPU基于整体mesh与系统存储的负载情况,灵活决策存储prefetcher的行为;N2有个名为PDP的管理机制,可基于负载做CPU微架构特性的调整,在不影响性能的前提下减少功耗……
总的来说,虽说Neoverse出现的时间还不久,基础设施市场的参与者反馈却已经相当积极了。如今不仅有亚马逊、Ampere Computing、Marvell这样的参与者,Chris Bergey分享了更多有关Neoverse的生态发展情况。
 亚马逊云Graviton2之上的各种工作负载
亚马逊云Graviton2之上的各种工作负载
“腾讯在硬件测试和软件支持方面持续投入,这将使他们能够采用Arm Neoverse技术。他们的硬件测试在性能方面展现了出色的结果。” Bergey说的是Arm服务器测试框架TencentBench。腾讯专项测试技术中心总监黄闻欣说,“我们通过TencentBench测试框架发现,得益于更多可扩展的CPU核心数,Arm服务器比传统的服务器性能表现更强劲。非常值得一提的是,其在AI推理和图片处理领域优势非常明显。”
阿里云方面,“他们测试了即将推出的Arm架构ECS实例,并在SPECjbb的测试数据中心获得了惊艳的结果。” Bergey表示,“Java对于阿里巴巴来说是很重要的工作负载”,“阿里巴巴和Arm在Java工作负载分析和调试方面持续合作。通过双方的紧密合作,我们看到DragonWell JDK的性能提高了50%。”目前用户和开发者已经可以在阿里云网站注册,获取Arm系列实例测试。
而针对这次最新发布的Neoverse V1/N2,“4月中,印度电子和信息技术部MeitY宣布,其百兆级高性能计算CPU设计将采用Neoverse V1平台”,此前另外两个宣布要采用Neoverse V1的参与者还包括法国芯片初创企业SiPearl和韩国电子通信研究所ETRI。
在HPC、5G、边缘等方面的更多进展,包括Oracle将Ampere Altra用于云基础设施、MarvellOCTEON DPU在5G方面的应用等,这里不再一一分享。随技术本身的这种发展趋势,Arm的确是搭上了这班变革热潮,这可能也是数据中心市场改朝换代的开端。旧有的市场竞争者,这会儿应该正感受着前所未有的压力。
责编:Luffy Liu
