
前年的GTC China报道中,我们总结过英伟达的业务构成和近10年的营收变化情况,发现这家公司2015-2019年的营收增长完全不像是一家发展了几十年的公司,倒像是个初创企业。当时我们提到,英伟达这种业绩水平的猛增,与AI的发展有着很大的关系。
英伟达FY2019,游戏业务占到了其营收构成的54%,其次就是数据中心(25%)。当时其数据中心业务的营收相比上一财年增长了52%,可见AI这一大趋势对英伟达的价值。
2020年疫情客观上促成了全球数据中心相关业务的又一波增长,从直觉上来看,英伟达应该更能从中获益。这一点也能从英伟达FY2021 Q4(截至2021年1月31日)的业务变化情况看出来。下图是近些年来英伟达不同业务营收的变化。其中最显著的就是数据中心业务在英伟达这家公司的营收占比果然有了显著增长。
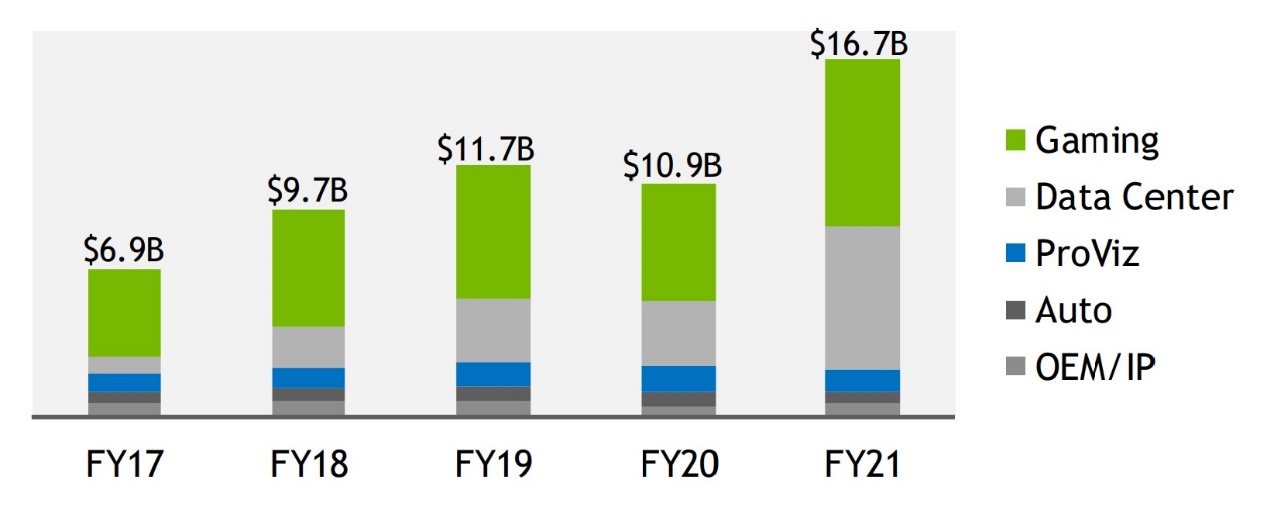 事实上,这一季度英伟达的数据中心业务营收达到了19.03亿美元,同比增长多达97%(当然其游戏业务也有67%的增长),占到整体营收的将近40%。英伟达数据中心业务的主要推力,来自于相关于AI训练与推理(inference)的云/超大规模计算客户与垂直领域(超算、金融服务、高等教育与消费互联网)。单是Mellanox就有30%的同比增长。
事实上,这一季度英伟达的数据中心业务营收达到了19.03亿美元,同比增长多达97%(当然其游戏业务也有67%的增长),占到整体营收的将近40%。英伟达数据中心业务的主要推力,来自于相关于AI训练与推理(inference)的云/超大规模计算客户与垂直领域(超算、金融服务、高等教育与消费互联网)。单是Mellanox就有30%的同比增长。
刚刚结束的GTC 2021,首日keynote英伟达CEO黄仁勋几乎将全部注意力都放在了AI和数据中心。今年GTC大部分人关注的可能是英伟达补全“缺失的最后一块拼图”:Grace CPU的发布,实则也只是是英伟达正在补全AI各方面能力的一部分。
为时一个半小时的keynote之上,高度抽象黄仁勋表达的意思应该是:(1)AI的硬件我们造,(2)AI的软件(模型、工具、中间件等)我们造,(3)还没有用上AI的行业我们也提前承包。这个总结当然有玩笑的成分,但英伟达对AI生态帝国的构建,几乎已经做到竞争对手难以望其项背的程度。

在看这篇文章之前,推荐阅读此前两篇相关英伟达的文章。这两篇文章对英伟达现下热门的一些概念,如BlueField、TensorRT、DOCA、Isaac等概念做了解释,将有助于理解本文的内容。比如BlueField DPU目前作为英伟达数据中心市场版图的重要组成部分,如何理解其价值——本文针对这些内容将不做赘述。
1.Arm在数据中心的价值:黄氏定律背后,英伟达打的什么算盘?
GTC 2021发布了什么?
按照常规,还是首先理一理今年黄仁勋在GTC的keynote主题演讲上,都发布了些什么:英伟达的此类发布会,宣布的产品和信息含量总是相当密集:
● 宣布推出DOCA 1.0(面向BlueField DPU的SDK,其中包括深度数据包检测、安全启动、TLS加密、基于硬件的实时时钟等);
● 宣布推出BlueField-3 DPU:预计2022年上市,400Gbps网络速率,220亿晶体管(上一代BlueField-2是70亿),处理能力为BlueField-2的10倍;(计划中的BlueField-4网络速率800Gbps,计算能力再提升10倍,2024年推向市场)
● 发布DGX Station 320G:4个A100 GPU,采用320GB HBM2e显存,8TB/s显存带宽,2.5 petaFLOPS算力,1500W功耗——被英伟达称作“每位AI研究人员的理想AI开发助手”;
● 更新DGX SuperPOD:80GB A100 GPU(总共90TB HBM2显存,2.2EB/s总带宽),应用了BlueField-2 DPU,提供Base Command(DGX管理和编排工具);
● 宣布推出cuQuantum,专为模拟量子电路设计的加速库,让研究人员设计更好的量子计算机,并验证其结果;
● 宣布推出数据中心CPU,代号Grace,2023年发布;基于Arm下一代Neoverse,专为加速大量数据的计算应用程序(如AI)构建。针对AI和数据科学的新计算架构,CPU与CPU、CPU与GPU都改用NVLINK连接,实现系统内存到GPU带宽30倍提升;
● 宣布瑞士国家超级计算中心打造全球最快的超级计算机Alps,20ExaFLOPS的AI性能,搭载Grace CPU,2023年上线;
● 宣布推出NVIDIA EGX for Enterprise平台,Nvidia AI可以通过VMware软件实现了,为VMware企业客户构建AI计算基础设施打造:“AI负载可分配给多个系统,并实现裸金属级别的性能”;
● 宣布推出Aerial A100,5G与AI融合的边缘计算卡,将安培GPU和BlueField DPU集成到一张卡上(提供20Gbps速率,处理9100MHz的MIMO,适配64T64R天线阵列);
● 宣布推出Nvidia Morpheus,用于实时全数据包检测的数据中心安全平台,基于Nvidia AI、BlueField、Net-Q网络遥测软件和EGX构建;
● 宣布推出TAO框架,可针对英伟达AI的预训练模型进行微调和适配;宣布推出Fleet Command,用于跨分布式计算集群的安全操作和AI编排;
● NVIDIA Jarvis对话式AI开放下载,可进行语音转文字、语言翻译、快速响应等,目前支持英语、日语、西班牙语、德语、法语和俄语;Jarvis可部署在云端,数据中心EGX,以及边缘;
● 宣布推出Merlin开源推荐系统框架,10-50倍的ETL加速、2-10倍训练加速、3-100倍推理加速;
● Maxine虚拟协作(virtual collaboration)技术演示,可在视频会议中针对低带宽改善视频质量,纠正眼睛注视位置;
● 宣布推出NVIDIA Triton推理服务器,支持各种AI模型、框架;
● 宣布Orin汽车中心计算机2022年投产,涉及的工作领域包括仪表盘、信息娱乐、乘客交互AI、信心视图(confidence view);
● 宣布推出Hyperion 8汽车平台,包括参考传感器、AV(Auto Vehicle)和中央计算机、3D真值、数据记录器、网络和各种软件,面向交通运输生态系统;
● 宣布推出DRIVE Atlan, 采用新的Arm CPU以及新款GPU与BlueField,作为Orin的迭代产品,预计2024年投产,单芯片1000TOPS性能(超过L5无人驾驶计算能力)。

这些发布基本上围绕AI,并将AI发散到各行各业,如汽车、医疗、数据中心、HPC、科研、信息安全等。发布的具体产品涵盖芯片、板卡、系统设备、软件工具、解决方案等。黄仁勋在会后的电话采访中针对发布中提到的AI for Enterprise说道:“我们将AI扩展到企业的边缘。我们相信企业产业边缘将会是AI产生巨大影响的地方,包括医疗健康、仓储物流、生产制造、零售、农业、交通。AI还没有触达这些行业,但现在不同了。”
通过英伟达的GPU、GPU,还有Aerial A100这样的选择,包括与15家计算机制造商、55个服务器系统,与VMware、Red Hat以及“整个IT行业”的合作,“我们要将Nvidia AI带到全球企业5G产业边缘。”这是能够表现英伟达对自家AI帝国的展望的。

AI生态养成指南
除了前面这些,黄仁勋的主题演讲中,还有一些发布内容,比如说与合作伙伴之间达成的合作。典型如韩国最大搜索引擎Naver开始采用DGX SuperPOD运行其AI平台CLOVA训练韩语语言模型;Recursion生物科技公司,采用DGX SuperPOD构建系统,用于生成、分析大量生物和化学数据集;还有如爱立信、富士通等合作伙伴基于Aerial库构建5G解决方案,谷歌云预计也将在云环境中支持Aerial(所谓的将5G拓展到云端)......
这些都属于硬件形式的合作了。而在这些之外,英伟达手中还握有不少AI预训练模型资源,除了前文提到的Jarvis模型,“我们拥有各种计算机视觉、语音、语言和机器人模型”。举例说,比如英伟达的基因组学和医学成像团队,通过X光片和电子病历预测补充供氧需求,据说这是来自多个国家地区应对COVID-19合作开发的成果。
打造各种模型及更为具体的AI应用,其实是英伟达始终在做的一件事。这也是延展AI生态、巩固公司在AI界地位的重要组成部分。今年英伟达针对Clara Discovery(用于药物研发的加速库套件)又发布了4款新模型,具体的这里就不再列举了,不参与其中的人其实也不大能够理解它们是做什么用的。

这里可以列举一些比较知名的模型,如游戏中的DLSS——深度学习超级采样、StyleGAN——AI高分辨率图像生成器、GANcraft——神经渲染引擎,典型如将《我的世界》中的游戏场景转为细腻的3D画面、BioMegatron——最大规模的生物医学语言模型、GANverse3D——将照片转换为可呈现动画效果的3D模型等。这些都属于英伟达内部AI研究的成果。AI开发者可以将这些预训练模型集成到自己的应用中。“还有许多其他模型在源源不断地推出。”
于此同时,配套的工具又显得尤为重要,比如这次发布的TAO,可对预训练模型进行调整和适配:用开发者自己的数据来对模型做调整。而且TAO也支持联邦学习系统——此前的文章中,我们已经解释过联邦学习,不同机构的研究人员、开发者可以协作开发一个AI模型,同时保持各机构数据分离。

另外TAO藉由TensorRT针对目标GPU系统优化模型。TensorRT又是英伟达AI生态中的重要组成部分了。作为极为重要的中间件:英伟达对此已经有了多次迭代。这是一种graph计算图优化编译器,输入部分是模型,以CUDA GPU生成优化过后的模型运行时(runtime)。微信,使用BERT这样的自然语言理解模型,藉由TensorRT就能达成8ms的延迟。
还有像是RAPIDS这样的数据科学库套件,Spotify就用RAPIDS来分析模型,为用户提供个性化播放列表等等。今年发布的cuQuantum,是用于模拟量子电路设计的加速库,算是一种以当代AI技术推动量子计算发展的工具,“构建混合量子-经典计算并发现更多量子优化算法,例如Shor算法和Grover算法。”
黄仁勋在主题演讲中说:“Nvidia创建了端到端机器学习所需的芯片、系统和库。例如Tensor Core GPU、NVLINK、DGX、cuDNN、RAPIDS、NCCL、GPU Direct、DOCA等众多技术,我们称该平台为Nvidia AI。”这句话在演讲中是一句带过的,“端到端”这个说法可是相当庞大的工程量。这些是在AI生态方面,令其他竞争对手几乎难以望其项背的根本所在,芯片实则只是其中的很小一部分。“NVIDIA是个全栈计算平台。”
谈谈英伟达的CPU:Project Grace
今年GTC最受关注的话题莫过于英伟达最新发布的代号为Grace的CPU了。我们在去年的《Arm在数据中心的价值:黄氏定律背后,英伟达打的什么算盘?》一文中曾提到过,英伟达凭借自身在数据中心的地位,将Arm带到数据中心圈子几乎是个必然。而且随着DPU这类产品形态的出现,英伟达可能正在尝试令数据中心的CPU地位愈发边缘化。
当时我们就提到,英伟达很有可能要推出自己的CPU。这次黄仁勋宣布CPU、GPU、DPU策略并进,其中CPU是“缺失的最后一块拼图”,好像完全不令人意外,虽说Grace的问世要等到2023年。很多媒体评论Grace,是英伟达全面取代x86处理器,彻底征服各大市场的开始——这一点可能是有待商榷的。
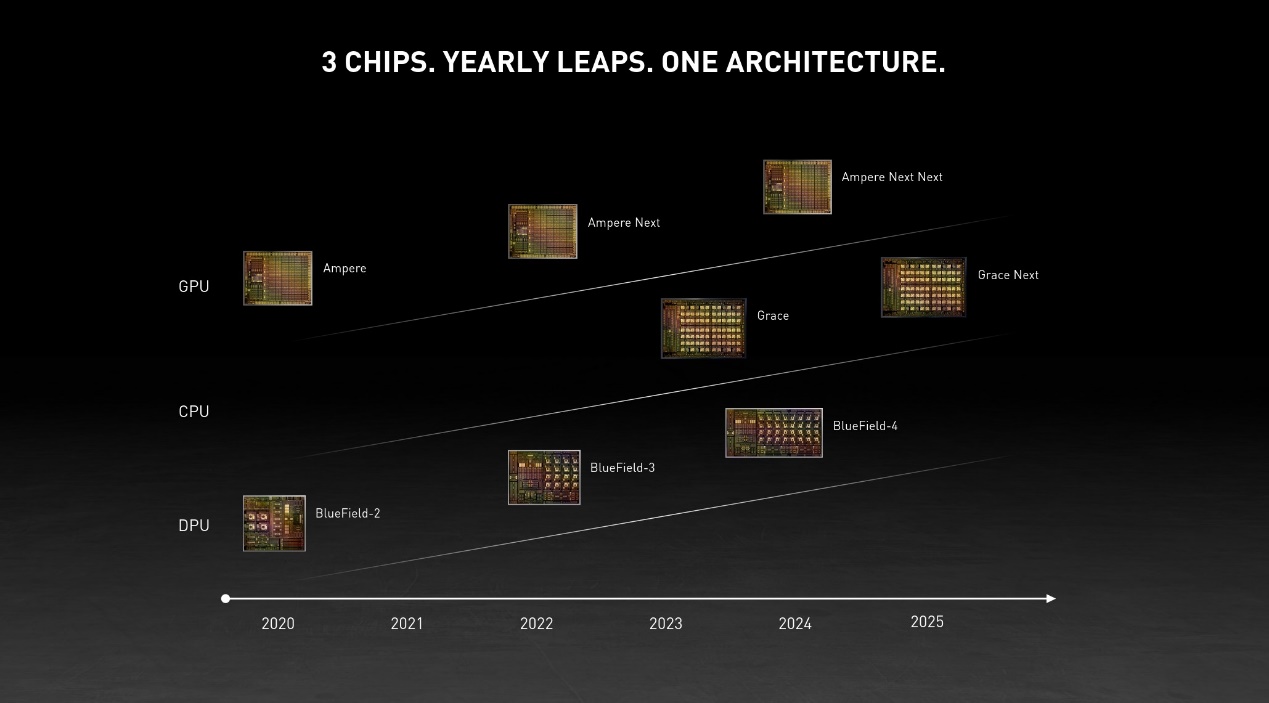
早在2011年,英伟达就曾推过Project Denver,当时也号称是英伟达设计的高性能Arm核心,面向HPC市场。很显然当时的机会还没成熟,如今的时代却不同了。《Arm的十年PC征程,和微软的“暧昧”》一文中提到,Arm过去1-2年在HPC市场是全面开花的,比如说亚马逊自研的Graviton2处理器采用Arm Neoverse N1架构。
英伟达目前针对Grace处理器透露的消息并不多,仅提及核心基于Arm Neoverse未来的迭代(N2?),有关核心数、频率等均是未知的,据说单颗CPU能够达到SPECint 300分以上(与二代Epyc类似?)——作为2023年的得分,不能说太占优势。

黄仁勋在主题演讲中提到,当前英伟达的安培架构GPU都连接80GB HBM2e显存,带宽可以达到2TB/s,4个GPU总共320GB显存,速度为8TB/s。而目前其x86平台的DGX,CPU配置内存容量1TB,速度0.2TB/s。CPU与GPU之间PCIe已经成为瓶颈。
推Grace同时的一个重要价值在于出现新的计算架构,英伟达将CPU与GPU之间的通讯改用自家的NVLINK。所以Grace成为与英伟达未来的GPU搭配的“高带宽”CPU。一颗GPU与一颗Grace CPU搭配,构成一块单板(应该还会直接包含LPDDR5x内存)——这种思路颇有CPU为GPU服务的意思,这在AI HPC应用方向上也是相当适用的。

英伟达给出的数据是,内存带宽至少500GB/s。国外媒体AnandTech提到,2023年英伟达开推NVLINK 4,Grace处理器与GPU之间上下行累计带宽至少900GB/s,Grace处理器之间也能超过600GB/s。数值高于内存带宽表明GPU与CPU之间有缓存一致性连接,以及整个系统可能有共享的存储地址空间。英伟达特别提到,在此架构下,GPU到主内存的带宽相比传统x86的计算架构,提升30倍。这对大型神经网络应当是具备了相当价值的。
看起来略有革x86处理器的命的意思。不过事实上Grace是一颗专门面向大规模神经网络负载的处理器,服务于其GPU芯片,处理大规模、海量参数的AI模型。黄仁勋在接受采访时说,Grace是专门面向大规模AI HPC的,原话是“It’s gonna be completely revolutionary for this particular use case.”这种架构限定在某个使用场景中的“革命”,如“处理海量数据”,像是Transformer和推荐系统之类的AI模型。它对大规模AI仍然会有相对长远的影响。

不过要说用于“取代x86”,恐怕并不科学。一方面,主题演讲中提到未来的架构更新,一年专注于Arm平台,而接下来一年仍将专注x86平台。在答记者问时,黄仁勋反复强调了Grace是针对特定场景的。“我们会持续支持x86 CPU,在很多领域x86还是很理想的,比如工作站、PC。”黄仁勋说,“而Grace是特定应用的。我觉得它不会多大程度影响到现有的客户。”
“说到CPU,我们的工作主要是专注于能够提供Nvidia AI、Nvidia加速计算平台,包括我们的GPU、DPU,以及任意CPU架构的基础设施。如果是Arm,那很好;如果是x86,也很好;如果是亚马逊Graviton,很不错;是面向云和科学计算的Ampere Computing,也很棒;或者是边缘的Marvell,亦或针对移动设备的联发科——我们期望以Nvidia AI去支持全球各种CPU。”

黄仁勋列举的这些CPU相关的合作,也是他在本次GTC主题演讲之上宣布的一些合作。包括与亚马逊云合作,实现Graviton2与英伟达GPU的结合;与Ampere Computing合作,让英伟达GPU可搭配Altra CPU;与Marvell合作,创建边缘与企业市场SDK与参考系统;与联发科合作,令英伟达GPU与联发科SoC结合,打造PC与笔记本电脑。
从这个意义来看,Grace暂时还不是承载英伟达一统天下野心的CPU,即便后续迭代产品可能会是。而且实际上,Grace更应看作是英伟达的反击之作,尤其在Intel、AMD都在推CPU、GPU及更多处理器融合的思路,连Intel都很快就要推出面向数据中心的GPU了,这种时候还是要更大程度地自主掌控生态才行。届时可能会有更复杂的竞争局面出现,即便就AI HPC来看,英伟达目前的计算架构,在数据传输吞吐上暂时有优势——这个优势可能也并不会维持太久。
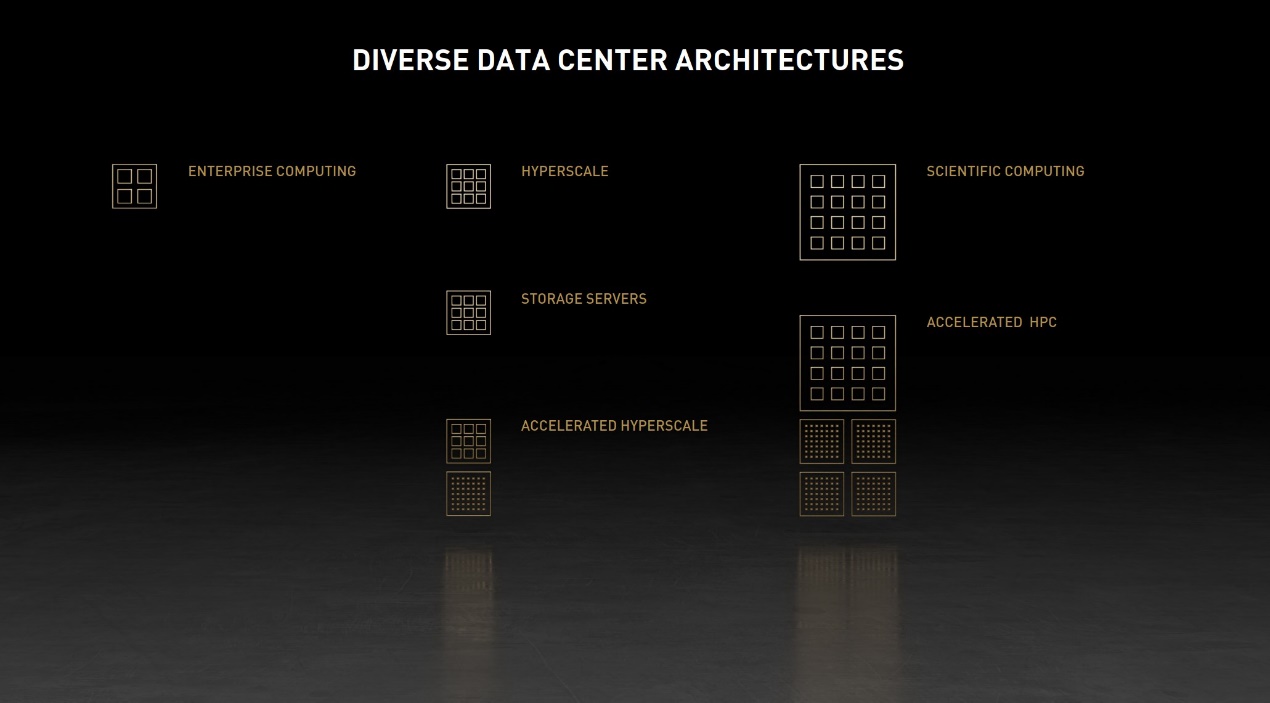 不同的数据中心架构,包括企业服务器、超大规模服务器、存储服务器、深度学习训练服务器、深度学习推理服务器;其中的方格大致表示这些应用场景对计算的需求
不同的数据中心架构,包括企业服务器、超大规模服务器、存储服务器、深度学习训练服务器、深度学习推理服务器;其中的方格大致表示这些应用场景对计算的需求
当图形计算与AI交汇
因为篇幅的关系,无法将本次GTC 2021之上发布的所有内容做一一探讨,比如Morpheus——可针对数据中心网络东西向流量做安全检测的方案(AI在信息安全中的应用);在自动驾驶领域,规划中的NVIDIA DRIVE Atlan结合了英伟达在AI、汽车、机器人、安全等方面的技术;针对Transformer模型的训练,英伟达推出了Megatron等等……
最后这部分谈一谈Omniverse,这是黄仁勋在主题演讲中花了将近半小时介绍的内容。Omniverse在前年的报道文章中,我们有提到过。这是用于创建、模拟虚拟世界的平台,在虚拟世界中的元素是遵循物理定律的(比如对液体、材料的模拟等)。Omniverse关乎专业视觉的设计协作、模拟,并且延展到了Digital Twin(数字孪生或数字复刻版)。
Omniverse前年似乎还局限在设计师和一些专业视觉领域,比如面向建筑或者动画行业,位于全球各地的设计师都能借助Omniverse进行3D制作流程的协作。光线追踪加入到其中,还能够实时渲染,比如ILM(工业光魔)就在测试Omniverse,让多个工作室内部和外部工具管线在Omniverse中聚集到一起,也算是相当炫酷的。
如今其价值还涉及到了digital twin或者针对现实世界模拟。比如爱立信针对5G波,就用Omniverse在一些存在大量多路径干扰的环境中,进行波的传播模拟;基础设施工程软件公司Bentley用Omniverse来创建基础设施的digital twin,在其平台之上,可在施工完毕后用3D模型在整个生命周期中监控和优化性能。

今年英伟达宣传Omniverse的重点,更偏向当它与AI结合之后的能力。比如说机器人可以在Omniverse模拟的虚拟世界中,学习各种技能,如搬箱子、拾取和放置物体等(与Isaac的结合)。藉由Omniverse创建一个虚拟工厂,训练和模拟机器人工人。而且这个虚拟世界中,运行的软件、AI与实体工厂完全一样。据说宝马现在就在应用这种digital twin技术,模拟了31家工厂。
另外,Omniverse与NVIDIA DRIVE结合,在Omniverse中模拟车队的信息,包括虚拟世界的高精度地图、场景仿真等,构建DRIVE和汽车的digital twin。所以英伟达也特别做了个DRIVE Sim数字孪生,预计今年夏季推出。英伟达现如今将Omniverse定位于“有助于机器人和自动驾驶汽车打造新一波AI浪潮”。
之所以将Omniverse放到最后,在我们看来,Omniverse是回归英伟达老本行计算机图形学——也是GPU最初工作的精华。如今GPU却开始从事各种各样的工作,尤其是AI。黄仁勋说:“计算机图形学的核心是模拟,使得数学和计算机科学模拟光线和材料的交互,模拟物体、粒子和波的物理特性,如今又在模拟智能和动画。在为实现大自然物理学而奋斗的事业中,我们开展了科学、工程和艺术工作,取得了非凡的进步。”
而Omniverse结合Nvidia AI之后,构成虚拟世界、创造digital twin,为现实世界贡献成果,应该算是英伟达这么多年来集大成的作品了。其发展也极有可能超出人们原本的预想。
责编:Amy Guan

