
简单谈谈十一代酷睿(选读)
本文选读部分再花点笔墨,简单谈谈移动平台十一代酷睿。十一代酷睿移动处理器的代号名为Tiger Lake。这代处理器主体上有三个关键词:10nm SuperFin制造工艺、CPU采用Willow Cove架构、GPU核显是Intel最新的Xe。其他组成部分还包括I/O支持PCIe 4.0、雷电4、LPDDR5,还有升级版的AI能力(Gaussian Neural Accelerator)等。
(1)10nm SuperFin工艺

Intel的10nm SuperFin工艺,仔细算起来应该是Intel的第三代10nm工艺了(也可能是第四代)。如果昙花一现的Cannon Lake不算的话,那么也已经是第二代。初代10nm工艺,此前我撰文详细介绍过;新一代的10nm SuperFin应该算是Intel 10nm工艺的真正成熟版。

一个重要的依据是,十代酷睿(Ice Lake)虽然IPC有着15%-20%的提升,意即同频性能相比再上一代酷睿(Whiskey Lake)有15%-20%的提升。但十代酷睿的频率(主频与睿频)却降了10%-20%,大约在4.2GHz左右,故IPC性能提升就被抵消了,虽然理论上会更省电。十代酷睿频率降低,很大程度上与当时的10nm尚不成熟有关。
Tiger Lake的CPU就再次回到了5.0GHz的水平,这表明10nm SuperFin起码应付高频率已经没问题了。不过其产能可能仍是问题,毕竟很快要发布的桌面版十一代酷睿Rocket Lake,仍会延续14nm工艺。有关10nm SuperFin的具体改进,我会在后续的文章中详细介绍。本文主要来谈谈Willow Cove架构和Xe核显。
(2)Willow Cove处理器核心
Willow Cove也就是目前十一代酷睿移动版处理器的CPU架构。Intel宣称,Willow Cove比上一代(Sunny Cove,十代酷睿)的性能提升了10%-20%。事实上,Willow Cove和Sunny Cove的微架构设计基本上差不多,包括分支预测器、解码、ROB、TLB、后端执行、load/store等。这两者的差异,除了10nm SuperFin工艺带来更高的频率(以及可能同频更省电),还包括:L2、L3 cache更大,以及CET(控制流强制技术)。
Willow Cove的最重要微架构变化,应该主要来自cache架构调整。其中Sunny Cove的L2 cache为包含式512KB 8-way,而Willow Cove的L2 cache变成了非包含式1.25MB 20-way。cache size的提升,是能够显著提升缓存命中率的。当然尺寸加大,也会增加访问时延。

包含式(inclusive)的意思,就是指L1 cache中的每一行内容,在L2 cache中都有相同的一份。而非包含式就是两级cache没有这种关系,不过也因此实现缓存一致性原则就需要有额外的晶体管实施,也就需要额外的芯片面积,并可能带来一定的功耗影响。
这一代CPU的L3 cache部分提升到了12MB,增大了50%;只不过关联性从16-way 8MB变成了12-way 12MB。L2、L3 cache的这种调整应该能够带来IPC的小幅提升,功耗、面积的提升则可能会因10nm SuperFin的工艺改进而填平。
除了Cache变化,Willow Cove的另一个加强就是CET(Control-Flow Enforcement Technology,控制流强制技术)。这属于处理器安全方面的调整,用于抵御返回、跳转式的恶意攻击,通过page追踪实现返回地址保护;还有Indirect Branch Tracking(间接分支追踪)来抵御错误的跳转/调用目标。
CPU外围还有一些变化,主要是存储子系统——如前文所述开始支持LPDDR5-5400。不过现有主流实施普遍都是DDR4-3200、LPDDR4X-4266,也就是内存带宽有提升。而且Tiger Lake整个芯片上开始采用双向的双ring互联,这对内存敏感型应用场景应该也是有价值的。
(3)Xe GPU核显
十代酷睿的Gen11核显相比Intel此前的处理器,在性能上实则已经有个显著飞越了。无奈市面上的竞争对手都越来越彪悍,所以十一代酷睿的Xe-LP架构核显更上了一层楼。如果不考虑系统设计中内存带宽的限制,Xe可以说是目前性能最强悍的核显(可能需要排除苹果M1)。Xe-LP同等电压下可以达到远高于上一代Gen11核显的频率,这和10nm SuperFin工艺当然也是分不开的。

有关Xe的详情,未来我也有计划独立撰文。Xe是Intel 2018年宣布的一种GPU架构产品,大方向包括3种不同的微架构,Xe-LP(集成和入门级独立GPU)、Xe-HP(狂热爱好者、数据中心)和Xe-HPC(HPC集群)。所以移动版十一代酷睿集成的就是Xe-LP GPU。
原本十代酷睿的Gen11核显包含了64个EU(执行单元)。每个EU有2组4-wide ALU,其中一组面向FP/INT,另一组针对FP/Extended Math型计算。Xe-LP架构中,每个EU现有10个ALU(8+2),其中8个ALU支持2xINT16和INT32数据类型运算,有个新的DP4a指令可加速INT8 inference工作。Tiger Lake的Xe-LP GPU总共有96个EU。
Xe-LP的每2个EU共享一个单线程的控制模块,可做合作任务的分派。16个EU构成一个所谓的subslice,根据性能需求,这些subslice可按需增加。与上一代的差别在于,每个subslice都有独立的L1数据和纹理cache,像素后端每2个subslice每周期跑8个像素。另外Xe-LP有独立的16MB L3 cache,连接到memory fabric的接口部分带宽翻倍。
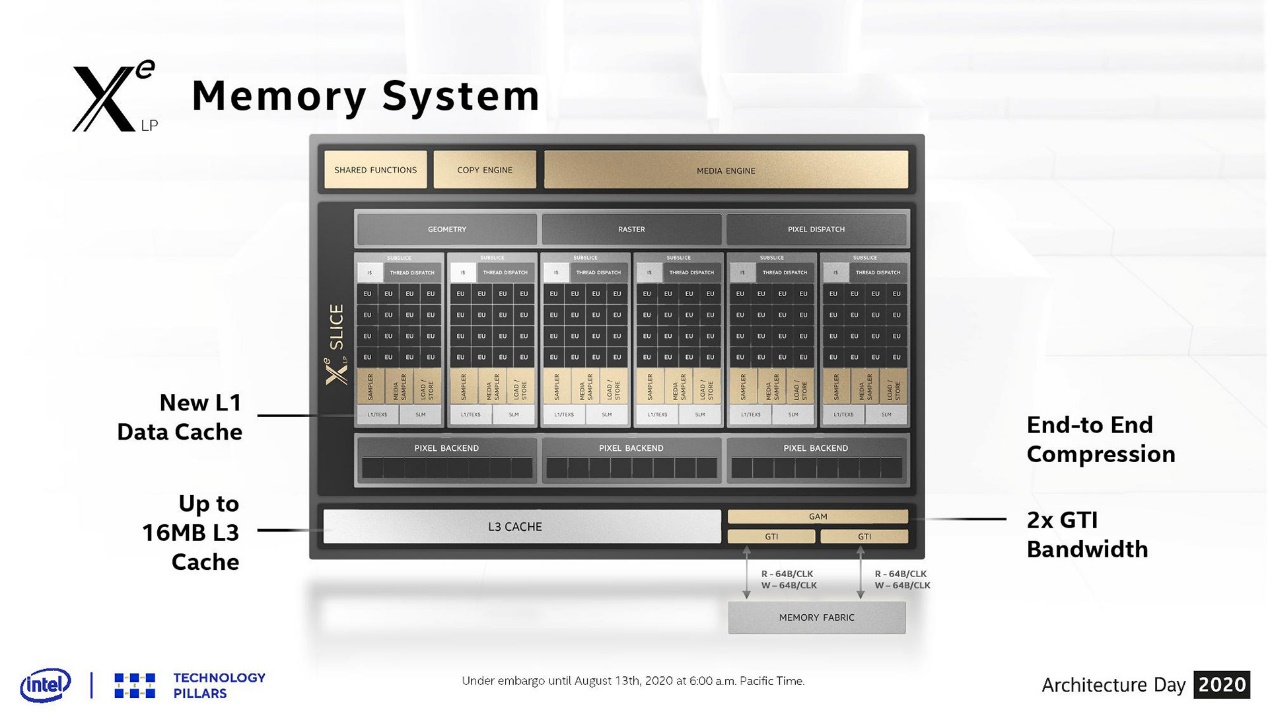
从实际情况来看,Tiger Lake之上的Xe算力表现靠谱,不过会较大程度受制于数据传输带宽。从现有十一代酷睿超级本的实际游戏体验,与跑分的差异能够看得出来——所以Xe应用于Tiger Lake感觉略有些匆忙。这个问题理论上会在十二代酷睿Alder Lake上得到解决(更高的内存频率)。
有关Xe核显另外值得一提的是,它开始正式支持AV1解码加速,其他一些流行的codec也有编解码带宽的翻倍,即硬解8K 60fps支持,“12bit端到端视频管线”。而在显示支持部分,Tiger Lake扩展至4条4K显示管线:Display Port 1.4、HDMI 2.0、雷电4、USB 4 Type-C四输出同时到位。
所以前文中提到Intel嘲讽M1在显示输出方面的表现局限。另外显示引擎也支持HDR10、12bit BT2020色彩、最高360Hz刷新率和自适应同步。
有关Intel的10nm SuperFin工艺,以及Xe核显更多技术方面的内容更新,可关注我的面包板。我会将这些内容更新在面包板博客上。
责编:Luffy Liu
- 产品论合格,不说好坏。合格有标准,好坏没有度。
- 产品论合格,不说好坏。
