
Intel这两年的日子真是相当不好过,也不只是和苹果在基带的事情上闹掰,和宣布放弃5G基带产品;而且在AMD于2017年推出Zen架构,终于彻底抛弃CMT以后,Intel居然在桌面处理器产品线上一时乱了阵脚。Jim Keller带领下Zen的猛然一击,竟然让近两年桌面处理器的性能获得了前些年从未有过的步进,Intel都让低压U用上四核了,这在摩尔定律逐渐停滞的当下还真是奇景。
不过在老江湖Intel面前,AMD前两代Zen和Zen+架构还是有偏科生迹象的,尤其是单核、浮点性能表现。而AMD在年初的CES大会预告Zen 2架构和Ryzen 3000系列CPU以后,AMD似有在桌面市场扭转乾坤的魄力。如果说Ryzen CPU的一代和二代产品表达的是AMD终于重返战场并开始侵蚀Intel在性能上的领导地位,那么Ryzen 3000系列是AMD在将近13年的时间里,第一次在桌面CPU市场达到(以及超过)Intel的高度。上一次是 Athlon 64。
外媒评价说:“这是AMD的高光时刻,也是CPU行业令人兴奋的一刻。”那么我们就来详细聊聊,AMD的Zen 2架构究竟如何或者是否真的达到了这个高度。

纸面数据很好看
Zen 2相比一代Zen,就AMD的纸面数据来看变化还是比较大的。而且AMD也不像Intel那样采用tick-tock更新节奏,Zen 2就不光是从GlobalFoundries的12nm转到台积电的7nm,而且也不只是微架构的小调整。加上AMD宣称同配产品表现可与Intel一较高下,Zen 2是值得花笔墨来多谈一番的。要了解Zen 2实际性能表现,请直接拉到本文的最后部分。
Zen 2架构主要应用于AMD Ryzen 3000系列也就是Ryzen的第三代消费级CPU产品(代号Matisse),以及EPYC企业级处理器Rome之上。目前,AMD明确发布的Zen 2架构产品有6款,从最高级别16核心的Ryzen 9 3950X(3950X需要等到9月才会正式上市),到6核心的Ryzen 5 3600。不同的SKU在核心数、频率、缓存和TDP等方面自然有着比较大的差别。

Ryzen 3000处理器每四个核心组成一个簇(CCX),每个CCX内部还包含了容量翻番的L3 cache(每个CCX 16MB L3 cache,总共32/64MB)。每个CPU有个中央I/O die单元。这里的中央I/O单元是所有off-chip的通讯中心,配备有PCIe通道、内存通道,并通过Infinity Fabric来连接其他die或者其他CPU。值得一提的是,Ryzen 3000的中央I/O die是基于GlobalFoundries的12nm制程。

Zen 2的一个CCX,来源:AMD
Ryzen 3000实际上并非单die芯片,而可能包含了不一致的多个chiplet。这还是AMD第一次在消费级产品中采用这种设计。比如12个核心的Ryzen 3900X,会分成两个chiplet(或称双die);而6核心与8核心的CPU则是单个chiplet(单die)。不同的chiplet之间通过中央I/O单元来通讯——也就是说单CCX内部四核通讯是可以保证高速的,跨越chiplet访问可能会有略高的延迟。EPYC企业级Rome处理器支持八个chiplet,也就是最多64个核心,中央I/O die支持连接八个内存通道,至多128个PCIe 4.0连接通道。
I/O die支持24 PCIe 4.0通道,和双通道内存——AMD宣称内存控制器是全新设计的,可以支持到DDR4-4200的程度。不过实际上在超过DDR4-3600时,内存频率与Infinity Fabric时钟比会从1:1变为2:1,Infinity Fabric频率减半。鉴于新架构将Infinity Fabric的总线宽度扩展到了512bit,内存到CPU核心的带宽可能仍然不会构成瓶颈,但整体的内存延迟应该是会增加的,后面的测试也可以反映这一点。
当前最高规格的3900X相比上一代旗舰2700X在核心数目和频率方面都有提升,但TDP仍然维持在了105W,单就这个数据看来,台积电的7nm还是相当给力的。
从架构和7nm工艺说起
一般我们习惯把“架构”和“微架构”这两个词混用。但在某些场景下,架构特指CPU指令集。这一次AMD为Zen 2引入了新的指令。主体包括CLWB、WBNOINVD和QOS。
早前在Intel的处理器上就有过CLWB这样的设计。这个指令支持程序将数据推往非易失性存储,以防发生停机命令和数据丢失等状况。相关CLWB实际还有其他配套的指令,这些指令想必对EPYC企业级处理器是有价值的。
WBNOINVD基于WBINVD,该指令用于预测cache的某一部分何时会用到,提前做好准备以加速未来计算。一般情况下,处理器发现cache未就绪时,会使用flush指令冲刷cache line,这就增加了延迟。所以提前执行这个操作,能加速最终的执行。
QoS又是个主要应用于企业场景的指令,是相关缓存与内存优先级的。比如某个云的CPU切分成不同container或者VM。如果有VM占据所有的CPU核心到内存带宽,或者L3 cache,那么其他VM很难获得相应资源,产生延迟;对占据资源的VM本身来说,也可能发生资源中断。解决方法就是hypervisor可以控制每个VM可访问的内存带宽和cache量,进行相对智能的限制和资源优先级控制。Intel Xeon Scalable处理器是有类似特性的,只不过AMD这回把它下放到了消费级产品中。

每个CCX包含四个核心+L3 cache,每8个核心组成一个chiplet,下方的cIOD即为负责通讯的中央I/O die;来源:AMD
而在工艺部分,AMD让我们有机会了解7nm是如何改变其设计,应对封装挑战的。Zen 2每个chiplet是74mm²——上一代Zen+每个CCX就占地60mm²。其中核心+L3 cache(16MB)占据了一个chiplet大约31.3mm²的面积。如前文所述,由于整个处理器上有个单独的中央I/O die,Zen 2也就不需要像上代那样为每个die添加内存控制器和单独的I/O,所以核心所在die的尺寸也就相对比较小,这大概也是 L3 cache得以做大的原因之一。

来源:AMD
另外由于7nm工艺 ,封装的bump间距(焊接凸点间的距离)从150微米缩减到了130微米。为了达到更紧密的bump间距,AMD采用了铜柱焊接凸点技术(copper pillar)。这里铜需要外延沉积在mask掩膜内,来构建回流焊的支撑。又由于铜柱直径的关系,所需的焊接掩膜更少,焊接位置的半径就更小。
值得一提的是,前文我们说到,CPU上的中央I/O die采用的仍然是GlobalFoundries的12nm工艺,所以用的仍然是常规焊接掩膜,AMD表示未来预计整个CPU都会采用7nm设计,也就是全部采用这种铜柱实施方案。

就连接布局来看,封装的衬底层数量增加到了12,用以处理更多的路径连接。从AMD提供的图片不难看出,下半部分就是传说中的中央I/O die,通过Infinity Fabric连接到上方的CCX。
重头戏:微架构变化
Zen 2毕竟还是Zen微架构的一员,其大体框架并没有变。不过微架构有几个地方的改动,是尤为值得一提的,这些改动可能正是Zen 2获得IPC提升的关键。其一是L2加了一个新的分支预测器,叫TAGE预测器;L1-I cache容量减半,但op cache大增;其二在浮点运算单元获得256bit位宽,开始真正完整支持AVX2指令。
从前端说起,L1 cache较大变化在于,cache尺寸从64KiB缩减到32KiB,不过关联性由上一代的4路组相连改为8路组相连,一来一去的具体成效未知,尤其对cache命中率是个未知数。但L1尺寸的缩减,换来了op cache的尺寸翻倍(2K entry->4K entry)。L1 cache和op cache是紧邻的——这可能是AMD在设计微架构时的某种权衡之策。AMD宣称在更多场景下,测试发现这样的成效更大。
这部分AMD宣传的重头戏还在分支预测单元TAGE上。分支预测单元是在出现if then条件分支时,去“猜测”指令流的路径,而不是空等着计算结果明了以后再去执行。当分支出现时,会存储到BTB(分支目标buffer)中,后续分支就可以决策了。现在的处理器不光会存储上一个分支的历史,还会在GHR(全局历史寄存器)中存储前几个分支,以期了解分支间的关联性。
Zen架构的BTB是三层结构,Zen 2在这个结构的基础上,有了规模更大的BTB来追踪指令分支和缓存请求。L1 BTB从256 entry(条目)加大到512 entry;L2的部分也几乎翻了一番到7K entry;L0 BTB仍然是16 entry,但间接分支目标阵列(Indirect target array)扩展到1K entry。
这部分提升还需要搭配分支预测单元。Zen原本采用的分支预测器基于所谓“hashed”感知器,宣传中就叫神经网络预测器,是一种简单的机器学习方案,比gshare这样的机制要准确。不过以Zen架构的流水线长度和宽度,出现错误预测的情况是比较要命的。Zen 2也保留了这种基于感知的预测器,但在此基础上增加了TAGE预测器。不过这并不是个新东西,最早是2006年就有人提出来的。

TAGE分支预测器,来源:WikiChip
TAGE基于这样一个原则:程序中不同的分支需要不同的历史信息长度。对于某些分支而言,历史越少,实际表现才会更好。TAGE实际就是标记等比历史长度预测器(Tagged Geometric),包含多个全局历史信息表——不同长度的GHR寄存器用以存储。这些寄存器的不同长度,组成一个等比数列(所谓的geometric几何级数),这就是TAGE缩写的由来。TAGE预测器的主旨在于搞清楚何种量级的分支历史信息对哪个分支而言最佳,最长的历史优先,较短的次之。
这样一来Zen 2的预测器就变成了两级结构,一级就是感知预测器,用于快速查询(比如单周期解决的);第二级为TAGE预测器,它需要更多的周期来完成。AMD宣称上面这些机制加起来,错误预测率能够低30%。以当代处理器的预测准确率,这个程度的提升对IPC提升应该是非常有好处的。以往AMD的分支预测器技术相比Intel一直都是比较糟糕的,这次AMD大肆宣传TAGE,或许这方面的差距正在或者已经弥合。
Zen 2前端另一个比较大的提升就是加大的op cache(和减少的L1 cache)。指令解码时,就会存储到 op cache 中。Zen上一代op cache容量是2048 entry(8-way, 32-set),Zen 2则翻倍到了可容纳4096 个MOP(macro-operation,需要注意的是宣传材料中AMD官方已经不再区分x86指令、MOP宏指令和μop微指令,本文统一采用了wikichip的定义方法)。要知道Intel下一代Ice Lake也不过是2K entry。开启超线程的话,每条线程用一半的量。也就是说Zen 2之上每个线程有效性相当于Zen上一代整个op cache的程度。
在op cache模式下(对应于指令cache模式),前端其余部分为时钟门控。Op cache增大让更长的指令流处在op cache模式下,加强IPC吞吐的同时也能起到节能的作用。值得一提的是,在这一模式下,每周期发往后端8条MOP,但Zen 2的reorder buffer(重排序buffer,ROB/RCU)每个周期仍然只能处理至多6条MOP,所以op cache的吞吐也就局限在确保op队列的效率了。这一点可能是不大平衡的。
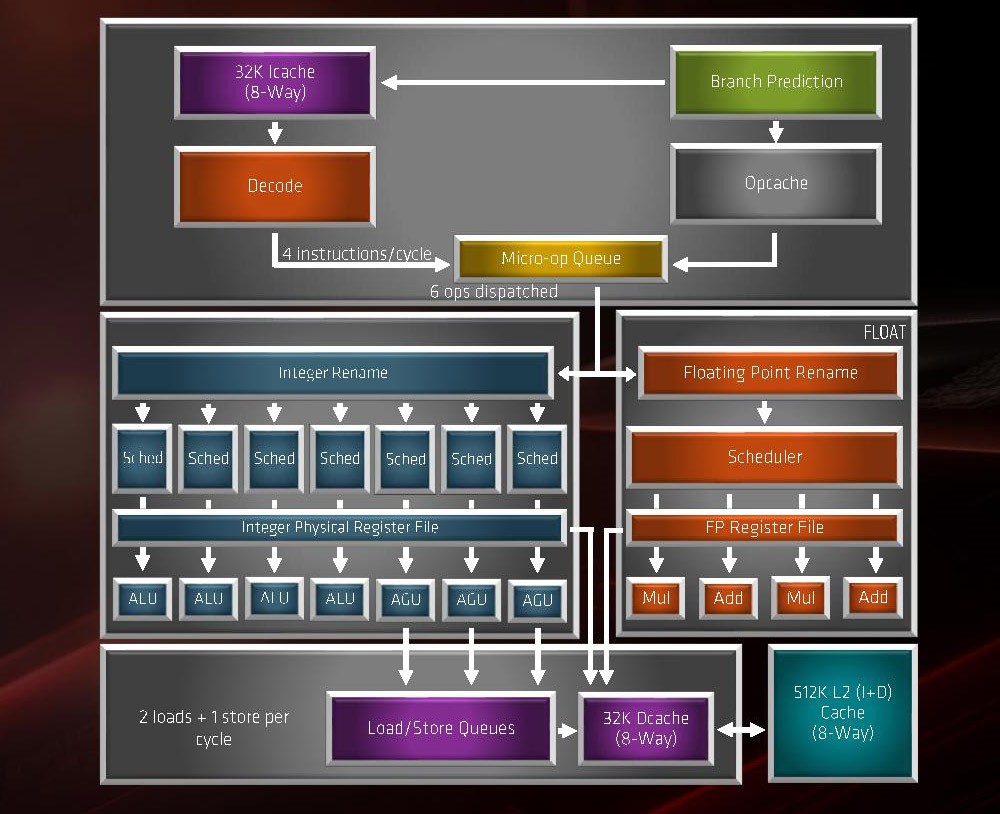
Zen 2微架构,来源:ARM
往后端走,dispatch分发就发往整数或者浮点运算单元了。Zen和Zen 2都有三种指令类型:FastPath Single、FastPath Double和VectorPath。FastPath表示指令中包含一条MOP,FastPath Double则表示一条指令包含两条MOP,VectorPath为超过两条MOP。在reorder buffer操作之后,MOP就分解成了真正的μop微指令,并抵达scheduler调度器。
浮点运算部分的亮点在于对AVX2(256bit AVX)和FMA的完整支持,执行单元宽度扩展到256bit,也包括了 256bit load/store,AVX2计算执行理论上只需要一个周期。以前的操作是256bit指令前端解码为FastPath Double类型,产生两个MOP,每个MOP再分解成两个μop;Zen 2则只需要把此类指令解码成FastPath Single即可。
有两个不大重要的点可以提一提。Zen 2浮点部分的两个FMA单元都是256bit位宽,每个Zen 2核心的总FLOP都达到了双精度16 FLOPs/周期,达到了Intel主流服务器处理器的水平,和Cascade Lake的32 FLOPs/周期有距离;另外Zen 2仍无法完整支持AVX512,可能Zen 2处理AVX512的方法和以前Zen/Zen+处理AVX2的方法一样。
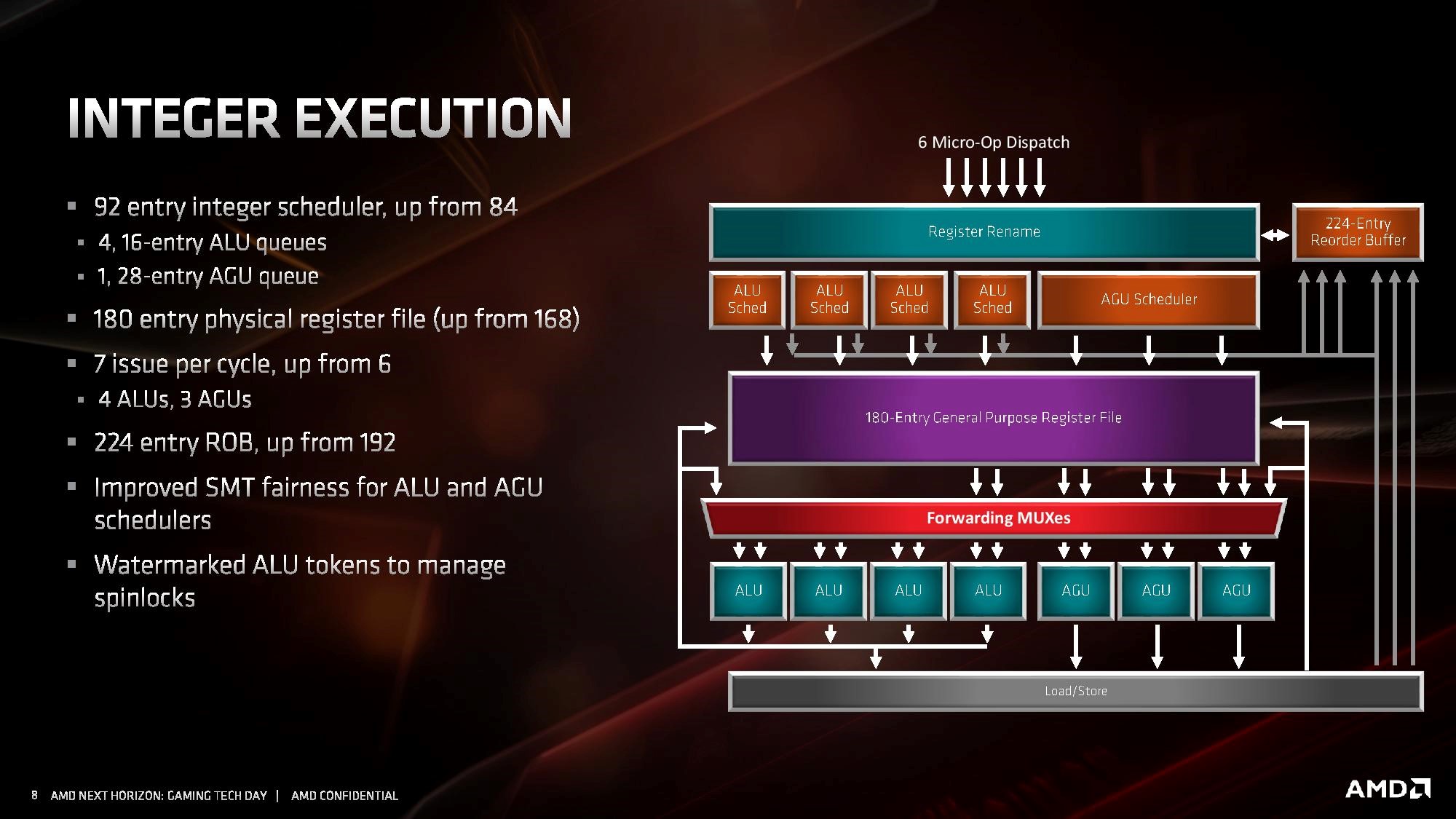
Zen 2整数后端,来源:AMD
整数运算部分支持接收至多每周期6个MOP,再分解成相应μop。类似加法这样的FastPath Single指令会分解为两个μop,即load与add。这部分的μop总体就是ALU和load/store。然后μop发往相应的scheduler。Zen 2的ALU scheduler还是4个,不过深度变深了一点,理论上或许可以在并行能力方面略有提高。
Load/store操作的 AGU scheduler从先前的2个14-entry变成了 1个28-entry; AGU执行单元倒是多加了一个,变成了3个——多加的这个单元专门用于store操作。AGU最终关联的load/store单元支持每周期256bit两次读和一次写操作。存储带宽提升当然也是为了配合浮点运算单元。尾巴还有个L1-D数据缓存 ,也是32KB 8-way,load/store带宽增加到32字节/周期。
谈到L1-D了 ,最后再返回到核心部分的存储子系统, L2缓存512KB 8-way,L2数据TLB(translation lookaside buffer,地址转换buffer)变大到2048 entry(上一代是1536 entry),还有新的1G page支持,AMD宣称L2 TLB访问可缩减周期。不过L3容量似已超出L2 TLB可容纳的范围,超过8MB以后访问延迟会表现出page walk。
实际性能与功耗:IPC有15%提升?
在今年6月的Computex展上,AMD宣布Zen 2核心相较上代产品IPC性能表现提升15%,相同功耗下性能提升25%,相同性能下功耗至多降低一半。今年年初的CES展会上,AMD展示了Cinebench的跑分成绩——这项测试偏重浮点运算能力,以及cache性能表现。当时AMD展示某个8核Zen 2处理器,相比Intel的i9-9900K获得了差不多的性能成绩,但AMD的功耗少了1/3。下面这张图则是AMD在Computex大会上公开的Cinebench单线程和多线程跑分成绩。

来源:ARM
实际性能表现,这里主要借用AnandTech的测试数据。鉴于篇幅关系,这里主要呈现Zen 2部分具有代表性的 测试成绩。我们来看看,Zen 2究竟有没有AMD宣传的那么神奇。

3900X与9900K存储延迟测试,来源:AnandTech
就Zen 2的存储子系统表现,Zen 2核心在测试中的内存延迟表现方面略有倒退,3900X相比2700X的DRAM延迟多了大约10ns上下,达到75ns左右,这和Intel同配不到40ns的水平还是有差距的(测试内存为DDR4-3200CL16 16-18-18-36)。3900X的L3 cache延迟从上一代产品的7.5ns左右降至如今的8.1ns左右,与Intel基本相当。而倒退可能是多方面原因促成的,比如说更大的L3 cache容量带来的妥协。
值得一提的是,这里AnandTech只选择了高配的12核3900X做测试,如前文所述这是个双die处理器;而相对低配的3800X及更低配置CPU都为单die。从已知的一些测试来看,Zen 2单die产品的内存写入带宽仅为理论值的一半,会影响到需要大量回写数据的任务负载表现。加上即便是双die产品,在内存频率高于3600MHz时,对高频内存的支持也并不好,这一点是值得考虑的。
到存储带宽部分,如前文所述Zen 2有了256bit位宽数据通路,AVX2指令执行能力比上一代是翻番的——这种变化在L1 cache部分很明显,对L2/L3则约有20%提升。就L3 cache带宽来看,AMD相比Intel是有60%的优势的。但在DRAM部分,内存控制器的效率方面,AMD却是落后的,最终3900X拷贝带宽部分提升到21GB/s仍略弱于9900K的22.9GB/s;写入带宽3900X是14.5GB/s,9900K则为18GB/s。不过在MLP(memory level parrallelism)存储级别并行表现上,Zen 2却又表现极为神勇,L3 cache和DRAM部分的速度都很快。
所以从存储子系统的综合表现来看,虽然Zen 2的存储延迟表现有退步,但核心prefetecher、L3 cache容量,还有MLP(内存级并行,考察cache miss时的表现)访问能力的提升都相当不错,另外内存控制器的情况相对复杂。改进与妥协一来一去,到实际应用环境里相比Intel大概也不会表现出弱势。

SPEC2017总成绩与每GHz性能,来源:AnandTech
接下来看SPEC2006的绝对性能成绩,无论整数还是浮点运算性能,就SPEC2006的测试,3900X都有25%的绝对性能提升,换算到IPC,提升约为17%,还是高于AMD官方宣传的15%的。
SPEC2017的情况基本类似的,3900X和Intel的9900K在诸多细分测试项能够打得有来有回——就IPC也就是每GHz的表现来看,相比上一代提升约15%,也强于9900K。这里需要补充的是,测试环境搭建对成绩影响较大,比如选择基于Windows的Linux子系统(WSL)来跑测试套件,LLVM编译器选择等等。有兴趣的可参见文末参考链接来具体了解AnandTech的测试环境。
下面有选择性地看看更偏上层的测试成绩,原本我们应该选综合系统性能测试的——这对日常各类使用更有参考性。但AnandTech的测试这回基本都是单项偏科的,所以我们也只能挑出一些具有代表性的测试项 。

Cinebench R15单线程与多线程测试成绩,来源:AnandTech
渲染测试中比较有代表性的就是Cinebench R15,毕竟AMD自己在宣传中也是用它。这个测试对于反映单线程性能是比较有说服力的,更高的IPC和频率通常能够在单线程测试中得到好成绩,这是Intel的优势;而更多的核心对多线程性能表现有利,这是这一代Ryzen 3000系列的优势。

WinRAR解压与AES编解码测试,来源:AnandTech
解码测试来看WinRAR 5.60b3解压表现,这项测试的具体内容为解压30个60秒视频文件+2000个小型web文件,多次测试并统计所需平均时间。WinRAR负载线程比较多变,而且也受cache影响。另一个选择的测试是AES加密,这里用的是TrueCrypt,在内存中测试多种加密算法;成绩包含了AES加密、解密性能,单位是GB每秒。
游戏表现就大致略过了。游戏测试就 CPU而言在绝大部分情况下都是Intel主场,9900K/9700K基本技高一筹,除了像《异域奇兵》这样的游戏——AMD早前就说《异域奇兵》是其Vulkan API实现的一个具体表现,为AMD的多显卡配置提供了弹性选择。

3900X的功耗表,来源:AnandTech
最后的看点是功耗,毕竟7nm是Zen 2的一个亮点。Ryzen 3700X的TDP 65W,上一代Ryzen 2700X的TDP 105W。要知道3700X核心/线程数与2700X一致,而频率还高了100MHz,最终结果是绝对能耗前者比后者低了32%。如果换算成每瓦性能,那么3700X可谓比2700X有巨大提升。其实际总功耗基本控制在了88W上下。
3900X的部分就比较有趣了,实际从AMD官方宣布3800X/3700X的性能提升幅度,及功耗增加的不对等就不难发现,3800X的频率已经越过了功耗临界点,那么3900X自然也就不例外了。测试成绩可知3900X的每核峰值功耗,实际是明显高于3700X的(还需要考虑到3900X多了一个die)。但即便如此,也还是比2700X优秀。

在满载的情况下,3900X的核心功耗达到118W,总功耗大约是142W的程度。如果对比满载情况下的总功耗水平,Intel都是明显落于下风的。AMD Ryzen 3700X功耗全面领先Intel大约60%;而3900X,考虑一下它的核心数还多于9900K。

有关Zen 2架构的介绍,文章花了这么多笔墨实际依然没有讲完,比如说AMD还特别跟微软进行了合作,就Zen 2这种非常规核心结构,共同优化线程和内存分配:当一个处理器有几簇核心时,线程分配会有不同的方式,AMD这次选择了thread grouping技术,新线程会直接分配到已有线程核心的临近核心,某个CCX线程填满以后,才会访问其他CCX——这种方案线程靠得更近,便于线程间通讯,但可能造成局部高功耗,且可能出现仅有一部分核心或chiplet活跃的状态。但AMD认为这种方案相比thread expansion还是值得的,后者核心离得较远,这对Zen 2而言,线程在不同chiplet或CCX间通讯,效率的确应该是不高的。
此外,Zen 2还有像是类似于Intel Speed Shift这样的特性(叫Clock Selection),细粒度进行频率调整,步进25MHz,和从空闲到加载状态更快的频率跳变;以及加强的安全性等等。
总体来看,Zen 2在设计上还是有颇多亮点的,包括TAGE预测器、增加的op cache,256bit AVX2指令的完整支持;虽然Zen 2的DRAM内存延迟变大,却因为整体的架构设计,而没有在存储相关测试中表现出太大落后;性能在各项测试中与Intel互有胜负之余,功耗还表现出了巨大优势。可能从2005年Athlon 64退役以后,AMD都还没有拿到过这样的成绩。
不过Intel仍然在某些领域表现出了优势,比如可以拿下更高的频率、单线程性能,存储敏感负载测试等,游戏表现也略胜一筹,但仅有的优势项实际差别也不大。Intel的攻势还在下一波,今年5月份Intel就宣布10nm Ice Lake在IPC方面将获得18%的提升。难得见桌面处理器市场在这样一个时间段掀起新一波的良性竞争,显然这已经不是Intel一家独大的市场了,况且Zen架构近期听闻都已经规划到Zen 5了。
参考来源:
The “Zen” Core Architecture – AMD(https://www.amd.com/en/technologies/zen-core)
AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome - AnandTech(https://www.anandtech.com/show/14525/amd-zen-2-microarchitecture-analysis-ryzen-3000-and-epyc-rome)
A Look At The AMD Zen 2 Core - WikiChip Fuse(https://fuse.wikichip.org/news/2458/a-look-at-the-amd-zen-2-core/2/)
The AMD 3rd Gen Ryzen Deep Dive Review: 3700X and 3900X Raising The Bar - AnandTech(https://www.anandtech.com/show/14605/the-and-ryzen-3700x-3900x-review-raising-the-bar/20)
博弈的艺术 AMD RYZEN 7 锐龙处理器深度测试 - Evolife(https://www.evolife.cn/computer/54351.html)
Translation lookaside buffer - Wikipedia(https://en.wikipedia.org/wiki/Translation_lookaside_buffer)
Intel’s 10nm Ice Lake CPUs Achieves 18% IPC Improvement Over Skylake - WCCFtech(https://wccftech.com/intel-10nm-ice-lake-18-pc-ipc/)
- 写得很清楚啊,是你阅读能力不行吧。说真的像这种翻译类文章能做到这样很不错了
- 农厂想翻身,还是可以的,不过还是要经过大哥 Intel 的准许,偶尔翻一下身估计还是可以,长久不是不行的。苟且活着该是农厂的 Old normal 和 New normal 以及 normal
- 抛开性能和功耗不说单从主板测试验证的来看,AMD比INTEL差很多,验证不严谨,BUG想到比较多
- 写的太差了,词不达意,好好学学语文再出来写东西吧
- 爬上去

