
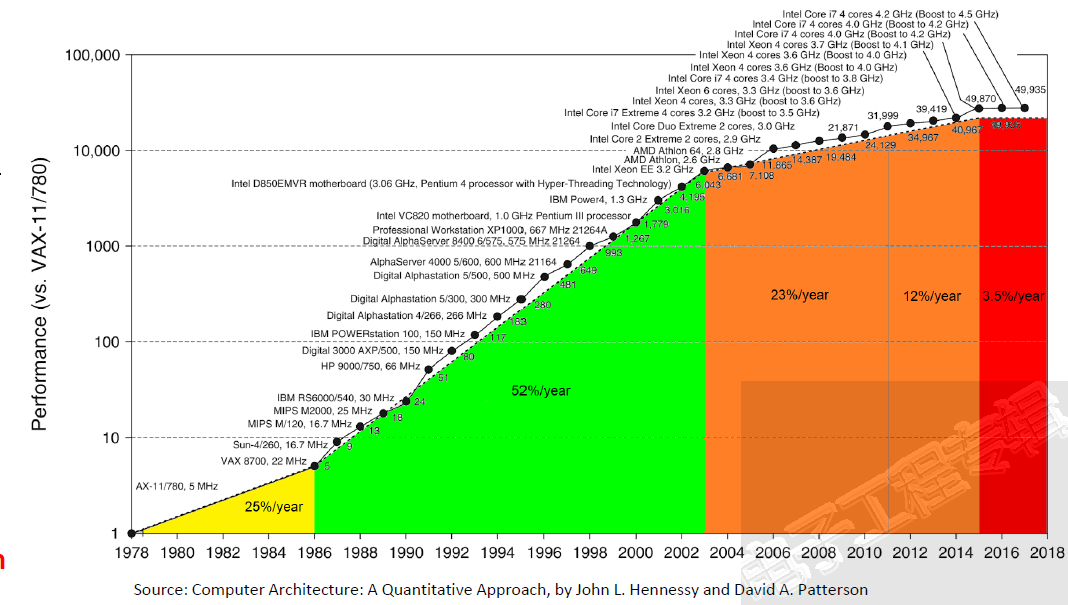
随着人工智能(AI)、机器学习和5G等要求快计算、高带宽和低延迟技术的迅速发展,以及摩尔定律进程的减缓,半导体产业正向新的计算架构演进。如果说1986年到2003年间,是摩尔定律的黄金时期,那么2003年到2015年间就是业界拼处理器核心数的时代,然而当大家发现增加核数也不再能提高处理效能时,专用型集成电路——比如ASIC和FPGA开始以效率和能耗的优势成为主角。
(图自:Achronix,下同)
“目前能提升能耗比和算力的唯一途径,就是专用化。”Achronix市场营销副总裁Steve Mensor说到,“未来的微处理器都会包含多个专用功能域核心,专职处理某一类型的计算任务,但他们的表现绝对好于现在各种处理器采用的通用核心。”
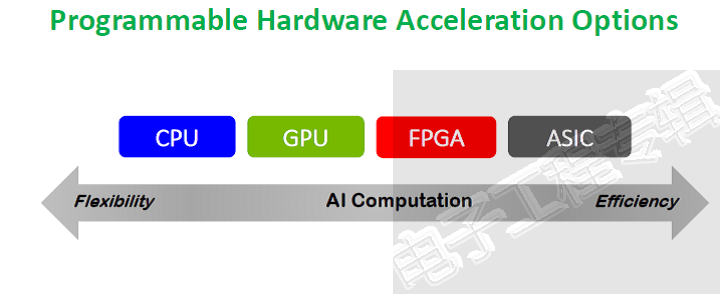
拿当前最火热的AI和机器学习应用来说,常见的计算平台有四种——CPU、GPU、FPGA和ASIC。他们各有特点和优势,目前采用最多的还是兼顾灵活性和能效的GPU和FPGA,但在价格和可塑性上FPGA更有优势。

Achronix市场营销副总裁Steve Mensor
Achronix日前正式推出其第四代嵌入式FPGA产品Speedcore™Gen4 eFPGA IP,以支持客户将FPGA功能集成到他们的SoC之中,该eFPGA独立器件也将在明年上半年量产,采用台积电(TSMC)最新7nm工艺。据悉,他们也是是第一家向SoC开发公司提供量产eFPGA IP的公司。
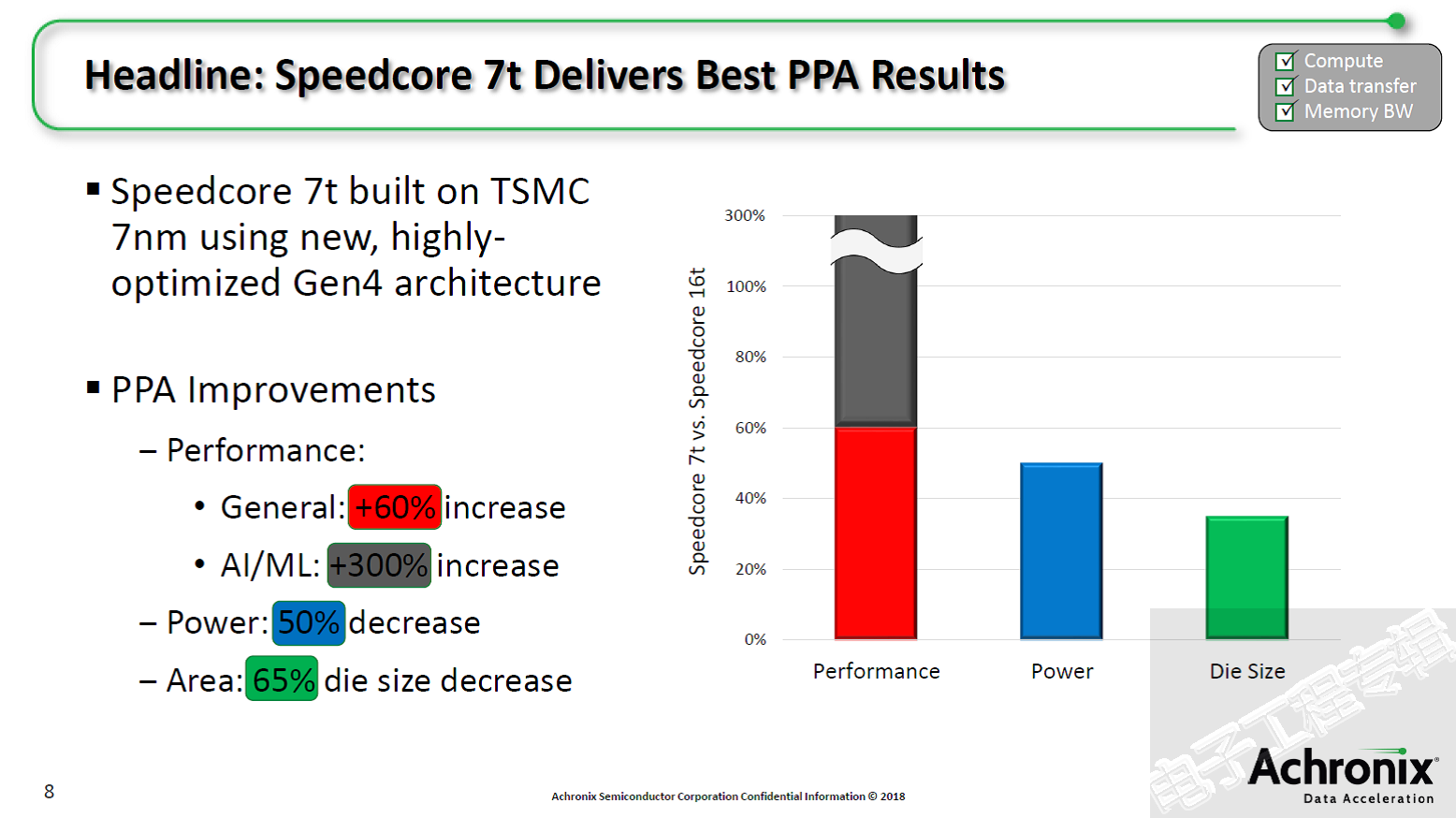
Speedcore Gen4将性能提高了60%、功耗降低了50%、芯片面积减少65%,同时保留了原有的Speedcore eFPGA IP的功能,即可将可编程硬件加速功能引入广泛的计算、网络和存储应用,实现接口协议桥接/转换、算法加速和数据包处理,提供了以前仅在ASIC中才能实现的硬件加速平衡。
在Speedcore Gen4架构中,Achronix将机器学习处理器(MLP)添加到Speedcore可提供的资源逻辑库单元模块中。MLP模块是一种高度灵活的计算引擎,它与存储器紧密耦合,从而为人工智能和机器学习(AI / ML)和高数据带宽应用的爆炸式需求,提供了支持。
解决带宽爆炸问题
固定和无线网络带宽的急剧增加,加上处理能力向边缘等进行重新分配,以及数十亿物联网设备的出现,将给传统网络和计算基础设施带来压力。这种新的处理范式意味着每秒将有数十亿到数万亿次的运算。传统云和企业数据中心计算资源和通信基础设施无法跟上数据速率的指数级增长、快速变化的安全协议、以及许多新的网络和连接要求。
Achronix亚太区总经理罗炜亮表示,传统的多核CPU和SoC无法在没有辅助的情况下独立满足这些要求,因而它们需要硬件加速器,通常是可重新编程的硬件加速器,用来预处理和卸载计算,以便提高系统的整体计算性能。经过优化后的Speedcore Gen4 eFPGA已经可以满足这些应用需求。
Achronix亚太区总经理罗炜亮
举例来说,不久前美光(Micron)官宣了其最新、最快的GDDR6存储器,Steve表示这将成为支持Achronix 7nm工艺独立FPGA芯片的首选高性能存储器。GDDR6针对包括机器学习等诸多要求严苛的应用进行了优化,这些应用需要数万兆比特(multi-terabit)存储宽带,从而使Achronix在提供FPGA方案时,其成本能够比其他使用可比存储解决方案的FPGA低出一半。
这种新的联合解决方案可应对很多深度神经网络中的固有挑战,包括存储大数据集、重权重参数和存储器激活;底层硬件需要在处理器和存储器之间存储、处理和快速移动数据。此外,因为机器学习算法总是在不断调整改变,所以需要可编程性来更加有效地实现设计。Achronix的下一代FPGA目前是唯一支持GDDR6存储器的FPGA系列产品。
全新模块为人工智能/机器学习加速
除了计算和网络基础设施的通用要求之外,人工智能/机器学习还对高密度和针对性计算产生了显著增加的需求。与以前的Achronix FPGA产品相比,新的Achronix机器学习处理器(MLP)利用了人工智能/机器学习处理的特定属性,并将这些应用的性能提高了300%。这是通过多种架构性创新来实现的,这些创新可以同时提高每个时钟周期的性能和操作次数。
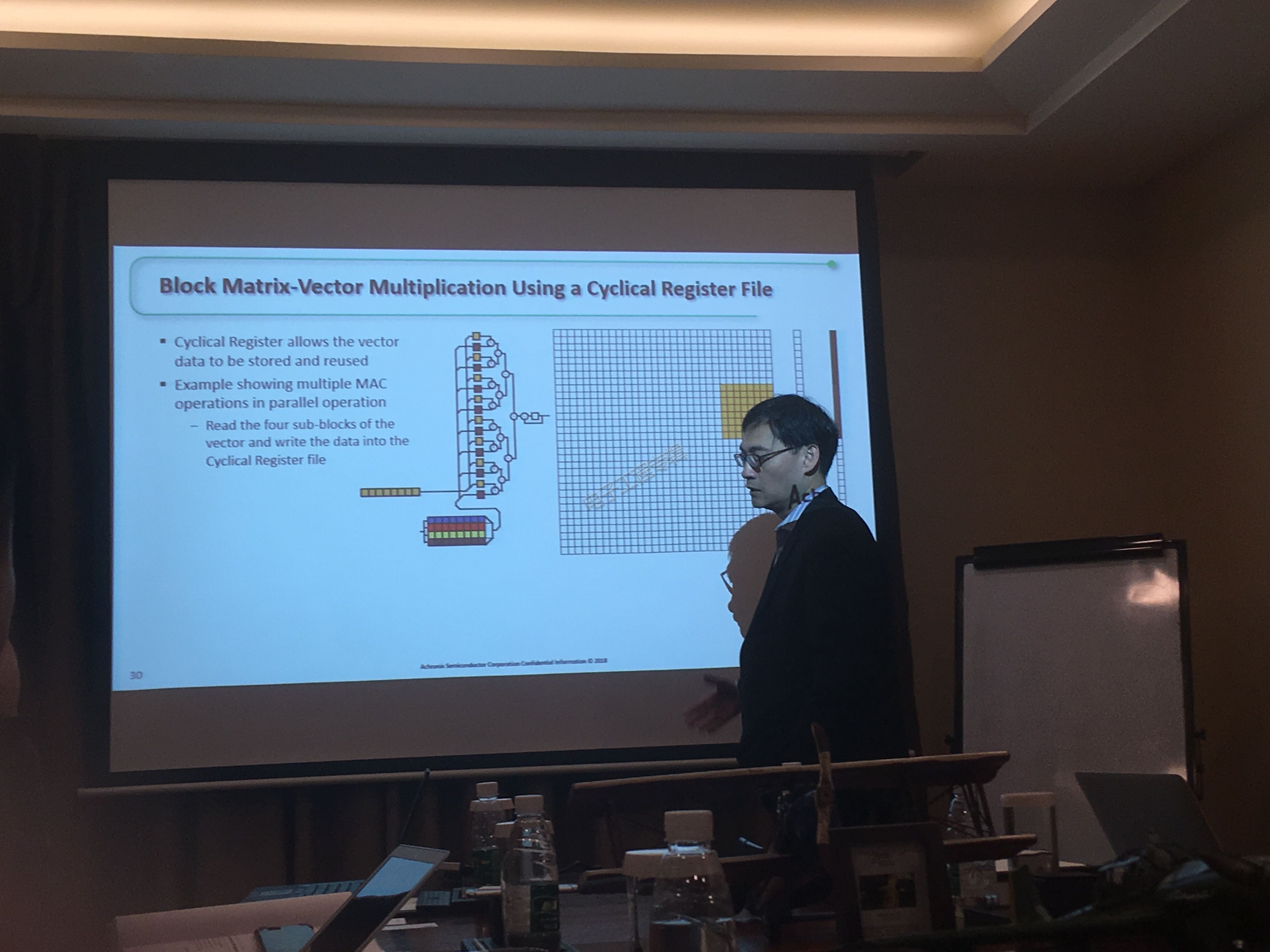
新的Achronix机器学习处理器(MLP)是一个完整的人工智能/机器学习计算引擎,支持定点和多个浮点数格式和精度。每个机器学习处理器包括一个循环寄存器文件(Cyclical Register File),它用来存储重用的权重或数据。各个机器学习处理器与相邻的机器学习处理器单元模块和更大的存储单元模块紧密耦合,以提供最高的处理性能、每秒最高的操作次数和最低的功率分集。这些机器学习处理器支持各种定点和浮点格式,包括Bfloat16、16位、半精度、24位和单元块浮点。用户可以通过为其应用选择最佳精度来实现精度和性能的均衡。
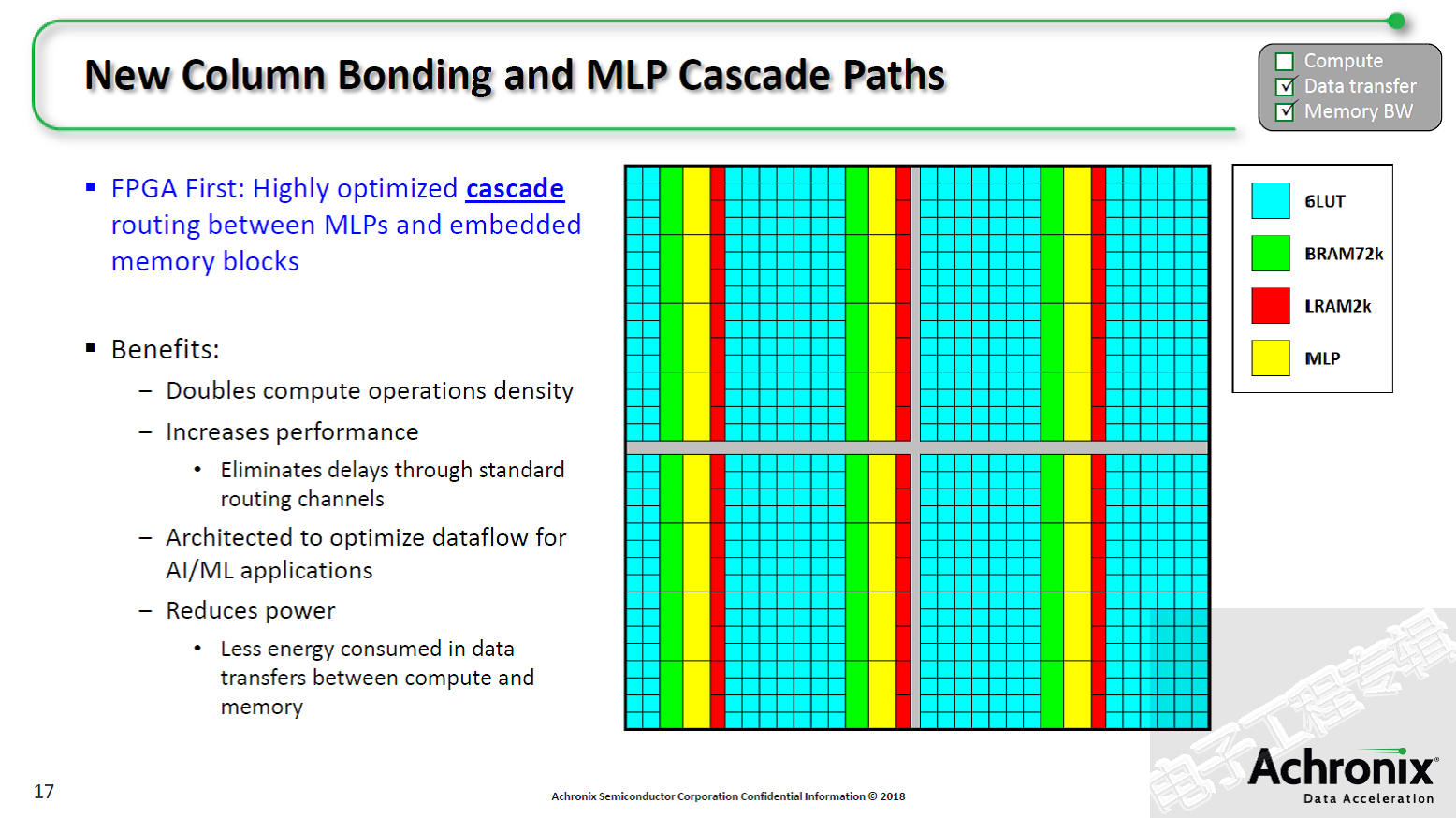
为了补充机器学习处理器并提高人工智能/机器学习的计算密度,Speedcore Gen4查找表(LUT)可以实现比任何独立FPGA芯片产品高出两倍的乘法器。领先的独立FPGA芯片在21个查找表可以中实现6x6乘法器,而Speedcore Gen4仅需在11个LUT中就可实现相同的功能,并可在1 GHz的速率上工作。
架构性创新提高系统性能
与上一代Speedcore产品相比,新的Speedcore Gen4架构实现了多项创新,从而可将系统整体性能提高60%。其中查找表的所有方面都得到了增强,以支持使用最少的资源来实现各种功能,从而可缩减面积和功耗并提高性能。其中的更改包括将ALU的大小加倍、将每个LUT的寄存器数量加倍、支持7位函数和一些8位函数、以及为移位寄存器提供的专用高速连接。
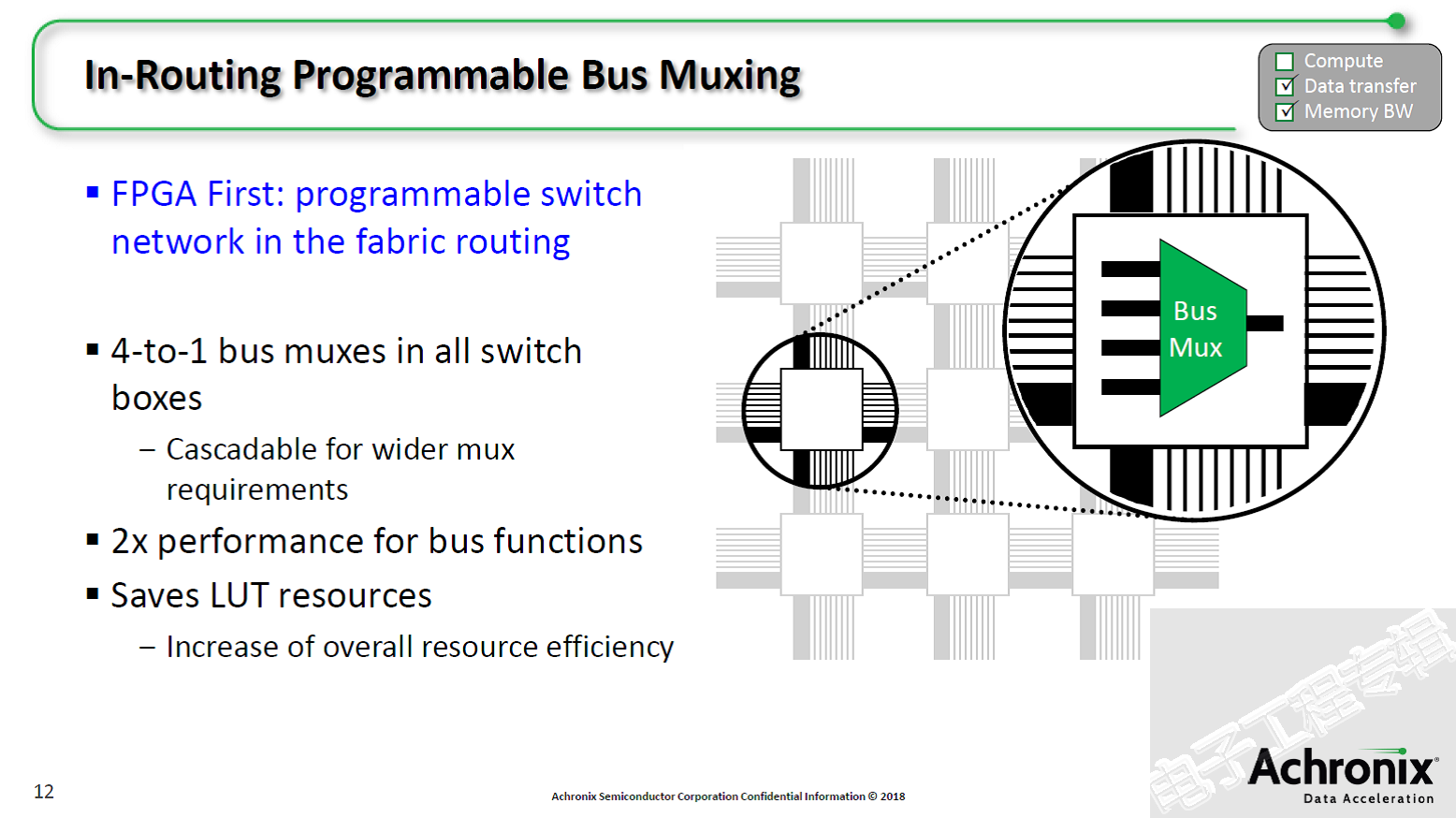
其中的路由架构也借由一种独立的专用总线路由结构得到了增强。此外,在该路由结构中还有专用的总线多路复用器,可有效地创建分布式的、运行时可配置的交换网络。这为高带宽和低延迟应用提供了最佳的解决方案,并在业界首次实现了将网络优化应用于FPGA互连。
如何评估Speedcore Gen4
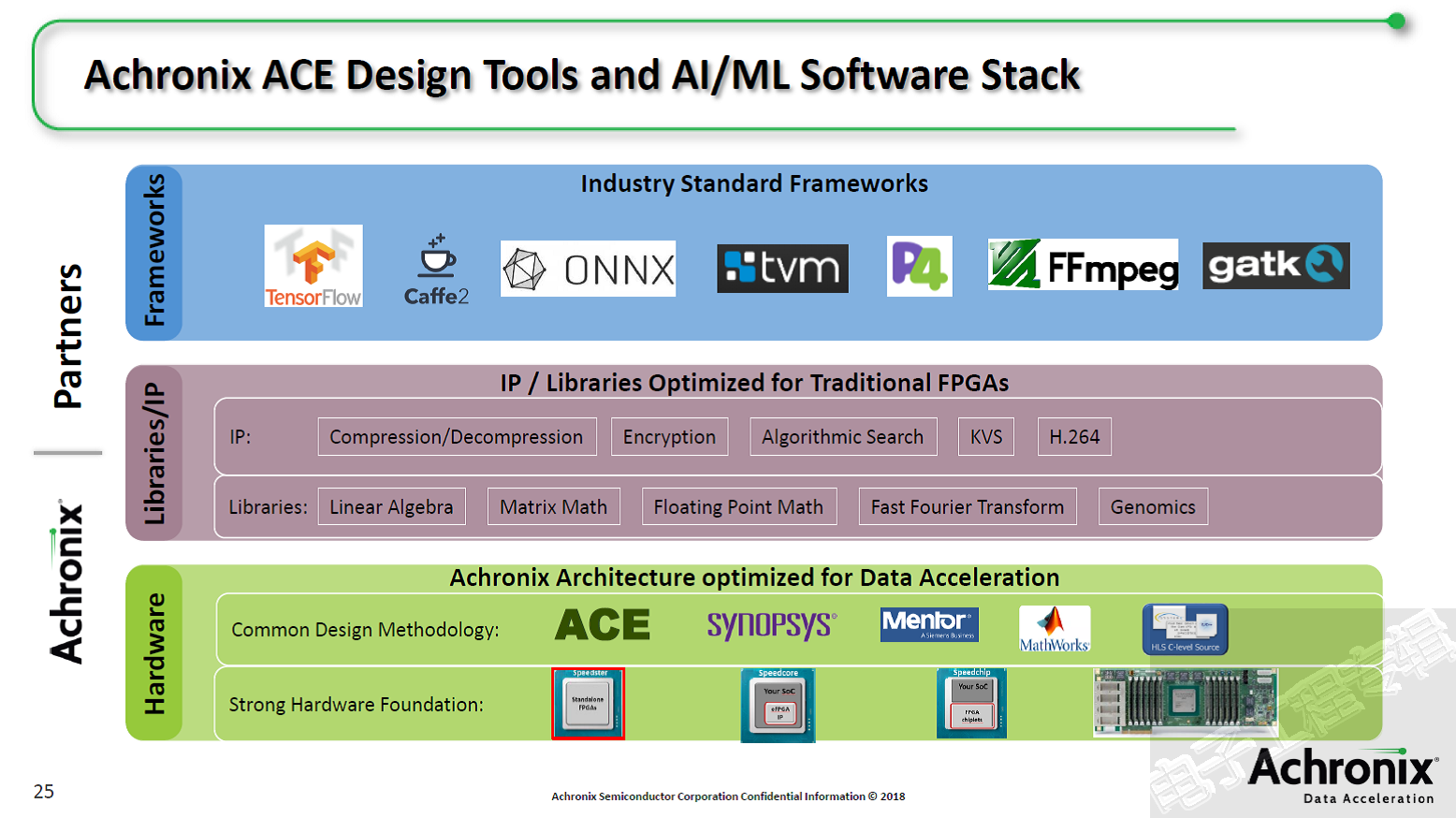
Achronix的ACE设计工具中包括了Speedcore Gen4 eFPGAs的预先配置示例实例,它们可支持客户针对性能、资源使用率和编译时间去评估Speedcore Gen4的结果质量;Achronix现已可提供支持Speedcore Gen4的ACE设计工具。Speedcore采用了一种模块化的架构,它可根据客户的要求轻松配置其大小。Achronix使用其Speedcore Builder工具来即刻创建新的Speedcore实例,以便满足客户对其快速评估的要求。
供货
对于已量产的Speedcore架构,Achronix可在6周内为客户配置并提供Speedcore eFPGA IP和支持文件。采用台积电7nm工艺节点的Speedcore Gen4将于2019年上半年投入量产,但是芯片设计企业现已可以联系Achronix,以获得支持其特定需求的Speedcore Gen4实例。Achronix还将于2019年下半年提供用于台积电16nm和12nm工艺节点的Speedcore Gen4 eFPGA IP。
今年,Achronix搬入了更大的新总部办公室,人员方面增加了50%。公司在美国、欧洲和中国都设有销售办公室和代表处,在印度班加罗尔设有一间研发和设计办公室。Steve表示,当前公司产品最大的应用市场在中国,未来也会在这一市场投入更多的精力和资源。

关注最前沿的电子设计资讯,请关注“电子工程专辑微信公众号”
- 谢谢分享!

