
在1年前推出的首款神经网络处理器Vision C5 DSP基础上,Cadence日前再接再厉,推出了性能更强、拓展性能更好的处理器产品—Tensilica DNA100。根据Cadence公司IP事业部Tensilica资深产品总监Lazaar Louis的描述,较其他采用相似阵列尺寸大小的乘法累加运算(MAC)解决方案,DNA 100处理器性能提升达4.7倍,每瓦特性能提升高达2.3倍。
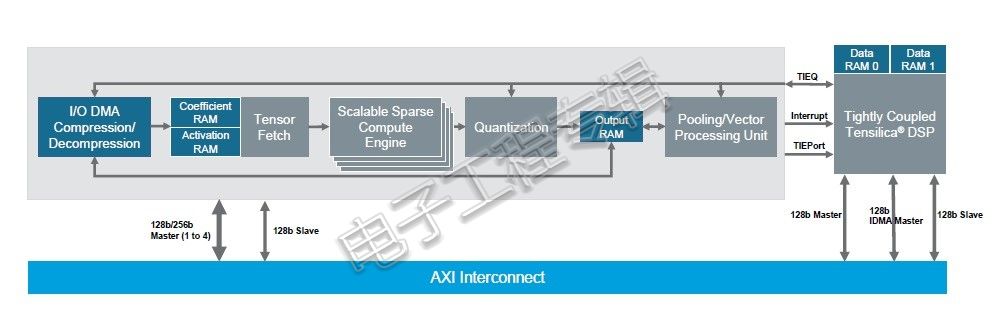
Tensilica DNA100处理器结构框图
按照Cadence的命名规则,DNA是深度神经网络加速器(Deep Neural-network Accelerator)的简称。但其实对更多的人来说,DNA是生命的符号,它在让我们每个人独一无二的同时,又将我们与地球上的其他人类联系在一起。那么,Tensilica DNA100处理器,会不会也具备类似的属性?
当前,大多数的AI推理发生在云端,以智能语音助手、旅行助手、导航助手等应用最具代表性。但Lazaar Louis认为,如果从更低的延时性、更好的连接性和保护用户隐私的角度考虑,在终端侧完成这一过程将更为合理,即所谓的“终端侧智能”。这一趋势目前在自动驾驶汽车(AV)、ADAS、监视、机器人、无人机、增强现实(AR)/虚拟现实(VR)、智能手机、智能家居和物联网等多个应用领域中已经得到了明显的体现。
但在上述应用中,神经网络推理需求涉及不同量级的人工智能处理和多种神经网络类型,对处理器性能的需求也从0.5到数百TMAC不等,如何设计出设备端AI推理所需的高性能和高能效产品,是摆在Lazaar Louis面前的难题之一。
“稀疏计算引擎是Tensilica DNA100处理器创新的关键所在。”Lazaar Louis说,神经网络的特征在于权重和激活函数的固有稀疏度,加载和乘以零会造成其他处理器不必要的MAC消耗。DNA 100处理器的专属硬件计算引擎移除了上述两项任务,利用稀疏度提高能效并降低计算量。神经网络再训练有助于提高网络的稀疏度,并通过DNA 100处理器的稀疏计算引擎实现最高性能。作为例证,4K MAC配置环境下,ResNet 50推理性能预计能实现每秒高达2550帧(fps)和3.4TMAC/W(16nm工艺)。

DNA 100处理器配备完整的AI软件平台,兼容最新版本的Tensilica神经网络编译器(Tensilica Neural Network Compiler),支持Caffe、TensorFlow、TensorFlow Lite及包括卷积和循环网络在内的广泛神经网络等高级AI框架。Tensilica神经网络编译器利用全面优化的神经网络库函数,将任意神经网络映射为可执行且高度优化的高性能代码。因此,DNA 100处理器为不同网络类型提供了强大的软件生态系统支持,包括分类、对象检测、分割、重复和回归。DNA 100处理器还支持安卓神经网络(ANN)API,可用于安卓设备端的AI推理。
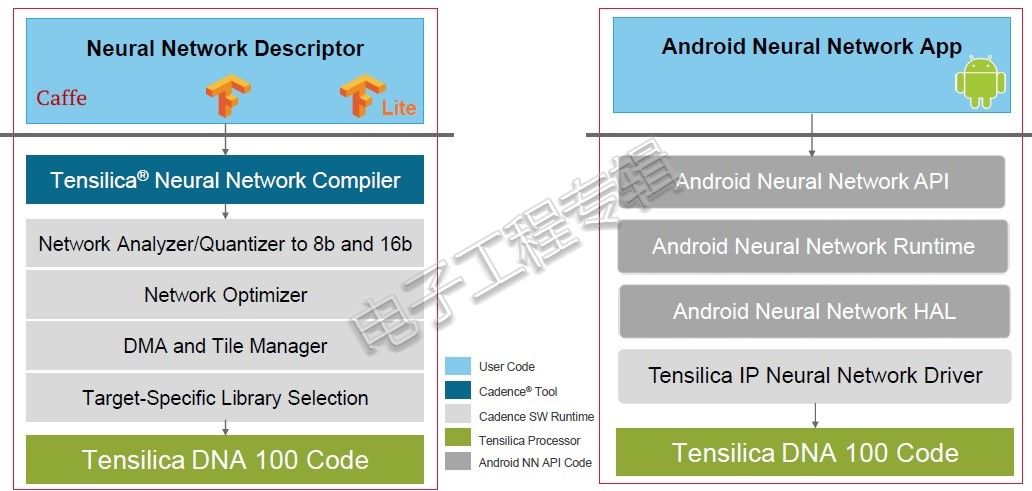
DNA 100处理器AI软件平台
DNA 100处理器可以在所有神经网络层运行,包括卷积、完全连接、LSTM、LRN和池化。单个DNA 100处理器可以轻松从0.5扩展到12有效TMAC;并可以通过堆叠多个DNA 100处理器,实现数百TMAC,适用于最计算密集型设备端的神经网络应用。DNA 100处理器还集成了Tensilica DSP,以适应DNA 100处理器内部硬件引擎当前不支持的新神经网络层;同时使用Tensilica指令扩展(TIE)指令集实现Tensilica Xtensa核心的可扩展性和可编程性。由于DNA 100处理器拥有独立的直接存储器访问(DMA),因此无需新增控制器即可运行其他控制代码。
与DNA 100处理器同时发布的,是面向音频和语音处理的Tensilica HiFi 5 DSP,这也是首款为高性能远场处理和人工智能语音识别处理量身优化的IP核。对比HiFi 4 DSP,第五代HiFi DSP的音频处理性能提高2倍,神经网络(NN)处理性能提高4倍。
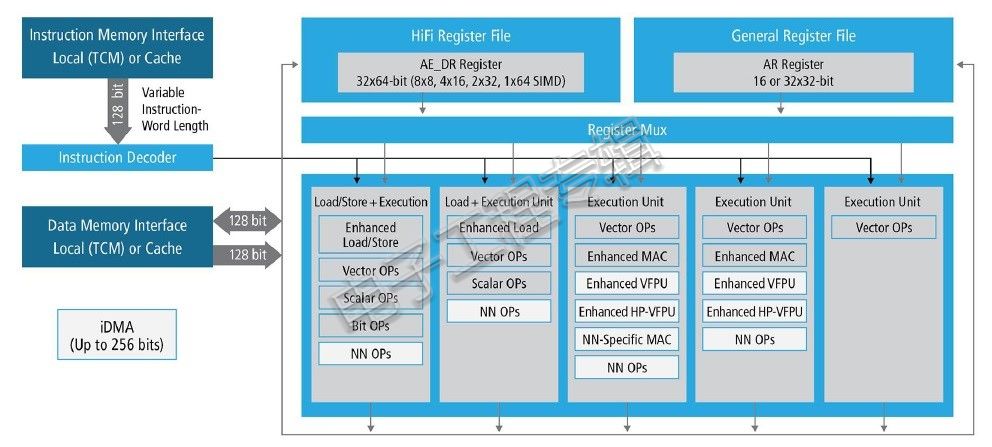
Tensilica HiFi 5 DSP结构框图
Cadence公司IP事业部Tensilica技术营销总监Yipeng Liu对记者表示,随着数字家庭助手普及度的快速上升,语音控制用户界面已经成为厂商开发创新消费产品的重要考量。高级DSP算法正在不断革新,消除噪音,从复杂环境分离并提取说话者的语音,以提高识别准确率。为此,更好的处理能力和能效必不可少。同时,因为延时,隐私保护和网络可用性等原因,基于神经网络的语音识别算法需要更多任务在本地运行,而非云端。
HiFi 5 DSP采用5个超长指令字(VLIW)插槽架构,支持每循环发出2个128-bit负载,完全兼容HiFi产品线拥有的超过300个为HiFi优化的音频语音编解码器以及语音增强软件包。对比HiFi 4 DSP,HiFi 5 DSP支持每周期8个32x32-bit MACs或16个16x16-bit MACs,可选每周期8个单精度浮点MACs,使得预处理和后处理的MAC性能提高2倍。神经网络处理MAC性能方面,HiFi 5支持每周期32个16x8或16x4 MACs,可选每周期16个半精度浮点MACs,从而将性能提高4倍。此外,全新的HiFi神经网络库为神经网络处理(特别是语音任务)提供专门优化的库函数,可以与主流机器学习框架轻松集成。
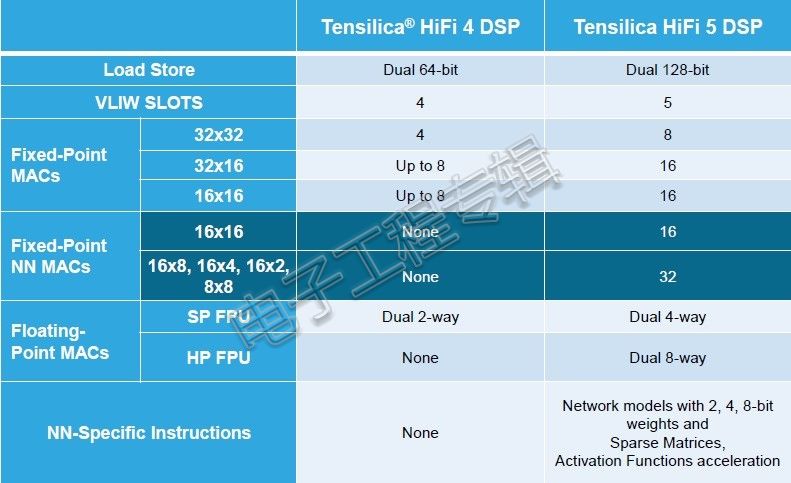
HiFi 5 DSP VS HiFi 4 DSP

