
除了Google、Facebook、亚马逊(Amazon)和百度(Baidu)等业界“大咖”一直在设计用于训练和推论的深度学习芯片,几乎每一周,我们都还会听说有一些“名不见经传”的新创公司开发出新一代AI SoC架构。
尽管有这么多的AI新芯片陆续发布,但一位资深的产业分析师——Tirias Research首席分析师Kevin Krewell提醒道:“机器学习处理领域充斥着许多新的主张,但只有真正可用的芯片和软件才能展现实力。”
事实上,这么多的产品中却找不到一款可在今年或甚至明年上市。直到真正的芯片上市,我们才有办法知道哪些芯片是真的,哪些只是误导市场的烟雾弹。
然而,最近在一次与Arteris营销副总裁Kurt Shuler的采访中,他提醒我们,有时候,像AI芯片这样一个被过度宣传的新兴市场中,真正发生哪些事情的答案必须要向更深层的食物链中去寻找。
谁在打造AI SoC?
Arteris日前推出新的互连IP以及名为FlexNoc 4的AI软件套件。据Shuler称,该公司的新产品旨在加速下一代深度神经网络(DNN)和机器学习系统的开发。
从与Shuler的访谈中可以发现,Arteris凭借其网络芯片(NoC) IP,已经将自家公司提升至一个新高度,清楚可见在全球AI SoC设计领域中有谁在经营哪些业务。
据Shuler表示,当专为训练而设计的AI芯片比以往任何时候都更加强大、更复杂,而且还经常与大规模平行处理器整合时,“互连变得格外重要”。
Shuler在采访中分享了目前使用该公司互连IP和工具开发AI SoC的芯片公司名单。虽然这份清单中包括许多没没无闻的新创公司和现有的系统供货商(包括日本相机OEM和一些大型系统OEM),但它清楚地描绘出现有SoC公司也在切入AI芯片设计及其最新进展。
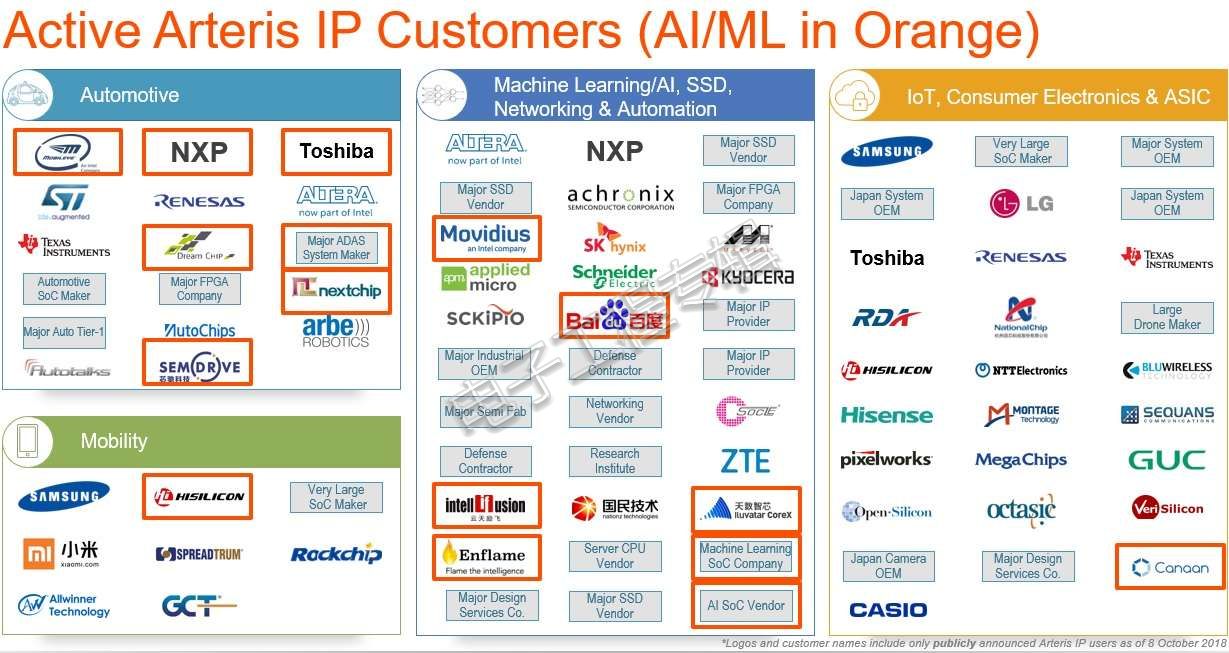
(来源:Arteris)
在汽车领域,这份清单中不乏Mobileye、恩智浦(NXP)和东芝(Toshiba)等知名大厂;针对移动性,当然少不了海思半导体(HiSilicon)。至于网络和自动化的机器学习类别,Arteris的客户还包括了Movidius和百度(Baidu)。
根据Shuler的观察,“中国目前正兴起一波AI芯片淘金热潮。”中国政府正大力支持各种相关活动。包括云天励飞(Intellifusion)、燧原科技(Enflame Technology)、天数智芯(Iluvatar Corex)、寒武纪科技(Cambricon Technologies)和嘉楠耘智(Canaan Creative)等多家中国业者也积极与Arteris合作投入AI芯片的开发。
谁在推动AI架构?
相较于应用处理器(AP)或物联网(IoT)芯片必须支持定义明确的架构,AI SoC则全然不同。Shuler说,“例如,应用处理器基本上就是一种架构。但对于AI SoC,每个人都还在尝试各种途径。”
至今还没有哪一种SoC架构能一统AI世界,也没有一种所谓正确设计AI SoC的方法。Shuler指出,这使得“灵活性”成为AI SoC设计的一项重要元素。
他说,“目前大多都是软件人员在开发AI芯片。”
因此,软件人员可能会说,“让我们看看这种特殊的DNN类型。我们都专精于数学,所以想弄清楚哪一部份能以硬件加速。”每个人都跟着这样做,一直到有人终于问了,“数据需要整理吗?我们应该清除不需要的数据。我们能开发出有助于更快得到答案的硬件吗?”当然,但接下来,同样的软件类型起不了作用后,他们可能还会问:“我们该如何加速这种卷积?”
因此,Shuler解释说,许多设计团队倾向于个别处理元素——每个元素都有一些数学成份、一些本地内存。然而,最终真正未解决的问题是“数据流”(data flow)。
虽然处理元素之间必须能够彼此通讯,但也必须管理处理组件和内存之间的传输流量。Shuler说:“数据流是他们无法真正了解的问题之一。”但他们必须能够“以最有效率的方式保持这些数据的流动。”这就是互连IP和工具得以发挥作用之处。
架构问题
Arteris从与各种系统和SoC公司合作开发AI芯片的经验中,更清楚地掌握了AI芯片面临的架构问题。
Shuler说目前主要有三大挑战。他首先提到的是AI训练芯片,并指出网络拓扑、芯片尺寸太大,以及需要更大的带宽,包括芯片上数据流以及存取至芯片外接内存。
Shuler解释说,关于网络拓扑结构,AI芯片设计人员通常会寻找网格、环形和圆环等元素,这有助于建立可预测的数据流。Arteris根据从AI芯片客户学习到的各种知识,在其FlexNoC AI中打造了新的IP技术。Shuler说,该新工具能够“自动产生拓扑结构”,为硬件设计人员提供了“客制和优化拓扑和个别网络路由器”的机会。
另一项重大设计挑战来自于设计人员必须能够实际处理大型芯片的现实问题。
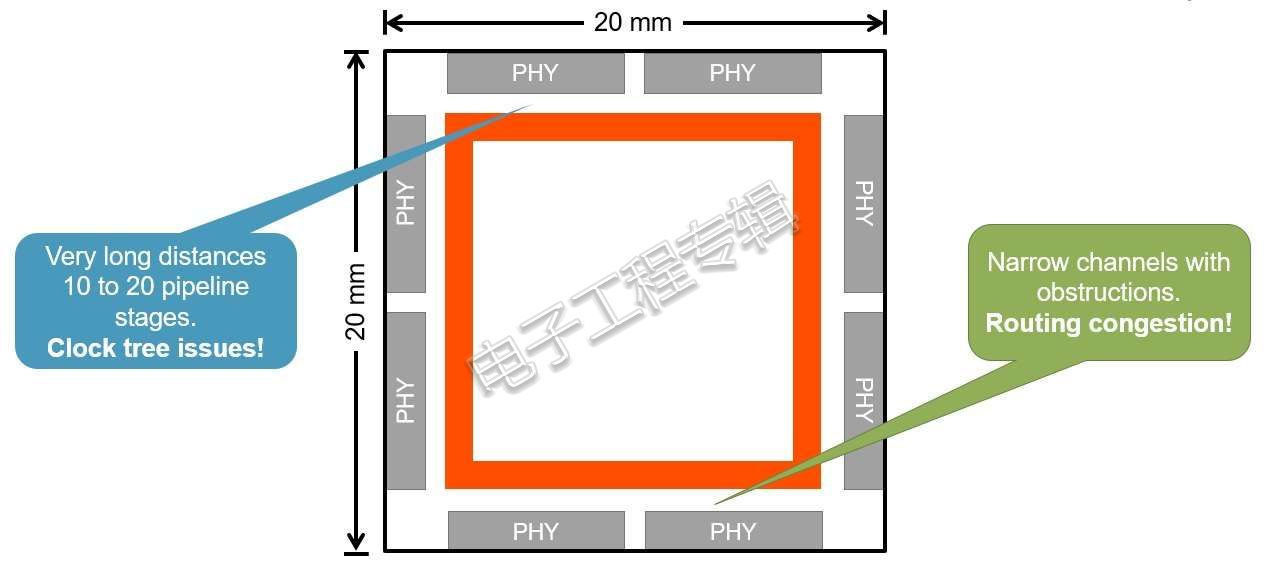
大型AI芯片可能成为时序收敛等问题的根源(来源:Arteris)
Shuler提到,他所见过的最大型AI芯片尺寸约20 x 20 mm。400 mm 2是一相当大的芯片了。他解释说,尺寸大小真的很重要,因为在AI芯片上跨越长距离时需要“较长的芯片路径,而这将导致时序收敛问题”。据Arteris指出,新工具提供的“来源同步通讯”和“虚通道链路”有助于解决这个问题。
第三项挑战是最经常被提到的问题:带宽。芯片上数据流以及存取至芯片外接内存都需要很大的带宽。
支援群播
最近几个月,AI芯片客户越来越关注于芯片是否能支持“群播”(multicast)。
为什么需要群播?因为它能以尽量接近网络目标的方式播送数据,从而使芯片上和芯片外内存带宽的利用优化。Shuler说:“这将更有效率地升级DNN权重、影像映像以及其他群播数据。”
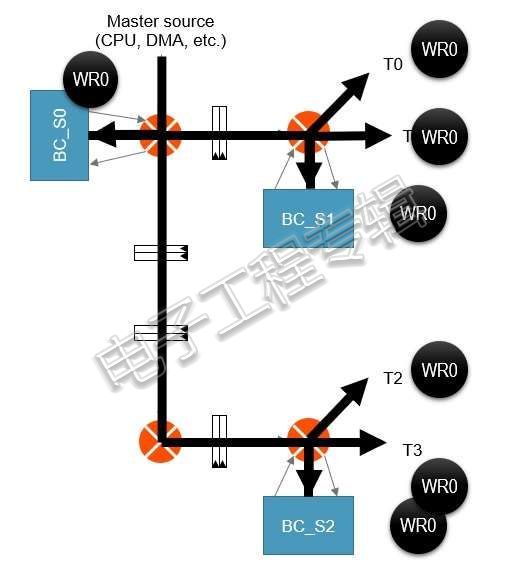
AI芯片日益需要智能群播功能。例如上述的广播电台技术能使NoC带宽利用优化(来源:Arteris)
加一家新创公司Provino Technologies首席执行官Shailendra Desai曾经在接受《EE Times》采访时表示,由于该公司开发出NoC IP,目前正获得了好几家名列Fortune 500的公司关注。Desai表示,系统供应商如今都要求AI芯片“支持群播”,因为他们认为这将显著地降低AI芯片的功耗和延迟。
Shuler也认同“智能群播”是目前每一个AI SoC设计师都在追求的功能。
内存存取
众所周知,外接内存的数据经常需要移进移出,但由此带来的功耗,是在设计AI芯片时最头痛的问题。
一方面,新创公司Mythic期望将神经网络映像至NOR内存数组。据该公司介绍,这种新架构能以节省多达两个数量级的功耗计算和储存数据。
但是,对于等不及Mythic推出商用产品的人来说,目前并没什么选择。他们必须找到最节能的方法来建立存取至芯片外接内存的途径。
为此,Arteris提供第二代高带宽内存(HBM2)和多信道内存支持工具,让设计人员能整合HBM2多信道内存控制器以及“8或16通道交错”。
藉由Arteris的工具部署记录器缓冲区和“流量聚合和数据宽度转换”,即可透过8或16个目标网络接口单元,将各种不同的连接组合于HBM2前端,如下图所示:
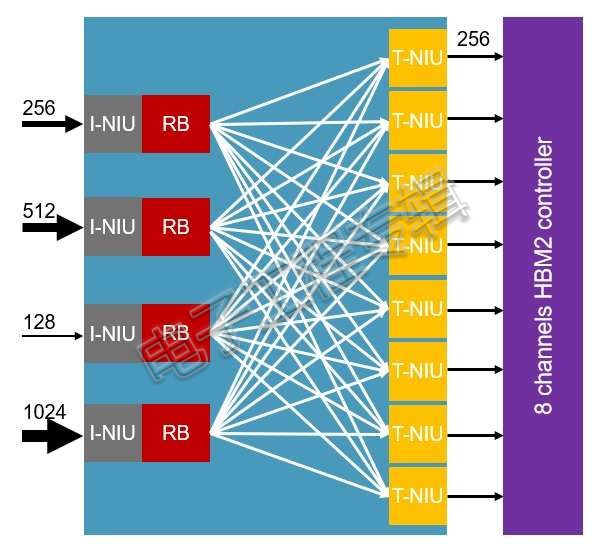
HBM2和多信道内存支持(来源:Arteris)
未来:“一定有人阵亡…”
Arteris规划了一个远大的未来蓝图,毕竟,AI SoC设计移动并不只是“空谈”或幻影。从取得Arteris IP授权的业者即可证实,许多新创公司和传统SoC供货商都在设计AI芯片。有趣的是,Arteris发布的设计工具也显示许多公司都面临相同的设计问题。
但实际上,大多数产业观察家并不看好目前所有的AI芯片公司都能在五年后继续存在。
一位不愿透露姓名的AI新创公司主管表示,“最终必然会有公司阵亡。每一家新创公司都必须考虑如何退场,未来并不一定会一路顺风。”
他看到一个可能的重要变量是“云端解决方案供货商和OEM的需求”,他们希望在内部开发自家芯片。因此,他们很可能造成“一些新创公司的退场。”
而在边缘端,“仍然存在一些机会,但要和大型公司竞争也不容易。”这将促使一些希望求生存的竞争者采取“更高风险的路径”,例如AI在内存内计算(IMC)、模拟等方面。
历史背景
AI芯片新创公司正从创投业者(VC)手中获得了大把创投资金。然而,Linley Gwennap总裁Linley Gwennap说,“虽然VC通常都会审慎行事,但仅有1/5或1/10的投资案能带来巨大报酬即可接受。无论是VC或任何人应该都不会指望所有的新创公司都能繁荣兴盛。”
Linley认为,“VC大举投资AI新创公司,主要是因为这些解决方案的市场规模很大,在未来五年内,每年创造的芯片营收可能至少都有100亿美元。”
但是,“在新创公司开始出货产品之前,你很难对其进行评估。”他指出,这种循环就像回到了我们开始对话AI芯片之处。
Linley说:“即使是像Wave和Graphcore等似乎比多数公司发展更超前的公司,就算发布了一些性能基准,也不允许第三方公开评估其产品。许多新创公司已经远远落后于其最初所承诺的性能和时间表。等到这些产品能够公开供测试时,证据自然就会出现了;预计在一年后,我们将更能了解整个市场定位。”
编译:Susan Hong, EET Taiwan

关注最前沿的电子设计资讯,请关注“电子工程专辑微信公众号”

