
看好深度学习加速器市场预计将达到250亿美元的庞大商机,数据中心正积极为多款芯片展开实验室测试,预计将在明年部署其中的一些芯片,并可能针对不同的工作负载挑选多款加速器。
目前为止,包括Graphcore、Habana、ThinCI和Wave Computing等50家供应商的AI芯片都在其客户实验室中进行测试。在日前于美国加州举行的人工智能硬件高峰会(AI Hardware Summit)上,来自这两大阵营——芯片供应商及其数据中心客户的代表们均表达了各自的立场。
微软(Microsoft) Azure部门的杰出芯片工程师Marc Tremblay指出,一个逐渐明朗的问题是“没有所谓的通用编译程序——这些芯片架构各不相同”。Marc Tremblay的部门负责管理超过1百万台的服务器。
微软勾勒数据中心AI芯片版图
该数据中心巨擘正在开发称为Lotus的自家执行环境,可将人工智能(AI)图形映像至硬件语言。Facebook上周也推出一款通用的深度学习编译程序Glow,以支持其生态伙伴策略。
数据中心渴望能在AI性能方面实现重大飞跃进展,超越被誉为当今“训练加速器之王”(the king of training accelerators)的英伟达(Nvidia)运算架构Volta。Tremblay在发表专题演说时提到,“有些训练任务在GPU上执行需要22天的时间,甚至还有超过2个月时间的,但我们希望尽快就会有答案。”
语音识别应用程序(App)大约使用4,800万个参数。研究人员正致力于研究神经网络;这些神经网络使用非对称连接产生自己的模型,进一步将运算需求提升到新的层次。
Tremblay说:“我们需要10-50倍的带宽,才足以支持更多深奥的神经网络出现。”。
针对16芯片的系统,当今的GPU价格高达40万美元且功耗相当高,即使是交换器芯片也需要散热片。他说,在芯片丛集上进行线性扩展“有时需要进行一些工程师不想做的任务。”
目前,微软采用V100和上一代GPU,并密切“关注”Nvidia上周发布的T4芯片。Tremblay指出,它看起来可望用于同时执行多个神经网络。
此外,微软以及其他数据中心巨擘都在其x86 CPU上执行多种深度学习任务。“对我们来说,它通常是免费的,因为x86芯片并非一直在执行中。”他指出,软件优化——例如英特尔(Intel) Cascade Lake中的新AI指令,将有助于推动多年的进展。
未来,数据中心可能会采用多个加速器,让每个加速器分别映像到最适合的特定工作负载。Tremblay简介了各种不同的语音、视觉、语言、搜寻和其他AI App,每一个App都各自具有延迟和吞吐量要求。

微软杰出芯片工程师Marc Tremblay介绍AI芯片发展现况(来源:Microsoft)
有些App使用多达20种类型的神经网络,使得跨不同神经网络模型的灵活性成为必备要求。范围甚至包括对延迟敏感的Bing搜寻采用单个批处理,而为其他App采用超过100个批处理。因此,Tremblay为其测试的芯片分配了一个稳定的数字作为其灵活性的衡量标准。
他说:“新创公司先忽略安全和虚拟化等问题。他们并不需要从一开始就准备齐全,但最终我们都必须着手以成熟的CPU和GPU实现各种功能。”
他总结道,关于数据中心AI的好消息是“我们还有很长的路要走,但如今的进展令人难以置信......许多创新不断涌现,AI的未来前景光明。”。
Wave Computing瞄准数据流系统
新创公司Wave Computing在会中介绍其数据流(dataflow)架构细节。如同其竞争对手Cerebras一样,Wave将会销售完整系统,因为要达到性能提升的目标需要的进展并不只是来自处理器。
具体来说,Wave目前的16nm处理器使用HMC内存上的15GByte/s端口,连接板上的4个芯片和系统上的4块板子。内存及其互连是透过其处理器丛集串流图形的关键,有助于避免处理器透过相对较窄的PCI Express总线馈入延迟。
Wave选择HMC的部份原因出于权宜之计。该新创公司与HMC供应商美光(Micron)建立了策略联盟,但对于一家规模相对较小的新创公司而言,竞争的HBM内存似乎过于复杂且风险高。
目前在金融、随选视频和制造业等市场约有6家公司正在测试用于其IT部门的部份机架。为了服务像微软等大型数据中心,Wave需要一个全机架的系统,该系统将会采用基于HBM的下一代7nm处理器。
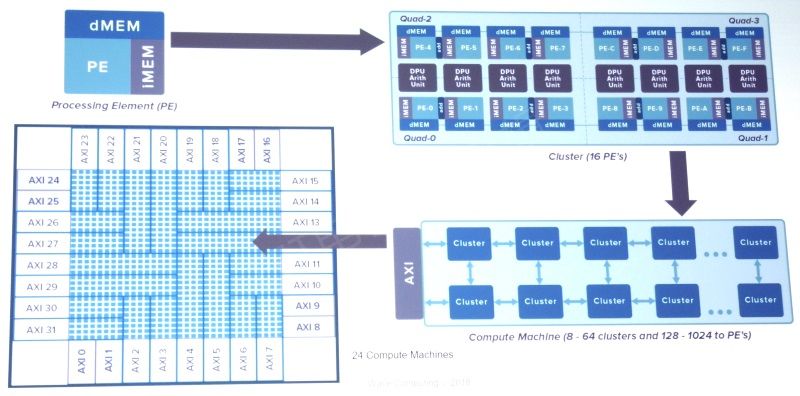
Wave的首款系统使用HMC连接4个四路处理器板(来源:Wave Computing)
针对其关键的互连技术,该新创公司仍在研究如何从序列HMC转换至平行的HBM内存。虽然HMC支持多个端口,但HBM通常配置一个执行高达307Gbytes/s的快速埠——1,024I/O中的每一接脚都支持2.4 Gbits/s的速度。
Wave最初关注的是企业用户,因而发展成为其服务业务。该公司在菲律宾建立了一支20人的团队,协助IT部门学习如何开发自家深度学习模型。有些大型数据中心的数据科学家经常自行处理数据。
有趣的是,Wave原本是在Tallwood Venture Capital育成中心的一支团队,到了2009年才独立出来,这时间大约是深度学习开始蓬勃发展的三年前。当时,该公司的目标在于打造能以高级语言编程的更高效率FPGA竞争方案,希望挑战Tabula和Achronix。
Wave的深度学习处理器右途径是让图形元素流经电路,并加以执行。Wave共同创办人兼首席技术官Chris Nichol在主题演讲中表示,它可以为任务设置最佳精确规格的指令,而电路在完成执行后会回到睡眠状态。一位市场观察家曾经发布一份关于此系统架构的白皮书。
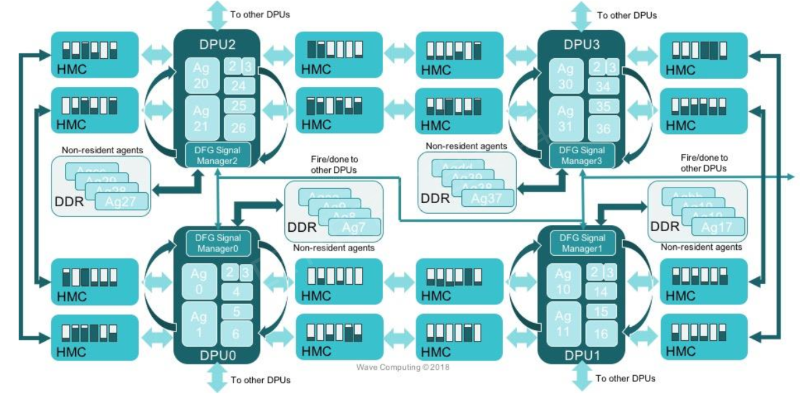
Wave的处理器丛集,可让图形数据流经电路
Graphcore聚焦完整系统
Graphcore发表其采用236亿个晶体管的Colossus,该芯片目标在于将整个神经网络模型保留于其300 Mbytes的芯片上内存。该新创公司声称可以在其1,216个核心上平行处理7,000个程序,每个核心都有100 GFlops的效能。
Colossus支持高达30 TBytes/s的内部存储器带宽,外部支持在80个信道上的2.5 TBits/s芯片到芯片间互连。在单个PCIe Gen4 x16板卡中封装2个芯片,提供31.5 GByte/s的I/O性能。
针对该新创公司的架构或时间表,Cerebras首席执行官Andrew Feldman并未详谈,但他表示必须打造完整的系统。他在会中的一场专题讨论中指出,“如果你做好了PCI适配卡,就可能受限于功率、散热和I/O。”唯有提供完整的系统才不至于造成系统扩展的阻碍。
新的硬件将为新的AI工作负载铺路,从而带动更多需求。他说,深度学习“研究人员最担心受限。他们有一连串的问题和想法,而且(今天发展相对较慢)的计算机也造成阻碍。”
至于产品,他说将会透过管理神经网络稀疏性,以提供1,000倍的性能提升。他说,该公司并不会使用任何奇特的技术,但确实需要新颖的核心、内存架构、编译程序、结构和技术,从而为数据中心冷却系统以及降低功耗。
SambaNova Systems是另一家在会中首度亮相的新创公司。如同Cerebras、Graphcore和Wave一样,SambaNova Systems拥有一支经验丰富的架构师团队,将基于斯坦福大学(Stanford University) Spatial的编译程序整合于其数据流芯片中。
编译:Susan Hong

关注最前沿的电子设计资讯,请关注“电子工程专辑微信公众号”

