
人脸识别(face recognition)是机器学习领域中最受欢迎的技术之一。最近,该技术的使用案例已经从政府安全系统的特定监视应用扩展到多个产业的更广泛应用,例如使用者的识别和认证、消费者体验、健康和广告。事实上,根据MarketsAndMarkets,到2022年,脸部识别(facial recognition)市场预计将成长到77.6亿美元,复合年成长率(CAGR)为13.9%。
本文讨论eInfochips工程师为存取管理应用成功开发的人脸识别算法实务。在这样的系统中有两个阶段:人脸检测;然后是人脸识别。一开始,脸部的检测是在影像上使用Haar级联分类器(Haar Cascade Classifier),结合脸部主要的裁剪部份。
使用Haar级联分级器进行眼睛检测,形成几何脸部模型;而鼻子的检测则被用作眼睛检测的再确认机制。之后,从大量脸部影像中撷取“定向梯度直方图”(Histogram of Oriented Gradients;HOG)特征,作为识别机制的一部份。然后将这些HOG特征一并标记为某一个人脸/使用者,并且训练支持向量机(SVM)模型以预测馈送到系统中的脸部。
可能的用例和环境条件如下:
• 使用人脸识别进行存取管理。
• 近距离场景,摄影机与待识别人员脸部之间的距离为5到6英呎。
• 成功识别仅限于15个自由度(℃)以内的脸部俯仰翻转、左右翻转和平面旋转姿态。
就像任何其他形式的生物识别一样,人脸识别需要采集、识别、提取必要(特征)信息的脸部样本,并储存以供识别。整个人脸识别解决方案分为以下几个主要模块:
1. 脸部撷取
2. 脸部训练
3. 脸部识别
脸部检测是在人脸识别过程中执行任何操作的基本步骤。基于Haar特征的级联分类器是一种广泛使用的脸部检测机制。为了训练分类器来检测脸部,要形成两组包含众多影像的影像集:一组包含具有脸部的影像,另一组则包含没有脸部的影像。然后使用这些影像产生分类器模型。透过从正像(positive image)和负像(negative image)中撷取Haar特征来产生分类器。
Haar级联分类器如何运作?
Haar分类器主要根据Paul Viola和Michael Jones在其论文《使用增强级联的简单特征进行快速对象检测》(Rapid object detection using boosted cascade of simple features)中提出的对象检测架构。使用下图所示的每个特征训练单个分类器。然而,单个分类器本身无法实现高精度,因此多个这样的分类器形成级联。所形成的最终分类器是弱分类器的加权之和。使用此方法,分类器可提供95%以上的分类准确度。
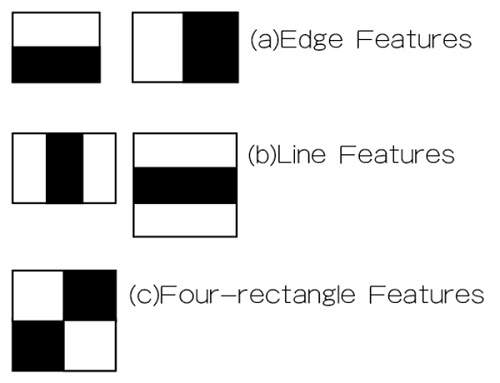
图1:Haar特征(来源:opencv.org)
在图2的示例中,影像作为卷积核心以撷取特征,其中每个特征是透过从白色矩形下方像素总和中减去黑色矩形下方像素总和所取得的值。

图2:Haar特征示例(来源:opencv.org)
上图提供了两个特征示例:边缘和线条。边缘特征有效地映像脸部属性;即眼睛区域比脸部其它任何部份更暗。线条特征映像了鼻子属性;即脸部的垂直鼻线比两侧更亮。因为,这些特征中的任一个都无法准确对图案进行分类,所以将它们做成级联;因此,这就是基于Haar特征的级联分类器名称由来。
现在,让我们详细考虑脸部识别的三个主要模块,如下所述。
脸部撷取
人脸识别的第一步是收集脸部样本。基本上包括以下三个基本步骤:
1. 检测脸部。
2. 裁剪脸部的主要部份。
3. 储存脸部影像。
如同前一节中所讨论的,脸部检测主要使用基于Haar特征的级联分类器来实现。通常,脸部识别的准确性高度依赖于样本影像的质量和种类。针对相同脸部捕捉具有多个脸部表情的多个影像,可获得各种样本影像。

图3:捕捉脸部样本(来源:eInfochips)
一旦检测到脸部,就可以将其裁剪并储存为样本影像以供分析。广泛地使用矩形来框定影像中的区域,引入了裁剪头部影像的多余部份。因此,使用Haar级联分类器获得的矩形限定脸部特征中包含了无关紧要的数据,例如颈部、耳朵、头发等周围的区域。使用几何脸部模型可缓解这一情况,该几何脸部模型由各种脸部特征(包括眼睛、鼻子和嘴巴)之间的几何关系形成。
几何脸部模型如何运作?为了形成几何脸部模型,通常将一双眼睛视为影像内定位的第一特征。理想情况下,任何特征都可用于作为形成脸部模型的起点,但从眼睛的位置开始产生具有更高精度的脸部模型。在某些情况下,鼻子的位置用于确定脸部模型。然而,眼睛通常被认为是主要的起始特征,而鼻子则被认为是眼睛未定位或部份闭塞(occluded)情况下的次要起始特征。
使用眼睛的脸部模型:从两只眼睛中心的坐标开始,使用以下等式获得脸部的必要部份(特征):

图4:使用眼睛的几何脸部模型(来源:eInfochips)
使用鼻子的脸部模型:使用鼻子中心的坐标,利用以下等式获得两只眼睛中心的坐标。此外,使用等式(eq.) 1、2和3 (如上所述)获得脸部必要部份的裁剪。

图5:使用鼻子的几何脸部模型(来源:eInfochips)
为了提高识别准确度,在脸部捕捉过程中丢弃尺寸小于256x256的脸部剪裁区域。此外,脸部区域相对于光源方向有显著偏差。为了减轻这种影响,在裁剪的脸部影像实施直方图等化。这降低了由于不均匀照明而在脸部形成的不对称性。
脸部训练
在此阶段,从与每个人相关联的影像中收集特征。之后,对来自所有储存影像的完整信息集(每人作为单个SVM标签予以隔离)进行训练以产生SVM模型。
什么是支持向量机(SVM)?支持向量机(SVM)是受监督的机器学习模型,用于对数据进行划分和分类。

图6:脸部训练方块图(来源:eInfochips)
SVM广泛用于诸如脸部检测、影像分类、手写识别等应用。可以将SVM模型视为使用超平面隔离多个类的点空间。
什么是定向梯度直方图(HOG)?HOG是通常用于对象检测的特征描述符号,在行人检测应用上也广为人知。HOG依赖于影像内对象的属性而拥有强度梯度或边缘方向的分布。在每个区块的影像内计算梯度。区块被认为是像素网格,其中梯度由区块内像素强度的变化幅度和方向构成。

图7:具HOG特征的脸部样本(来源:eInfochips)
在当前示例中,个人的所有脸部样本影像被馈送到特征描述符号撷取算法;即HOG。描述符号是影像的每个像素所产生的梯度向量。每个像素的梯度由大小和方向组成,使用以下公式计算:

在当前示例中,Gx和Gy分别是像素强度变化的水平和垂直分量。大小为128x144的窗口用于脸部影像,因为它与人脸的一般宽高比相匹配。描述符号是在具有8×8维度的区块上计算的。在8×8区块上每个像素的这些描述符号值被量化为9个区间(bin),其中每个区间表示在该区间内梯度和值的方向角,其为具有相同角度的所有像素强度总和。此外,将直方图在16×16区块的大小上统一处理,这意味着将4个8×8区块统一以最小化光条件的影响。该机制减轻了由于光变化导致的精度降低。使用针对多个脸部的几个HOG向量来训练SVM模型。
脸部识别
视频序列中的脸部识别分为三个主要任务:脸部检测、脸部预测和脸部追踪。脸部捕捉程序执行的任务也在脸部识别期间执行。为了识别所获得的脸部,必须撷取脸部的HOG特征向量。然后在SVM模型中使用该向量来确定具有每个标签的输入向量之匹配分数。SVM返回具有最高分数的卷标,这表示对训练脸部资料内最接近匹配的置信度。

图8:脸部识别流程方块图(来源:eInfochips)
计算匹配分数的任务需要大量的运算。因此,一旦被检测和识别到,就需要追踪影像中的标记脸部,以减少未来讯框中的运算量,直到脸部最终从视频中消失。在所有可用的追踪器中,使用Camshift追踪算法可产生最佳的脸部识别结果。
范例应用
本文采用的实际范例应用是在视频管理系统中使用脸部识别存取管理和分析。在该计划中,艾睿(Arrow)旗下子公司eInfochips的一支团队设计并实施了一个带有脸部识别功能的视频管理系统,用于检测和识别多个IP摄影机馈送的人脸。该设置部署在制造业中,其中摄影机安装在多个建筑物中的不同位置,并且使用局域网络(LAN)互连。
该团队为该网络开发并安装了完整的视频管理解决方案,为安全部门赋予视频串流、透过视频分析提供警报以及访客身份验证。该视频管理系统中的脸部识别服务用于识别来自摄影机实时馈送的人脸,并产生系统事件,以触发员工和访客到场所的认证过程。此外,这些事件包括诸如识别时间、人名、人在地图上的位置等细节。然后使用视频管理系统内的用户接口客户端分析来自数据库的这些事件。
结论
在现代监控和安全应用方面,脸部识别扮演着非常重要的作用。透过应用本文中描述的方法,可以获得准确的算法和高质量的脸部识别结果。此外,藉助HOG和SVM模型,即使在包含复杂背景的场景中,也可以在识别人脸和分析脸部特征方面实现高性能。

关注最前沿的电子设计资讯,请关注“电子工程专辑微信公众号”
