
在机器学习中,分类是指预测建模问题,其中为给定的输入数据示例预测类别标签。分类问题的例子包括: 给定一个例子,分类它是否是垃圾邮件。给定一个手写字符,将其分类为已知字符之一。
一、分类
二元分类是指那些具有两个类标签的分类任务。
示例包括:
电子邮件垃圾邮件检测(垃圾邮件与否)。
流失预测(流失与否)。
转化预测(购买或不购买)。
通常,二元分类任务涉及一类是正常状态,另一类是异常状态。
例如“非垃圾邮件”是正常状态,“垃圾邮件”是异常状态。另一个例子是“未检测到癌症”是涉及医学测试的任务的正常状态,“检测到癌症”是异常状态。
正常状态的类被分配类标签 0,而具有异常状态的类被分配类标签 1。通常使用预测每个示例的伯努利概率分布的模型来对二元分类任务进行建模。
伯努利分布是一种离散概率分布,涵盖事件的二进制结果为 0 或 1 的情况。对于分类,这意味着模型预测属于第 1 类或异常状态的示例的概率.
2. 流行的算法
可用于二进制分类的流行算法包括:
- 逻辑回归
- k-最近邻
- 决策树
- 支持向量机
- 朴素贝叶斯
一些算法是专门为二进制分类设计的,本身不支持两个以上的类;示例包括逻辑回归和支持向量机。
3. 数据和模块
import numpy as np # 线性代数
import pandas as pd # 数据处理,CSV 文件 I/O(例如 pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import timedelta
import warnings
warnings.filterwarnings('ignore')df=pd.read_csv("/kaggle/input/tabular-playground-series-aug-2022/train.csv")
df_test=pd.read_csv("/kaggle/input/tabular-playground-series-aug-2022/test .csv")
ss=pd.read_csv("/kaggle/input/tabular-playground-series-aug-2022/sample_submission.csv")
4. 基础探索与建模
数字 = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']newdf = df.select_dtypes(include=numerics)
newdf=newdf.sample(1000)
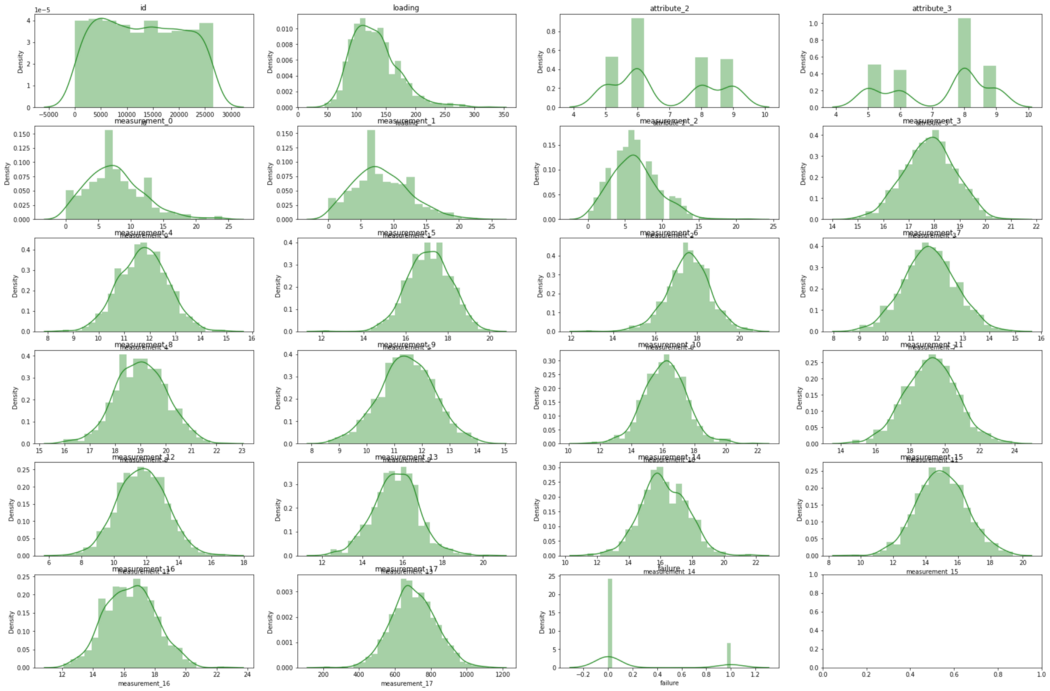
fig, axes = plt.subplots(nrows = 6, ncols = 4) # 轴是二维数组 (3x3)
axes = axes.flatten() # 将轴转换为长度为 9 的一维数组
fig.set_size_inches(30, 20)对于 ax, col in zip(axes, newdf.columns):
sns.distplot(newdf[col], ax = ax, color='forestgreen')
ax.set_title(col)
sns.heatmap(newdf.corr())
输出:

随后再进行预处理和建模。
5.分类算法
5.1朴素贝叶斯
朴素贝叶斯方法是一种监督学习算法,它基于应用贝叶斯定理,在给定类变量值的情况下,每对特征之间的条件独立性的“朴素”假设。朴素贝叶斯分类器是基于贝叶斯定理的分类算法的集合。它不是一个单一的算法,而是一个算法家族,所有这些算法都有一个共同的原则,即每一对被分类的特征是相互独立的。
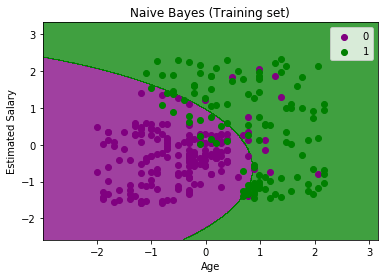
什么时候使用这个模型?
基本的朴素贝叶斯假设是每个特征都会对结果做出:独立且平等的贡献。
这是什么意思?这意味着当您有多个特征并且它们是独立的时,它们是不相关的,并且没有一个属性是不相关的并且假定对结果有同等贡献。
由于独立性假设永远不正确,我们称之为 Naive。该模型特别适用于自然语言处理 (NLP) 问题。因为我们可以假设
文档 X 中单词的顺序没有区别,但单词的重复有区别。(词袋假设)给定文档类(条件独立),单词彼此独立出现。有不同的类型,常见的类型有:
a) 多项朴素贝叶斯分类器特征向量表示某些事件由多项分布生成的频率。这是通常用于文档分类的事件模型。
b) 伯努利朴素贝叶斯分类器 在多元伯努利事件模型中,特征是描述输入的独立布尔值(二元变量)。与多项式模型一样,该模型在文档分类任务中很流行,其中使用二进制词项出现(即一个词是否出现在文档中)特征而不是词频(即一个词在文档中的频率)。
c) 高斯朴素贝叶斯分类器在高斯朴素贝叶斯中,假设与每个特征相关的连续值按照高斯分布(正态分布)分布。
概括
朴素贝叶斯算法对于这个特征丰富的数据集非常快(请记住,我们有一个具有 10,000 个特征向量的张量)并且已经提供了 80% 以上的良好结果。训练数据和测试数据的得分接近,说明我们没有过拟合。
5.2逻辑回归
逻辑回归根据给定的自变量数据集估计事件发生的概率,例如投票或未投票。由于结果是概率,因此因变量的范围在 0 和 1 之间。
逻辑回归是一种机器学习算法,用于进行预测以找到因变量的值,例如肿瘤状况(恶性或良性)、电子邮件分类(垃圾邮件或非垃圾邮件)或大学录取(录取或录取)不承认)通过从自变量(与问题相关的各种特征)中学习。
例如,为了对电子邮件进行分类,该算法将使用电子邮件中的单词作为特征,并据此预测电子邮件是否为垃圾邮件。
逻辑回归是一种有监督的机器学习算法,这意味着为训练提供的数据被标记,即,答案已经在训练集中提供。该算法从这些示例及其相应的答案(标签)中学习,然后使用它对新示例进行分类。
用数学术语来说,假设因变量是 Y,而自变量集是 X,那么逻辑回归将预测因变量 P(Y=1) 作为自变量集 X 的函数。

Logistic 回归需要相当长的时间来训练并且确实过拟合。从训练数据得分(98%)与测试数据得分(86%)的偏差可以看出算法过拟合。
什么时候使用这个模型?
好吧,如果数据的分布可以分布在这个逻辑函数上,或者像 sigmoid 函数一样,输出的行为可能与前两个公式一样,那么这可能是一个很好的测试候选者。逻辑回归是一种概率方法。
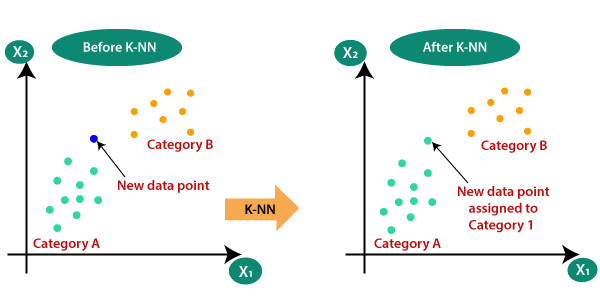
5.3 K-最近邻
K-Nearest Neighbor (K-NN) 算法假设新案例/数据与可用案例之间的相似性,并将新案例放入与可用类别最相似的类别中。K-NN 算法存储所有可用数据并根据相似性对新数据点进行分类。这意味着当新数据出现时,可以通过使用 K-NN 算法轻松地将其分类为井套件类别。
K-NN 算法可用于回归和分类,但主要用于分类问题。K-NN 是一种非参数算法,这意味着它不对基础数据做出任何假设。它也被称为惰性学习算法,因为它不会立即从训练集中学习,而是存储数据集,并在分类时对数据集执行操作。
KNN 算法在训练阶段只存储数据集,当它获得新数据时,它将数据分类到与新数据非常相似的类别中。
什么时候使用这个模型?
假设有两个类别,即类别 A 和类别 B,并且我们有一个新的数据点 x1,那么这个数据点将位于这些类别中的哪一个。为了解决这类问题,我们需要一个 K-NN 算法。借助 K-NN,我们可以轻松识别特定数据集的类别或类别。
正如预期的那样,该算法不太适合这种预测问题。它需要 12 分钟,它预测很差,只有 62%,并且显示出过度拟合的趋势。
5.4 支持向量机
支持向量机基于统计方法。我们试图找到一个最能区分这两个类的超平面。SVM 找到超平面之间的最大边距,这意味着两个类之间的最大距离。当数据集小而复杂时,SVM 效果最好。只有当数据完全线性可分时,我们才能使用线性 SVM。当数据不是线性可分时,我们可以使用非线性 SVM,这意味着当数据点不能通过使用线性方法分成 2 类时。
支持向量机是一种用于分类和回归任务的简单算法。它可以非常快速地以较少的计算能力提供高精度。由于特征数量众多,我们使用的是 LinearSVC。事实证明,设置正则化参数 C=0.0001 可以提高预测质量并减少过拟合。
支持向量机算法的目标是在 N 维空间(N — 特征数)中找到一个对数据点进行明确分类的超平面。
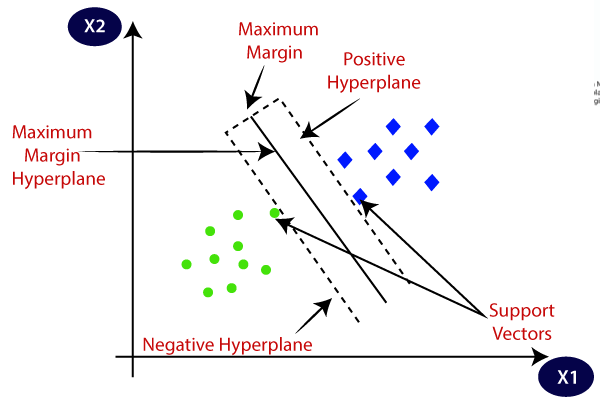
支持向量机或 SVM 是最流行的监督学习算法之一,用于分类和回归问题。但是,它主要用于机器学习中的分类问题。
SVM 算法的目标是创建可以将 n 维空间划分为类的最佳线或决策边界,以便我们将来可以轻松地将新数据点放入正确的类别中。这个最佳决策边界称为超平面。
支持向量机速度非常快,预测得分很高,并且没有显示过拟合问题。
什么时候使用这个模型?
当与数据集中的许多数据点相比,许多特征较高时,我们可以使用 SVM。通过使用正确的内核并设置一组最佳参数。它在高维空间中很有效。在维度数大于样本数的情况下仍然有效。在决策函数中使用训练点的子集(称为支持向量),因此它也具有内存效率。
5.5 决策树
决策树是一种用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过学习从数据特征推断出的简单决策规则(if-else)来预测目标变量的值。

决策树可以执行分类和回归任务,因此您会看到作者将它们称为 CART 算法:分类和回归树。这是一个总称,适用于所有基于树的算法,而不仅仅是决策树。
但是让我们专注于分类的决策树。
决策树背后的直觉是,您使用数据集特征来创建是/否问题并不断拆分数据集,直到您隔离属于每个类的所有数据点。
通过此过程,您可以将数据组织成树状结构。
每次您提出问题时,您都会向树中添加一个节点。第一个节点称为根节点。
提出问题的结果会根据特征值拆分数据集,并创建新节点。
如果您决定在拆分后停止该进程,则最后创建的节点称为叶节点。
什么时候使用这个模型?
当您不需要在构建模型之前准备数据时,以及当您的数据集可以包含数字和分类数据的混合时,您不需要对任何分类特征进行编码。
但是,您应该考虑到决策树模型通常偏向于对具有大量级别的特征进行拆分。训练数据的微小变化可能会导致决策逻辑的巨大变化,并且大树可能难以解释,并且它们做出的决策可能看起来违反直觉。
其中一些用途包括:
生物医学工程(用于识别可植入设备中使用的特征的决策树)。
财务分析(客户对产品或服务的满意度)。
天文学(分类星系)。
系统控制。
制造和生产(质量控制、半导体制造等)。
药物(诊断、心脏病学、精神病学)。
物理学(粒子检测)。
小结:
将单个决策树应用于此特征丰富的数据集会导致大量过拟合。事实上,100% 的准确度意味着它准确地记住了训练数据集,因此在测试数据上的泛化能力很差。我们在这里看到的是单一决策树的缺点之一,它无法处理具有太多特征的数据。
6. 参考
机器学习中的 4 种分类任务:
https://machinelearningmastery.com/types-of-classification-in-machine-learning/#:~:text=In%20machine%20learning%2C%20classification%20refers,one%20of%20the%20known%20characters.
分类算法简介:
https://www.edureka.co/blog/classification-algorithms/
机器学习中的分类算法:
https://www.javatpoint.com/classification-algorithm-in-machine-learning
