
这是机器学习业界常用的机器学习术语表。
准确性
准确性用于评估任何分类模型。它被定义为正确预测总数的百分比。在数学上它表示为:
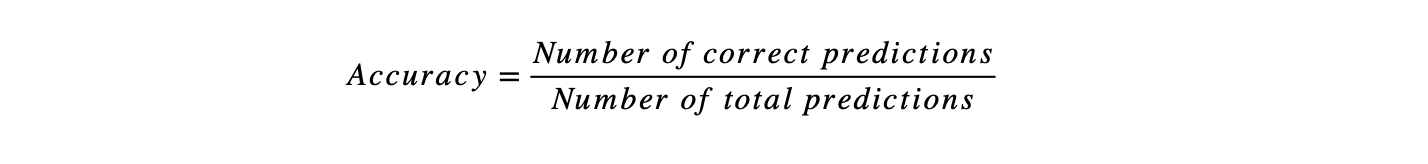
算法
在机器学习中,算法是应用于数据以创建机器学习模型的过程。例如,线性回归、决策树。
注解
为未标记数据分配标签的过程。例如,在手写数字识别任务中,如果我们将 8 的值分配给 8 的图像。
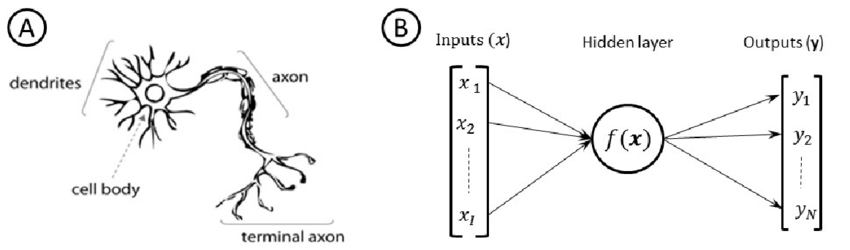
人工神经网络
人工神经网络是受构成动物脑细胞的生物神经网络启发的机器学习算法。
属性
实例的一个方面。如果我们谈论结构化数据并以表格格式存储值,那么列代表属性。例如,假设我们要估计今天的大气温度,为此,我们记录了大气压力、风速和其他基本属性。这些属性称为属性。
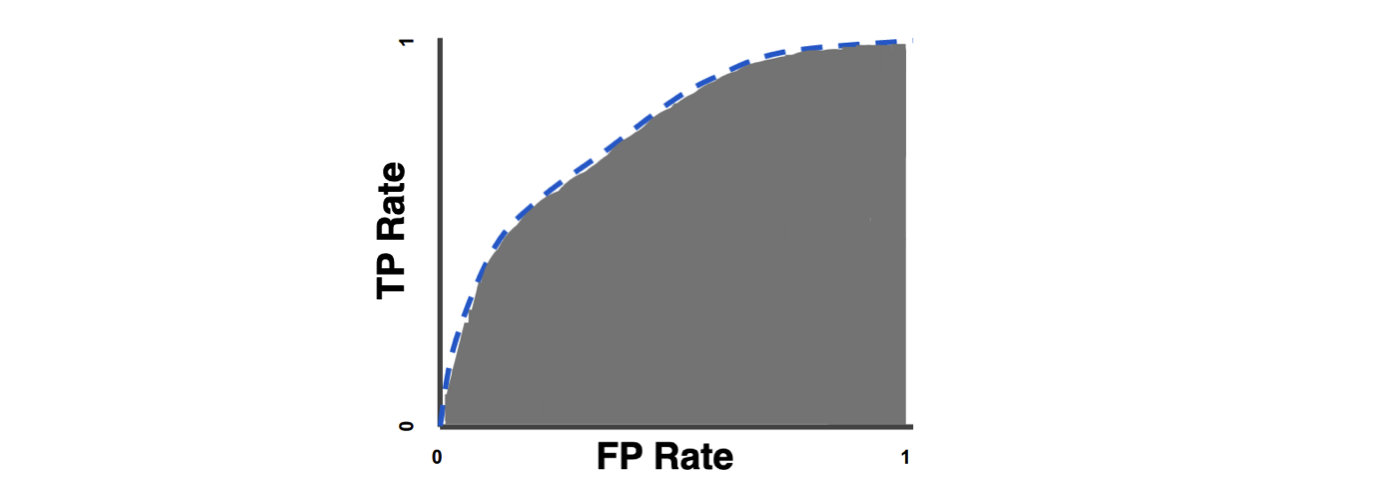
AUC(曲线下面积)
ROC 曲线下的面积表示分类模型在所有分类阈值下的总体性能。ROC曲线表示真阳性率相对于假阳性率的变化。
偏见
偏差通过使我们的模型对任何特征或数据点更不敏感或更敏感来帮助概括结果。由于不正确的 ML 过程假设,偏差被认为是机器学习模型中的系统错误。
偏差误差
由于算法倾向于通过不考虑所有数据信息来持续学习错误事物而导致的错误。
高偏差:-对数据做出假设的趋势增加,因此误差增加。
低偏差:-对数据做出假设的趋势变小。模型在训练数据上准确学习。
下面的右侧图显示了点分散在圆的中心周围,因此具有较低的偏差。
但右图中存在很大偏差,因为散射只发生在特定方向。

低偏置与高偏置
分类
分类是机器学习中的一个问题陈述,模型试图预测输出类别。可以有两种分类:
二进制分类:- 将输入分类为两个二进制类;例如,图像中是否包含猫,Statement as True or False。
多标签分类:-对多个类中的对象进行分类。例如,图像同时检测到房子、猫、狗等的存在。
分类阈值
它是做出特定决定的极限值。假设一个机器学习模型以 X% 的保证预测猫在任何图像中的存在。我们已经设定了标准,如果置信度 > 60%,那么这将是一个有效的预测。那么分类的阈值为60。
聚类
一种无监督学习,模型根据一些固有的数据特征将输入数据分组到不同的桶中。通常,集群由具有相似特征的项目组成。最常用的聚类算法是 K-Means、层次聚类和亲和聚类。
混淆矩阵
机器学习分类问题的性能测量指标,其中输出可以是两个或更多类。它将预测分为四类,
True Positive:猫的图像被机器学习模型归类为猫的图像。
True Negative:输入图像中没有猫,机器学习模型也预测没有猫。
误报:狗的图像被机器学习模型分类为猫的图像。这也称为I 类错误。
假阴性:输入图像中有一只猫,但机器学习模型预测没有猫。它们也被称为II 型错误。
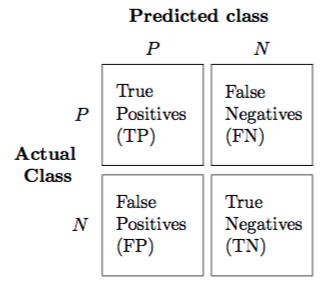
收敛
训练机器学习模型期间的一种状态,当连续时期之间损失值的变化变小时。更具体地说,如果损失函数的代价变化很小,那么可以说模型找到了最小值,或者说它的位置不会进一步改变,即已经收敛。
深度学习
机器学习的一个子领域,处理基于人工神经网络的算法,并能够理解时间和空间依赖性。它也被称为深度结构化学习。
方面
机器学习中的维度是指已用作机器学习算法输入的特征数量。
退出
一种正则化器,用于在训练神经网络时通过丢弃隐藏或可见单元来防止过度拟合。
时代
1 Epoch = 对整个数据集的 1 次迭代。
外推
超出原始观测范围的一种估计。
误报率 (FPR)
数学上计算如下:

特征
特征被称为属性和值(最终用于训练)。温度是属性,温度 = 25°C 是一个特征。
特征向量
特征向量列出了所有馈送到 ML 模型的特征。
全局最小值
损失函数值在整个损失函数域中全局达到最小值。它是函数在其整个范围内的最小整体值。
隐藏层
神经网络中输入层和输出层之间的层是隐藏层。
超参数
一个参数,其值用于控制学习过程。例如,神经网络中隐藏层的数量。
实例
数据集中的样本行特征值。它也被称为观察。
独立同居样本
这意味着样本的每个随机变量具有相同的概率分布,并且都是相互独立的。
标签
输出数据用于训练监督学习模型。例如,为了训练猫分类器模型,我们需要准备一个数据集,在其中我们通过说明它是否是猫来标记图像。
学习率
任何优化问题中的调整参数决定了每个时期的步长,同时朝着任何损失函数的最小值(全局/局部)移动。
失利
简单来说,Loss = (Actual value) - (Predicted value)。与错误相同;因此,损失值越低,模型越好(除非过度拟合)
局部最小值
损失函数的值在局部区域的该点处变为最小值。这是一个函数值小于附近但可能大于远处的点。
机器学习
一个计算机科学领域,使计算机无需明确编程即可学习。
模型
模型是在数据上运行的任何 ML 算法的输出。它是一种存储包含学习参数的权重和偏差矩阵的数据结构。
神经网络
机器学习算法的灵感来自于构成动物脑细胞的生物神经网络。
正常化
在任何回归问题中,重新缩放特征值以将数据集值限制在标准范围内。它提高了计算速度。
噪音
数据中存在其他无意义的信息。
空精度
准确度可以通过直接预测任何分类问题中最常见的类别来实现。
观察
数据集中的样本行特征值。它也称为实例。
优化器
改变参数值以使损失达到最小的方法。它们用于通过最小化成本函数来解决优化问题。例如,梯度下降
离群值
与其他观察结果显着不同的数据样本。
过拟合
模型训练误差明显小于模型测试误差的情况。在这种情况下,模型在训练数据上表现非常好,但在测试数据上表现不佳。

参数
我们通过训练任何机器学习模型来学习其价值的变量。例如,神经网络的权重。
精确
Precision 试图回答这个问题,True Positive 的哪一部分实际上是正确的?

记起
Recall 试图回答以下问题:正确识别出阳性的哪一部分?

回归
一种机器学习,其中预测输出是连续的。
正则化
一种用于解决过拟合问题的技术。
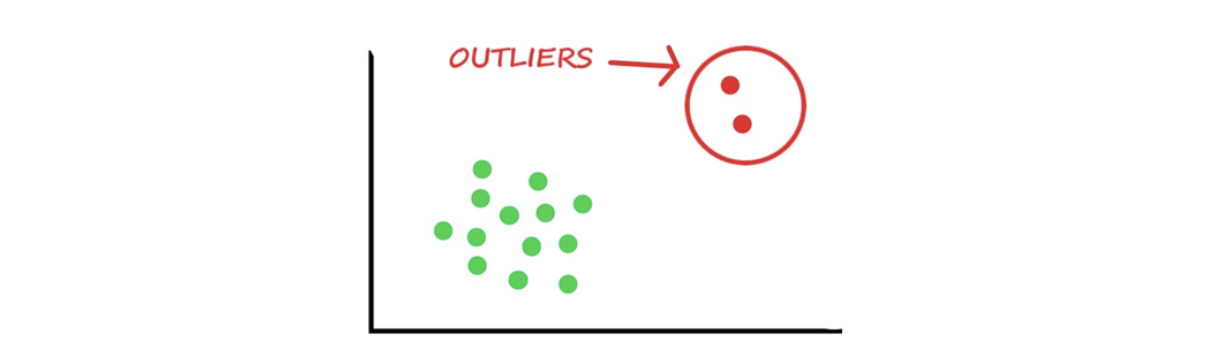
强化学习
机器学习的一个子集,其中学习基于基于代理在环境中所采取的行动来最大化奖励。
ROC(接收器操作特性)曲线
真阳性率与假阳性率的图表用于检查分类模型在不同分类阈值下的性能。
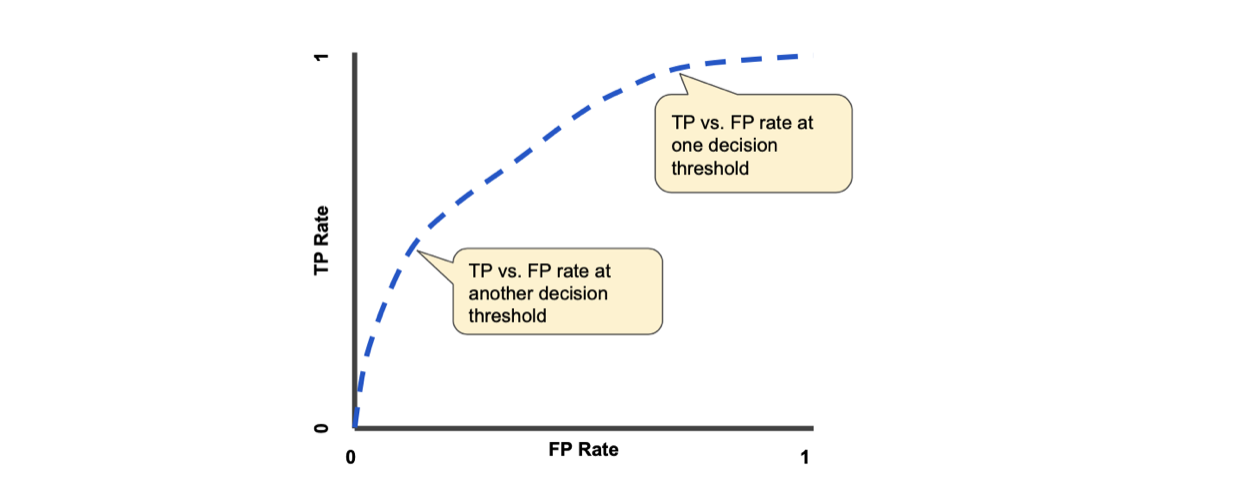
灵敏度

特异性

监督学习
在标记数据集的监督下训练机器学习模型。
测试集
数据样本用于检查机器学习模型的通用性。这些集合对模型是不可见的。
动车组
用于训练机器学习模型的数据集。
迁移学习
一种机器学习算法选择已训练模型的权重并根据问题要求对其进行微调的方法。
真阳性率
与召回相同。

类型 1 错误
与假阳性相同
类型 2 错误
与假阴性相同
欠拟合
机器学习模型不学习数据中存在的变化的情况。
通用逼近定理
对于 ANN,如果模型针对 (a,b) 的输入范围进行训练,则预计该模型将在仅位于 (a,b) 范围内的测试数据集上表现良好。
无监督学习
一类机器学习,其中训练基于未标记的数据集。例如,降维、聚类。
验证集
一个数据集,用于在训练时通过检查调整参数的通用性来验证训练模型。
方差
对训练数据集中的小波动敏感的错误。它可以有两种类型:
低方差:-指模型输出变化很小的情况。
高方差:-指模型开始非常准确地遵循噪声模式并最终过度拟合数据的情况。
在测试模型时,预测在下左图中击中了靶心。因此它的方差很小。在右图中,预测是分散的,在测试时未能收敛;因此它具有很高的方差。
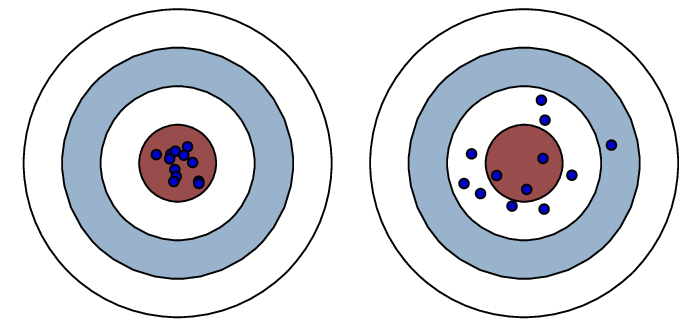
低方差 高方差
权重
机器学习中的可学习参数。
Z-均值
标准化也称为 Z 均值标准化。
参考:https ://developers.google.com/machine-learning/glossary

