
AI(人工智能)已经是未来十年甚至是数十年科学和科技界最重要的发展领域,未来技术的进步也将在AI的不断进化中快速提升。在AI领域的软件模型算法已经相对成熟(当然还在不断的优化、改进和发展)的当下,对硬件的考验与要求越来越高。以往,AI芯片级硬件主要被NVIDIA的A100主导称王,现在这一局面逐渐被打破。6月底,MLCommons公布的MLPerf v2.0 训练结果显示,Graphcore的Bow Pod系列和Intel的HLS-Gaudi2的性能已经比NVIDIA的DGX-A100快了超过30%。
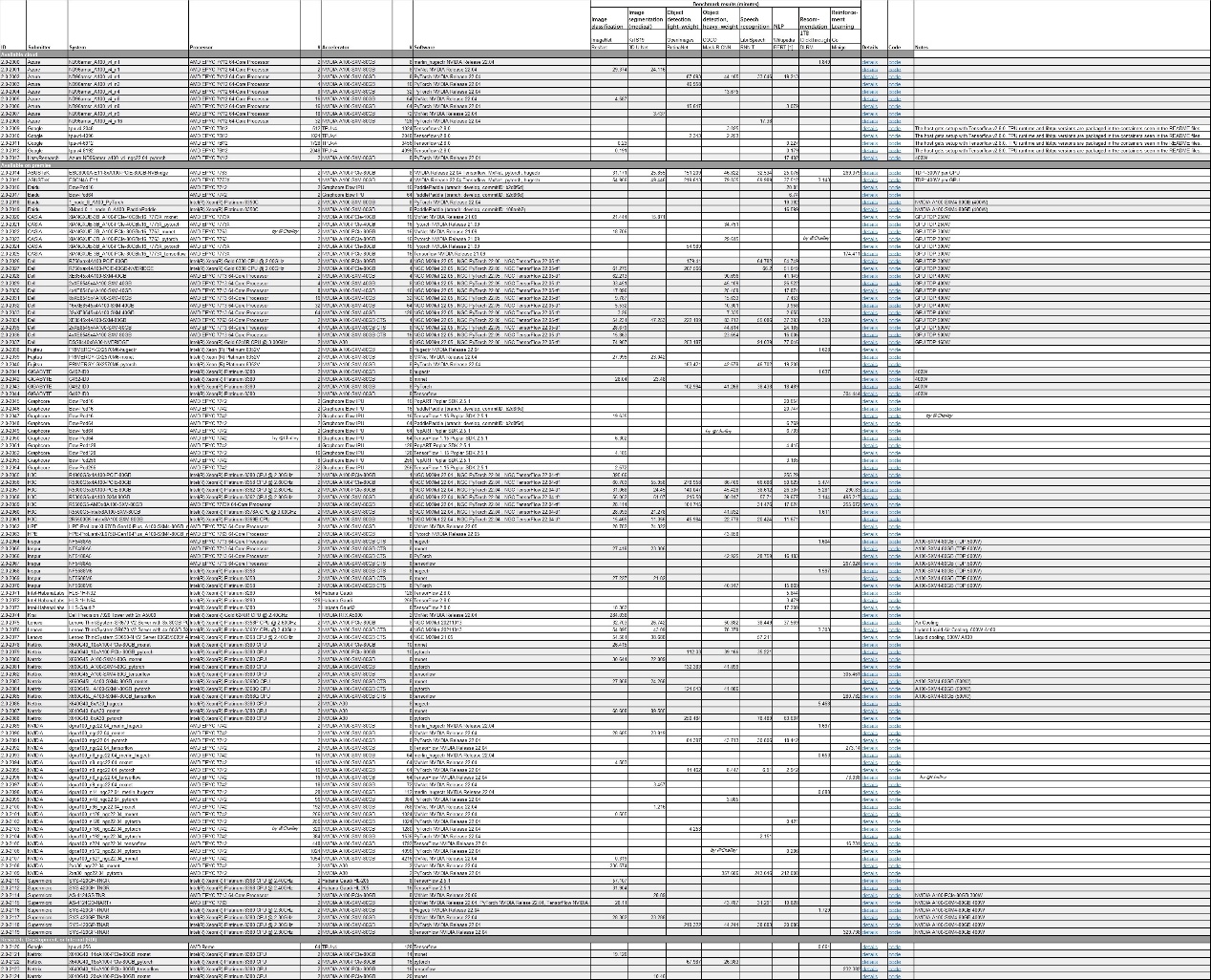
MLPerf v2.0 Result,来源:MLCommons,2022-6-29,整理 by @Challey

MLPerf竞赛由图灵奖得主大卫·帕特森(David Patterson)联合谷歌、斯坦福、哈佛大学等单位共同成立,是国际上最有影响力的基准测试之一。在AI领域,主要模型有ResNet(深度残差网络)和BERT等。ResNet的提出是CNN(卷积神经网络)图像史上的一件里程碑事件,BERT是史上最强的NLP模型之一,但却也最耗时间。
下面主要针对这两种模型对Graphcore、Intel、NVIDIA的对应硬件的性能进行综合比较,本文将主要对Graphcore Bow Pod 与NVIDIA A100的性能进行分析。需要详细了解AI模型算法可以关注我们或者联系作者(微信同名)。
三大AI硬件性能比较
先看具体数据:
 图表分析如下:
图表分析如下:
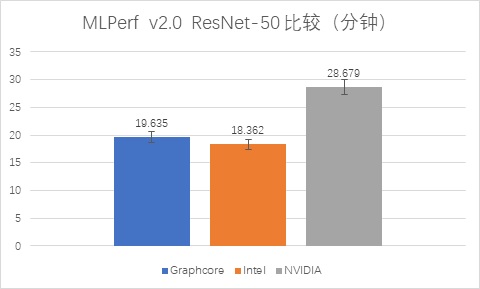
完成ResNet-50模型的运算,
NVIDIA的A100耗时28.679分;
Graphcore的Bow Pod16耗时19.635分,相比A100快了31.53%;
Intel的Habana Gaudi2耗时18.362分,比A100快了35.97%,比Graphcore的Bow Pod16稍快。

完成BERT模型的运算,
NVIDIA的A100耗时24.185分;
Graphcore的Bow Pod16耗时20.654分,相比A100快了14.60%;
Intel的Habana Gaudi2耗时17.209分,比A100快了28.84%。
在以上两种模型运算中,Intel最快,NVIDIA最慢。
如果用大尺度计算平台,比如8台DGX-A100和Bow Pod256相比,性能对比约为6x比10x,而Bow Pod的价格远远低于DGX-A100,甚至低到只有A100的1/8。

来源:Graphcore
Intel HLS-Gaudi2在本次MLPerf v2.0测试中提交的性能表现不错,但目前还未公布价格,但按照Intel以往的策略,比A100稍微便宜,比Graphcore要贵(较多)。
因此,从性价比来看,Graphcore是最好的,相对A100,无论是性能还是价格都更优。
在当前科技行业,一个AI应用模型的训练费用动辄数百万甚至数千万,性价比显得尤为重要。下面,我们主要分析Graphcore的Bow Pod系列硬件性能出众的原因,以及其生态发展情况。
性能超过30%的原因分析
为什么Graphcore的硬件在这种能够标称AI运算能力的测试中胜出,甚至比A100超过30%?笔者了解到,主要有以下三个方面:
3D芯片封装技术
2022年3月,Graphcore发布了一款IPU产品Bow,采用台积电7纳米的3D封装技术。这款处理器将计算机训练神经网络的速度提升40%,同时能耗比提升了16%。

能够有如此大的性能的全面提升,主要得益于台积电的3D WoW硅晶圆堆叠技术。
在台积电3D封装技术的加持下,Bow IPU单个封装中的晶体管数量达到了前所未有的新高度:超过600亿。
官方介绍称,Bow IPU的变化主要体现在这颗芯片采用3D封装,晶体管的规模有所增加,算力和吞吐量均得到提升,Bow每秒可以执行350万亿flop的混合精度AI运算,是上一代产品的1.4倍,吞吐量从47.5TB提高到了65TB。
Graphcore首席技术官和联合创始人Simon Knowles将其称为当今世界上性能最高的AI处理器。
软件优化
在软件上,我们发现Graphcore进行了很多优化,在通信库、内存、编译器等方面进行了非常多的性能提升,使得整个local batch size有了很大的提升,整个吞吐量在软件的优化下,大概实现了1.2-1.3倍。
模型优化
同时,在模型层面Graphcore对整个训练过程进行了一些优化。比如在训练过程中有一些训练迭代,迭代之后要做验证来看精度是多少,这个验证过程不会提高训练精度,但会消耗训练资源,Graphcore优化了验证的过程,提高了验证效率,从而使得它的计算效率提高了。
芯片3D封装技术,软件和模型的优化,使得Graphcore的Bow Pod的性能比NVIDIA的A100提高了超过30%。
基于芯片硬件底层和AI上层架构的生态
在此次提交的测试中,我们发现Graphcore与百度同时提交了基于Bow Pod的硬件测试。Graphcore与百度飞桨联合提交的结果显示性能也一样非常出众。
Graphcore采用的是其自研框架PopART,这是一个基于芯片所构造的高效的训练推理引擎。而百度采用的是百度飞桨架构。
百度飞桨使用Bow Pod16和Bow Pod64进行了BERT在封闭分区的提交,结果与Graphcore使用PopART进行提交的结果几乎一致。

数据来源:Graphcore和MLCommons官方
这说明了Graphcore的软件栈非常成熟,能够快速对接新的AI框架。另一方面,也说明百度飞桨的框架非常高效,没有任何性能侵入式的设计(性能损失)。
延展开来,也体现了Graphcore在其基于芯片硬件底层和上层AI架构方面的良好生态。特别是国内与百度飞桨基于芯片硬件和架构及模型的深入合作。
Graphcore的PopART架构
PopART是Graphcore自研的训练推理框架,它是非常底层的一个AI框架。依托于PopART,可以往上支持不同的训练框架,譬如PyTorch、百度飞桨,以及其他未来的一些AI框架等等。
“比起直接使用PopART,我们更希望让其他框架在IR层和PopART进行对接,它是一个更底层的框架。”Graphcore中国工程副总裁、AI算法科学家金琛曾这样表示。
百度飞桨架构
在国内,AI研发最早、技术出众的当属百度。百度在深度学习技术领域中,是比较早地应用该技术的企业,据报道,2012年百度便已经把深度学习技术用于百度内部的业务,像我们经常用到的百度搜索、百度机器翻译等等,在2012年前后,就已经进行了数据同步。基于百度内部自研的需要,百度在2014年前后开始在自研社区搭建框架,并且在2016年把这个框架进行开源,这就是百度飞桨。
2017年前后,百度在发改委的支持下,成立了目前国内唯一的深度学习技术及应用国家工程实验室,2020年,升级为深度学习技术及应用国家工程研究中心。
经过几年的推广,目前百度飞桨已经进入相对稳定的发展节奏,每2-3年发布一个大版本,半年发布一个小版本。
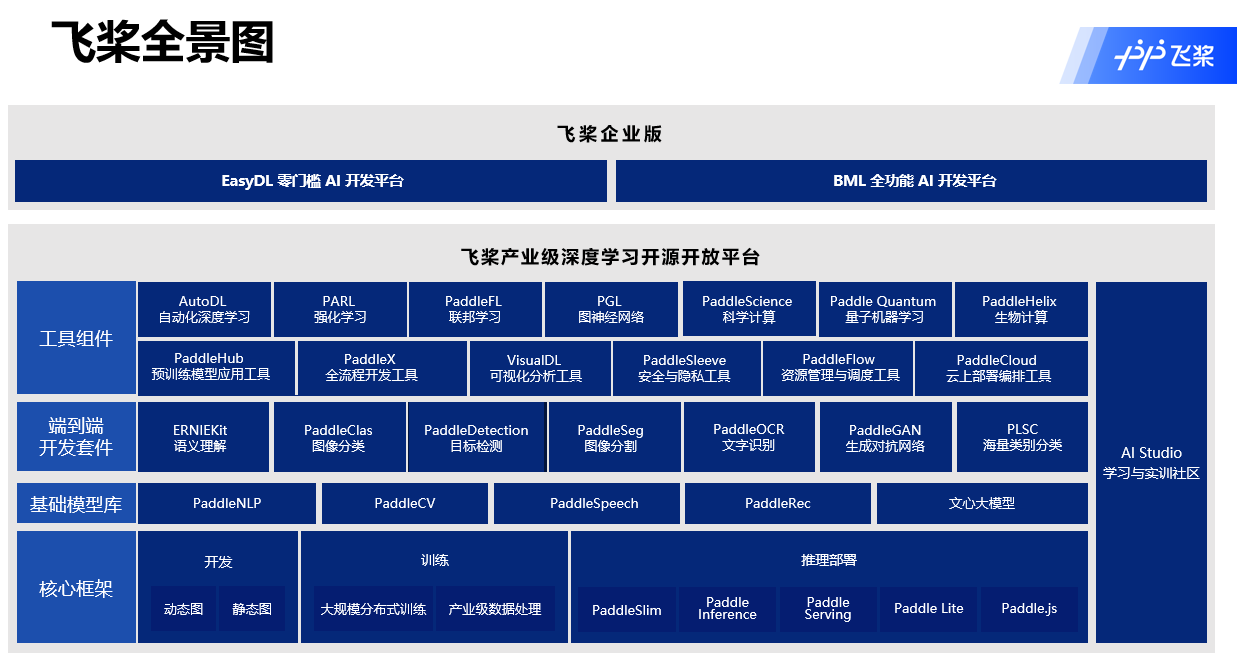
百度飞桨架构
百度飞桨整个产品栈,最底层是核心框架,是用来实现AI应用开发核心的开发训练以及部署功能的底层核心框架。除了框架要做的动态图、动静转换等高性能工作之外,在硬件合作方面,目前在全球的三大框架内,百度飞桨是唯一一个在积极地接收各家厂商代码的框架,并且建立完备的CI和CE的技术栈,来确保所有硬件合作伙伴的代码能跟着百度飞桨的主干代码进行升级,TensorFlow和PyTorch目前是只有一条A类型代码。
除了底层的核心框架以外,百度飞桨作为一个深耕产业级应用的平台,在上层的技术模型库和以模型为特色的一些领域的端到端开发套件上,采取了和其他框架不太一样的发展路线。除了经典的深度学习应用工具以外,在强化学习、图神经网络,包括目前受到很多关注的AI for Science等方向,百度也有很多的开源工具提供给科研以及企业内的开发者使用。
基于百度希望通过和硬件合作伙伴一起推动AI软件技术栈的升级的思路,Graphcore与百度达成了深度合作,达到了性能几乎无损失的AI软硬件结合。
Graphcore与百度飞桨的深度合作
Graphcore与百度飞桨的合作主要有两个方面。
第一,在整个硬件适配的过程中,Graphcore与百度相互合作和启发,形成了很多新的思路,下图展示了百度飞桨对接硬件厂商的适配统一方案。
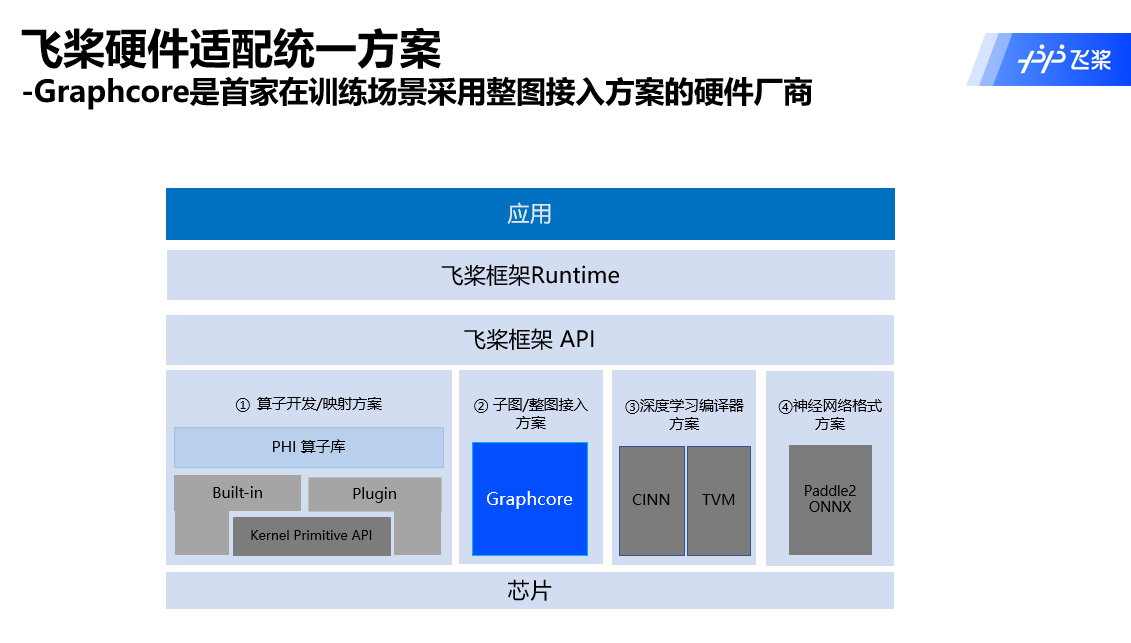
百度早期的方案主要是进行类似算子开发、映射的工作,主要对接包括像NVIDIA的CUDA或者AMD的ROCm这样的一些软件栈进行。由于这几年各类型的硬件厂商非常多,每个厂商采用不同的创新的软件栈来不断提升整个软件栈的开发效率以及性能,所以百度飞桨也在不断地更新,或者增加百度与硬件厂商对接的技术方案,包括已有的算子开发方案、深度学习编译器方案、神经网络格式方案。
Graphcore在与百度飞桨的合作过程中,提出了一个新的思路,就是以子图或者整图的方式,与硬件厂商做高效率对接。
最终的效果通过这次的MLPerf v2.0结果可以看到,无论是基于PopART的成绩还是基于百度飞桨的成绩,性能一致度非常高。在得到这个成果之前,百度飞桨花了半年多的时间在对框架进行改造,以整图的方式和厂商更好地对接,Graphcore也是首家在训练场景中和百度对接的硬件厂商,从结果看整个效果很好。
第二,百度本次也打开了在全球范围内首次双方共同提交的先例,这个过程中有很多技术上的合作,也在MLPerf的规则内收获了一些来自MLPerf整个组织的官方认可。
“这个过程中也有非常多的不确定性以及挑战。在与Graphcore合作的整个过程中,我们觉得,无论是Graphcore本地的工程、营销团队,还是国际团队,都非常崇尚技术,非常开放,并且抱有一个愿意紧密合作的态度,所以我们以很高的效率,大概一个季度多一点的时间就完成了整体的联合提交。”百度飞桨产品团队负责人赵乔表示。
“从2020年的百度飞桨的早期硬件生态圈,一直到2022年的硬件生态共创计划,Graphcore一直是百度非常重要的硬件厂商合作伙伴。目前我们和Graphcore在AI Ecosystem的共创方面还有很多新的方向。以技术为核心,百度飞桨会跟着Graphcore新的技术创新,在硬件的适配等方面不断提供一些共创的新思路,我们也会把核心技术的创新转变在产品化方面,无论是百度飞桨的软件栈,还是Graphcore的软件栈,或者是在Graphcore的模型花园里为开发者提供一些更偏应用层面的开发工具,我们将基于这些内容在生态方面开展合作,并在百度的内部以及国内其他的行业,落地产业开展真实应用。此外,我们与Graphcore也计划在AI Studio上后续开设Graphcore的硬件应用专区,基于这个平台更好地共同拓展与国内开发者,甚至国际开发者合作的边界,繁荣整个AI开发者社区。”赵乔曾这样高度肯定与Graphcore的合作。
结语
当前科技行业,一个AI应用模型的训练费用动辄数百万甚至数千万,而未来科技的发展速度也越来越依赖AI技术对计算和分析的加速,同样的模型,花更少的成本以更快的速度完成训练和计算显得非常重要,因此,AI硬件的性价比显得尤为重要。
同时,基于芯片和硬件底层和上层应用的生态完善也将成为未来AI应用致胜的关键一环。
如Graphcore、Intel一样,越来越多的芯片和硬件厂商已经或将逐渐超越以往NVIDIA A100这个曾经的王者。
下一篇,我们将对Intel HLS-Gaudi2与NVIDIA A100的性能进行PK分析,感兴趣者可以关注我们或者联系作者。
8月16-17日,#IIC Shanghai 2022将在上海国际会议中心举行!
聚焦#IC 设计、SoC设计、#碳中和 、元宇宙/AR/VR、物联网、新能源汽车和自动驾驶、智能家居/家电、新能源发电与传输、汽车电动化、第三代半导体、东数西算等行业热点。
会议上有来自安谋科技、ADI、Cadence、英飞凌、纳芯微、极海、沐曦、思特威、合见工软、智芯微、京东方、Imagination、PI等国内外领先厂商的100多位重磅嘉宾及行业先锋在大会上发表创新演讲。
现场惊喜好礼等你来 ~席位有限,立即报名请戳:https://aspencore.mike-x.com/ViZFZN5
