
Arm高级副总裁兼终端事业部总经理Paul Williamson说,今年Arm通过新的扩展CPU集群,来应对市场对性能和效率的新需求。新的CPU设计旨在提升峰值性能,并提供出色的持续性能和效率。据称,TCS22 的 Arm IP 组合可在一系列工作负载中实现28%的性能提升,以及16%的能耗降低。
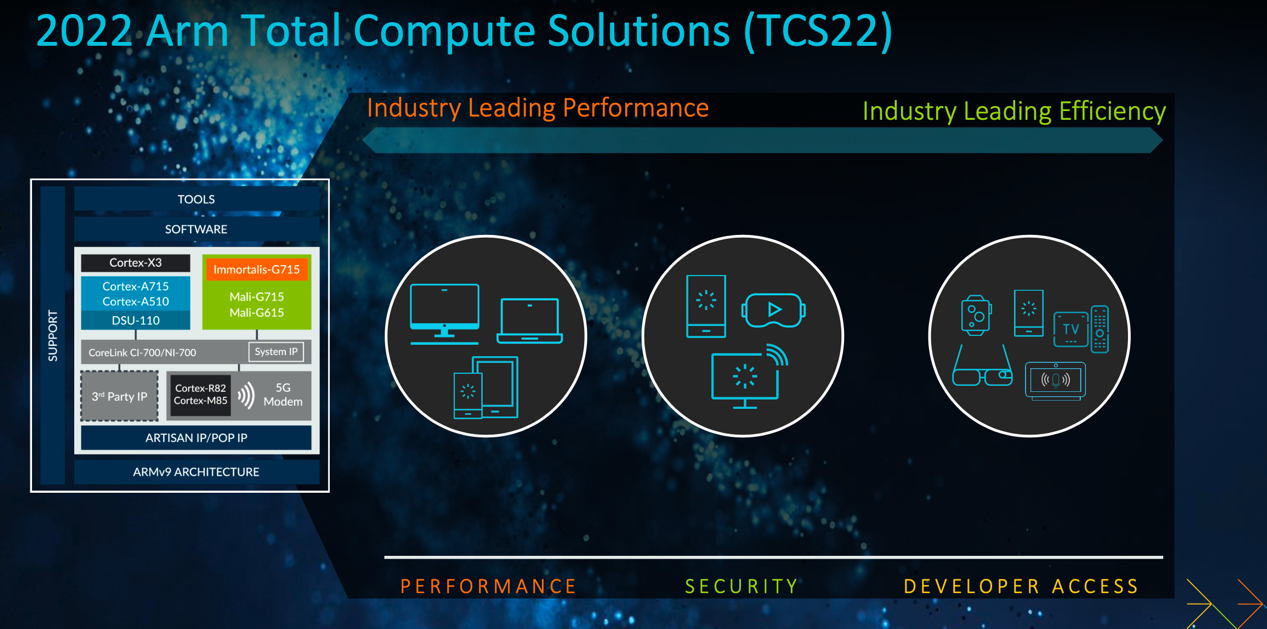
Armv9 CPU家族再度上新
新的Arm Cortex-X3可面向广泛的基准和应用市场,与最新款的安卓旗舰智能手机和最新的主流笔记本电脑相比,其性能分别提升了25%和34%。

Arm Cortex-A715专注于高效性能,与Cortex-A710相比,其能效提升了20%,且性能提升了5%,达到了可媲美Cortex-X1性能的重要里程碑。考虑到高效性能的重要性,Cortex-A715的CPU集群采用了基于大小核(big.LITTLE)的配置,这也是目前全球消费级设备最常用的异构处理架构。
基于Armv9架构的Arm Cortex-A510在2021年推出,这是Arm四年来推出的首款高效小核。今年的更新版本在保持性能不变的同时,将功耗降低了5%。同时,与去年的上一代产品相比,更新版的DSU-110所支持的CPU集群内核数增加了50%,实现了不同等级消费级设备的可扩展性。

Arm史上性能最强GPU问世
移动设备的创新推动了移动游戏的迅猛发展,视觉效果出色的AAA游戏的兴起也要求相互匹配的性能表现,从而又推动了相关硬件平台的升级。
全新旗舰级GPU产品Immortalis在Mali技术积淀的基础上进行了配置和增强,具备基于硬件的光线追踪功能,旨在为安卓游戏生态系统提供更好的移动3D体验。特别值得关注的是,Arm的光线追踪单元专为效率而打造,只占用了约4%的着色器核心面积,且仅耗费非常小幅的功耗,却能在相关领域带来300%的显著性能提升。
另外两款高端GPU产品,Arm Mali-G715 GPU提供所有新款GPU都具备的可变速率着色(Variable Rate Shading)图形功能,能够显著降低能耗,并进一步提升游戏性能;Mali-G615则将为更广大的开发者和消费者更快地带来高端的移动应用场景、功能和特性。

与前一代产品相比,最新的Arm GPU在性能和能效方面均提升了15%,可提供更长的游戏时间。同时,它们还将提供2倍的机器学习能力,以实现更多的智能应用和更出色的用户体验,是迄今为止Arm性能最强的 GPU。
“Mali-G715和Mali-G615将提供比去年旗舰级GPU更高的性能,天玑9000已在游戏中展现出了领先性能,正在用更丰富、更深入的视觉效果来推动性能的极限。” Paul Williamson说。
迄今为止,Arm Mali GPU出货量已超过80亿颗,Arm架构正成为移动游戏的基石。Paul Williamson指出,性能效率是将视觉体验应用到各处的关键,而今天,实时3D 游戏是主要的驱动力。如果要将游戏应用从智能手机转移到AR/VR等其他领域,则需要游戏世界的开发者和创作者将他们的经验应用其中。因此,Arm一直与Unity等伙伴合作,致力于通过最新的IP,为开发者带来基于Arm架构的终极视觉体验。

以游戏为例,这是一项系统级别的工作负载,重要的是衡量系统相关的指标,而非个别IP。在一个游戏示例中,通过基于8核CPU集群进行测量,在DSU上共享 8MB L3 缓存,并运行于安卓S的软件栈。在2022全面计算解决方案中,可以看到高达23%的DRAM带宽减少,显著改善了缓存大小与游戏工作负载,同时改善了效率并最终延长游戏性能续航。
与2021全面计算解决方案相比,系统能耗减少了16%。这一重大提升,将为百万级移动游戏开发者带来进一步的持续游戏性能表现。并且,最终在不同工作负载中的测试,性能可显著提高28%,这些都是来自于系统层级优化的结果。

总体而言,Arm全面计算是面向系统范围的方法,其中包括所有囊括在内的Arm产品,从而进行全面优化设计。针对具体用例,Arm会对其工作负载以及它本身的局限性进行深入了解。也就是说,对方案中涉及的Arm产品(包括编译器、IP、开发人员的工具等)进行优化时,就能确保所建模的工作负载能够在实际性能中实现。这一方法在于理解每个应用都有其独特的需求。只有对系统上的各项组件进行优化,才能实现最佳性能。
移动计算生态全面进入64位时代
Paul Williamson认为,不仅是游戏,所有应用都应该尽快过渡到64位。中国市场在这方面已经取得了良好进展——主要的应用商店已表明,到今年8月,所有新上架的应用都是64位的。他补充说,事实上,64位应用能够为用户带来更好的体验,比如在应用启动时间方面能够加快20%,任何没有过渡到64位的应用都会因为性能上的欠佳,让用户感到失望。
为此,Arm 2022全面计算解决方案提出了三项原则:
首先是性能方面,如果用户对性能有高要求,Arm倡导需要迅速过渡到64位。如果说过去开发者对64位生态系统的就绪程度还有一些犹豫不决,那么随着近期OPPO、vivo 和小米等公司参与的中国金标联盟的宣布,中国的计算生态系统和应用生态系统已全面就绪64位。这意味着,未来几年的旗舰级智能手机都需保证为全64位设计,以确保获得更好的效率和更强的性能。

其次是开发者的可及性方面,最新的IP在机器学习性能方面进行了更新或提升,为了确保开发者能够获得这些性能,Arm将持续致力于Arm计算库和Arm NN框架,以确保开发者能访问这些性能。无论是在GPU中的矩阵乘法的改善,还是系统级优化和设计中其他地方的缓存微调中,Arm NN和Arm计算库让开发者能获取这些性能。
最后是安全性。Arm一直在加强处理内的安全性,已经推出了非对称内存标签扩展,这被认为是去年推出的同步MTE和异步MTE的结合。Arm还将这些保护措施扩展到设计中较小的可信执行环境中,这也是系统执行软件栈中可能最具安全意识的组件,例如人脸解锁和面部识别功能,需要确保免受额外的恶意攻击。在新一代产品,Arm将这些安全增强引入设备的可信执行环境中,安全功能将在这个环境中运行。
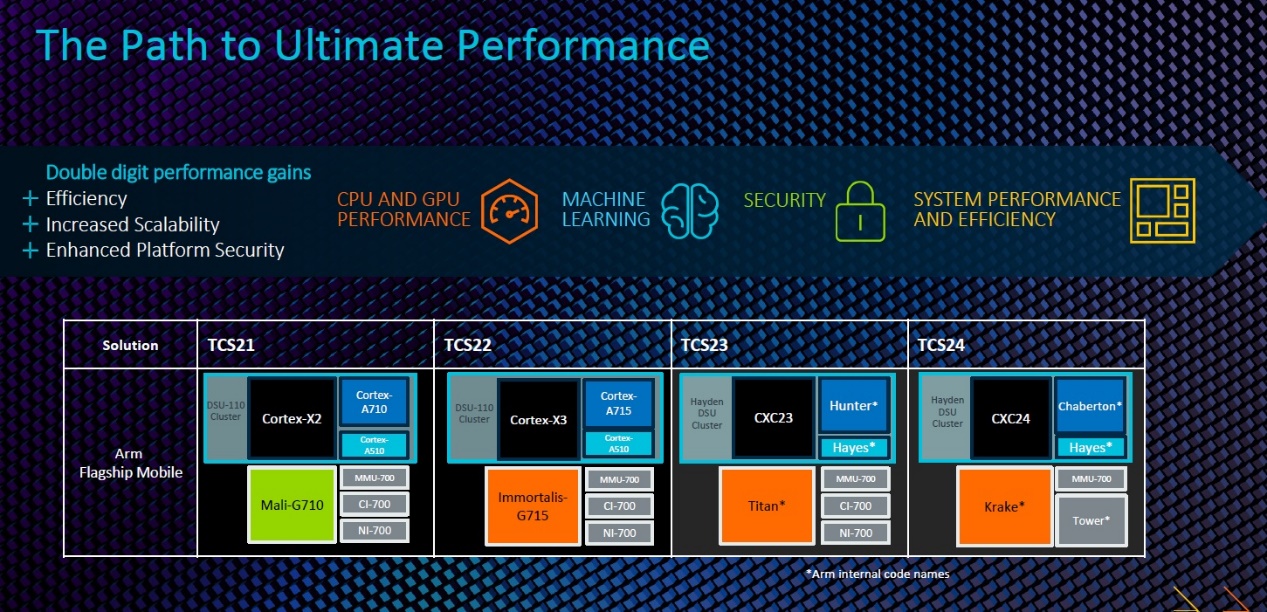
Paul Williamson还在最后透露了Arm未来的产品路线图。如上图所示,在大核CPU产品线中出现了新的项目:Hunter和 Chaberton;GPU产品线中则出现了Titan和Krake两个项目。同时,Arm也正投资于系统IP和安全性的增强,前者将确保低延迟的内存路径和系统级缓存性能,从而推动现实世界的持续性能以及综合基准的提升;后者,例如增加对隔离和虚拟化的支持,这将与安卓系统的的pKVM倡议保持一致。

