
在本文中,我将讨论用于构建机器学习模型的著名机器学习算法。每当您尝试从数据中提取信息、编写代码来预测事物或尝试从数据中找到推理时,您都会发现这些算法的用法。这也是为面试和考试准备提供基本 的ML 算法。
1. 线性回归与逻辑回归
线性回归是一种预测统计方法,用于对因变量与给定的一组自变量之间的关系进行建模。
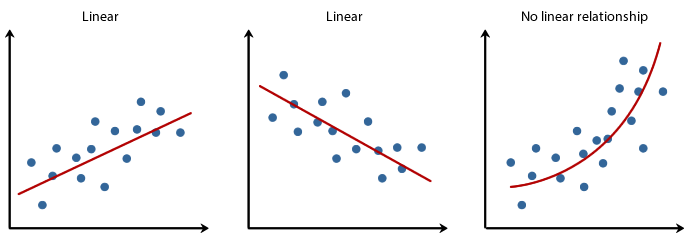
线性和非线性关系
它是一种对因变量与一个或多个自变量之间的关系进行建模的线性方法。当我们只有一个自变量时,它被称为简单线性回归。对于多个自变量,该过程称为多元线性回归。
逻辑回归
逻辑回归是一种广泛用于分类的监督学习算法。它用于在给定一组自变量的情况下预测二元结果(1/ 0、是/否、真/假)。为了表示二元/分类结果,我们使用虚拟变量。
逻辑回归使用方程作为表示,非常类似于线性回归。它与线性回归没有太大区别,只是Sigmoid 函数正在拟合线性回归方程。
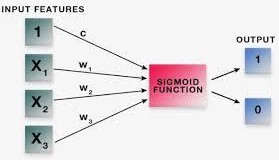
逻辑回归
线性回归的优点:
它不对特征空间中的类分布做出任何假设。
轻松扩展到多个类(多项回归)。
类预测的自然概率视图。
快速训练并且非常快速地对未知记录进行分类。
对于许多简单的数据集具有良好的准确性。
抗过拟合。
逻辑回归的缺点:
它不能处理连续变量。
如果自变量与目标变量不相关,则逻辑回归不起作用。
需要大样本量才能获得稳定的结果。
2. 支持向量机 (SVM)
支持向量机 (SVM) 是一组用于分类、回归和异常值检测的监督学习方法。
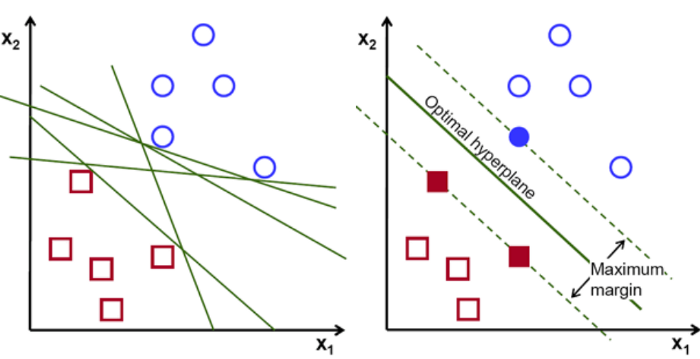
支持向量机 (SVM)
SVM 的优点包括:
他们最大化决策边界的边距
他们可以处理大型特征空间。
SVM 可以很好地处理半结构化和非结构化数据。
他们可以使用内核技巧的概念来解决任何复杂的问题。
SVM 的缺点包括:
当类的数量超过 2 时,SVM 可能难以实现。
SVM 需要很长时间进行训练,并且它们对噪声很敏感。
在 SVM 中选择一个好的核函数并不容易,需要大量的测试。
像gamma 和 cost-C 这样的超参数不容易微调。
3. K-最近邻(KNN)
K-最近邻是一种监督机器学习算法,可用于分类和回归。它没有对基础数据分布模式做出假设。
KNN 中的对象分类是根据其最近的 K 个邻居的多次投票进行的,其中 K 可以是任何小的正整数。该算法在训练步骤中急切地学习。它可以预测一个新点是否会落入给定的集群。
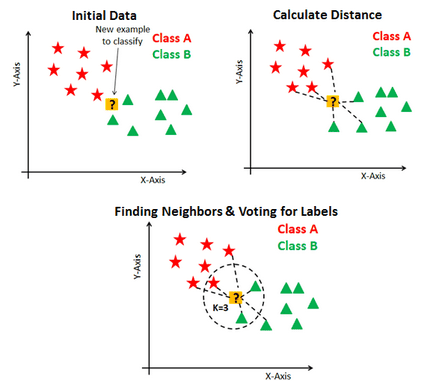
应用 KNN 算法的步骤
应用 K-Nearest Neighbors 算法的步骤:
为 K(奇数)选择一个值
选择一个需要分类的样本数据点并计算到它的 n 个训练样本的距离。
对距离进行排序并取 K 个最接近的样本。
将样本数据点分配给拥有其 K 个邻居多数票的类。
KNN 算法的缺点:
KNN 在计算上很昂贵,因为它在预测阶段搜索最近的邻居来寻找新点。KNN 的内存要求很高。对异常值敏感,准确性会受到噪声或不相关数据的影响。
后面的三大算法的优缺点请关注我们或者联系作者(微信同名)。
