
科技界论文是新技术生产力的源泉之一。虽然现在已经2022年了,但论文的影响力和应用一般都有所延迟,因此本文介绍2021年最顶级的的深度学习论文。
剪辑
视觉+语言学习是一种趋势,这方面最顶级的论文是一篇OpenIA论文,它使图像识别任务更容易扩展,因为它不需要耗时的ImageNet人工标注。它从原始文本中学习,而不是手动定义标签,在几个著名的数据集中归档了State Of The Art结果。
这是一个新的学习概念吗?不是,但却是到目前为止最雄心勃勃的一个。他们收集了一个由4亿个图像+文本对组成的数据集来训练艺术状态模型:修改后的Transformer架构用于文本编码,几个ResNet-50、ResNet-101、EfficientNet和Vision Transformers(都经过修改)用于图像编码。其中表现最好的是Vision Transformer ViT-L/14。
它是如何工作的?很简单。对比性学习。一个众所周知的零点学习和自我监督学习的技术。给出一对图像及其文字描述,把它们放近。给出一对有错误文字描述的图像,就把它们放得远远的。这样,当用一句话来查询一张图片时,离得近的就是 "更正确 "的。
N张图像及其N个文本描述分别用图像和文本编码器进行编码,因此它们被映射到一个低维的特征空间。接下来,使用另一个映射,一个简单的线性投影映射,从这些特征空间到一个混合的特征空间,称为多模式嵌入空间,在那里他们通过余弦相似度(越接近越相似),使用正+负对的对比学习进行比较。
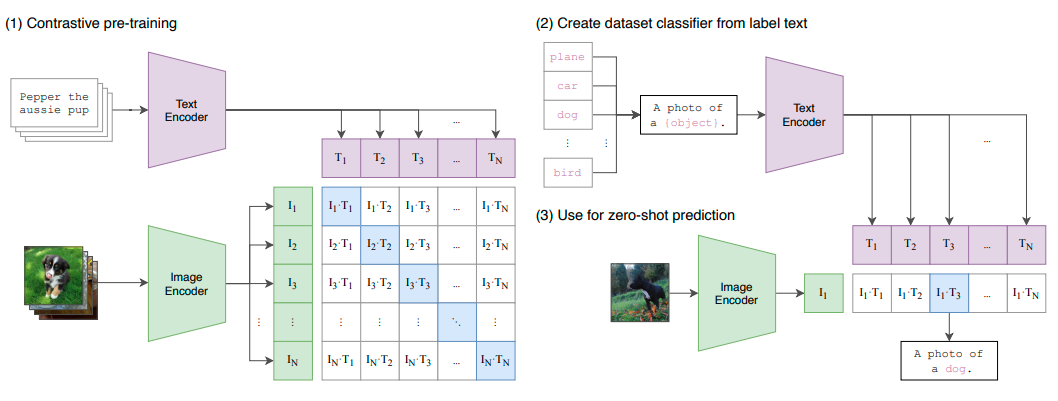
CLIP的方法
CLIP能够解决对同一图像使用多种文本表示法的问题,多义性,并且在一些最著名的数据集,如ImageNet,CIFAR和Pascal VOC上优于State Of The Art(而在其他如MNIST,Flowers102,KITTI Distance上表现不如SOTA)。另外,由于它使用的是对比学习,所以它是一个零点学习器,可以比以前的零点学习模型更好地泛化到未见过的物体类别。
扩散模型
说实话,我们都讨厌GANs。他们有一个非常不稳定的学习,需要大量的时间进行微调,而该死的NVIDIA在GitHub上的StyleGAN的实现,它的使用是一些令人愤怒的废话。现在我们都坦白了我们的秘密,我们几乎可以肯定地说,如果有人听到GANs不再是图像生成和翻译的最先进技术,没有人会哭。
你是在说VQ-VAEs吗?不,不是。生成流?不是的。我说的是扩散博士或。我如何学会停止担心并爱上噪音。
我们可以取一个可爱的狗的图像,并在其中加入一些噪音,我们仍然可以完美地看到狗,所以让我们加入更多一点,更多,更多,直到最初的狗图像无法识别,你看到的只是随机噪音。好吧,如果一个非常有艺术性的人见证了所有一步步添加噪音的过程,艺术家将能够在每一个时间步骤中恢复这个过程,这样就可以再次恢复最初的狗。耶,狗哥回来了!
