
2021年7月27日,全球领先的专业电子机构媒体Aspencore与深圳市新一代信息通信产业集群联合主办“2021国际AIoT生态发展大会”。在智慧能源分论坛上,百度ACG AI产品研发部高级研发工程师傅雨东先生介绍了智慧能源中的边缘部署适配与加速解决方案。

根据百度过往合作的经验来看,目前定制化AI的需求其实不止在能源方面,从科研机构、工业,一直到农业等各个方面都有定制化AI模型的需求,下面是几个例子:

1、生产安全行为识别:检测生产车间内的安全作业情况,比如在机器运转过程当中是否有工作人员误入机器的运转范围,或者是工作人员操作搅盘时,他和搅盘之间的是否为安全距离。
2、加油站风险识别:针对加油站中的危险行为,比如玩手机、打电话、吸烟等不安全行为进行检测。
3、能源相关案例:佛山供电局输电管理所针对电网附近大型机车做检测,如果发现电网附近有机车就会通过微信自动推送警告的通知。目前识别率是达到80%,目前还在以2-3周的更新频率不断的迭代优化识别率。
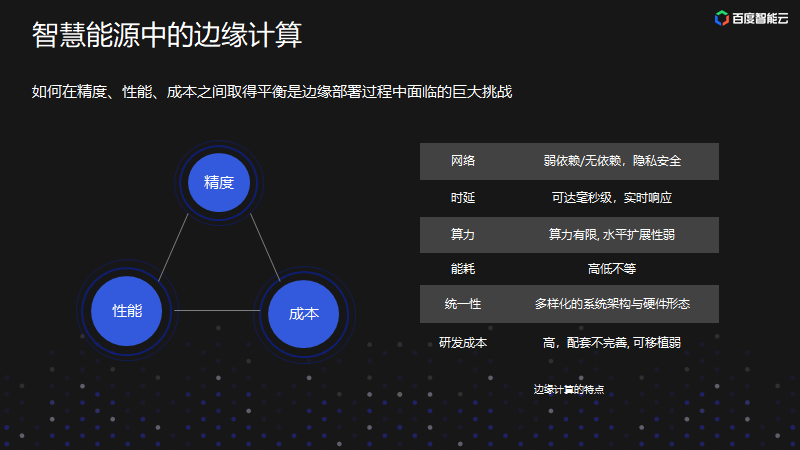
从上面几个案例总结边缘计算的三个特点:
1、首先是网络方面;之所以要把服务部署在边端而不是放在云服务器上,是因为用户对隐私有一定的要求,无需把数据传到云端,而是在边端处理,再进行结果返回。
2、对时延有较高要求;把图片或数据传到云端,网络开销很大。通常很多场景下,需要毫秒级的响应时延。
3、边缘计算实际运行的设备、系统架构、硬件形态是多样的;也正是因为这样,比如针对某一个设备做了适配,当把它移植到另一种硬件上时,往往是比较难移植的。因此,在边缘计算的过程当中,有一个巨大的挑战就是针对精度、性能和成本进行平衡。
总结起来就是下图:
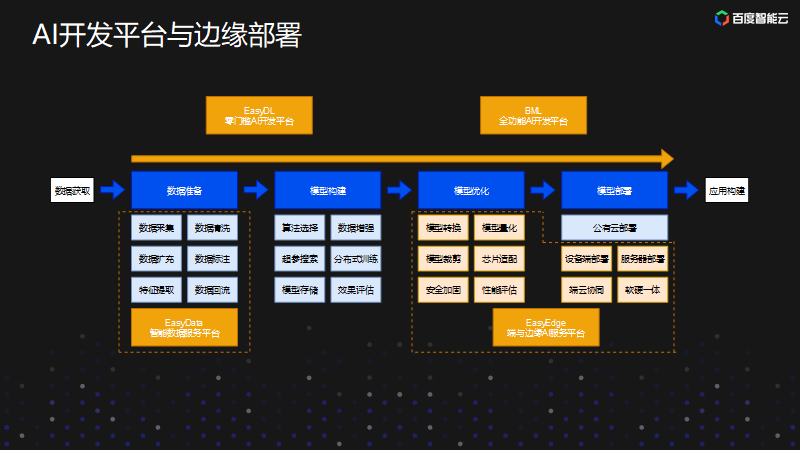
为了方便用户在精度、性能、成本三个方面取得平衡,我们有两大平台来给用户提供全套的解决方案。用户经过平台就能方便构建出自己的应用。整个平台可以分为数据准备、模型构建、模型优化和模型部署四大模块,本文主要针对模型优化和模型部署进行详细的介绍。
EasyEdge平台
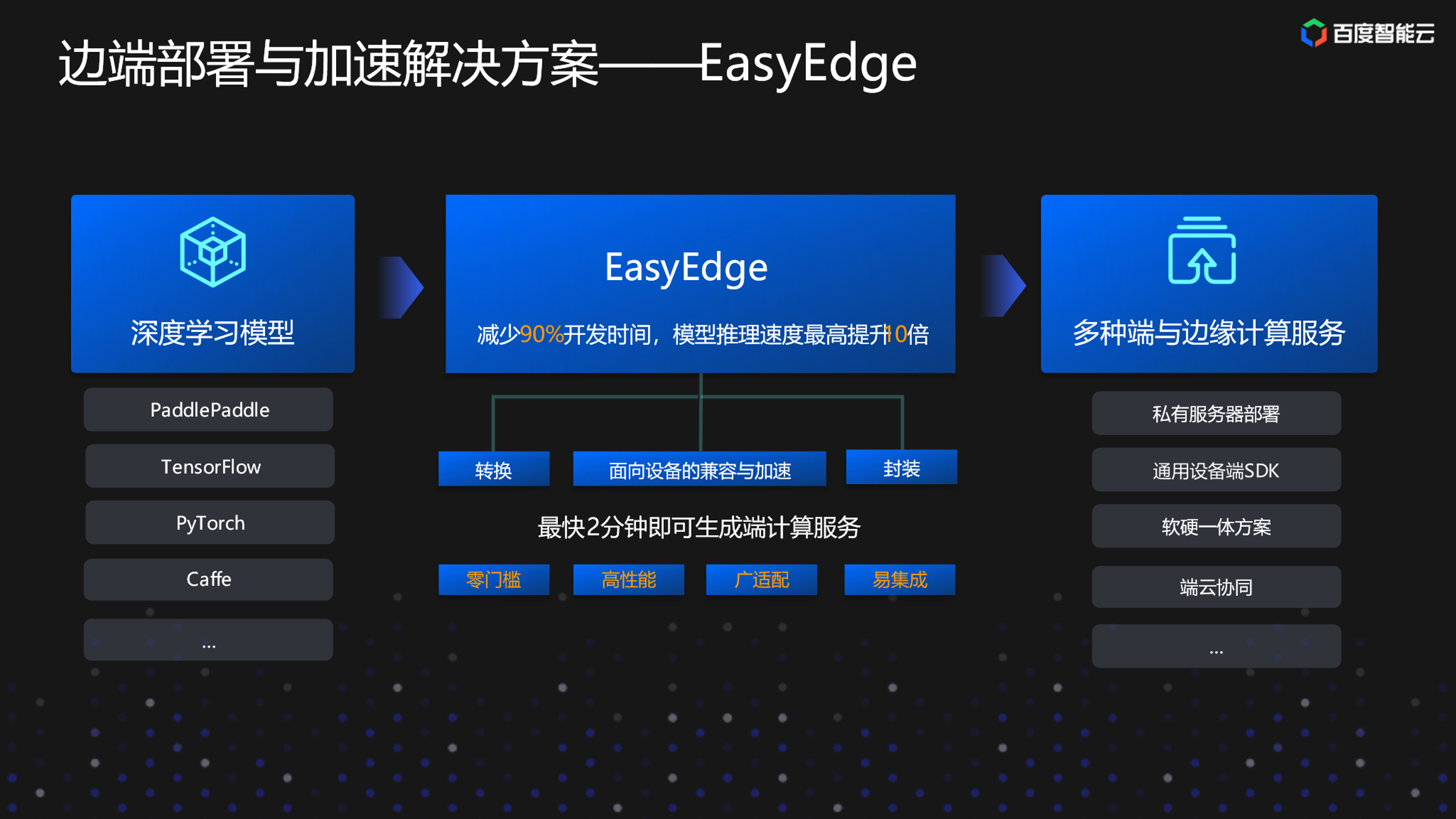
首先介绍一下EasyEdge平台,它帮助用户屏蔽模型转换、面向设备的兼容和加速、封装,最终直接转换为各种端与边缘计算供用户实际部署。

EasyEdge平台支持20余种芯片与硬件平台,4大主流操作系统,除了CPU和GPU两款主流的芯片之外,还有很多芯片,比如百度自研的昆仑芯片、华为的服务器等。

EasyEdge网络的支持如上图展示,上半部分是对于框架的支持。百度在框架上除支持飞桨,也支持其他框架。下半部分是EasyEdge支持的网络,可以看到涵盖了分类、检测、人脸等各方面,这里列出具体的网络是挑选了比较具有代表性,或者是具有实用价值的网络,但并不代表平台仅支持这些网络。因为对于网络的支持是从网络结构的各个OP来为角度支持的,有一些不在这个表上,但只要OP支持,整个网络都是可以支持的。
那么EasyEdge是怎么做到的呢?
EasyEdge技术架构
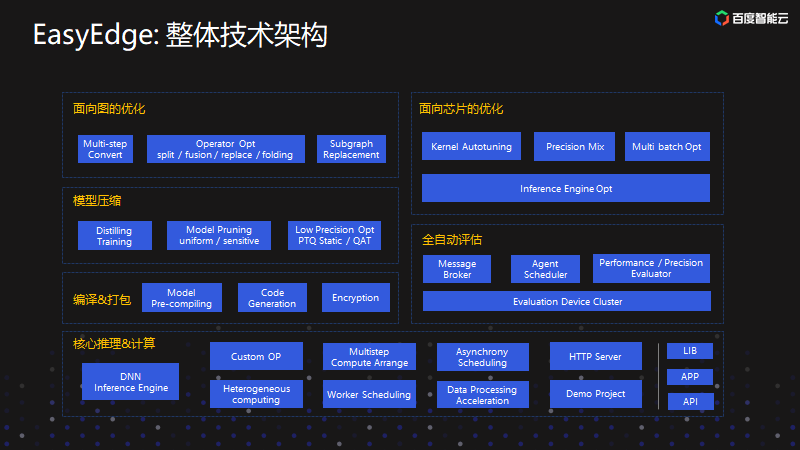
这幅图展现了EasyEdge平台的技术架构。EasyEdge平台分为面向图的优化、面向芯片的优化、编译打包和评估。面向图的优化主要是模型中的算子融合、裁剪等;面向芯片的优化主要包括针对特定的优化,比如最终想把服务部署在英伟达的GPU上,就把模型预处理工作放到GPU上;如果有一些在GPU上框架没有实现的算子,也会自定义算子,最后完成端到端的过程。模型压缩主要是包括量化、裁剪、蒸馏等,主要是把模型的体积降下来。当通过这几个优化得到模型之后,就会通过编译和打包模型来生成用户得到的开发套件。对于集成商,他们往往对于模型的安全性是有一定考量的。所以,这个平台集成了模型安全加固操作。除此之外,全自动评估模块是在实际模型打包的同时,把它下发到评估集群,然后可以得到这个模型实际的运行效率,以及消耗各项资源的指标。
推理计算图的优化
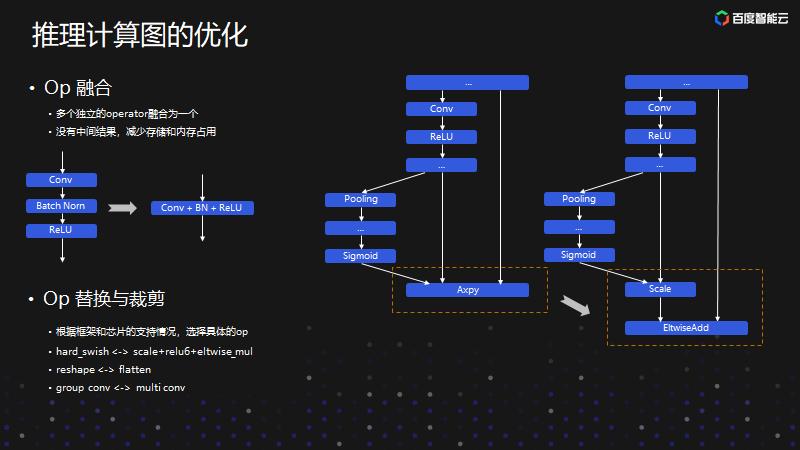
这是几个图优化的案例。首先是OP融合,把几个算子融合为一个算子,它可以减少中间的存储和内存占用。OP替换与裁剪,之所以要对OP进行替换和裁剪就是优秀算子只在某一些芯片上有,但是在另外一些芯片上没有。当我们支持各个不同芯片时,就要做算子的替换。比如说有的芯片不支持一些算子,就要用其他的方式做替换。

这是模型压缩的方案。内部是提供了包括训练后量化、量化训练、裁剪、蒸馏等多套智能的压缩方案。当然,用户在实际使用过程当中并不需要关心内部是基于哪套压缩方案来实现的,只需要关心加速是需要精度无损的加速,或者是精度微损的加速。但希望这个精度损失较少,或者是精度损失比较大也能接受,但它要尽可能快,用户就会选择不同的压缩方案,内部就会用具体的压缩方案来实现。

这是软硬一体的方案。百度和一些硬件厂商或者是自研的硬件做更深入的适配工作,目前软硬一体方案大致可以分为超高性能、高性能、低成本/小功耗大类,总共是6款硬件产品。
首先是自研的EdgeBoard计算盒,可以支持8路的视频流,通用性也是比较强的,它能支持主流的深度框架。

这是EdgeBoard开发套件。算力好,定制化能力更高,可支持定制化的设计。

这是Jetson开发套件。有三款,但算力不一样。下面的表格是列举三款硬件的推理性能。
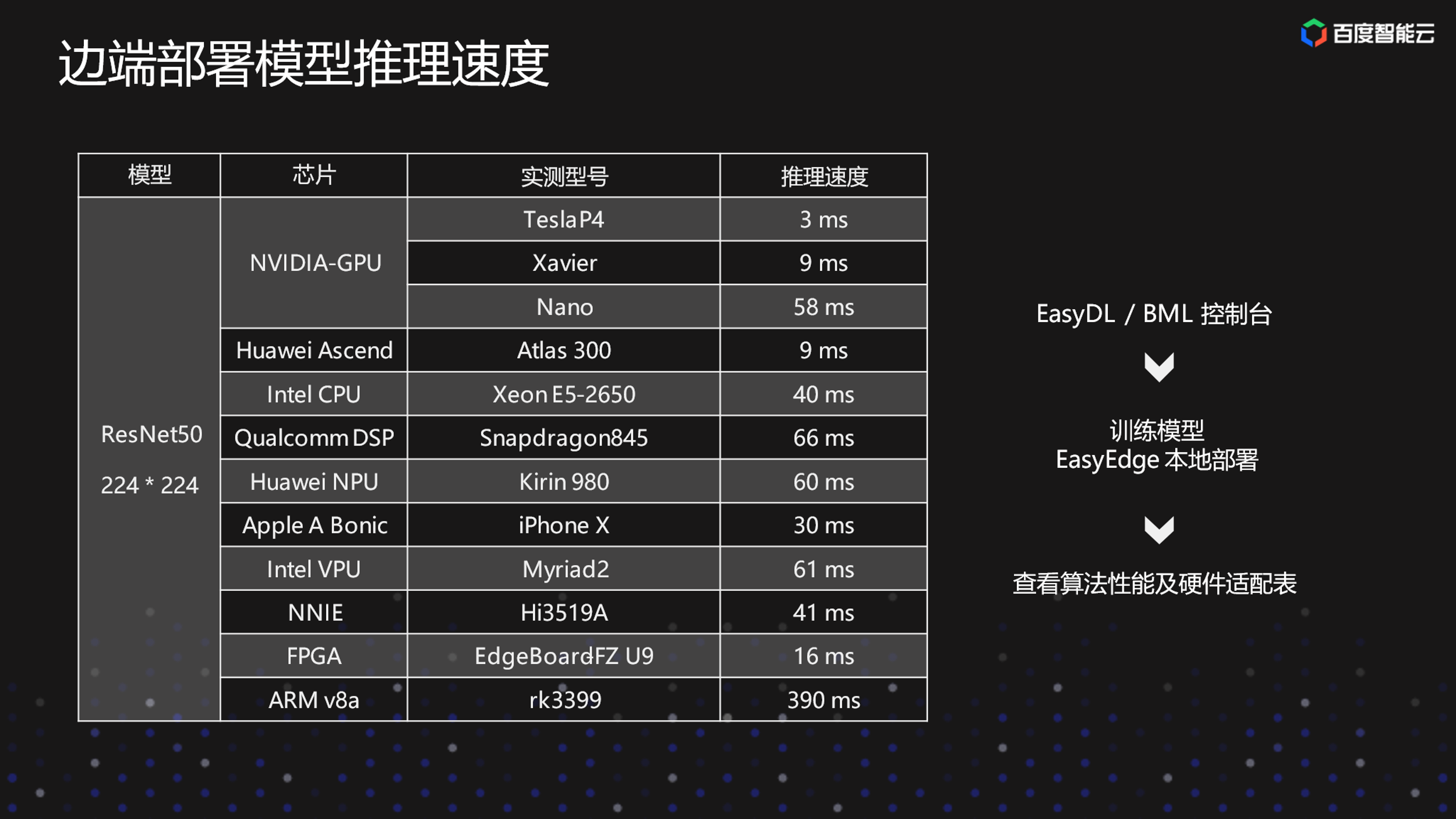
这是输入尺寸224×224的模型为例,列举各个芯片上的实际推理速度,右边是一个硬件适配表进入的流程。大家也可以在平台具体的硬件适配表上看到不同的模型,在不同硬件上大致推理速度,可以帮助大家在训练前就能对训练出来的模型性能有一个大致的了解。
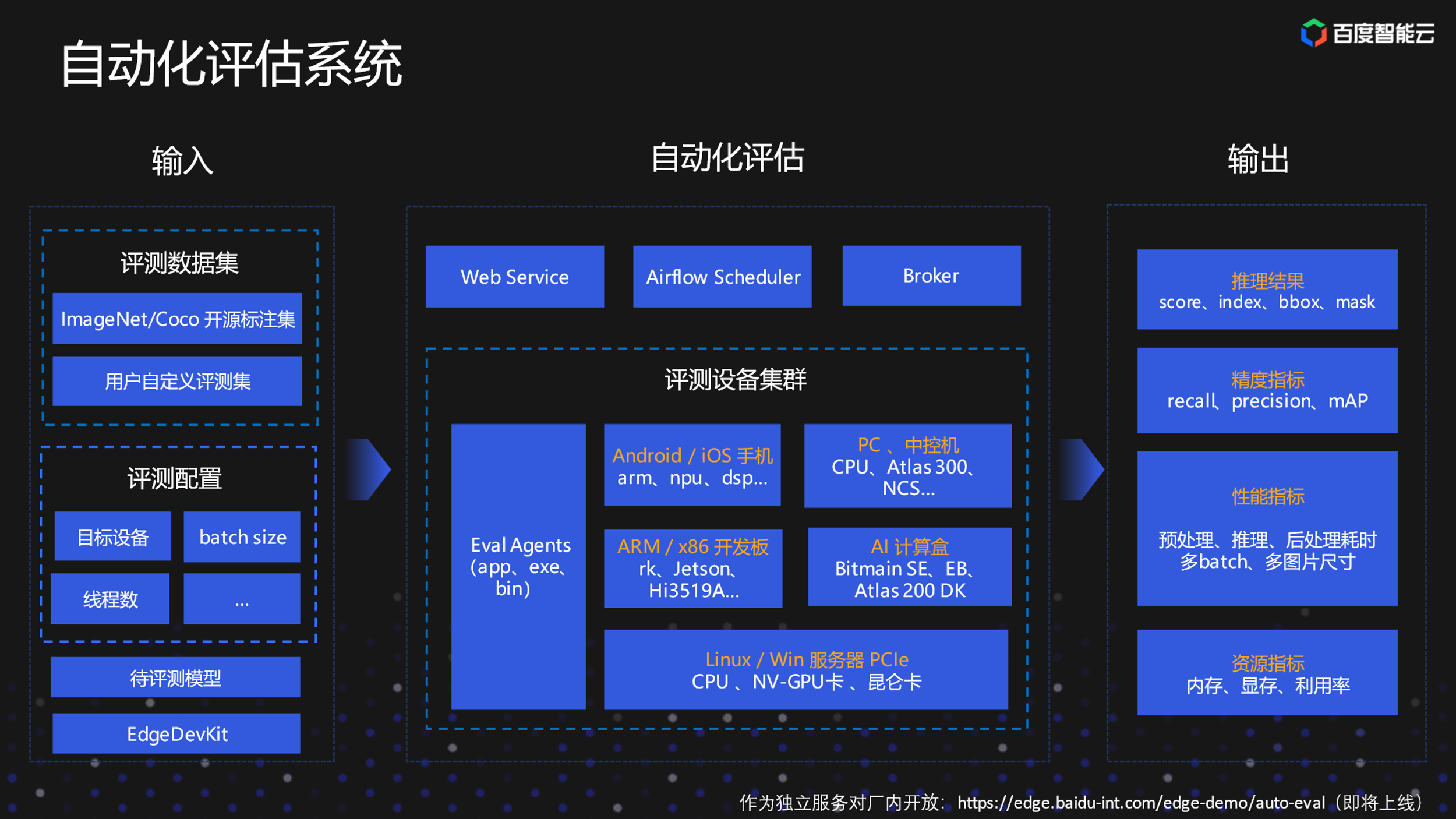
这是自动化评估系统。自动化评估系统输入是包括评测的数据级、评测的配置。比如说希望这个模型在哪个设备上评测,输出主要是这个模型在对应的硬件上的推理结果。另外是推理结果计算出来的精度的指标,以及一些性能的指标。比如说在这个硬件上,这个模型耗时多少等。还包括资源的指标,比如说这个模型在这款硬件上运行推理100张图,它需要消耗多少内存、多少显存。
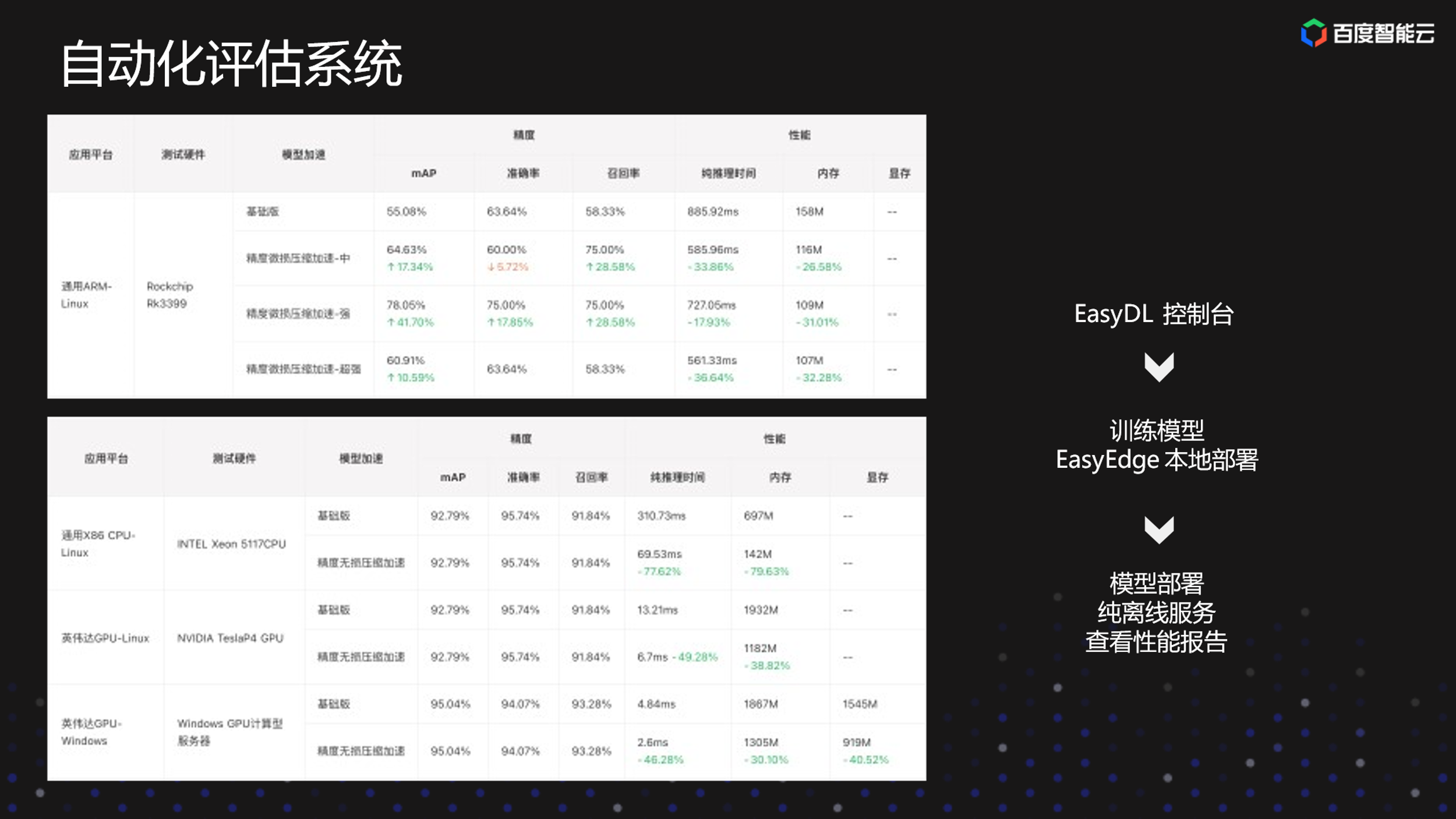
这是平台上最后产出的性能报告。主要展示在不同的应用平台和实际的测试应用上,针对用户选择不同模型加速的方案实际的模型精确度和推理性能,内存、显存消耗的展示对比,可以供用户在实际部署前,有一个大致的概念。用户可以看到在预算范围内,或者是在他可以接受的硬件上,哪一种方案更适合他。
端云协同部署方案
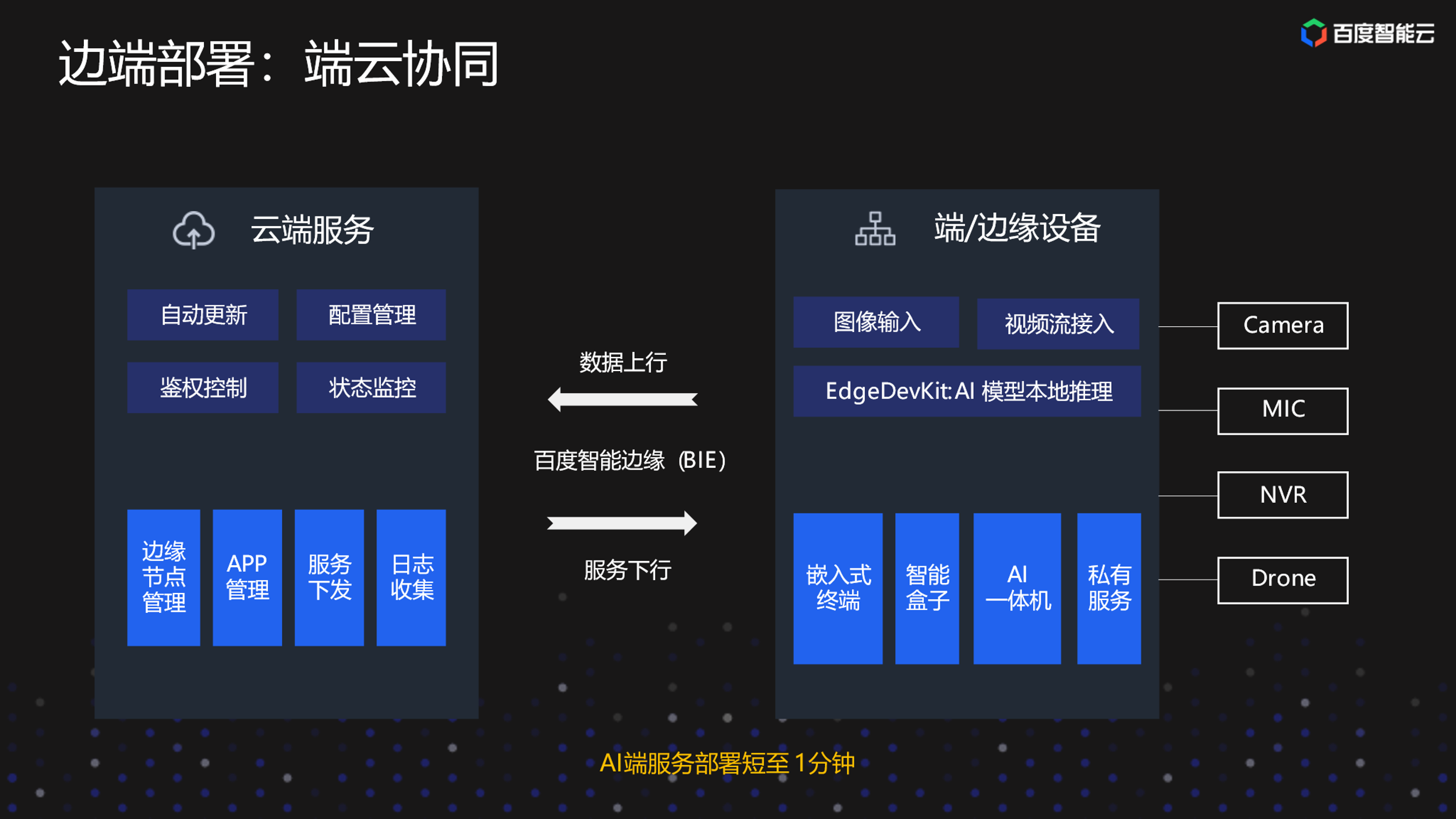
端云协同部署方案主要是解决设备管理和服务管理的痛点。在这种方案下,用户可以在云端管理边端设备以及可以在边端设备上管理要部署的服务,但实际的服务还是运行在端和边缘的设备上的。这样,用户就不需要手动每一台机器登录、启动服务、操作服务,上述动作都可在云端完成。通过这种服务部署方案,也可以极大的提升用户部署AI服务的效率。
