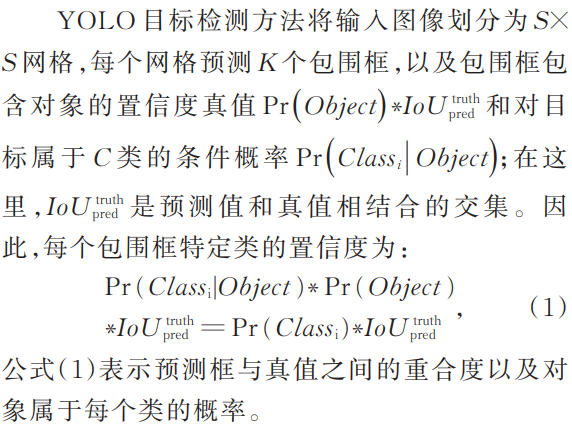
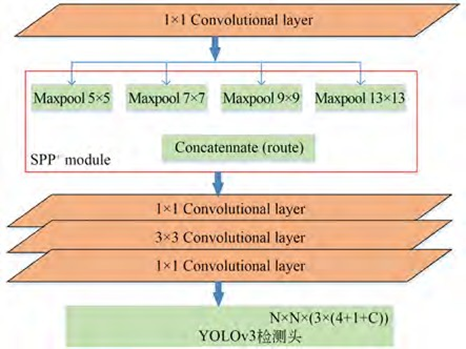
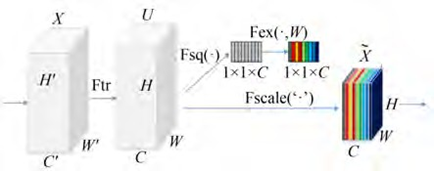
在过去十年中,自动驾驶和高级驾驶辅助系统(AD/ADAS)软件与硬件的快速发展对多传感器数据采集的设计需求提出了更高的要求。然而,目前仍缺乏能够高质量集成多传感器数据采集的解决方案。康谋ADTF正是应运而生,它提供了一个广受认可和广泛引用的软件框架,包含模块化的标准化应用程序和工具,旨在为ADAS功能的开发提供一站式体验。一、ADTF的关键之处!无论是奥迪、大众、宝马还是梅赛德斯-奔驰:他们都依赖我们不断发展的ADTF来开发智能驾驶辅助解决方案,直至实现自动驾驶的目标。从新功能的最初构思到批量生